前言
本文為筆者學習圖靈系列程式設計叢書的《面向資料科學家的使用統計學》的一些感悟和總結,本文撰寫主要參考了該書目,希望本文對接觸,學習和研究資料科學的各位能有所幫助,
首先,第一篇介紹探索性資料分析(EDA)的相關內容,
目錄
- 前言
- 1.什么是結構化資料
- 2.矩形資料
- 3.位置估計
- 4.變異性估計
- 5.探索資料分布
- 5.1 百分位數和箱形圖
- 5.2 頻數表和直方圖
- 5.3 密度估計
- 6.探索分類資料
- 6.1 眾數和期望值
- 6.2 條形圖和餅圖
- 7.相關性
- 7.1 相關系數
- 7.2 相關矩陣
- 7.3 散點圖
- 8.探索多個變數
- 8.1 雙變數分析的可視化
- 8.1.1 六邊形圖、等勢線和熱力圖
- 8.1.2 箱形圖和小提琴圖
- 8.2 多個變數的可視化
- 后記
1.什么是結構化資料
在現代,尤其是這個大資料時代,我們獲取資料的途徑非常豐富,各種儀器(例如各種傳感器)的測量值、事件、文本、影像和視頻等都屬于可獲取的資料來源,整個物聯網無時無刻不在涌出大量的資訊流,如何將這些大量的原始資料轉化為可操作的資訊,這才是當今資料科學所面對的主要挑戰,首先,就需要將非結構化的原始資料結構化,或是處于研究目的采集有效資料集,
結構化資料有兩種基本型別:數值型資料(numeric data)和分類資料(categorical data),其中,數值型資料還分為連續型和離散型兩種形式,連續型資料又稱區間資料和浮點型資料,即表示該資料可在一個區間內取任何值;離散型資料通常只能取整數,例如計數,所以一般又稱計數型資料,分類資料(因子資料)只能從特定集合中取值,這些值表示這種資料一系列可能的分類,例如:計算機編程語言主要包括匯編語言、機器語言以及高級語言三種(類別);中國的直轄市有北京市,上海市,天津市和重慶市,二元資料是一種特殊的分類資料,資料值只能從兩個之中取其一(例如0或1,True或False),也就是一般所稱的布爾型資料和邏輯性資料,有序資料(有序因子資料)是具有明確排序的分類資料,例如數值排序(1,2,3,4或5),
注:連續型資料和離散型資料的區別:1.離散型變數是通過計數方式取得的,即是對所要統計的物件進行計數,增長量非固定的;連續型變數不是單獨的整十整百的數字,其包含若干位小數且取值密集,增長量可以劃分為固定的單位,2.域不同,離散型變數:離散型變數的域(即物件的集合)是離散的;連續型變數的域(即物件的集合)是連續的,3.分組方式不同,離散型變數:如果變數值的變動幅度小,就可以一個變數值對應一組,稱單項式分組,如果變數值的變動幅度很大,變數值的個數很多,則把整個變數值依次劃分為幾個區間,各個變數值則按其大小確定所歸并的區間,區間的距離稱為組距,這樣的分組稱為組距式分組,在組距式分組中,相鄰組既可以有確定的上下限,也可將相鄰組的組限重疊,連續型變數:連續型變數由于不能一一列舉其變數值,只能采用組距式的分組方式,且相鄰的組限必須重疊,
- 我們為什么要關心資料型別的分類呢?
首先,資料型別對于確定可視化型別、資料分析或統計模型是非常重要的,再者,更為重要的是,變數的資料型別決定了軟體處理變數計算的方法, - 因子資料或說有序因子資料也只是一組文本值或數值,那么為什么我們也需要在資料分析種明確提出它們的概念呢?
相比于文本表示,將資料顯示地標識為因子資料具有如下優點: - 如果我們明確輸入的是分類資料,那么軟體就可以據此確定統計程序的作業方式,例如圖表生成或模型擬合,
- 可以優化存盤或索引,
- 限定了給定分類變數在軟體中的可能取值,例如列舉型別,
總結:
- 在軟體中,資料通常按型別分類,
- 資料型別包括連續型資料、離散型資料、分類資料和有序資料,
- 資料分類為軟體指明了資料的處理方式,
2.矩形資料
矩形資料物件是資料科學分析中的典型參考結構,矩形資料物件包括電子表格、資料庫表等,
矩形資料本質上是一個二維矩陣,通常稱資料表中的一行為一條記錄(事例、樣本),一列為一個特征(屬性、變數),資料并非一開始就是矩陣形式的,非結構化資料必須先經過處理和操作才能表示為矩陣資料形式,
除了矩形資料之外,還有一些其它型別的資料:例如:時序資料,空間資料和圖形(或網路)資料,(此處的空間和圖形同矩形一樣,均指一種資料結構,)
3.位置估計
面對大量資料的記錄和特征,對它們有一個大致的了解,即總結資料特征的特性是很有必要的,其中,探索資料的一個基本步驟就是獲取每個特征的“典型值”,典型值是指對資料最常出現位置的估計,即資料的集中趨勢,
平均值(mean),是最基本的位置估計量,它等于所有值的和除以值的個數,給出計算公式:
x
ˉ
=
Σ
i
=
1
n
x
i
n
\bar x=\frac{\Sigma_{i=1}^n x_i} n
xˉ=nΣi=1n?xi??
對于某些資料集,我們需要對值賦予權重,進行位置估計時便需取加權均值(weighted mean),它等于加權值的總和除以權重的總和,給出計算公式:
x
ˉ
w
=
Σ
i
=
1
n
w
i
x
i
Σ
i
=
1
n
w
i
\bar x_w=\frac{\Sigma_{i=1}^n w_ix_i}{\Sigma_{i=1}^n w_i}
xˉw?=Σi=1n?wi?Σi=1n?wi?xi??
均值雖然易于計算且方便使用,但在資料集中有離群值(極值)影響時便無法較為準確地進行位置估計,此時,中位數(median)是更好的選擇,中位數是位于有序資料集中間位置的數值,是對位置更為穩健的估計量,但不同于使用所有觀測值計算得到的均值,中位數僅取決于有序資料集中間位置處的值,與加權均值相似,加權中位數(weighted median)也有廣泛的應用,它使得排序資料集中分別有一半的權重之和位于該值之上或之下,
若想盡可能使用所有觀測值對位置有一個較為穩健的估計,我們可以使用切尾均值(trimmed mean),它是指在資料集剔除一定數量的極值后再求均值,這樣就能消除極值對均值的影響,例如在國際體育賽事中,通常會去掉一個最高分和一個最低分,就是使用了切尾均值,給出計算公式:
x
ˉ
=
Σ
i
=
p
+
1
n
?
p
x
i
n
?
2
p
\bar x=\frac{\Sigma_{i=p+1}^{n-p} x_i}{n-2p}
xˉ=n?2pΣi=p+1n?p?xi??
對于小規模的資料集,還有很多其他更為穩健和高效的位置估計量,在此不做介紹,
4.變異性估計
位置只是總結特性的一個維度,另一個維度是變異性(variability),也稱離差(dispersion),它是資料集關于某個中心值偏離或散布的離散程度的一種標志,測量了資料值是緊密聚集的還是發散的,使用最廣泛的變異性估計量是基于位置估計值和觀測資料值之間的偏差(deviation)或者說殘差(residual),在這里,給出多種計算偏差的方式,
首先是平均絕對偏差(mean absolute deviation),即對資料值和均值之間的偏差的絕對值計算均值,給出公式:
平
均
絕
對
偏
差
=
Σ
i
=
1
n
∣
x
i
?
x
ˉ
∣
n
?
2
p
平均絕對偏差=\frac{\Sigma_{i=1}^n \lvert x_i-\bar x \rvert}{n-2p}
平均絕對偏差=n?2pΣi=1n?∣xi??xˉ∣?
更廣為人知的變異性估計量是方差(variance)和標準偏差(standard deviation),它們基于偏差的平方,方差是偏差平方值的均值,而標準偏差是方差的平方根,給出公式:
方
差
=
s
2
=
Σ
(
x
?
x
ˉ
)
2
n
?
1
方差=s^2=\frac{\Sigma (x-\bar x)^2}{n-1}
方差=s2=n?1Σ(x?xˉ)2?
標
準
偏
差
=
s
=
Σ
(
x
?
x
ˉ
)
2
n
?
1
標準偏差=s=\sqrt\frac{\Sigma (x-\bar x)^2}{n-1}
標準偏差=s=n?1Σ(x?xˉ)2?
?
注:在統計模型中,使用平方值比使用平均值更為方便,所以標準偏差比平均絕對偏差使用更為廣泛,而式中使用除數n-1是因為我們使用自由度進行無偏估計,
無論是方差,標準偏差還是絕對平均偏差對離群值都是不穩建的,尤其是方差和標準偏差對極值更為敏感,為此,我們提出更為穩健的變異性估計量,中位數絕對偏差(median absolute deviation),通常簡寫為MAD,給出計算公式:
M
A
D
=
中
位
數
(
∣
x
1
?
m
∣
,
∣
x
2
?
m
∣
,
…
,
∣
x
n
?
m
∣
)
MAD=中位數(\lvert x_1-m \rvert,\lvert x_2-m \rvert,…,\lvert x_n-m \rvert)
MAD=中位數(∣x1??m∣,∣x2??m∣,…,∣xn??m∣)
我們還可以參考切尾均值計算切尾標準偏差,
注:即使資料符合正態分布,方差、標準偏差、平均絕對偏差以及中位數絕對偏差也并非是等價的估計量,事實上,標準偏差總是大于平均絕對偏差,而平均絕對偏差總是大于中位數絕對偏差,有時,中位數絕對偏差會乘上一個常數比例因子(通常是1.4826),使得在正態分布下,中位數絕對偏差與標準偏差具有相同的尺度,
另一種估計離差的方法基于對有序資料分布情況的查看,其中最基本的是測量極差(range),或稱為全距,但極差對離群值非常敏感,為避免這種情況,我們可以洗掉有序資料兩端的值,然后再查看資料的極差,即估計百分位數(percentiles)之間的差異,其中常用的測量方法是估計第25分位數和第75分位數之間的差值,稱為四分位距(interquartile range, IQR),在此不做過多介紹,
5.探索資料分布
5.1 百分位數和箱形圖
百分位數對于總結資料的整體分布十分有用,四分位數和十分位數有著廣泛的應用,尤其是在總結資料尾部情況(外延范圍)時,百分位數十分有用,
箱形圖(boxplot)是一種快速可視化繪圖,它基于百分位數來可視化資料的分布,能顯示出一組資料的最大值、最小值、中位數、及上下四分位數,
import numpy as np
import pandas as pd
data=pd.Series(np.arange(0,16)).append(pd.Series(25))
data.plot(kind='box')
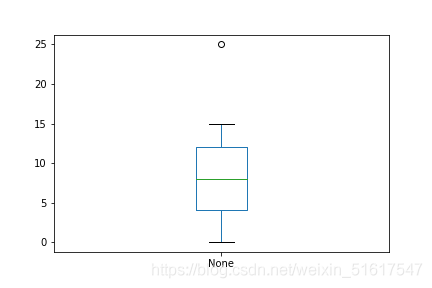
使用python繪出一個簡單的箱形圖,其中,箱子的頂部和底部分別是第75百分位數和第25百分位數,箱內的水平線表示的是中位數,從箱頂或箱底延伸的線段稱為須(whisker),須從最大值一直延伸到最小值,顯示了資料的極差,而箱外的圈(或說點)表示的則是離群值,
5.2 頻數表和直方圖
變數(特征)的頻數表可以將該變數的極差均勻地分割為多個等距分段,并給出落在每個分段中地數值個數,
import numpy as np
import pandas as pd
data=pd.Series(np.random.rand(10))
data.plot(kind='hist')
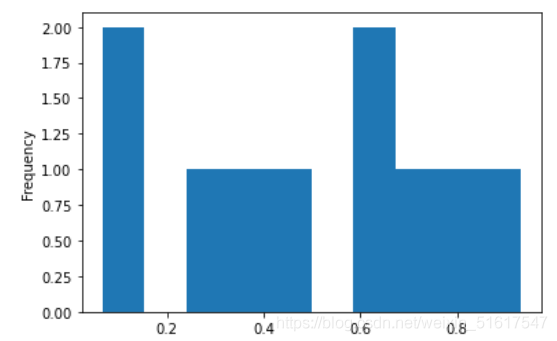
使用python繪出一個簡單的直方圖,可以觀察到其中有兩個組距是空的,添加空組距也是有必要的,空組距中沒有值通常是很有價值的資訊,嘗試不同大小的組距也是非常有用的,如果組距過大,可能就會隱藏掉分布的一些重要特性;如果組距過小,那么結果就會過于顆粒化,失去查看整體圖的能力,
繪制直方圖需注意:1.空組距也應在直方圖中,2.各組距是相等的,3.組距的數量(或組距的大小)是自定的,4.各條塊相互緊鄰,條塊間沒有任何空隙,除非存在空組距,
注:頻數表和百分位數都是通過創建組距總結資料,一般情況下,四分位數和十分位數在每個組距中具有相同的計數,但每個組距的大小不同,將其稱之為等計陣列距,相反地,頻數表中每個組距的大小相同,但其中的計數可以不同,將其稱之為等規模組距,
統計學中的矩(moment):在統計學理論中,位置和變異性分別稱為分布的一階矩和二階矩,而分布的三階矩和四階矩分別被稱為偏度(skewness)和峰度(kurtosis),偏度顯示了資料是偏向較小的值還是較大的值;峰度則顯示了資料中具有極值的傾向性,通常情況下,我們不使用度量去測定偏度和峰度,而是通過可視化方法來發現他們,
5.3 密度估計
密度圖用一條連續的線顯示資料值的分布情況,可以將密度圖看作由直方圖平滑得到的,盡管它通常是使用一種核密度估計量從資料中直接計算得到的,
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.Series(np.random.normal(0, 1, 1000))
plt.figure()
plt.subplots_adjust(wspace=0.2)
plt.subplot(1,2,1)
data.plot(kind='hist',bins=14,density=True)
data.plot(kind='kde')
plt.xlim(-4,4)
plt.subplot(1,2,2)
data.plot(kind='kde')
plt.xlim(-4,4)
plt.rcParams['figure.figsize']=(12.0,4.0)
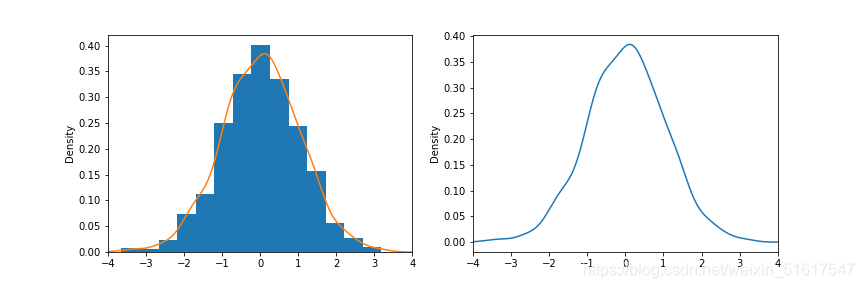
使用python繪出一個正態分布數值集的密度圖和直方圖的情況,可清晰的看出核密度圖與直方圖之間的關系,而當資料量越大時,核密度圖和直方圖平滑得到的曲線越相似,
data=pd.Series(np.random.normal(0, 1, 100)) #右圖為data=pd.Series(np.random.normal(0, 1, 10000))
y=data.plot(kind='hist',bins=14,density=True,alpha=0.3,label='hist')
data.plot(kind='kde',label='kde')
plt.plot(np.arange(-3.6,4,0.4)-0.2,frequency_each,label='hist_line')
plt.xlim(-4,4)
plt.legend()
plt.show()
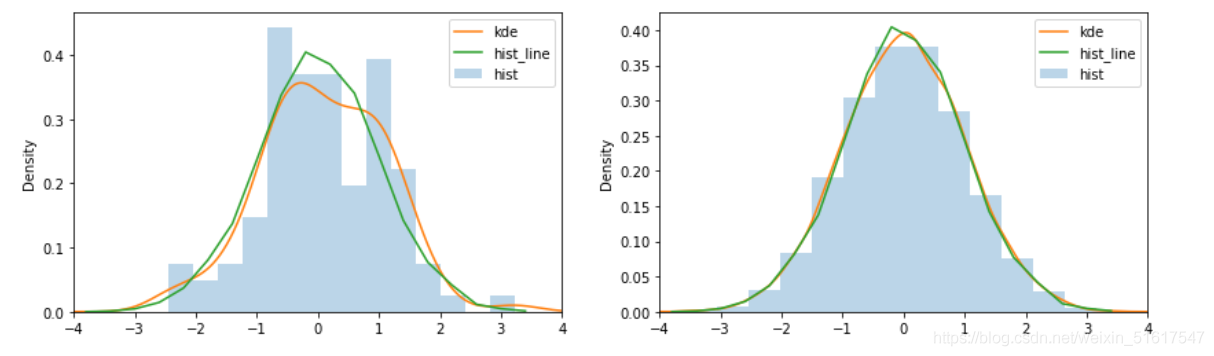
如圖,分別為選取100個資料和10000個資料核密度圖與取直方圖組距中點的值得到的平滑曲線擬合的情況,
6.探索分類資料
6.1 眾數和期望值
眾數是資料集中出現次數最多的類別或值,是分類資料的一個基本匯總統計量,通常不用于數值型資料,
有些資料類別可以表示成或映射到同一尺度的離散值,也就是可以與一系列的數值相關聯,那么就可以根據類別出現的概率計算出一個平均值,稱之為期望值,它是一種加權均值,權重使用的是類別出現的概率,
6.2 條形圖和餅圖
條形圖和餅圖是常用來可視化分類資料的方法,條形圖以條形表示每個類別出現的頻數或占比情況,餅圖是條形圖的一種替代形式,以圓餅中的一個扇形部分表示每個類別出現的頻數或占比情況,
要特別注意的是,雖然條形圖與直方圖非常相似,但二者之間仍存在著一些差異,在條形圖中,x軸表示因子變數的不同類別,而在直方圖中,x軸以數值度量的形式表示某個變數的值,另外,在直方圖中,通常各個條形是相互緊鄰的,條形間的間隔表示空組距(即資料中未出現的值),而在條形圖中,各個條形的顯示是相互獨立的,
data=pd.Series(np.random.randint(1,11,20))
data.plot(kind='bar')
data.plot(kind='pie')
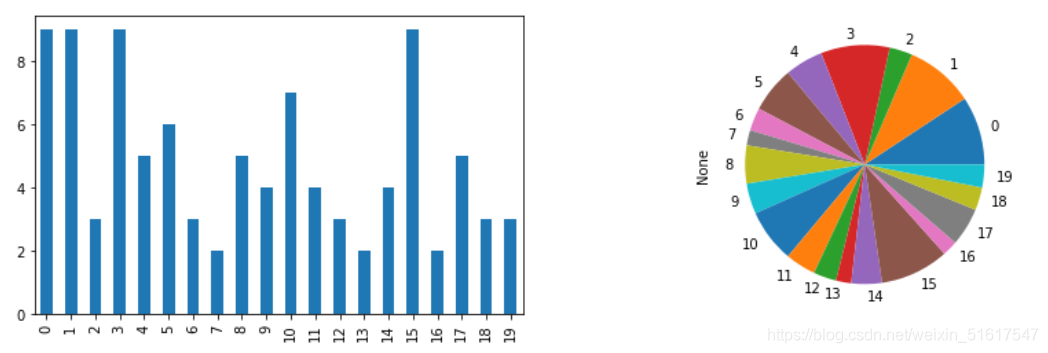
使用python繪出一些離散變數的條形圖和餅圖,
7.相關性
相關性,是指兩個變數的關聯程度,無論是在資料科學還是研究中,很多建模專案的探索性資料分析都要檢查預測因子之間的相關性,以及預測因子和目標變數之間的相關性,
如果一個變數的高值隨另一個變數的高值的變化而變化,并且它的低值隨另一個變數的低值的變化而變化,那么稱這兩個變數正相關,如果一個變數的高值隨另一個變數的低值的變化而變化,且反之亦然,那么稱這兩個變數負相關,如果一個變數的變化對另一變數沒有明顯影響,那么稱這兩個變數不相關,
首先介紹三個重要概念:
- 相關系數(Correlation coefficient):一種標準化的度量,用于測量數值變數之間的相關程度,取值范圍在-1(完全負相關)和+1(完全正相關)之間,若其值為0,則表示兩個變數之間沒有相關性,需注意,資料的隨機排列將會隨機生成正的或負的相關系數,
- 相關矩陣(Correlation Matrix):將變數在一個表格中按行和列顯示,表格中每個單元格的值是對應變數之間的相關性,
- 散點圖(scatter-plot):在繪圖中,x軸表示一個變數(特征)的值,y軸表示另一個變數的值,可以反映出y隨x的變化而變化的大致趨勢,
7.1 相關系數
皮爾遜相關系數公式:
r
=
Σ
i
=
1
N
(
x
i
?
x
ˉ
)
(
y
i
?
y
ˉ
)
(
n
?
1
)
s
x
s
y
r=\frac{\Sigma_{i=1}^ N{(x_i-\bar x)(y_i-\bar y)}}{(n-1)s_xs_y}
r=(n?1)sx?sy?Σi=1N?(xi??xˉ)(yi??yˉ?)?
當變數的相關性是非線性的時候,相關系數就不再是一種有用的度量,此時需計算非線性相關系數來對變數的相關性來做出判斷,而反映一個因變數與一組自變數(兩個或兩個以上)之間相關程度的指標稱為復相關系數,在此不做過多介紹,
7.2 相關矩陣
在可視化方法上,我們可以使用熱力圖(見8.1.1)來可視化相關矩陣,
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
from pyforest import *
wine=pd.read_csv('wine.csv')
corr = wine.corr() #相關矩陣計算方法
fig, ax = plt.subplots(figsize=(16, 12))
ax = sns.heatmap(corr,square=True,ax=ax,annot=True)
ax.set_title('Correlation coefficient')
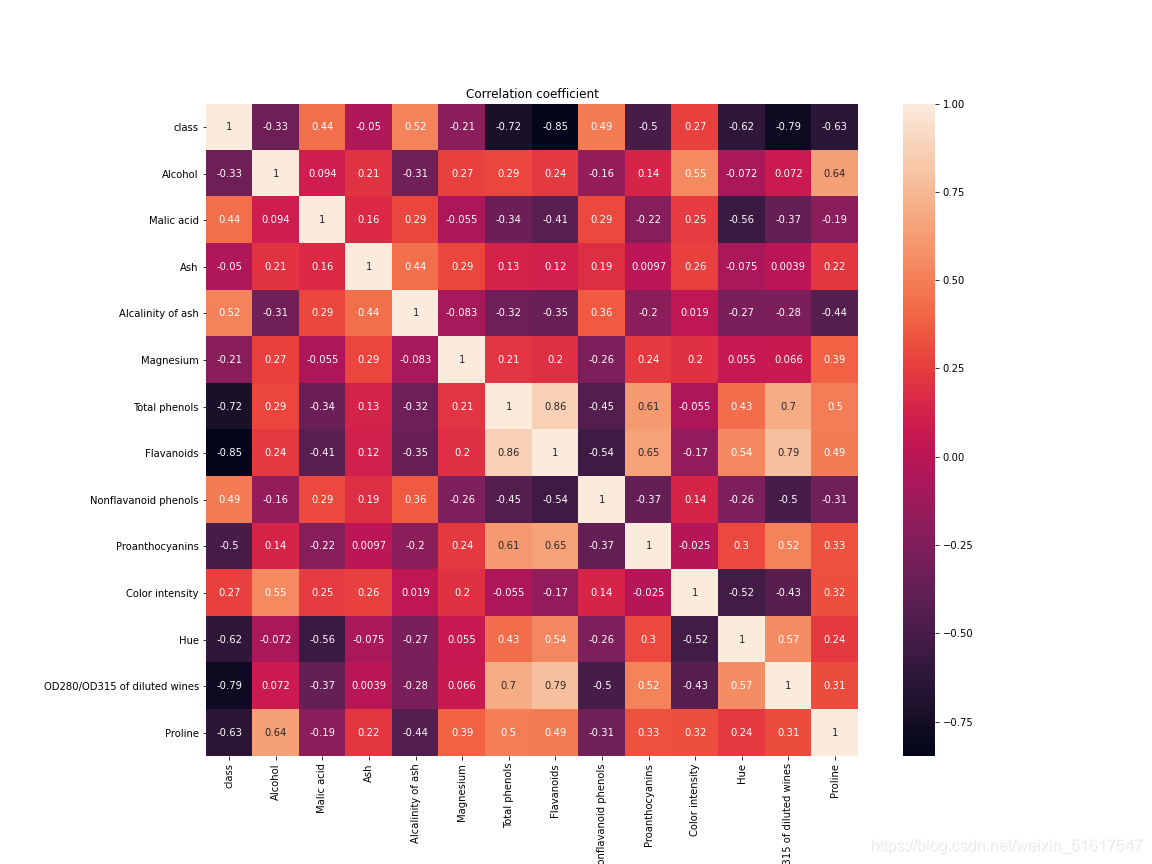
以sklearn庫中的wine資料集(筆者使用時已將資料集匯入到了csv檔案中)為例,計算該資料集各變數(特征)之間的相關系數,
7.3 散點圖
散點圖是一種可視化兩個測量資料變數間關系的標準方法,在散點圖中,x軸表示一個變數,y軸表示另一個變數,圖中的每個點對應于一條記錄,
plt.scatter(wine.Alcohol,wine.Proline)
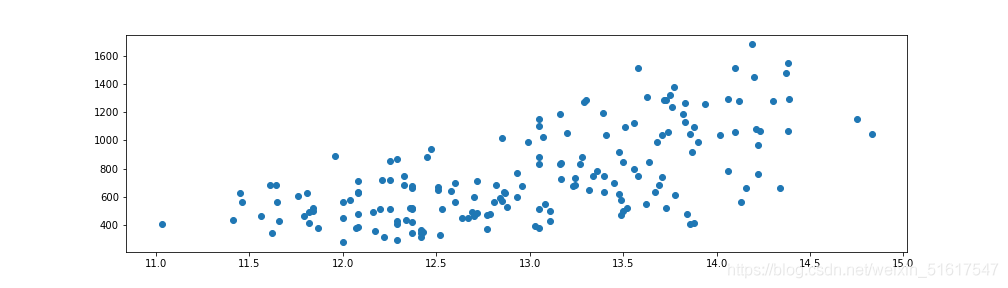
再以wine資料集中Alcohol與Proline兩列為例繪出散點圖,
8.探索多個變數
對一個變數進行分析稱為單變數分析;對兩個變數及其關系進行分析稱為雙變數分析,例如(線性)相關性分析;而對兩個以上的變數進行分析稱為多變數分析,與單變數分析一樣,雙變數分析不僅計算匯總統計量,而且生成可視化的展示,雙變數或多變數分析的適用型別取決于資料本身,即資料是數值型資料還是分類資料,
8.1 雙變數分析的可視化
多個變數的分析與可視化完全可以由雙變數分析加上條件(conditioning)這個概念擴展得到,所以首先介紹幾種關于兩種變數的可視化方法,它們有六邊形圖、等勢線、熱力圖、箱形圖、小提琴圖等,事實上,這些可視化方法本質上對應的都是直方圖和密度圖,
8.1.1 六邊形圖、等勢線和熱力圖
六邊形圖、等勢線和熱力圖均適用于兩個數值型變數,它們所給出的都是二維密度的可視化表示,現再以wine資料集為例使用python實作可視化,簡單地展示三種影像,
plt.hexbin(wine.Alcohol,wine.Proline,gridsize=30,cmap='Blues')
plt.colorbar()
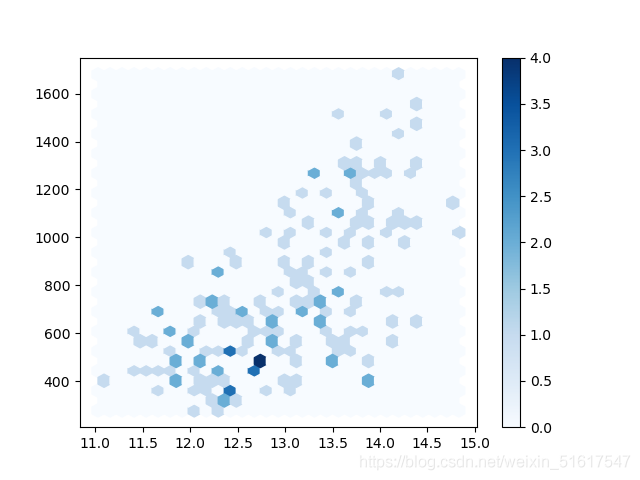
六邊形圖繪制的并非資料點,而是將記錄(樣本)分組為六邊形的組距,并用不同的顏色繪制各個六邊形,以顯示每組中的記錄數,
wine_AP=wine.loc[:,['Alcohol','Proline']]
sns.kdeplot(wine_AP)
plt.scatter(wine['Alcohol'],wine['Proline'])
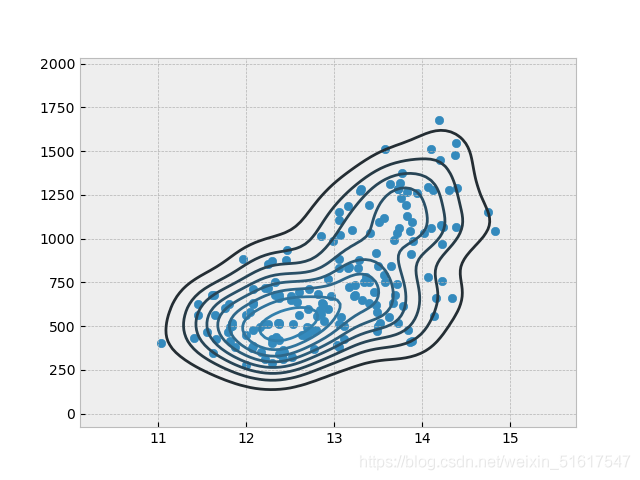
上圖在散點圖上繪制了一個等勢線圖(二維密度圖),可視化了兩個數值型變數之間的關系,等勢線在本質上就是兩個變數的地形圖,每條等勢線表示特定的密度值,并隨著接近“頂峰”而增大,
wine_AP.set_index('Alcohol',inplace=True)
wine_AP_part=wine_AP.iloc[0:10]
sns.heatmap(wine_AP_part)
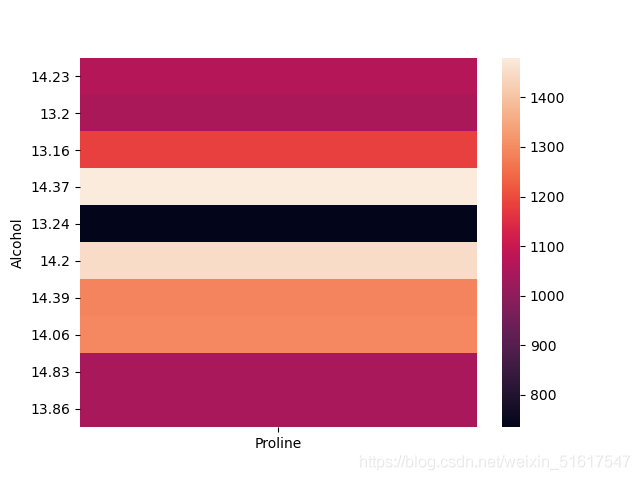
當然,一種可視化方法可以有多種用途,例如熱力圖還可以展現兩個離散變數之間的組合關系或進行分類變數中數值型資料的相關性分析等,
8.1.2 箱形圖和小提琴圖
一些數值型資料是根據分類變數進行分組的,或者要同時比較多個變數的分布,可視化這類資料通常使用箱形圖或小提琴圖,
wine_BV=wine.loc[:,['Malic acid','Total phenols','Flavanoids','Proanthocyanins','Hue']]
sns.boxplot(data=wine_BV)
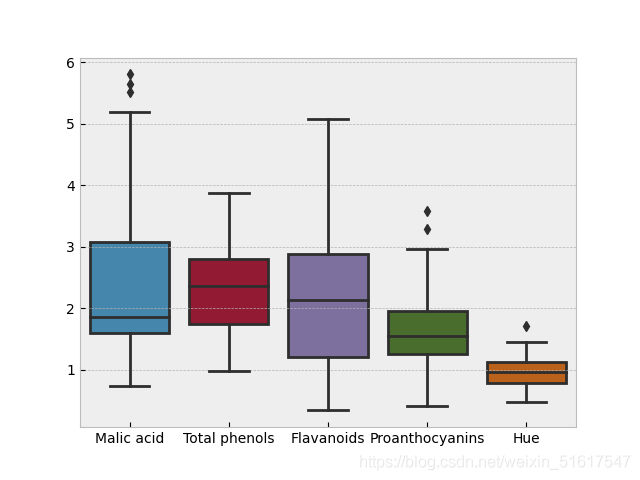
箱形圖可以很直觀的比較不同類別的(或不同特征的)資料分布,
sns.violinplot(data=wine_BV)
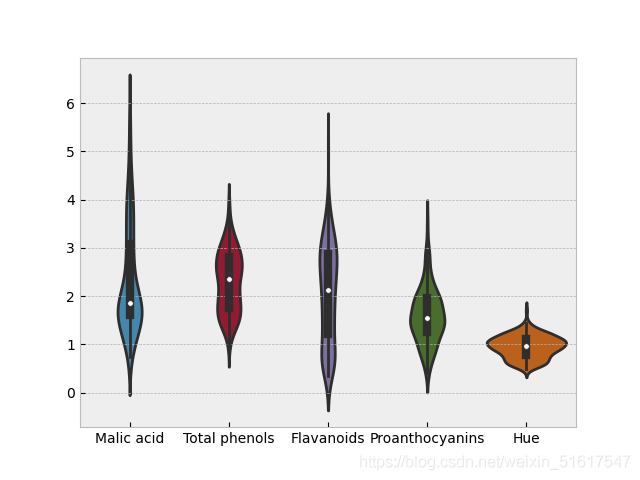
小提琴圖是箱形圖的一種增強表示,它以y軸為密度來繪制密度估計量的情況,繪圖中對密度做鏡像并反轉(即核密度函式),并填充所生成的形狀,由此生成了一個類似小提琴的圖形,
sns.violinplot(data=wine_box,inner='quartile')
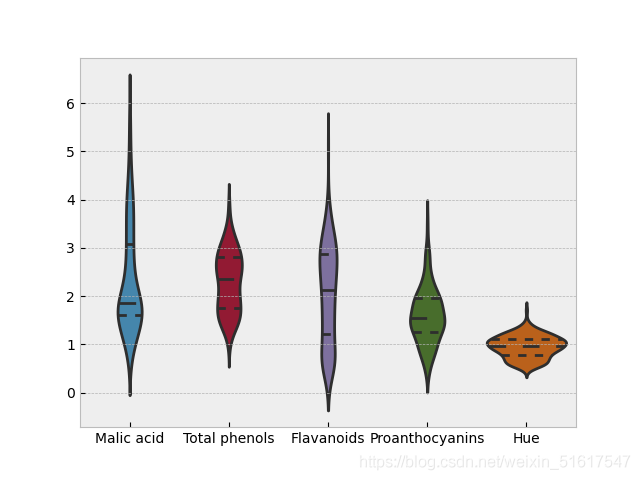
如果規定inner=‘quartile’,那么繪出的小提琴圖相當圖結合了箱形圖,在某些情況下會有更好的效果,
8.2 多個變數的可視化
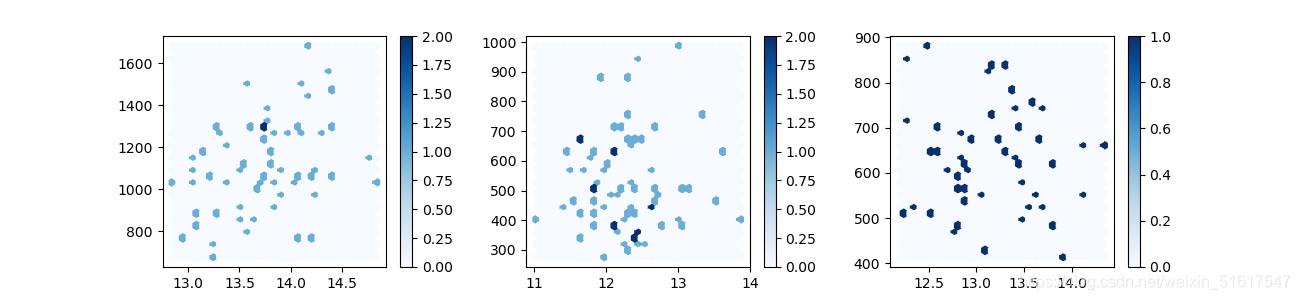
例如可視化上述資料集wine_AP(取特征Alcohol,Proline)時加入條件分別可視化不同等級(wine中的特征class,class=1,2,3)的資料,這就變成了一個多變數分析的可視化問題,我們通過建立多個子圖來對比它們,例如:
wine_class1=wine.loc[wine['class']==1]
wine_class2=wine.loc[wine['class']==2]
wine_class3=wine.loc[wine['class']==3]
plt.figure()
plt.subplots_adjust(wspace=0.3)
plt.subplot(1,3,1)
plt.hexbin(wine_class1.Alcohol,wine_class1.Proline,gridsize=30,cmap='Blues')
plt.colorbar()
plt.subplot(1,3,2)
plt.hexbin(wine_class2.Alcohol,wine_class2.Proline,gridsize=30,cmap='Blues')
plt.colorbar()
plt.subplot(1,3,3)
plt.hexbin(wine_class3.Alcohol,wine_class3.Proline,gridsize=30,cmap='Blues')
plt.colorbar()
plt.rcParams['figure.figsize']=(13,3)
后記
到這里,對于探索性資料分析的簡要介紹就結束了,對于任意基于資料的專案,最重要的第一步都是查看資料,這正是探索性資料分析的關鍵理念所在,通過總結并可視化資料,我們可以對專案獲得有價值的洞悉和理解,從位置估計和變異性估計等簡單度量,到探索多個變數之間的關系,我們可以借助各種技術和工具并結合python這樣的語言強大的表達能力來建立豐富多樣的資料探索和分析方式,
在最后,希望本文能夠幫助到閱讀的各位,也請大家多多關注,筆者會在后續介紹更多有關資料科學的內容以及使用python等語言進行資料分析的方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282843.html
標籤:AI