《例外檢測——從經典演算法到深度學習》
- 0 概論
- 1 基于隔離森林的例外檢測演算法
- 2 基于LOF的例外檢測演算法
- 3 基于One-Class SVM的例外檢測演算法
- 4 基于高斯概率密度例外檢測演算法
- 5 Opprentice——例外檢測經典演算法最終篇
- 6 基于重構概率的 VAE 例外檢測
- 7 基于條件VAE例外檢測
- 8 Donut: 基于 VAE 的 Web 應用周期性 KPI 無監督例外檢測
- 9 例外檢測資料匯總(持續更新&拋磚引玉)
- 10 基于條件 VAE 的魯棒無監督KPI例外檢測
- 11 針對大量出現的KPI流快速部署例外檢測模型
- 12 對復雜 KPI 基于VAE對抗訓練的非監督例外檢測
12 對于復雜 KPI 基于VAE對抗訓練的非監督例外檢測
2019 Unsupervised Anomaly Detection for Intricate KPIs via Adversarial Training of VAE
下載地址
一直在糾結有沒有必要這么這么地翻譯一遍,是否有意義,是否真的有人會讀,所以從這篇論文開始,去除了一些套話,盡可能更加突出重點,
Abstract
為了保證互聯網應用服務的可靠性,我們需要實時地密切監測 KPIs,并必須及時發現 KPIs 中隱藏的例外,盡管對于周期性光滑的業務級別的 KPIs (例如每分鐘的交易次數) 的例外檢測在文獻中已經被合理地解決了,但是機器級別的 復雜的 KPIs(例如一個被檢測的服務每秒的 I/O 請求數)很少研究,這些復雜的 KPIs 既普遍又重要,但是它們呈現的是非高斯分布、很難建模的資料分布,本文中,我們提出了一個基于區域分析的貝葉斯網路的對抗性訓練方法,這種方法具有堅實的理論證明,基于這個方法,我們提出了第一個針對于復雜的 KPIs的高性能無監督例外檢測演算法 Buzz,在來自一家全球互聯網公司的資料中它的 最優 F-score 范圍在0.92到0.99之間,顯著優于基于最先進VAE的無監督方法(無對抗性訓練)和最先進的有監督方法,
I. Introduction
略去前面一部分與 Abstract 基本重合的部分
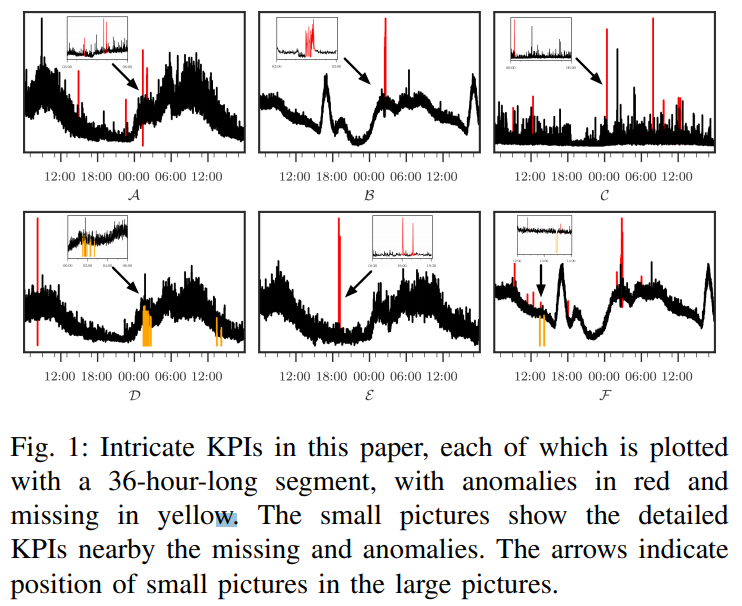
圖 1 展示了幾個這類的 KPI,Opprentice[3](最先進的監督方法)和Donut [4] (一種基于變分自動編碼器(VAE)的先進無監督方法)性能不佳,將在第5節展示,
Buzz 有幾個關鍵idea,首先,為了使不可分割的 KPI 模型易于處理,我們采用了度量理論中常用的分析方法,具體而言,我們將資料空間切分為若干個子空間(隔離的),其次,在計算距離時,我們使用了生成分布和經驗分布之間的Wasserstein距離[6],這在 WGAN[6] 中已經被證明是分布空間中的一個穩健(robust)度量,
第三,我們提供理論推導,提出了一種訓練目標的基本形式,然后將我們的模型轉化為貝葉斯網路,特別是,Buzz 通過對抗訓練,從本質上優化了 VAE 中變分的最低證據界(ELBO) 似然,第四,我們使用 VAE 作為生成模型來生成樣本,并使用另外一種神經網路作為判別模型來識別生成的樣本和真實樣本,第五,為了保證對抗訓練穩定,我們調整了梯度懲罰技術[7],一種從 WGAN[6] 的基本訓練的改進技術,最后,例外檢測是采用變分推斷來完成的,
Buzz 的 contribution 總體如下:
- Buzz 是針對于復雜 KPIs 的第一個通過深度生成模型無監督例外檢測演算法,在全球頂級公司的資料中,Buzz 的最優 F-score 在 0.92 到 0.99 之間,顯著優于現有方法,
- Buzz 提出的訓練方法是第一種基于磁區的VAE對抗性訓練方法理論推導與實驗分析相結合,
- 基于磁區分析,我們提出了一種基于 Wasserstein 距離的 Buzz 訓練目標的初始形式,并給出了將該模型轉化為貝葉斯網路的理論推導,在貝葉斯網路和最優運輸理論之間架起橋梁是一種新的思路,
2. Background
A. KPI Anomaly Detection
一個 KPI 是一個時間序列,可以標記為: X = { x 1 , x 2 , . . . , x T } X=\{x_1,x_2,...,x_T\} X={x1?,x2?,...,xT?},其中 x t x_t xt? 是指對應 t t t 時刻的值, t ∈ { 1 , 2 , . . , T } t\in\{1,2,..,T\} t∈{1,2,..,T},
基于 KPI 的例外檢測即給定最近的 W W W 個資料點,來判定 x t x_t xt? 是不是例外,如果是例外的話, α t = 1 \alpha_t=1 αt?=1,例外檢測演算法通常計算條件概率, P ( α t = 1 ∣ X t ? W + 1 , . . . , x t ) P(\alpha_t=1|X_{t-W+1},...,x_t) P(αt?=1∣Xt?W+1?,...,xt?),而不是直接給定 α t \alpha_t αt? 的值,因此,基本上任何 KPI 例外檢測蘇阿帆需要對條件概率進行一些建模,
B. Intricate KPIs
本文中,我們注重對復雜 KPIs 的例外檢測, KPIs 大概分為兩類:周期性光滑 KPIs 和 復雜 KPIs,前者一般是基于服務/業務層的分析(比如每分鐘的交易數目),我們可以粗略地假設這些 KPI 具有對角多元高斯噪聲(diagonal multivariate Gaussian noises),為了捕捉突發流量(例如,典型的資料庫流量)引起的微擁塞,經常復雜 KPIs 進行細粒度監控,我們可以粗略地假設復雜 KPIs 中的噪聲不是對角多元高斯噪聲,
圖1 展示了一些復雜 KPIs 例子,可以看到,復雜的 KPIs 是復雜的,在短時間尺度上劇烈抖動,但在全球范圍內似乎有一些模式,此外,不同的復雜 KPIs 可以具有不同的全域和區域模式,因此,精確定義復雜的 KPIs 或列舉不同型別的復雜 KPIs 具有挑戰性,因此,設計一個框架并測驗所有復雜的 KPIs 是很難的,因此,在本文中,我們將重點放在復雜的關鍵績效指標,我們反擊,并在實踐中很重要,更具體地說,我們從一家具有手動例外標簽的大型互聯網公司獲得 11 個維護良好的復雜 KPIs,圖1 顯示了其中的一部分,它們代表了一系列重要、實用和復雜的 KPIs,與我們合作的操作人員證實,解決這些復雜的 KPIs 例外檢測問題具有迫切的現實意義,
C. Previous Anomaly Detection Approaches
多年來,人們提出了許多基于傳統統計模型的例外檢測器,如 [8] 等人 [9]-[14],但演算法選擇和引數調整需要在每個 KPI 的基礎上進行,它們無法在復雜的 KPIs 中捕獲復雜的資料分布,
最近的方法使用了有監督集成學習和上述檢測器作為特征,如 EGADS[15] 和 Opprentice [3],并在平滑 KPI 上顯示了有希望的結果,但是,它們的標記開銷太大,并且它們的特征(來自傳統統計模型)不適合復雜的 KPI,
無監督例外檢測方法,如 [16]-[20] 學習獲取正常資料模式并推導條件概率 P ( α t = 1 ∣ x t ? w + 1 , x t ? W + 2 , . . . , x t ) P(\alpha_t=1|x_{t-w+1}, x_{t-W+2},...,x_{t}) P(αt?=1∣xt?w+1?,xt?W+2?,...,xt?),通過假設例外,例如例外的可能性可以忽略不計,Donut [4] 是最先進的無監督例外檢測方法,它以VAE [21]、[22] 為基礎,對周期性平滑 KPI 表現出高性能、并且具有扎實的理論分析,但由于 Donut 假設為對角多元高斯噪聲,因此它在復雜的 KPI 上表現不佳,如 圖9 所示,
D. Variational Auto-Encoder
VAE [21],[22] 是一個深度貝葉斯網路,它對兩個隨機變數 x x x 和 z z z 之間的關系進行建模, p ( x ) p(x) p(x) 稱為經驗分布, p ( z ) p(z) p(z) 稱為先驗分布,通常為多元標準高斯分布 N ( 0 , I ) \mathcal{N}(0,I) N(0,I), 條件分布 p θ ( x ∣ z ) p_\theta(x|z) pθ?(x∣z) 的形式是根據任務的特定要求來選擇,然后, p θ ( x ) = E p ( z ) [ p θ ( x ∣ z ) ] p_\theta(x)=\mathbb{E}_{p(z)}[p_{\theta}(x|z)] pθ?(x)=Ep(z)?[pθ?(x∣z)] 可以看作是一種核密度估計(kernel density estimation), q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 是對計算困難的真實后驗 p θ ( z ∣ x ) p_\theta(z|x) pθ?(z∣x) 的后驗似然, q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 可以通過神經網路,利用 SGVB 演算法,通過對最大化 證據下界(ELBO)的似然估計進行擬合,
VAE 的訓練目標,記作
L
v
a
e
\mathcal{L}_{vae}
Lvae?,即
E
p
(
x
)
[
log
?
p
θ
(
x
)
]
\mathbb{E}_{p(x)}[\log_{p_\theta}(x)]
Ep(x)?[logpθ??(x)] 的 ELBO,
L
v
a
e
=
E
p
(
x
)
[
E
q
?
(
z
∣
x
)
[
log
?
p
θ
(
x
∣
z
)
]
?
K
L
[
q
?
(
z
∣
x
)
∣
∣
p
θ
(
z
)
]
]
\mathcal{L}_{vae}=\mathbb{E}_{p(x)}[\mathbb{E}_{q_\phi(z|x)}[\log {p_\theta(x|z)}]-KL[\ q_\phi(z|x)\ ||\ p_\theta(z)]]
Lvae?=Ep(x)?[Eq??(z∣x)?[logpθ?(x∣z)]?KL[ q??(z∣x) ∣∣ pθ?(z)]]
Donut [4] 修改了 ELBO 的一部分,以避免訓練中例外的影響,并在周期性平滑 KPI 上取得了較高的性能,但是,Donut 在復雜的 KPI 上作業得不好 —— 我們對 Donut 進行了多次訓練,發現 Donut 的性能很低,不穩定,而且沒有經過良好的訓練(將在第5節中顯示),我們推測,由于神經網路表達能力和訓練方法的限制,很難在復雜的經驗分布 p ( x ) p(x) p(x) 上進行訓練,并且訓練樣本有限,如 圖8 所示,
E. Adversarial Training
文獻中已經提出了一系列對抗性訓練方法,如 GAN [23]、WGAN [6]、AAE [24]、WAE [25] 和 GAN-OT [26],在對抗訓練中,生成器模型試圖生成樣本來欺騙鑒別器模型,鑒別器試圖區分生成的樣本和真實樣本,在對抗訓練中,發生器和鑒別器的能力都有很大的提高,在影像分類、影像生成、語音識別等領域,對抗訓練在復雜的經驗分布上取得了很好的效果,
有幾項關于 VAE 和高級訓練相結合的研究,如 [27],與我們的結構看起來是相似的,但我們的理論證明表明它們在本質上是完全不同的,AAE[24] 提出了一種基于先驗分布 p ( z ) p(z) p(z) 的對抗性訓練方法,具有較高的性能和可靠的證明,受此啟發,本文提出了一種復雜經驗分布 p ( x ) p(x) p(x) 的VAE對抗訓練方法,在此基礎上,提出了一種基于深層生成模型的復雜 KPI 例外檢測演算法,
3. Architecture
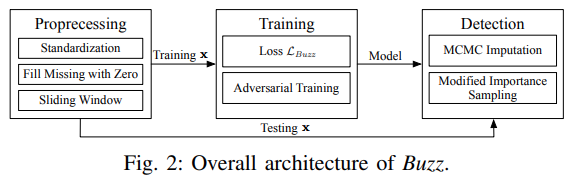
在本節中,我們將介紹我們的動機和提出的例外檢測框架 Buzz ,包括預處理階段、訓練目標和相應的演算法、神經網路結構以及檢測方法,總體架構如 圖2 所示,
A. Motivation
Buzz 有兩個主要觀點:Wasserstein 距離和與測量理論的分離(Partitioning from measure theory.),
在計算距離時,我們使用了生成分布和經驗分布之間的Wasserstein距離[6](以下稱為分布距離),WGAN[6]表明,在測量概率分布之間的距離時,該距離是穩健的,
Partitioning 是測度論中一種強大且常用的分布分析方法[28],[29],其基本思想本質上類似于微積分中的一種常見技術:在計算一個復雜函式的積分時,通常把它的積分域分成若干個磁區,然后計算每個磁區上的積分,然后求其平均值,同樣地,我們將具有復雜經驗分布的空間 X \mathcal{X} X 劃分為幾個磁區,直觀地說,在每個足夠小的磁區上計算分布距離可能比在整個空間上更容易,
每個磁區上的分布距離是通過對抗訓練計算出來的,全域距離是所有磁區上分布距離的期望值,如 圖3 所示,

巧合的是,我們注意到,當每個磁區越來越小時,全域距離接近 VAE 的一個特殊變數的 ELBO 中的重構項,其后驗分布是指數分布(an exponential distribution),磁區(Potition)在磁區從整體到點的變化程序中起著連接 WGAN 和 VAE 的損失的作用,它啟發了我們對抗性的VAE訓練方法,
我們將對這一動機進行理論推導,并在第4節中給出一個近似的訓練目標, 在本節中,我們將首先演示它在實踐中是如何作業的,
B. Preprocessing
實際應用中的 KPIs 是復雜的時間序列資料,有時監視器不會捕獲某個值并將其設定為 NaN,稱為缺失值,有時,在一段時間內,價值觀的規模都非常大,這些值會給訓練和檢測帶來困難,因此需要對資料進行預處理,
首先,我們將缺失的值設定為零,然后分割資料將 KPI 分為訓練集和測驗集,其次,我們計算訓練集中的均值 μ \mu μ 和標準差 σ \sigma σ ,第三,我們對資料進行標準化,即將每個數值 x x x 設為 ( x ? μ ) σ {{(x-\mu)}\over{\sigma}} σ(x?μ)? ,第四,我們將標準值截斷在 [?10, 10] 之間,
我們的模型的輸入是來自標準化 KPI 的滑動視窗,每個視窗是 W W W長的時間序列段,其中 W W W是一個稱為視窗大小的超引數,在時間 t t t 結束的視窗表示為 x ( t ) x^{(t)} x(t) 視窗 { x t ? W + 1 , . . . , x t x_{t-W+1},...,x_t xt?W+1?,...,xt?} 中的值記錄為 x k ( t ) x_k^{(t)} xk(t)?,
C. Neural Network
我們的模型由 3 個子網路組成:變分網路(the variational network)、生成網路 (the generative network) 和判別網路(the discriminative network),如 圖4a、圖4b、圖4c 中所示,
變分網路的設計是為了找到與給定的視窗 x x x 對應的 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) ,我們將視窗 reshape 為 2 維矩陣,使用卷積層 [30] 來提取高級別的特征,記作 h z ( x ) h_z(x) hz?(x),然后我們分離 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 中的均值和標準差: μ z ( x ) = W μ z T ? b μ z \mu_z(x)=W^T_{{\mu}_z} \cdot b_{\mu_z} μz?(x)=Wμz?T??bμz?? , σ z ( x ) = S o f t P l u s ( W σ z T ) ? h z ( x ) + b σ z ) + ? \sigma_{z}(x)=SoftPlus(W^T_{\sigma_z})\cdot h_z(x)+b_{\sigma_z})+\epsilon σz?(x)=SoftPlus(Wσz?T?)?hz?(x)+bσz??)+? ,其中 ? \epsilon ? 是一個正的向量常數,
生成網路的設計是為了由變分網路得到的 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 生成重構視窗,我們通過一個全連接層將 z z z 映射到 2維矩陣,然后通過一系列二維轉置到卷積層,最后 reshape 為 1 維資料,從而得到重構視窗 G ( z ) G(z) G(z),
判別網路的設計是為了從重構視窗 y \mathcal{y} y 中檢測出真實視窗 x x x ,我們將視窗 reshape 為 2 維,通過卷積層獲得高級別的特征,將這些特征傳遞到一個全連接層,最后獲得判別器的輸出 F ( x ) F(x) F(x),
D. Training Objective
Buzz 最重要的部分是它的訓練目標,我們為復雜 KPIs 提出了一個新的訓練目標 L ~ B u z z \mathcal{\widetilde L}_{Buzz} L Buzz? ,以解決在資料集上很難使用純貝葉斯下界(如 Donut 方法)來訓練模型的問題(參見第5節), L ~ B u z z \mathcal{\widetilde L}_{Buzz} L Buzz? 的準確定義和推導在第4節中給出,這個章節,我們只給出 L ~ B u z z \mathcal{\widetilde L}_{Buzz} L Buzz? 的采樣格式和它的訓練演算法,
符號 s , b s, b s,b 是引數,表示鄰域大小和批量大小,設 W \mathcal{W} W 為 { w 1 , w 2 , . . , w b \mathcal{w}_1,\mathcal{w}_2,..,\mathcal{w}_b w1?,w2?,..,wb?},即隨機選擇時間的一個小批量,滿足:每一個 w i w_i wi? 都是 s s s 的倍數,并且 $w_i \ne w_j $ ? i ≠ j i\ne j i?=j,我們把 W \mathcal{W} W 上的這個條件稱為領域條件(Neighbor Condition,NC), w ∈ W w\in \mathcal{W} w∈W 的領域集合為 { w , w + 1 , . . . , w + s ? 1 w,w+1,...,w+s-1 w,w+1,...,w+s?1},這是一個磁區的時間, x ( w ) , x ( w + 1 ) , . . . , x ( w + s ? 1 ) x^{(w)},x^{(w+1)},...,x^{(w+s-1)} x(w),x(w+1),...,x(w+s?1) 的多面體單元的聯合是 X \mathcal{X} X 的一個磁區 S w S_w Sw?,這個一個簡單高效的磁區方法,定義符號:
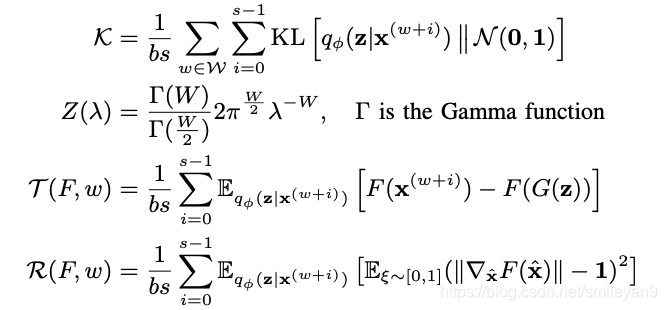
其中
x
^
\hat x
x^ 是指
ξ
x
w
+
i
+
(
1
?
ξ
)
G
(
z
)
\xi x^{w+i}+(1-\xi)G(z)
ξxw+i+(1?ξ)G(z),然后訓練目標
L
~
B
u
z
z
\mathcal{\widetilde L}_{Buzz}
L
Buzz? 為:
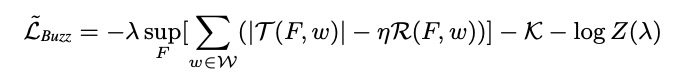
L ~ B u z z \mathcal{\widetilde L}_{Buzz} L Buzz? 是 一種特殊的對抗訓練演算法 WGAN-GP [7] 損失函式的改進,我們的模型中的判別網路( F ( x ) F(x) F(x))可以看作WGAN-GP 的 “判別器” ,而變分網路和生成網路可以看作 “生成器”, s u p F [ ? ] sup_F[\cdot] supF?[?] 和 T ( F , w ) \mathcal{T(F,w)} T(F,w) 可以看作 “WGAN” 損失術語(loss term), R ( F , w ) \mathcal{R}(F,w) R(F,w) 可以看作 F F F 的正則化器,也是 “-GP” (梯度懲罰,gradient penalty)術語,而 η \eta η 是梯度懲罰權重,
另外,WGAN-GP [7] 中的術語, L ~ B u z z \mathcal{\widetilde L}_{Buzz} L Buzz? 也添加了從貝葉斯訓練目標中借鑒的術語 K \mathcal{K} K ,為 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 做正則化, λ \lambda λ 是一個可訓練的變數(trainable variable),包括貝葉斯推斷框架,它可以平衡 WGAN-GP 項和貝葉斯正則化,
E. Training
給定 L ~ B u z z \mathcal{\widetilde L}_{Buzz} L Buzz? 是 WGAN-GP 的一種改進,所以 Buzz 的訓練程序與 WGAN-GP 演算法相似,生成器的引數(比如變分網路和生成網路,加上 λ \lambda λ ),記作 w w w ,而判別器的引數,(比如判別網路 F ( x ) F(x) F(x) ),記作 v v v, R ( F , w ) \mathcal{R}(F,w) R(F,w) 在優化 w w w 時被忽略,因為它僅僅是為 F F F 而正則化, 只依賴于 v v v ,我們使用 SGVB [21] 來為 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 作變分推斷,使用 Adam [31] 來優化神經網路引數,由于 WGAN-GP 損失具有很強的收斂性,我們的訓練程序非常穩定,超引數調整很少,
將會在第4節證明,當 s → 1 s\to1 s→1 ( L B u z z \mathcal{L}_{Buzz} LBuzz? 是 L ~ B u z z \mathcal{\widetilde L_{Buzz}} L Buzz? 的最初似然格式), L B u z z → L v a e \mathcal{L_{Buzz}} \to \mathcal{L}_{vae} LBuzz?→Lvae? ,因此,我們可以在訓練后,可以將模型轉換到貝葉斯網路,這是第三節-F 部分需要的,因此,在演算法1中,我們開始時設定 s = s 0 s=s_0 s=s0?,然后通過每一個小批次設定 s ← s / 2 s\leftarrow s/2 s←s/2 逐漸減小 s s s 到 1,
F. Detection
我們需要構建 L B u z z \mathcal{L}_{Buzz} LBuzz? 和 L v a e \mathcal{L}_{vae} Lvae? ,即 VAE[21] 的一種特殊變體的損失函式, 如第4節中, p θ ( x ∣ z ) = 1 Z ( λ ) e x p { ? λ ∣ ∣ x ? G ( z ) ∣ ∣ } p_\theta(x|z)={{1}\over{Z(\lambda)}}exp\{-\lambda || x-G(z)||\} pθ?(x∣z)=Z(λ)1?exp{?λ∣∣x?G(z)∣∣},通過這種技術,我們可以通過 演算法1 將我們的模型投入到貝葉斯網路中,然后我們可以通過概率框架分離出檢測輸出,如下,
當檢測到一個新的點時,最后一個視窗(也就是視窗中最后一個點是新的點)記作 x x x ,因為我們的目標是檢測出最后一個資料點是不是例外,我們假設它是例外,然后反復使用 MCMC imputation(也在 Donut [4] 中使用),來獲得重構 x  ̄ \overline x x 的合理評估,步驟如下:
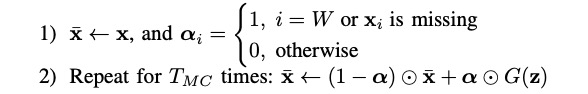
最后,我們把
log
?
p
θ
(
x
)
?
log
?
p
θ
(
x
 ̄
)
\log p_\theta(x)-\log p_\theta(\overline x)
logpθ?(x)?logpθ?(x) 作為最后一個點的例外值評估方法,通過如下方法進行計算:
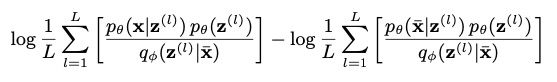
其中, z ( l ) z^{(l)} z(l)~ q ? ( z ∣ x  ̄ ) q_\phi(z|\overline x) q??(z∣x), L L L 是采樣數目,公式是基于評估 log ? p θ ( x ) ? log ? p θ ( x  ̄ ) \log p_\theta(x)-\log p_\theta(\overline x) logpθ?(x)?logpθ?(x) 的重要性采樣 [32] 稍作修改,(記作 Buzz-strict 檢測器),在對 log ? p θ ( x ) \log p_\theta(x) logpθ?(x) 計算重要性采樣公式時,我們使用 q ? ( z ∣ x  ̄ ) q_\phi(z|\overline x) q??(z∣x) 來取代 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) ,因為 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x) 可能因為例外的影響而有所偏差,圖6 中的實驗結果證實了這種猜測,例外檢測的例外分數閾值是如 [4] 通過最佳 F-score 進行選擇的,

4. THEOREM(定理)
限于篇幅,這里不再翻譯原版論文,更多翻譯內容請參考我的個人博客 https://smileyan.cn/#/ad/Buzz
相關資源
這里介紹大家最關心的內容,有源代碼嗎?額,目前為止我還沒有找到原始碼,
這里有關于這篇論文的 PPT,但是由于沒有視頻,沒有原稿,其實參考價值不是很大:https://netman.aiops.org/wp-content/uploads/2019/08/infocom-chinese.pdf
其次,也不知道具體使用的是什么資料集,估計和 Donut 類似,但是 KPI 更加復雜,繪制出來的曲線也應該不是那么光滑的,
演算法分析
事實上,我個人認為,讀這篇論文的順序是這樣的,先大概看一下(忽略第4部分),大致清楚這個是怎么回事以后,再考慮一下要不要去看第4部分,因為第 4 部分是定理部分,相對而言,既很難看懂,也不一定能有參考價值 —— 如果不是想做這型別的論文的話,
除去第4部分相關定理和前面的背景介紹,我們概述一下這篇論文就簡單很多了:
Buzz 總體結構
這一部分非常容易理解,這與 Donut 的總體結構基本上差不多,預處理(preprocessing,注:圖片中有誤)、訓練、檢測,推薦對比一下 Donut 來看差別在哪里, Donut 論文介紹,
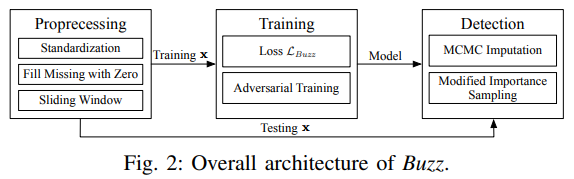
對抗性訓練與檢測
這應該是這篇論文最大的亮點,總體框架是一個 WGAN ,而 WGAN 其中的生成網路是 VAE,從最簡單的 GAN,由于基于 Wasserstein 距離計算,成為 WGAN,接著對于 GAN 中的生成模型下手,替換成為 VAE,因而得到了現在的模型,
對抗性訓練的程序與普通的GAN類似,論文介紹是在 WGAN-GP 基礎上進行了改進,但是只要是對抗生成模型就差不多是這個程序:不斷優化生成模型使得生成模型生成資料盡可能接近于真實資料;不斷優化判別模型使得判別模型依然能夠很好地識別生成資料,
而例外檢測的程序必須結合演算法1而分析了,

- 初始化引數 w w w,生成模型的引數; v v v,判別模型的引數; s s s ,鄰域大小; b b b,批量大小,
- repeat1
- repeat2
- 這個for回圈是指判別迭代,其中的 n c r i t i c n_{critic} ncritic? 是指迭代次數,
- 滿足領域條件(s.t. NC) 情況下,采樣 w 1 , . . . , w b w_1,...,w_b w1?,...,wb?,其中 b b b 是指批次大小,
- 賦值 L v \mathcal{L}_{v} Lv? 與 L w \mathcal{L}_w Lw? 為 0,
- 對于批次中每個資料,回圈,
- 定義臨時變數 L i \mathcal{L}_i Li? 等,
- 對于每一個資料,進行相應的損失計算,
- 相應的損失計算,
- 相應的損失計算,
- 相應的損失計算,
- 相應的損失計算,
- 相應的損失計算,
- 相應的損失計算,
- 結束對每一個資料的回圈,
- 計算本批次的總損失 L v \mathcal{L}_v Lv? ,
- 計算本批次的總損失 L w \mathcal{L}_w Lw?,
- 結束對每一個批次的回圈,
- 如果回圈下標 t 等于判別迭代次數,則優化生成模型,
- 如果回圈下標 t 不等于判別迭代次數,則優化判別模型,
- 結束回圈
- s ← s / 2 s\leftarrow s/2 s←s/2, b ← 2 b b\leftarrow 2b b←2b
- 當 s = 0 時,結束回圈,
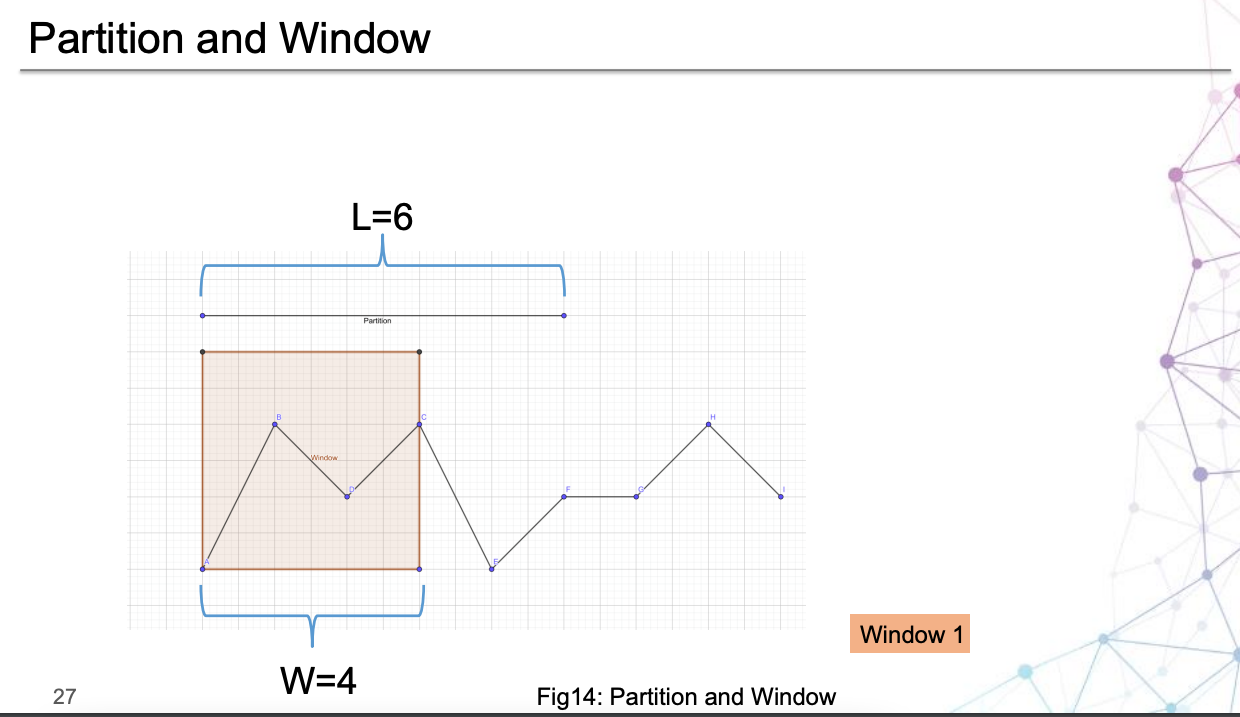
磁區思想
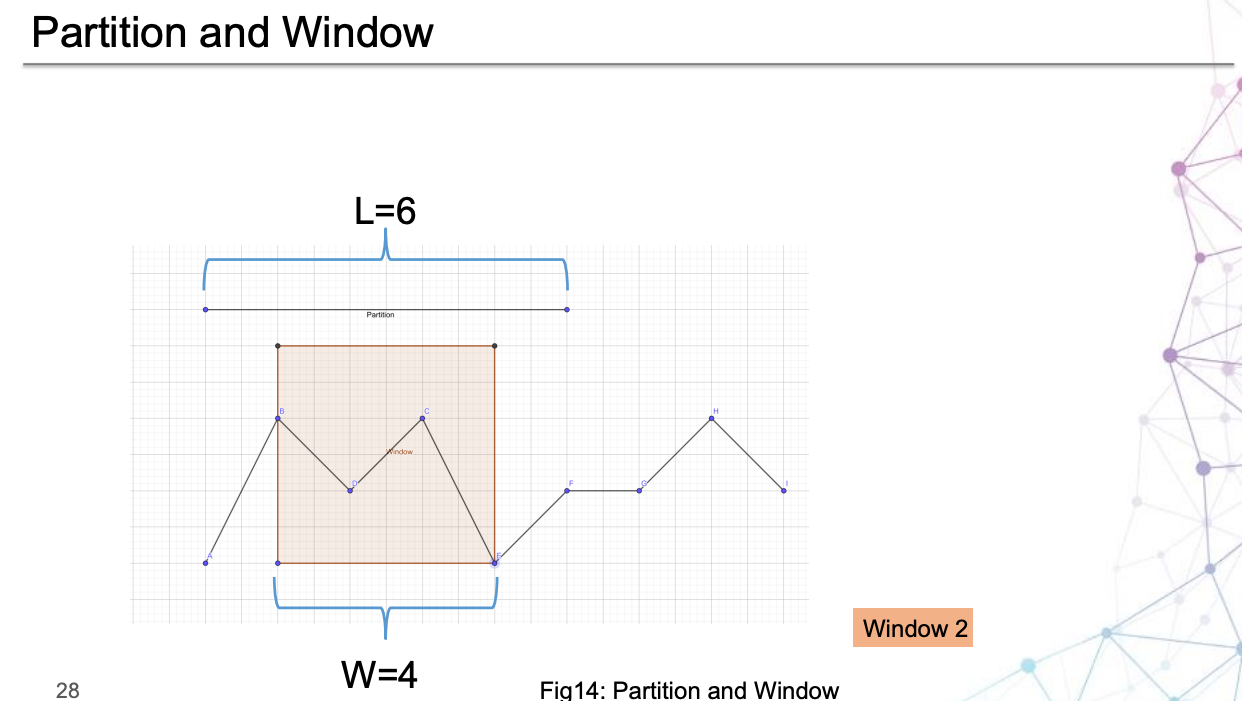
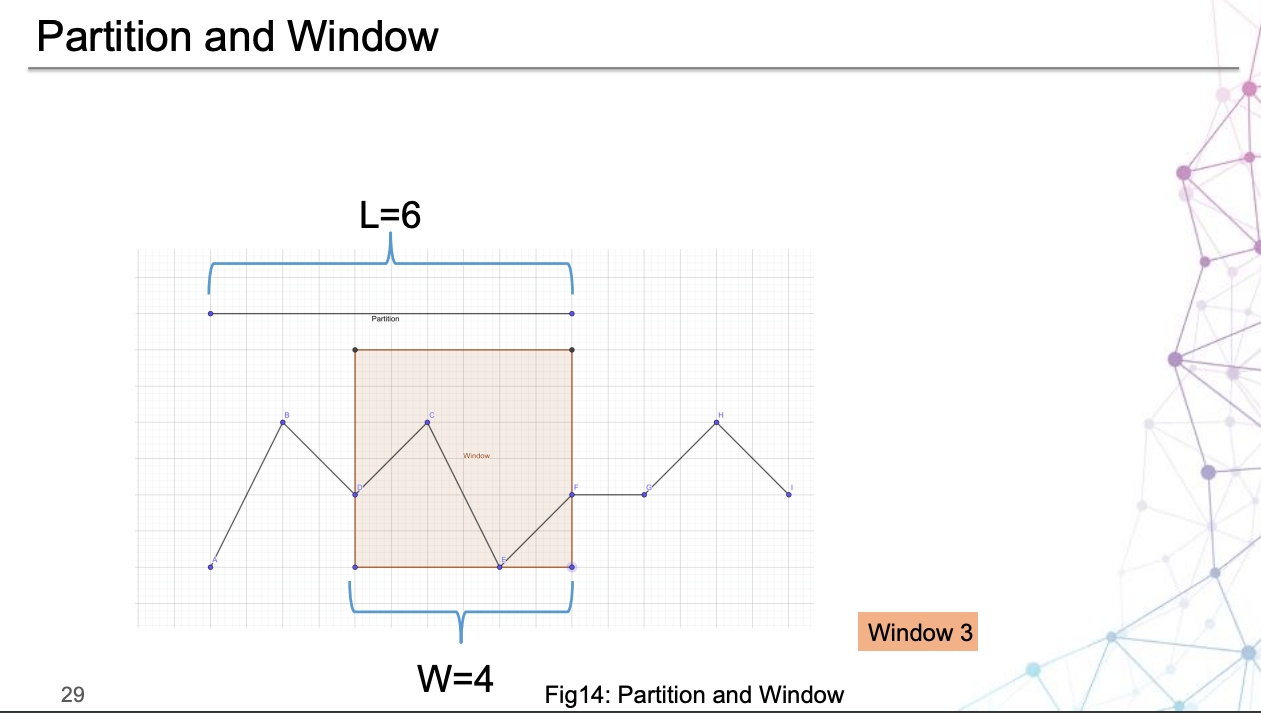
論文有一個很重要的想法:磁區,結合圖3,查看一下這個例子,其中一小塊一小塊就是指磁區思想:

具體是如何磁區的,請參考第3節的D部分,
結合 PPT,可以看出磁區思想與時間窗的劃分的區別:
總結
論文將 VAE 應用在 GAN 中,并且根據 VAE 的特點對目標函式進行了一些改進,這個程序中牽扯到不少定理與證明,但是由于時間關系,本人并沒有仔細閱讀這一部分,但是如果有小伙伴對這一方面感興趣,并且遇到了一些問題,也同樣歡迎留言,我一定認真閱讀,想辦法解決問題,
與 Donut 比起來,這篇論文強調的是:即便是對于復雜的 KPIs,Buzz 也能很好處理——而 Donut 適合于處理平滑的 KPI 資料,
另外,論文提出的磁區的思想是很值得一提的,也就是說,在 Donut 中,輸入模型的資料的基本單位是 視窗,并且在視窗之外沒有更大的單位了:直接把 KPI 資料切分成若干個視窗,而 Buzz 是先分割成多個區域,然后再把每個區域像 Donut 一樣進行切分視窗,這樣的好處大概是引入了 “區域” 的概念,對于復雜 KPI 能夠更好地提取特征,進行訓練與檢測,
感謝 您的 閱讀、點贊、收藏 和 評論 ,別忘了 還可以 關注 一下哈,感謝 您的支持!
Smileyan
2021.5.4 22:02
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283164.html
標籤:AI