基于深度學習的手部21類關鍵點檢測
基于深度學習的人體關鍵點檢測
開發環境
* Python 3.7
* PyTorch >= 1.5.1
* opencv-python
資料源
- 普通USB彩色(RGB)網路攝像頭
- 已經存盤下來的視頻或者圖片
資料集
本專案資料集百度網盤下載地址:下載地址
該資料集包括網路圖片及資料集<<Large-scale Multiview 3D Hand Pose Dataset>>篩選動作重復度低的部分圖片,進行制作(如有侵權請聯系洗掉),共49062個樣本,
<<Large-scale Multiview 3D Hand Pose Dataset>>資料集,其官網地址 http://www.rovit.ua.es/dataset/mhpdataset/
感謝《Large-scale Multiview 3D Hand Pose Dataset》資料集貢獻者:Francisco Gomez-Donoso, Sergio Orts-Escolano, and Miguel Cazorla. “Large-scale Multiview 3D Hand Pose Dataset”. ArXiv e-prints 1707.03742, July 2017.
本專案訓練測驗資料集、訓練測驗代碼和演示demo
打包下載地址:下載地址
本專案demo


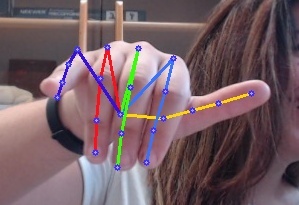
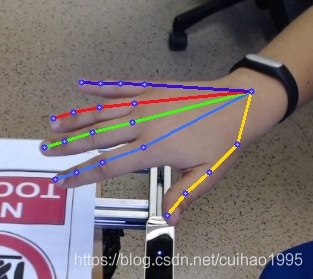

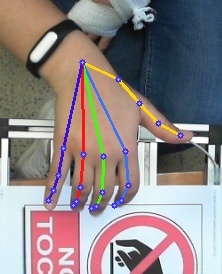
目前支持的模型 (backbone)
- resnet18 & resnet34 & resnet50 & resnet101
- squeezenet1_0 & squeezenet1_1
- ShuffleNet & ShuffleNetV2
- MobileNetV2
- rexnetv1
- shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0 (torchvision 版本)
預訓練模型
- 預訓練模型:代碼下載地址中,見檔案夾W
模型訓練
- 運行命令: python train.py
#-*-coding:utf-8-*-
import os
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import sys
from utils.model_utils import *
from utils.common_utils import *
from hand_data_iter.datasets import *
from models.resnet import resnet18,resnet34,resnet50,resnet101
from models.squeezenet import squeezenet1_1,squeezenet1_0
from models.shufflenetv2 import ShuffleNetV2
from models.shufflenet import ShuffleNet
from models.mobilenetv2 import MobileNetV2
from models.rexnetv1 import ReXNetV1
from torchvision.models import shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0
from loss.loss import *
import cv2
import time
import json
from datetime import datetime
import random
def trainer(ops,f_log):
try:
os.environ['CUDA_VISIBLE_DEVICES'] = ops.GPUS
if ops.log_flag:
sys.stdout = f_log
set_seed(ops.seed)
#---------------------------------------------------------------- 構建模型
if ops.model == 'resnet_50':
model_ = resnet50(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == 'resnet_18':
model_ = resnet18(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == 'resnet_34':
model_ = resnet34(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == 'resnet_101':
model_ = resnet101(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == "squeezenet1_0":
model_ = squeezenet1_0(pretrained=True, num_classes=ops.num_classes,dropout_factor=ops.dropout)
elif ops.model == "squeezenet1_1":
model_ = squeezenet1_1(pretrained=True, num_classes=ops.num_classes,dropout_factor=ops.dropout)
elif ops.model == "shufflenetv2":
model_ = ShuffleNetV2(ratio=1., num_classes=ops.num_classes, dropout_factor=ops.dropout)
elif ops.model == "shufflenet_v2_x1_5":
model_ = shufflenet_v2_x1_5(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x1_0":
model_ = shufflenet_v2_x1_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x2_0":
model_ = shufflenet_v2_x2_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet":
model_ = ShuffleNet(num_blocks = [2,4,2], num_classes=ops.num_classes, groups=3, dropout_factor = ops.dropout)
elif ops.model == "mobilenetv2":
model_ = MobileNetV2(num_classes=ops.num_classes , dropout_factor = ops.dropout)
elif ops.model == "ReXNetV1":
model_ = ReXNetV1(num_classes=ops.num_classes , width_mult=0.9, depth_mult=1.0, dropout_factor = ops.dropout)
else:
print(" no support the model")
use_cuda = torch.cuda.is_available()
device = torch.device("cuda:0" if use_cuda else "cpu")
model_ = model_.to(device)
# print(model_)# 列印模型結構
# Dataset
dataset = LoadImagesAndLabels(ops= ops,img_size=ops.img_size,flag_agu=ops.flag_agu,fix_res = ops.fix_res,vis = False)
print("handpose done")
print('len train datasets : %s'%(dataset.__len__()))
# Dataloader
dataloader = DataLoader(dataset,
batch_size=ops.batch_size,
num_workers=ops.num_workers,
shuffle=True,
pin_memory=False,
drop_last = True)
# 優化器設計
optimizer_Adam = torch.optim.Adam(model_.parameters(), lr=ops.init_lr, betas=(0.9, 0.99),weight_decay=1e-6)
# optimizer_SGD = optim.SGD(model_.parameters(), lr=ops.init_lr, momentum=ops.momentum, weight_decay=ops.weight_decay)# 優化器初始化
optimizer = optimizer_Adam
# 加載 finetune 模型
if os.access(ops.fintune_model,os.F_OK):# checkpoint
chkpt = torch.load(ops.fintune_model, map_location=device)
model_.load_state_dict(chkpt)
print('load fintune model : {}'.format(ops.fintune_model))
print('/**********************************************/')
# 損失函式
if ops.loss_define == 'mse_loss':
criterion = nn.MSELoss(reduce=True, reduction='mean')
elif ops.loss_define == 'adaptive_wing_loss':
criterion = AdaptiveWingLoss()
step = 0
idx = 0
# 變數初始化
best_loss = np.inf
loss_mean = 0. # 損失均值
loss_idx = 0. # 損失計算計數器
flag_change_lr_cnt = 0 # 學習率更新計數器
init_lr = ops.init_lr # 學習率
epochs_loss_dict = {}
for epoch in range(0, ops.epochs):
if ops.log_flag:
sys.stdout = f_log
print('\nepoch %d ------>>>'%epoch)
model_.train()
# 學習率更新策略
if loss_mean!=0.:
if best_loss > (loss_mean/loss_idx):
flag_change_lr_cnt = 0
best_loss = (loss_mean/loss_idx)
else:
flag_change_lr_cnt += 1
if flag_change_lr_cnt > 50:
init_lr = init_lr*ops.lr_decay
set_learning_rate(optimizer, init_lr)
flag_change_lr_cnt = 0
loss_mean = 0. # 損失均值
loss_idx = 0. # 損失計算計數器
for i, (imgs_, pts_) in enumerate(dataloader):
# print('imgs_, pts_',imgs_.size(), pts_.size())
if use_cuda:
imgs_ = imgs_.cuda() # pytorch 的 資料輸入格式 : (batch, channel, height, width)
pts_ = pts_.cuda()
output = model_(imgs_.float())
if ops.loss_define == 'wing_loss':
loss = got_total_wing_loss(output, pts_.float())
else:
loss = criterion(output, pts_.float())
loss_mean += loss.item()
loss_idx += 1.
if i%10 == 0:
loc_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(' %s - %s - epoch [%s/%s] (%s/%s):'%(loc_time,ops.model,epoch,ops.epochs,i,int(dataset.__len__()/ops.batch_size)),\
'Mean Loss : %.6f - Loss: %.6f'%(loss_mean/loss_idx,loss.item()),\
' lr : %.8f'%init_lr,' bs :',ops.batch_size,\
' img_size: %s x %s'%(ops.img_size[0],ops.img_size[1]),' best_loss: %.6f'%best_loss, " {}".format(ops.loss_define))
# 計算梯度
loss.backward()
# 優化器對模型引數更新
optimizer.step()
# 優化器梯度清零
optimizer.zero_grad()
step += 1
#set_seed(random.randint(0,65535))
torch.save(model_.state_dict(), ops.model_exp + '{}-size-{}-loss-{}-model_epoch-{}.pth'.format(ops.model,ops.img_size[0],ops.loss_define,epoch))
except Exception as e:
print('Exception : ',e) # 列印例外
print('Exception file : ', e.__traceback__.tb_frame.f_globals['__file__'])# 發生例外所在的檔案
print('Exception line : ', e.__traceback__.tb_lineno)# 發生例外所在的行數
if __name__ == "__main__":
parser = argparse.ArgumentParser(description=' Project Hand Train')
parser.add_argument('--seed', type=int, default = 126673,
help = 'seed') # 設定隨機種子
parser.add_argument('--model_exp', type=str, default = './model_exp',
help = 'model_exp') # 模型輸出檔案夾
parser.add_argument('--model', type=str, default = 'shufflenet_v2_x2_0',
help = '''model : resnet_34,resnet_50,resnet_101,squeezenet1_0,squeezenet1_1,shufflenetv2,shufflenet,mobilenetv2
shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0,ReXNetV1''') # 模型型別
parser.add_argument('--num_classes', type=int , default = 42,
help = 'num_classes') # landmarks 個數*2
parser.add_argument('--GPUS', type=str, default = '0',
help = 'GPUS') # GPU選擇
parser.add_argument('--train_path', type=str,
default = "./handpose_datasets_v1/",
help = 'datasets')# 訓練集標注資訊
parser.add_argument('--pretrained', type=bool, default = True,
help = 'imageNet_Pretrain') # 初始化學習率
parser.add_argument('--fintune_model', type=str, default = 'None',
help = 'fintune_model') # fintune model
parser.add_argument('--loss_define', type=str, default = 'adaptive_wing_loss',
help = 'define_loss : wing_loss, mse_loss ,adaptive_wing_loss') # 損失函式定義
parser.add_argument('--init_lr', type=float, default = 1e-3,
help = 'init learning Rate') # 初始化學習率
parser.add_argument('--lr_decay', type=float, default = 0.1,
help = 'learningRate_decay') # 學習率權重衰減率
parser.add_argument('--weight_decay', type=float, default = 1e-6,
help = 'weight_decay') # 優化器正則損失權重
parser.add_argument('--momentum', type=float, default = 0.9,
help = 'momentum') # 優化器動量
parser.add_argument('--batch_size', type=int, default = 16,
help = 'batch_size') # 訓練每批次影像數量
parser.add_argument('--dropout', type=float, default = 0.5,
help = 'dropout') # dropout
parser.add_argument('--epochs', type=int, default = 3000,
help = 'epochs') # 訓練周期
parser.add_argument('--num_workers', type=int, default = 10,
help = 'num_workers') # 訓練資料生成器執行緒數
parser.add_argument('--img_size', type=tuple , default = (256,256),
help = 'img_size') # 輸入模型圖片尺寸
parser.add_argument('--flag_agu', type=bool , default = True,
help = 'data_augmentation') # 訓練資料生成器是否進行資料擴增
parser.add_argument('--fix_res', type=bool , default = False,
help = 'fix_resolution') # 輸入模型樣本圖片是否保證影像解析度的長寬比
parser.add_argument('--clear_model_exp', type=bool, default = False,
help = 'clear_model_exp') # 模型輸出檔案夾是否進行清除
parser.add_argument('--log_flag', type=bool, default = False,
help = 'log flag') # 是否保存訓練 log
#--------------------------------------------------------------------------
args = parser.parse_args()# 決議添加引數
#--------------------------------------------------------------------------
mkdir_(args.model_exp, flag_rm=args.clear_model_exp)
loc_time = time.localtime()
args.model_exp = args.model_exp + '/' + time.strftime("%Y-%m-%d_%H-%M-%S", loc_time)+'/'
mkdir_(args.model_exp, flag_rm=args.clear_model_exp)
f_log = None
if args.log_flag:
f_log = open(args.model_exp+'/train_{}.log'.format(time.strftime("%Y-%m-%d_%H-%M-%S",loc_time)), 'a+')
sys.stdout = f_log
print('---------------------------------- log : {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", loc_time)))
print('\n/******************* {} ******************/\n'.format(parser.description))
unparsed = vars(args) # parse_args()方法的回傳值為namespace,用vars()內建函式化為字典
for key in unparsed.keys():
print('{} : {}'.format(key,unparsed[key]))
unparsed['time'] = time.strftime("%Y-%m-%d %H:%M:%S", loc_time)
fs = open(args.model_exp+'train_ops.json',"w",encoding='utf-8')
json.dump(unparsed,fs,ensure_ascii=False,indent = 1)
fs.close()
trainer(ops = args,f_log = f_log)# 模型訓練
if args.log_flag:
sys.stdout = f_log
print('well done : {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())))
模型推理
- 運行命令: python inference.py
#-*-coding:utf-8-*-
import os
import argparse
import torch
import torch.nn as nn
import numpy as np
import time
import datetime
import os
import math
from datetime import datetime
import cv2
import torch.nn.functional as F
from models.resnet import resnet18,resnet34,resnet50,resnet101
from models.squeezenet import squeezenet1_1,squeezenet1_0
from models.shufflenetv2 import ShuffleNetV2
from models.shufflenet import ShuffleNet
from models.mobilenetv2 import MobileNetV2
from torchvision.models import shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0
from models.rexnetv1 import ReXNetV1
from utils.common_utils import *
import copy
from hand_data_iter.datasets import draw_bd_handpose
if __name__ == "__main__":
parser = argparse.ArgumentParser(description=' Project Hand Pose Inference')
parser.add_argument('--model_path', type=str, default = './w/resnet50_2021-418.pth',
help = 'model_path') # 模型路徑
parser.add_argument('--model', type=str, default = 'resnet_50',
help = '''model : resnet_34,resnet_50,resnet_101,squeezenet1_0,squeezenet1_1,shufflenetv2,shufflenet,mobilenetv2
shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0,ReXNetV1''') # 模型型別
parser.add_argument('--num_classes', type=int , default = 42,
help = 'num_classes') # 手部21關鍵點, (x,y)*2 = 42
parser.add_argument('--GPUS', type=str, default = '0',
help = 'GPUS') # GPU選擇
parser.add_argument('--test_path', type=str, default = './image/',
help = 'test_path') # 測驗圖片路徑
parser.add_argument('--img_size', type=tuple , default = (256,256),
help = 'img_size') # 輸入模型圖片尺寸
parser.add_argument('--vis', type=bool , default = True,
help = 'vis') # 是否可視化圖片
print('\n/******************* {} ******************/\n'.format(parser.description))
#--------------------------------------------------------------------------
ops = parser.parse_args()# 決議添加引數
#--------------------------------------------------------------------------
print('----------------------------------')
unparsed = vars(ops) # parse_args()方法的回傳值為namespace,用vars()內建函式化為字典
for key in unparsed.keys():
print('{} : {}'.format(key,unparsed[key]))
#---------------------------------------------------------------------------
os.environ['CUDA_VISIBLE_DEVICES'] = ops.GPUS
test_path = ops.test_path # 測驗圖片檔案夾路徑
#---------------------------------------------------------------- 構建模型
print('use model : %s'%(ops.model))
if ops.model == 'resnet_50':
model_ = resnet50(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == 'resnet_18':
model_ = resnet18(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == 'resnet_34':
model_ = resnet34(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == 'resnet_101':
model_ = resnet101(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == "squeezenet1_0":
model_ = squeezenet1_0(num_classes=ops.num_classes)
elif ops.model == "squeezenet1_1":
model_ = squeezenet1_1(num_classes=ops.num_classes)
elif ops.model == "shufflenetv2":
model_ = ShuffleNetV2(ratio=1., num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x1_5":
model_ = shufflenet_v2_x1_5(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x1_0":
model_ = shufflenet_v2_x1_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x2_0":
model_ = shufflenet_v2_x2_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet":
model_ = ShuffleNet(num_blocks = [2,4,2], num_classes=ops.num_classes, groups=3)
elif ops.model == "mobilenetv2":
model_ = MobileNetV2(num_classes=ops.num_classes)
elif ops.model == "ReXNetV1":
model_ = ReXNetV1( width_mult=1.0, depth_mult=1.0, num_classes=ops.num_classes)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda:0" if use_cuda else "cpu")
model_ = model_.to(device)
model_.eval() # 設定為前向推斷模式
# print(model_)# 列印模型結構
# 加載測驗模型
if os.access(ops.model_path,os.F_OK):# checkpoint
chkpt = torch.load(ops.model_path, map_location=device)
model_.load_state_dict(chkpt)
print('load test model : {}'.format(ops.model_path))
#---------------------------------------------------------------- 預測圖片
'''建議 檢測手bbox后,crop手圖片的預處理方式:
# img 為原圖
x_min,y_min,x_max,y_max,score = bbox
w_ = max(abs(x_max-x_min),abs(y_max-y_min))
w_ = w_*1.1
x_mid = (x_max+x_min)/2
y_mid = (y_max+y_min)/2
x1,y1,x2,y2 = int(x_mid-w_/2),int(y_mid-w_/2),int(x_mid+w_/2),int(y_mid+w_/2)
x1 = np.clip(x1,0,img.shape[1]-1)
x2 = np.clip(x2,0,img.shape[1]-1)
y1 = np.clip(y1,0,img.shape[0]-1)
y2 = np.clip(y2,0,img.shape[0]-1)
'''
with torch.no_grad():
idx = 0
for file in os.listdir(ops.test_path):
if '.jpg' not in file:
continue
idx += 1
print('{}) image : {}'.format(idx,file))
img = cv2.imread(ops.test_path + file)
img_width = img.shape[1]
img_height = img.shape[0]
# 輸入圖片預處理
img_ = cv2.resize(img, (ops.img_size[1],ops.img_size[0]), interpolation = cv2.INTER_CUBIC)
img_ = img_.astype(np.float32)
img_ = (img_-128.)/256.
img_ = img_.transpose(2, 0, 1)
img_ = torch.from_numpy(img_)
img_ = img_.unsqueeze_(0)
if use_cuda:
img_ = img_.cuda() # (bs, 3, h, w)
pre_ = model_(img_.float()) # 模型推理
output = pre_.cpu().detach().numpy()
output = np.squeeze(output)
pts_hand = {} #構建關鍵點連線可視化結構
for i in range(int(output.shape[0]/2)):
x = (output[i*2+0]*float(img_width))
y = (output[i*2+1]*float(img_height))
pts_hand[str(i)] = {}
pts_hand[str(i)] = {
"x":x,
"y":y,
}
draw_bd_handpose(img,pts_hand,0,0) # 繪制關鍵點連線
#------------- 繪制關鍵點
for i in range(int(output.shape[0]/2)):
x = (output[i*2+0]*float(img_width))
y = (output[i*2+1]*float(img_height))
cv2.circle(img, (int(x),int(y)), 3, (255,50,60),-1)
cv2.circle(img, (int(x),int(y)), 1, (255,150,180),-1)
if ops.vis:
cv2.namedWindow('image',0)
cv2.imshow('image',img)
cv2.imwrite(file, img)
if cv2.waitKey(600) == 27 :
break
cv2.destroyAllWindows()
print('well done ')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282832.html
標籤:AI
下一篇:余弦定理和新聞的分類