一.協同過濾是什么?
協同過濾,英文又稱Collaborative Filtering,簡稱CF,注意這里不是指游戲cf,
舉個例子,你想和女朋友出去看場電影,但是你們兩個都不知道看什么好,這個時候,你就會想,要不我問問身邊和我興趣差不多的伙伴有什么值得看的吧?這就是協同過濾的核心思想,即協同過濾是一種基于一組興趣相同的用戶或專案進行的推薦,
演算法優點:
①協同推薦是應用最廣泛的推薦演算法,可以過濾掉許多人難以量化描述的概念標簽的構建;
②僅使用用戶行為的進行推薦,極大的提升了速度與準確度;
③可以很好地發現用戶的潛在興趣偏好,
演算法缺點
①用戶對商品的評價非常稀疏,而有些用戶對使用過的商品根本不做評價,這樣基于用戶的評價所得到的用戶間的相似性可能不準確;
②隨著用戶和物品的增多,系統的性能會越來越低,甚至會出現記憶體耗盡;
③對于新用戶或者新物品,推薦的質量會較差,即常說的冷啟動問題,
二.相似度的計算
在相似度的計算中,使用sim來代替英文similarity(相似度),用sim(a,b)來表示a與b的相似度,下面為3個關于相似度的經典演算法,
1.余弦相似度:2.1 余弦定理相似性度量余弦距離通過向量空間中兩個向量夾角的余弦值作為衡量兩個個體間差異的大小的度量,三角形余弦定理公式:
c
o
s
A
=
b
2
+
c
2
?
a
2
2
b
c
cosA=\frac{b^{2}+c^{2}-a^{2}}{2bc}
cosA=2bcb2+c2?a2?由三角形余弦定理公式可知,角 A 越小,bc 兩邊越接近,當 A 為 0 度時,bc 兩邊完全重合,在向量空間中,對于向量 a 和向量 b 符合公式:
c
o
s
C
=
<
a
?
,
b
?
>
∣
a
?
∣
∣
b
?
∣
cosC=\frac{<\vec a,\vec b>}{|\vec a||\vec b|}
cosC=∣a
∣∣b
∣<a
,b
>?當 a 和 b 越接近(越相似)時,余弦值就越大,最大為 1.所以在比對 a 和 b 的相似度時,可以將其向量化后,計算它的余弦值,從而比較其相似度,即:
s
i
m
(
a
,
b
)
=
c
o
s
(
a
?
b
?
)
=
a
?
?
b
?
∣
a
?
∣
?
∣
b
?
∣
sim(a,b)=cos(\vec a\vec b)=\frac{\vec a·\vec b}{|\vec a|·|\vec b|}
sim(a,b)=cos(a
b
)=∣a
∣?∣b
∣a
?b
?類似的也可以推廣到多個樣本的相似性度量公式:
s
i
m
(
a
,
b
,
?
?
?
)
=
c
o
s
θ
=
x
1
y
1
+
x
2
y
2
+
?
?
?
+
x
n
y
n
x
1
2
+
x
2
2
+
?
?
?
+
x
n
2
?
y
1
2
+
y
2
2
+
?
?
?
+
y
n
2
sim(a,b,···)=cosθ=\frac{x_{1}y_{1}+x_{2}y_{2}+···+x_{n}y_{n}}{\sqrt{x_{1}^{2}+x_{2}^{2}+···+x_{n}^{2}}·\sqrt{y_{1}^{2}+y_{2} ^{2}+···+y_{n}^{2}}}
sim(a,b,???)=cosθ=x12?+x22?+???+xn2?
??y12?+y22?+???+yn2?
?x1?y1?+x2?y2?+???+xn?yn??對于集合 A 和集合 B 的相似性度量,為了方便計算,我們往往會用到下面的公式(計算的結果大小和上面的公式計算的結果是一樣的):
s
i
m
(
A
,
B
)
=
A
∩
B
∣
A
∣
?
∣
B
∣
sim(A,B)=\frac{A∩B}{\sqrt{|A|·|B|}}
sim(A,B)=∣A∣?∣B∣
?A∩B?
2.歐幾里得距離(euclidea nmetric)(也稱歐式距離)是一個通常采用的距離定義,指在m維空間中兩個點之間的真實距離,或者向量的自然長度(即該點到原點的距離),在二維和三維空間中的歐氏距離就是兩點之間的實際距離,
那距離是如何反映出相似度的呢,很簡單,我們總是希望相似度越大回傳的值越大,所以我們取距離的倒數即可(因為距離越大相似度越小),又因為分母不能為0,所以我們往往取函式值加1的倒數,
3:皮爾遜相關度
皮爾遜相關系數是一種度量兩個變數間相關程度的方法,它是一個介于 1 和 -1 之間的值,其中,1 表示變數完全正相關, 0 表示無關,-1 表示完全負相關,公式有很多,這里取其中一個我認為最好理解的,
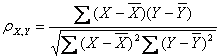
相關系數:一般指兩個事物(在函式里經常說變數)之間的關系程度,
如果有兩個變數:X、Y,最終計算出的相關系數的含義可以有如下理解:
(1)、當相關系數為0時,X和Y兩變數無關系,
(2)、當X的值增大(減小),Y值增大(減小),兩個變數為正相關,相關系數在0.00與1.00之間,
(3)、當X的值增大(減小),Y值減小(增大),兩個變數為負相關,相關系數在-1.00與0.00之間,
相關系數的絕對值越大,相關性越強,相關系數越接近于1或-1,相關度越強,相關系數越接近于0,相關度越弱,
通常情況下通過以下取值范圍判斷變數的相關強度:
相關系數:
0.8-1.0 極強相關
0.6-0.8 強相關
0.4-0.6 中等程度相關
0.2-0.4 弱相關
0.0-0.2 極弱相關或無相關
三.
1.基于物品(ItemCF)的協同過濾:
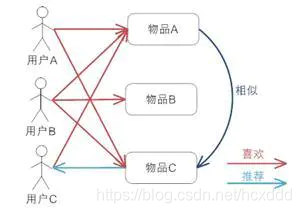
基本原理:通過某個用戶的瀏覽記錄,來分析用戶對于某類物品的偏好程度,從而為用戶推薦相似的物品,即相似的物品可能會被同一用戶喜歡,

演算法程序實作:
1.建立 物品 — 用戶 倒排表;
物品 a:用戶 A、用戶 B、用戶 C
物品 b:用戶 C
物品 c:用戶 A、用戶 B
2.計算各物品之間的相似度(使用余弦定理相似性度量);可以構建如下的相似度矩陣:

3.根據物品的相似度和用戶的歷史記錄給用戶生成推薦串列
通過如下公式計算用戶 u 對一個物品 j 的購買預測值:
p
(
u
,
j
)
=
∑
i
∈
N
(
u
)
∩
S
(
i
,
k
)
w
j
i
r
u
i
p(u,j)=\sum_{i∈N(u)∩S(i,k)}w_{ji}r_{ui}
p(u,j)=∑i∈N(u)∩S(i,k)?wji?rui?
其中,
p
(
u
,
j
)
p(u,j)
p(u,j) 表示用戶
u
u
u 對物品
j
j
j 的興趣,
N
(
u
)
N(u)
N(u) 表示用戶喜歡的物品集合(
i
i
i 是該用戶喜歡的某一個物品),
S
(
i
,
k
)
S(i,k)
S(i,k) 表示和物品
i
i
i 最相似的
K
K
K 個物品集合(
j
j
j 是這個集合中的某一個物品),
w
j
i
w_{ji}
wji? 表示物品 j 和物品 i 的相似度,
r
u
i
r_{ui}
rui? 表示用戶
u
u
u 對物品
i
i
i 的興趣(這里簡化
r
u
i
r_{ui}
rui? 都等于 1),
例如:我們默認K等于1,
p
(
C
,
c
)
=
2
6
p(C,c)=\frac{2}{\sqrt{6}}
p(C,c)=6
?2?,
p
(
B
,
b
)
=
1
3
p(B,b)=\frac{1}{\sqrt{3}}
p(B,b)=3
?1?
4.向用戶展示推薦物品
**代碼實作:**
import numpy as np
from math import sqrt
'''
用戶/物品 | 物品a | 物品b | 物品c
用戶A | √ | | √
用戶B | √ | | √
用戶C | √ | √ |
'''
#定義余弦相似性度量計算
def cosine(ls_1,ls_2,m): #ls_1,ls_2表示用戶1,2的相關陣列,m表示總的物品數
Numerator = 0 #公式中的分子
abs_1 = abs_2 = 0 #分母中兩向量的絕對值,即代表模
for i in range(m):
Numerator += ls_1[i] * ls_2[i]#同時喜歡才加一,就算一個人喜歡,另一個人不喜歡,相乘仍為零
if ls_1[i] == 1:
abs_1 += ls_1[i]#喜歡就加一
if ls_2[i] == 1:
abs_2 += ls_2[i]#喜歡就加一
Denominator = sqrt(abs_1 * abs_2) #公式中的分母
return Numerator/Denominator
#定義預測函式
def predict(w_uv,r_vi=1):
p = w_uv * r_vi
return p
if __name__ == "__main__":#一些牛b的代碼都會有
#建立用戶 - 物品矩陣
user_item = np.array([[1,0,1],
[1,0,1],
[1,1,0]])
print("用戶-物品矩陣:")
print(user_item)#列印用戶-物品矩陣
user = ['用戶A','用戶B','用戶C']
item = ['物品a','物品b','物品c']
n = len(user) #n 個用戶
m = len(item) #m 個物品
K = 1 #只找到一個最相似物品
#建立物品 - 用戶倒排表
item_user = user_item.T
print("物品-用戶矩陣:")
print(item_user)
#構建物品 - 物品相似度矩陣
sim = np.zeros((n,n)) #相似度矩陣,默認全為 0
for i in range(n):
for j in range(n):
if i < j:
sim[i][j] = cosine(item_user[i],item_user[j],m)#用到了前面定義的函式
sim[j][i] = sim[i][j]#代表用戶順序不同但相似度一樣
print("得到的物品-物品相似度矩陣:")
print(sim) #列印物品 - 物品相似度矩陣
#推薦物品
max_sim = [0,0,0] #存放每個物品的相似物品
r_list = [[],[],[]] #存放推薦給每個用戶的物品
p = [[],[],[]] #每個用戶被推薦物品的預測值串列
for i in range(m): #m 個物品回圈 m 次
#找到與物品 i 最相似的物品
for j in range(len(sim[i])): #range () 里面寫 m 也可以,二者等同
if max(sim[i]) != 0 and sim[i][j] == max(sim[i]):#max代表最大值
max_sim[i] = item[j] #此時的 j 就是相似物品的編號
break #break 目的:一是結束當前回圈,二是當前的 j 后面有用
if max_sim[i] == 0:
continue #等于 0,表明當前物品無相似物品,繼續下個物品
#找出應該推薦的物品,并計算預測值
for k in range(K): #為了更契合預測值計算公式,因為這里 K=1,所以也可以省去這個 for
for x in range(n): #n 個用戶回圈 n 次
if item_user[i][x] == 1 and item_user[j][x] == 0:#當前物品用戶知道,而相似物品該用戶不知道
r_list[x].append(max_sim[i])
p[x].append(predict(sim[i][j]))
#列印結果
for i in range(n): #n 個用戶回圈 n 次
if len(r_list[i]) > 0: #當前用戶有被推薦的物品
print("向{:}推薦的物品有:".format(user[i]),end='')#end的作用是防止游標移動到下一行
print(r_list[i])
print("該用戶對以上物品該興趣的預測值為:",end='')
print(p[i])
print()#輸出一行空白,即換行
**輸出結果:**
用戶-物品矩陣:
[[1 0 1]
[1 0 1]
[1 1 0]]
物品-用戶矩陣:
[[1 1 1]
[0 0 1]
[1 1 0]]
得到的物品-物品相似度矩陣:
[[0. 0.57735027 0.81649658]
[0.57735027 0. 0. ]
[0.81649658 0. 0. ]]
向用戶C推薦的物品有:['物品c']
該用戶對以上物品該興趣的預測值為:[0.8164965809277261]2.基于用戶的(userCF)的協同過濾:
基本原理:通過尋找與當前查詢者口味或偏好類似的用戶,將他們的一些喜好物品推薦給當前查詢者,即相似的用戶會喜歡相同的物品
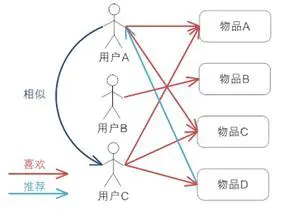
由圖片我們可以觀察出來,用戶A與用戶C的偏好類似,而用戶C又在喜歡物品A和B的基礎上喜歡物品C,所以我們考慮將物品C推薦給用戶A,

演算法程序實作:
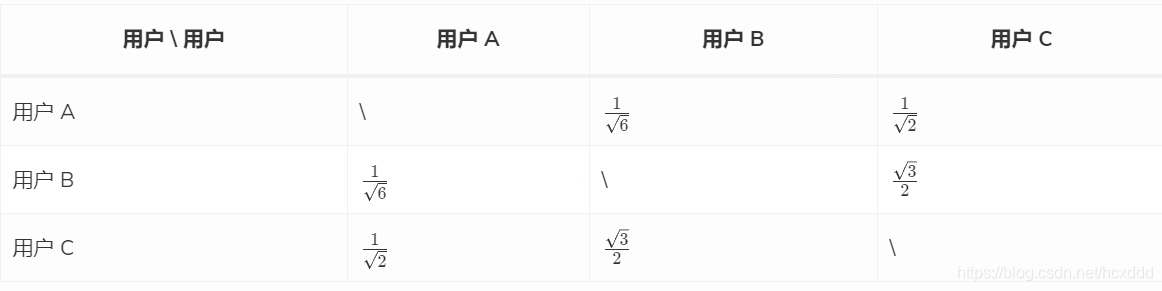
1.計算各個用戶之間的相似度(使用余弦定理相似性度量);可以構建如下的相似度矩陣:
2.根據相似度的高低找到各用戶的相似用戶;
用戶 A 的相似用戶為用戶 C;
用戶 B 的相似用戶為用戶 C;
用戶 C 的相似用戶為用戶 B,
3.找到相似用戶購買過而目標用戶不知道的物品,計算目標用戶對這樣的物品感興趣的預測值(就是預測目標用戶購買的可能性),向目標用戶推薦這些物品,
通過如下公式計算用戶 u 對一個物品 i的購買預測值:
p
(
u
,
i
)
=
∑
i
∈
N
(
v
)
∩
S
(
u
,
k
)
w
u
v
r
v
i
p(u,i)=\sum_{i∈N(v)∩S(u,k)}w_{uv}r_{vi}
p(u,i)=i∈N(v)∩S(u,k)∑?wuv?rvi?其中,
p
(
u
,
j
)
p(u,j)
p(u,j) 表示用戶
u
u
u 對物品
j
j
j 的興趣,
N
(
v
)
N(v)
N(v) 表示用戶喜歡的物品集合(
i
i
i 是該用戶喜歡的某一個物品),
S
(
u
,
k
)
S(u,k)
S(u,k) 表示和用戶
u
u
u 最相似的
K
K
K 個用戶集合(
u
u
u 是這個集合中的某一個用戶),
w
u
v
w_{uv}
wuv? 表示用戶u 和用戶v的相似度,
r
v
i
r_{vi}
rvi? 表示用戶
v
v
v 對物品
i
i
i 的興趣(這里簡化
r
v
i
r_{vi}
rvi? 都等于 1),
例如:我們默認
K
=
1
K=1
K=1,
p
(
A
,
b
)
=
1
2
p(A,b)=\frac{1}{\sqrt{2}}
p(A,b)=2
?1?,
p
(
B
,
c
)
=
3
2
p(B,c)=\frac{\sqrt{3}}{2}\qquad
p(B,c)=23
??
4.向用戶展示推薦物品,
**代碼實作:**
import numpy as np
from math import sqrt
'''
用戶/物品 | 物品a | 物品b | 物品c | 物品d
用戶A | √ | | √ |
用戶B | √ | √ | | √
用戶C | √ | √ | √ | √
'''
#定義余弦相似性度量計算
def cosine(ls_1,ls_2,m):#ls_1,ls_2表示用戶1,2的相關陣列,m表示總的物品數
Numerator = 0 #公式中的分子
abs_1 = abs_2 = 0 #分母中兩向量的絕對值,即代表模
for i in range(m):
Numerator += ls_1[i] * ls_2[i]#同時喜歡才加一,就算一個人喜歡,另一個人不喜歡,相乘仍為零
if ls_1[i] == 1:
abs_1 += ls_1[i]#喜歡就加一
if ls_2[i] == 1:
abs_2 += ls_2[i]#喜歡就加一
Denominator = sqrt(abs_1 * abs_2) #公式中的分母
return Numerator/Denominator
#定義預測函式
def predict(w_uv,r_vi=1):
p = w_uv * r_vi
return p
if __name__ == "__main__":
#建立用戶 - 物品矩陣
user_item = np.array([[1,0,1,0],
[1,1,0,1],
[1,1,1,1]])
print("用戶-物品矩陣:")
print(user_item)
user = ['用戶A','用戶B','用戶C']
item = ['物品a','物品b','物品c','物品d']
n = len(user) #n 個用戶
m = len(item) #m 個物品
K = 1 #只找到一個最相似用戶
#構建用戶 - 用戶相似度矩陣
sim = np.zeros((n,n)) #相似度矩陣,默認全為 0
for i in range(n):
for j in range(n):
if i < j:
sim[i][j] = cosine(user_item[i],user_item[j],m)#用到了前面定義的函式
sim[j][i] = sim[i][j]#代表用戶順序不同但相似度一樣
print("得到的用戶-用戶相似度矩陣:")
print(sim) #列印用戶 - 用戶相似度矩陣
# 推薦物品
max_sim = [0, 0, 0] # 存放每個用戶的相似用戶
r_list = [[], [], []] # 存放推薦給每個用戶的物品
p = [[], [], []] # 每個用戶被推薦物品的預測值串列
for i in range(n): # n 個用戶回圈 n 次
# 找到與用戶 i 最相似的用戶
for j in range(len(sim[i])): # range () 里面寫 n 也可以,二者等同
if max(sim[i]) != 0 and sim[i][j] == max(sim[i]):#max代表最大值
max_sim[i] = user[j] # 此時的 j 就是相似用戶的編號
break # break 目的:一是結束當前回圈,二是當前的 j 后面有用
if max_sim[i] == 0:
continue # 等于 0,表明當前用戶無相似用戶,無需推薦,繼續下個用戶
# 找出應該推薦的物品,并計算預測值
for k in range(K): # 為了更契合預測值計算公式,因為這里 K=1,所以也可以省去這個 for
for x in range(m): # m 個物品回圈 m 次
if user_item[i][x] == 0 and user_item[j][x] == 1: # 目標用戶不知道,而相似用戶知道
r_list[i].append(item[x])
p[i].append(predict(sim[i][j]))
# 列印結果
for i in range(n): # n 個用戶回圈 n 次
if len(r_list[i]) > 0: # 當前用戶有被推薦的物品
print("向{:}推薦的物品有:".format(user[i]), end='')#end的作用是防止游標移動到下一行
print(r_list[i])
print("該用戶對以上物品該興趣的預測值為:", end='')
print(p[i])
print()#輸出一行,即換行
**輸出結果:**
用戶-物品矩陣:
[[1 0 1 0]
[1 1 0 1]
[1 1 1 1]]
得到的用戶-用戶相似度矩陣:
[[0. 0.40824829 0.70710678]
[0.40824829 0. 0.8660254 ]
[0.70710678 0.8660254 0. ]]
向用戶A推薦的物品有:['物品b', '物品d']
該用戶對以上物品該興趣的預測值為:[0.7071067811865475, 0.7071067811865475]
向用戶B推薦的物品有:['物品c']
該用戶對以上物品該興趣的預測值為:[0.8660254037844387]四.UserCF和ItemCF的比較
Item CF是利用物品間的相似性來推薦的,所以假如用戶的數量遠遠超過物品的數量,那么可以考慮使用Item CF,比如購物網站,因其物品的資料相對穩定,因此計算物品的相似度時不但計算量較小,而且不必頻繁更新;
User CF更適合做新聞、博客或者微內容的推薦系統,因為其內容更新頻率非常高,特別是在社交網路中,User CF是一個更好的選擇,可以增加用戶對推薦解釋的信服程度,
總結:即如果人流量太大,考慮ItemCF,可以減少計算量;如果物流量太大,考慮UserCF,同樣也是減少了計算量,
五.人工智能實踐程序分為三個步驟:資料,學習與決策,
因此,有了評分矩陣后,我們便可以預測決策了,
例如:某個用戶喜歡圖書1,那我們怎么才能知道該不該向他推薦圖書二或其他書呢?這里我介紹兩種方法:
一.根據相似度預測評分來推薦物品
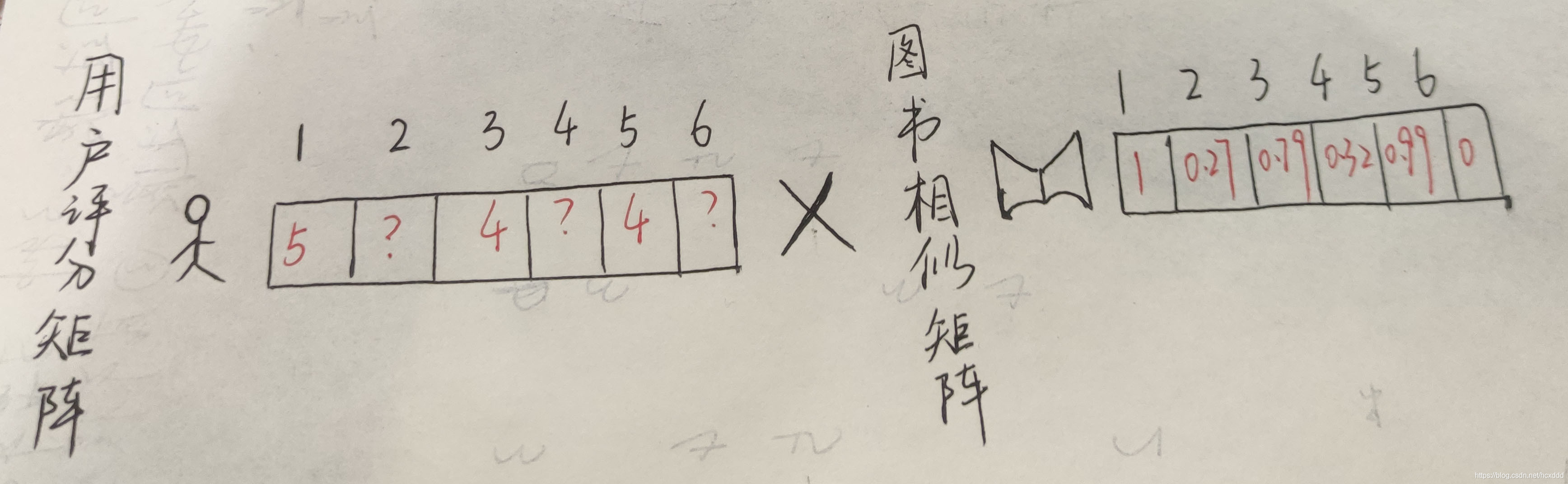
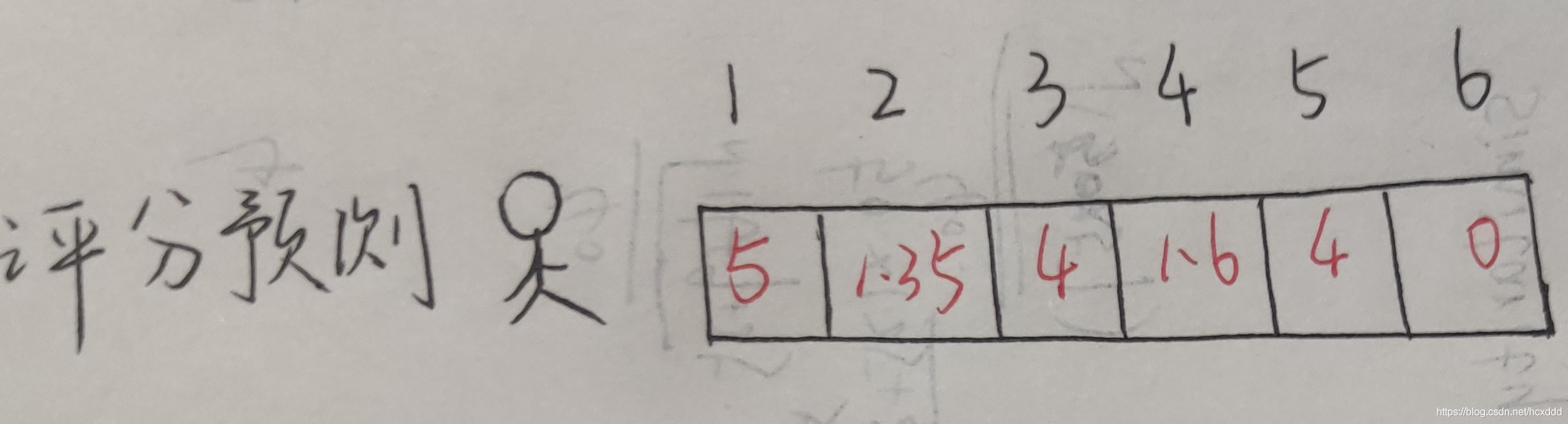
即通過將用戶評分矩陣與圖書相似矩陣進行乘積來獲得最后的評分預測,評分越高,推薦的可信度就越大;同理,評分越低,推薦的可信度就越小,
二.根據相似度排序推薦物品
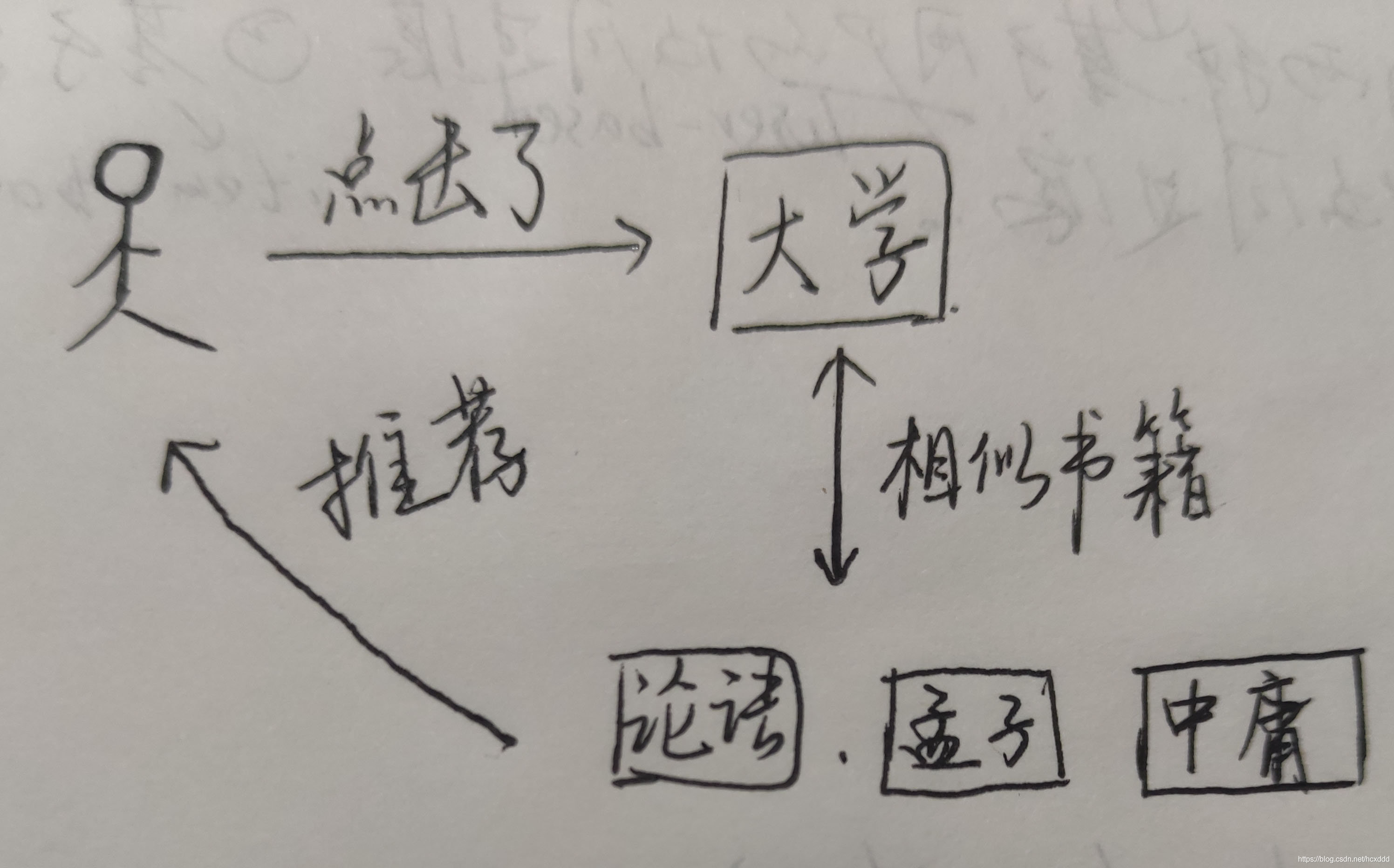
即用戶看了大學這本書,然后我們發現與其類似的論語等書,便可根據相似度向用戶推薦,
補充:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282834.html
標籤:AI
上一篇:余弦定理和新聞的分類
下一篇:2021華東杯數學建模賽題思路