世界上有些事情常常超乎人們的想象,余弦定理和新聞的分類似乎是兩件八桿子打不著的事,但是它們確有緊密的聯系,具體地說,新聞的分類很大程度上依靠的是余弦定理,
早在2002年夏天,Google就推出了自己的"新聞"服務,和傳統媒體的做法不同,這些新聞不是記者寫的,也不是人工編輯的,而是由計算機整理、分類和聚合各個新聞網站的內容,一切都是自動生成的,這里面的關鍵技術就是新聞的自動分類,
1. 新聞的特征向量:
所謂新聞的分類,或者更廣義地講任何文本的分類,無非是要把相似的新聞放到同一類中,如果讓編輯來對新聞分類,他—定是先把新聞讀懂,然后找到它的主題,最后根據主題的不同對新聞進行分類,但是計算機根本讀不懂新聞,雖然一些商業人士和愛炫耀自己才學的計算機專家宣稱計算機能讀懂新聞,計算機本質上只能做快速計算,為了讓計算機能夠"算"新聞(而不是讀新聞),就要求我們首先要把文字的新聞變成可以計算的一組數字,然后再設計一個演算法來算出任意兩篇新聞的相似性,
首先讓我們來看看怎樣找一組數字(或者說一個向量)來描述一篇新聞,新聞是傳遞資訊的,而詞是資訊的載體,新聞的資訊和詞的語意是聯系在一起的,套用俄羅斯文豪托爾斯泰在《安娜·卡列尼娜》開篇的那句話工來講,"同一類新聞用詞都是相似的,不同類的新聞用詞各不相同",當然,一篇新聞有很多詞,有些詞表達的語意重要,有些相對次要,那么如何確定哪些重要,哪些次要呢? 首先,直覺告訴我們含義豐富的實詞一定比"的、地、得"這些助詞,或者"之乎者也"這樣的虛詞重要這點是肯定的,接下來,需要進一步對每個實詞的重要性進行度量,在一篇文章中,重要的詞TF- IDF值就高,不難想象,和新聞主題有關的那些實詞頻率高,TF-IDF值很大,
現在我們找到了一組來描述新聞主題的數字∶ 對于一篇新聞中的所有實詞,計算出它們的 TF-IDF 值,把這些值按照對應的實詞在詞匯表的位置依次排列,就得到一個向量,比如,詞匯表中有 64 000個詞,其編號和詞如下圖所示:
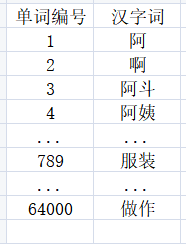
在某一篇特定的新聞中,這 64000 個詞的 TF-IDF 值分別如下圖 所示:
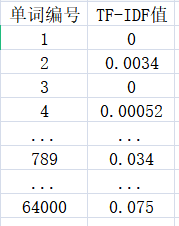
如果單詞表中的某個詞在新聞中沒有出現,對應的值為零,那么這 64000 個數,組成一個64000 維的向量,我們就用這個向量來代表這篇新聞,并成為新聞的特征向量(Feature Vector),每一篇新聞都可以對應這樣一個特征向量,向量中每一個維度的大小代表每個詞對這篇新聞主題的貢獻,當新聞從文字變成了數字后,計算機就有可能"算一算"新聞之間是否相似了,
一篇篇文章變成了一串串數字:
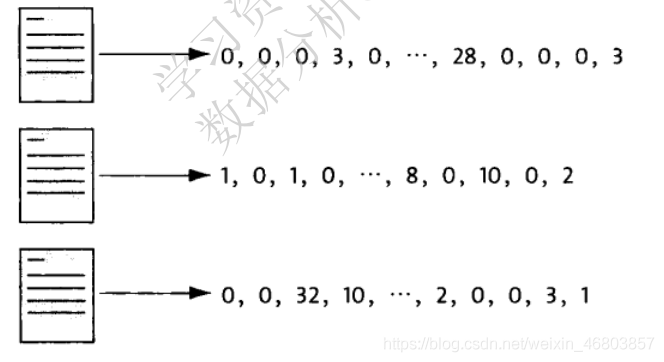
2. 向量距離的度量:
世界各國無論是哪門語言的"幼ò肝"(Language Art),老師教授寫作時都會強調特定的主題用特定的描述詞,幾千年來,人類已經形成了這樣的寫作習慣,因此,同一類新聞一定是某些主題詞用得較多,另外一些詞則用得少,比如金融類的新聞,這些詞出現的頻率就很高;股票,利息,債券,基金,銀行,物價,上漲,而這些詞出現的就少∶ 二訊訓碳,宇宙,詩歌,木匠,諾貝爾,包子,反映在每一篇新聞的特征上,如果兩篇新聞屬于同一類,它們的特征向量在某幾個維度的值都比較大,而在其他維度的值都比較小,反過來看,如果兩篇新聞不屬于同一類,由于用詞的不同,它們的特征向量中,值較大的維度應該沒有什么交集,這樣就定性地認識到兩篇新聞的主題是否接近,取決于它們的特征向量"長得像不像",當然,我們還需要定量地衡量兩個特征向量之間的相似性,

不同的新聞,因為文本長度的不同,它們的特征向量各個維度的數值也不同,一篇 10000 字的文本,各個維度的數值都比一篇 500 字的文本來得大,因此單純比較各個維度的大小并沒有太大意義,但是,向量的方向卻有很大的意義,如果兩個向量的方向一致,說明相應的新聞用詞的比例基本一致,因此,可以通過計算兩個向量的夾角來判斷對應的新聞主題的接近程度,而要計算兩個向量的夾角,就要用到余弦定理了,比如上圖中,左邊兩個向量的夾角小,距離就較"近",相反,右邊兩個向量的夾角大,距離就"遠",
3. 余弦定理:
我們對余弦定理都不陌生,它描述了三角形中任何一個夾角和三個邊的關系,換句話說,給定三角形的三條邊,可以用余弦定理求出三角形各個角的角度,假定三角形的三條邊為a,b和c,對應的三個角為A,B和C,
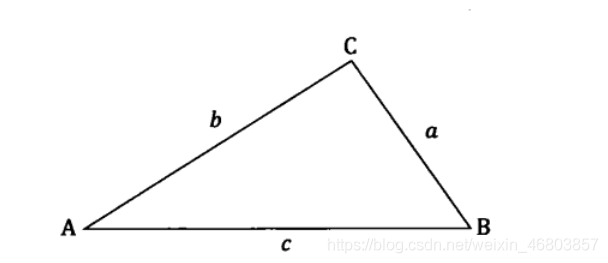
那么的余弦是:
,
如果將三角形的兩邊b和c看成是兩個以A為起點的向量,那么上述公式等價于 ,
其中,分母表示兩個向量b和c的長度,分子表示兩個向量的內積,舉一個具體的例子,假如新聞X和新聞Y對應的向量分別是: 和
,
那么它們夾角的余弦等于:
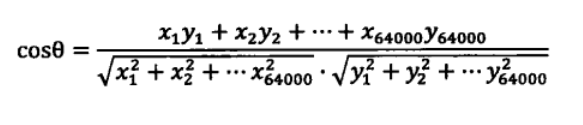
由于向量中的每一個變數都是正數,因此余弦的取值在 0和1 之間,也就是說夾角在 0 度到 90 度之間,當兩條新聞向量夾角的余弦等于1時,這兩個向量的夾角為零,兩條新聞完全相同;當夾角的余弦接近于1時,兩條新聞相似,從而可以歸成一類;夾角的余弦越小,夾角越大,兩條新聞越不相關,當兩個向量正交時(90 度),夾角的余弦為零,說明兩篇新聞根本沒有相同的主題詞,它們毫不相關,
現在把一篇篇文字的新聞變成了按詞典順序組織起來的數字( 特征向量),又有了計算相似性的公式,就可以在此基礎上討論新聞分類的演算法了,余弦定理就這樣通過新聞的特征向量和新聞分類聯系在一起,我們在中學學習余弦定理時,恐怕很難想象它可以用來對新聞進行分類,
補充:什么是TF-IDF:
TF-IDF(Term Frequency - Inverse Document Frequency, 單文本詞頻-逆文本頻率指數),一種用于資訊檢索和資訊探勘的常用加權技術,被公認為資訊檢索中最重要的發明,
TF-IDF是一種統計方法,用以評估一字詞對于一個檔案集或一個語料庫中的其中一份檔案的重要程度,字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降,TF-IDF加權的各種形式常被搜尋引擎應用,作為檔案與用戶查詢之間相關程度的度量或評級,
詞頻(Term Frequency):某一給定詞語在該文本中出現次數,該數字通常會被歸一化(分子一般小于分母),以防止它偏向長的檔案,因為不管該詞語重要與否,它在長檔案中出現的次數很可能比在段檔案中出現的次數更大,需要注意的是有一些通用詞對文章主題沒有太大作用,如“的”、“是”等,而有一些頻率出現少的詞如一些專業詞更能表現文章主題,所以為詞語設定權重,權重的設計滿足:一個詞預測主題的能力越強,權重越大,反之,權重越小,也就是說,一些詞只在很少幾篇文章中出現,那么這樣的詞對文章主題的判斷能力很大,這些詞的權重應該設計的較大,IDF完成這樣的作業,
逆向檔案頻率IDF(Inverse Document Frequency):一個詞語普遍重要性的度量,主要思想是:如果包含一個詞條的檔案越少, IDF越大,則說明詞條具有很好的類別區分能力,
可以簡單的理解成:一個詞語在一篇文章中出現的次數越多,同時在其他的所有檔案中出現的次數越少,越能夠代表該文章,
讀者可以自行去查閱資料,了解TF-IDF的具體計算方法和基于資訊論的基本原理,
結語:
本文旨在簡單的介紹余弦定理與新聞分類的聯系,也就是數學和計算機科學的交叉,在我們看來復雜的計算機處理工程中,其中蘊含的原理可能就是一個簡單的數學公式,數學有著簡單美的特性,計算機科學也有,文章主要參考了吳軍博士的《數學之美》,吳軍博士遵循著簡單的哲學,倡導要努力去尋找簡單有效的方法,不是靠直覺,更不是撞大運,而是要靠自己的經驗,不怕失敗,大膽嘗試,總會有所識訓的,
Everything is difficult until you know how to do it.😀
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282833.html
標籤:AI