前言:
本專欄在保證內容完整性的基礎上,力求簡潔,旨在讓初學者能夠更快地、高效地入門TensorFlow2 深度學習框架,如果覺得本專欄對您有幫助的話,可以給一個小小的三連,各位的支持將是我創作的最大動力!
系列文章匯總:TensorFlow2 入門指南
Github專案地址:https://github.com/Keyird/TensorFlow2-for-beginner
文章目錄
- 一、合并與分割
- (1)合并
- (2)分割
- 二、 資料統計
- (1)向量范數
- (2)最大值、最小值
- (3)和、均值
- (4)最大值、最小值索引
- 三、張量比較
- (1)tf.equal()
- (2)tf.cast()
- 四、張量排序
- (1)tf.sort()
- (2)tf.argsort()
- (3)tf.gather()
- (4)tf.math.top_k()
- 五、填充與復制
- (1)填充
- (2)復制
- 六、資料限幅
- (1)tf.maximum()
- (2)tf.minimum()
- (3)tf.clip_by_value()
- 七、其它操作
- (1)tf.gather()
- (2)tf.gather_nd()
- (3)tf.boolean_mask
- (4)scatter_nd
- (5)meshgrid
一、合并與分割
(1)合并
合并是指將多個張量在某個維度上合并為一個張量,在 TensorFlow 中,可以通過 tf.concat()和tf.stack()進行合并操作,
- tf.concat(tensors, axis) 有兩個引數,其中 tensors 保存了所有需要合并的張量,axis 指定需要合并的維度,例如:
# 隨機生成a,b兩個張量
a = tf.random.normal([5, 40, 10])
b = tf.random.normal([3, 40, 10])
# 在第一個維度合并,c最終的shape為:[8, 40, 10]
c = tf.concat([a, b], axis=0)
如果需要在合并資料時,產生一個新的維度,那就需要用堆疊操作:tf.stack()
- tf.stack(tensors, axis) 可以合并多個張量tensors,其中 axis指定插入新維度的位置,當axis ≥ 0時,在 axis 之前插入;當axis < 0時,在 axis 之后插入新維度,如下圖所示,不同的 axis 值代表的插入位置如下:
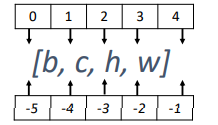
還是通過上面的例子,通過tf.stack()得到不同的合并結果:
a = tf.random.normal([3, 40, 10])
b = tf.random.normal([3, 40, 10])
c = tf.stack([a, b], axis=0)
print(c.shape) # 輸出的shape為:【2,3,40,10】
需要注意的是:使用 tf.stack() 進行合并時,a、b 的 shape 必須一樣,
(2)分割
合并操作的逆程序就是分割,是指將一個張量分拆為多個張量,在TensorFlow2中,可以通過 tf.unstack() 和 tf.split() 進行分割,
- tf.unstack(x, axis) 會將張量x在某個維度上全部 按長度為 1 的方式分割,例如:
x = tf.random.normal([8,28,28,3])
result = tf.unstack(x,axis=0)
通過tf.unstack分割后,維度由 [8,28,28,3] 變為 [28,28,3],準確來說變成了10個維度是 [28,28,3] 的張量,
- tf.split(x, axis, num_or_size_splits) 更加靈活,可以通過設定 num_or_size_splits 將張量維度分割的更細致,比如,要將 shape 為 [8, 28, 28, 3] 的張量按第一維度切分成3份,每份長度分別為:2,4,2
x = tf.random.normal([8,28,28,3])
result = tf.split(x, axis=0, num_or_size_splits=[2,4,2])
二、 資料統計
(1)向量范數
向量范數是表征向量“長度”的一種度量方法,在神經網路中,常用來表示張量的權值大小,梯度大小等,常用的向量范數有:
- L1 范數,定義為向量𝒙的所有元素絕對值之和:
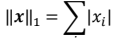
- L2 范數,定義為向量𝒙的所有元素的平方和,再開根號:
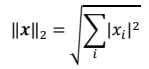
- ∞ ? 范數,定義為向量𝒙的所有元素絕對值的最大值:
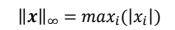
對于矩陣、張量,同樣可以利用向量范數的計算公式,等價于將矩陣、張量打平成向量后計算,在 TensorFlow 中,可以通過 tf.norm(x, ord)求解張量的 L1, L2, ∞等范數,其中引數 ord 指定為 1,2 時計算 L1, L2 范數,指定為 np.inf 時計算∞ ?范數:
x = tf.ones([2,2])
tf.norm(x, ord=1)
tf.norm(x, ord=2)
tf.norm(x, ord=np.inf)
(2)最大值、最小值
通過 tf.reduce_max, tf.reduce_min 可以求解張量在某個維度上的最大、最小值,也可以求全域最大、最小值,
考慮 shape 為 [4,10] 的張量,其中第一個維度代表樣本數量,第二個維度代表了當前樣本分別屬于 10 個類別的概率,需要求出每個樣本的概率最大值、最小值為:
x = tf.random.normal([4,10])
tf.reduce_max(x, axis=1) # 統計概率維度上的最大值(第2個維度)
tf.reduce_min(x,axis=1) # 統計概率維度上的最小值(第2個維度)
(3)和、均值
tf.reduce_mean, tf.reduce_sum 可以求解張量在某個維度上的均值、和,也可以求全域最均值、和資訊,
同樣利用上面的例子,求出每個樣本的概率的均值以及和:
tf.reduce_mean(x,axis=1) # 統計概率維度上的均值(第2個維度)
tf.reduce_sum(out,axis=-1)# 統計概率維度上的和(第2個維度)
注意:當不指定 axis 引數時,tf.reduce_* 函式會求解出全域元素的最大、最小、均值、和,
(4)最大值、最小值索引
通過 tf.argmax(x, axis),tf.argmin(x, axis) 可以求解在 axis 軸上,x 的最大值、最小值所在的索引號,比如求輸出向量out在概率維度上(第二維度)的最大值、最小值索引:
pred_max_index = tf.argmax(out, axis=1) # 最大值索引(第二維度)
pred_min_index = tf.argmin(out, axis=1) # 最小值索引 (第二維度)
三、張量比較
為了計算分類任務的準確率等指標,一般需要將預測結果和真實標簽比較,統計結果中正確的數量來計算準確率,
(1)tf.equal()
考慮 100 個樣本、10類的預測結果,先選取每個向量維度上的最大值索引,即預測值(比如第一個樣本的概率最大索引是5,表示預測的結果是第5類)
out = tf.random.normal([100,10]) # 隨機生成一個張量,用來模擬輸出結果
out = tf.nn.softmax(out, axis=1) # 輸出轉換為概率值,縮放到0-1,且概率和為1
pred = tf.argmax(out, axis=1) # 選取預測值(概率維度上的最大值),得到的是長度為100的向量
模擬100個真實標簽,采用上節講的均勻分布tf.random.uniform()來創建長度為100,值屬于[0,9]區間的向量:
y = tf.random.uniform([100],dtype=tf.int64,maxval=10) # 標簽
接下來,通過 tf.equal(pred, y) 可以比較這 2個張量是否相等,tf.equal()函式回傳布爾型的張量比較結果:
out = tf.equal(pred,y) # 預測值與真實值比較
注意:tf.math.equal(a, b) 與 tf.equal(a, b) 用法一樣
(2)tf.cast()
由于 tf.equal() 回傳的是bool型的張量,所以要統計張量中 True 元素的個數,即可知道預測正確的個數,為了達到這個目的,我們需要通過tf.cast(x, type)將布爾型轉換為整形張量:
out = tf.cast(out, dtype=tf.float32) # 布爾型轉 int 型
于是,比較結果都轉換成0和1了,然后再求和,統計其中 1 的個數,即預測正確的樣本個數:
correct_num = tf.reduce_sum(out) # 統計 True 的個數
假設最終得到的correct_num=95,那么本次預測資料的準確度是:95/100=95%
四、張量排序
(1)tf.sort()
tf.sort() 能對串列中的元素按照大小進行排序,默認情況下進行升序排列,關鍵字 DESCENDING 指定降序排序,
先創建一打亂后的串列:
# 創建串列 [0,1,2,3,4],并打亂順序
a = tf.random.shuffle(tf.range(5))
print("打亂后的串列:", a)
使用tf.sort()對其進行升序和降序排列:
# 升序
b = tf.sort(a)
print("升序排列后的串列:", b)
# 降序
c = tf.sort(a, direction="DESCENDING")
print("降序排列后的串列:", c)
輸出結果:

(2)tf.argsort()
tf.argsort(a) 回傳按照升(降)序排列的各元素在原串列a中的索引號,通過這種方式,可以方便地找到原陣列中最大值或者最小值的索引值,
arise_index = tf.argsort(a)
print("升序串列各元素在原串列a中的索引號:", arise_index)
descend_index = tf.argsort(a, direction="DESCENDING")
print("降序串列各元素在原串列a中的索引號:", descend_index)
輸出結果:

分析:該結果表明,元素 0、1、2、3、4 在原陣列 a=[4,0,2,1,3] 中的索引號分別是:1、3、2、4、0;同理,元素 4、3、2、1、0 在原陣列 a=[4,0,2,1,3] 中的索引號分別是:0、4、2、3、1,
以上是對一維向量的排序結果,采用 tf.sort() 和 tf.argsort() 也能對二維陣列進行排序操作,作用如下:
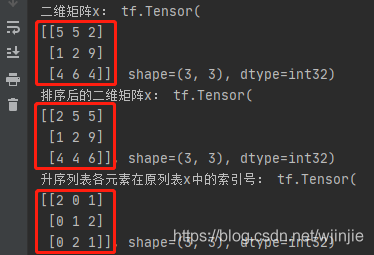
""" 對二維陣列進行排序 """
x = tf.random.uniform([3, 3], maxval=10, dtype=tf.int32)
print("二維矩陣x:", x)
x_arise = tf.sort(x)
print("排序后的二維矩陣x:", x_arise)
x_arise_index = tf.argsort(x)
print("升序串列各元素在原串列x中的索引號:", x_arise_index)
輸出結果:
(3)tf.gather()
tf.gather(a, index) 通過升(降)序索引,可將輸入串列 a 還原成升(降)序串列:
Arise_List = tf.gather(a, arise_index)
print("升序串列:", Arise_List)
DES_List = tf.gather(a, descend_index)
print("降序串列:", DES_List)
程式輸出:

(4)tf.math.top_k()
在 TensorFlow2 中,通過 tf.math.top_k() 、values、indices 可以很輕松地獲取陣列的top-k值以及他們的索引值:
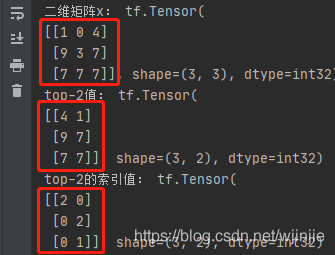
""" 獲取top-K的數值以及索引 """
x = tf.random.uniform([3, 3], maxval=10, dtype=tf.int32)
print("二維矩陣x:", x)
res = tf.math.top_k(x, 2)
print("top-2值:", res.values)
print("top-2的索引值:", res.indices)
程式輸出:
五、填充與復制
(1)填充
對二維矩陣進行填充:
在 TensorFlow2 中,可通過 tf.pad(x, [[上, 下], [左, 右]]) 指定在矩陣 x 的上下左右邊上填充一行(列)0 元素:
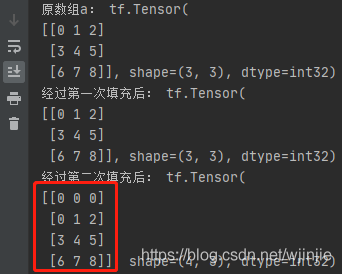
""" 填充 Padding """
a = tf.reshape(tf.range(9), [3, 3])
print("原陣列a:", a)
b = tf.pad(a, [[0, 0], [0, 0]])
print("經過第一次填充后:", b)
c = tf.pad(a, [[1, 0], [0, 0]])
print("經過第二次填充后:", c)
程式輸出:
更常見的,會對四維張量進行填充操作:
比如,下面對影像張量 [4,28,28,3] 進行填充,4是batch_size,一般不需要填充,通常情況是對影像的size 28x28 進行填充,現在對 28x28 向上下左右各填充兩行(列)0,其操作如下:
""" 對四維張量進行填充 """
x = tf.random.normal([4, 28, 28, 3])
print("x.shape:",x.shape)
x_pad = tf.pad(x, [[0, 0], [2, 2], [2, 2], [0, 0]])
print("x_pad.shape:", x_pad.shape)
填充前后,張量的 shape 分別如下所示:

(2)復制
在 TensorFlow2 中,通過 tf.tile() 選擇性地在行或者列的維度上進行復制,其操作如下所示:
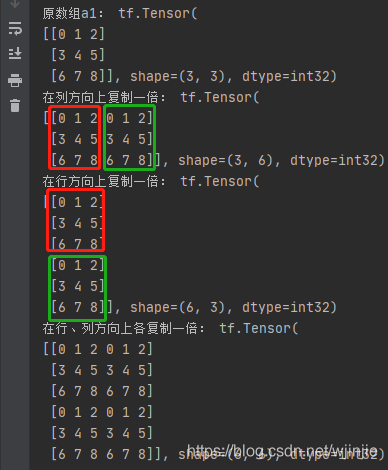
""" 復制 """
a1 = tf.reshape(tf.range(9), [3, 3])
print("原陣列a1:", a1)
b1 = tf.tile(a1, [1, 2])
print("在列方向上復制一倍:", b1)
c1 = tf.tile(a1, [2, 1])
print("在行方向上復制一倍:", c1)
d1 = tf.tile(a1, [2, 2])
print("在行、列方向上各復制一倍:", d1)
在行、列上進行復制操作后,得到的矩陣分別如下:
在 TensorFlow2 中,通過 tf.tile() 不僅可以在同一維度內進行復制,也可以通過復制擴充張量的維度,比如將shape為[3,3]的矩陣進行維度上的復制,使其變為shape為[2,3,3]的張量:
# 維度上的復制:[3,3] -> [2,3,3]
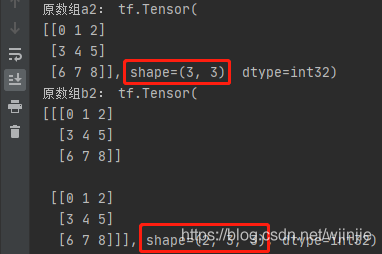
a2 = tf.reshape(tf.range(9), [3, 3])
print("原陣列a2:", a2)
a2 = tf.expand_dims(a2, axis=0) # 增加一個維度
b2 = tf.tile(a2, [2, 1, 1])
print("原陣列b2:", b2)
輸出結果:
六、資料限幅
(1)tf.maximum()
在 TensorFlow2 中,可以通過 tf.maximum(x, low) 實作資料的下限幅:𝑥 ∈ [low, +∞);示例如下:
a = tf.range(9)
print("a:", a)
b = tf.maximum(a, 2) # 設定下限是2
print("下限限制為2后:", b)
如下是限制前后的向量對比:

通過 tf.maximum() 限制下限,還可以實作基本的激活函式ReLU:
def relu(x):
return tf.maximum(x, 0)
x = a - 5
print("x:", x)
y = relu(x)
print("y:", y)
對ReLU函式輸入x,可以看到輸出的y滿足激活函式的特性:

PS:ReLU是常見的激活函式的一種,其函式模型如下:
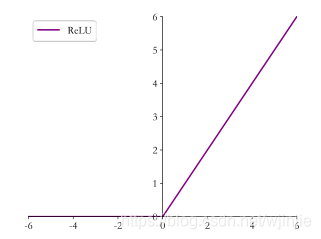
在 TensorFlow2 中,可以直接呼叫 tf.nn.relu() 來實作以上功能,
(2)tf.minimum()
在 TensorFlow 中,也可以通過 tf.minimum(x, high) 實作資料的上限幅:𝑥 ∈ (?∞, high],舉例如下:
b1 = tf.minimum(a, 6)
print("上限限制為6后:", b1)
設定上限為6后,向量限幅后變為:

(3)tf.clip_by_value()
如果想同時對資料設定上限和下限,那么可以使用 clip_by_value(x, low, high) 來將資料限制在 [low, high] 之間,例如下面要將向量a的資料限制在5~8之間:
b2 = tf.clip_by_value(a, 5, 8)
print("下限設定為5,上限設定為8后:", b2)
下限設定為5,上限設定為8后:

七、其它操作
(1)tf.gather()
通過 tf.gather(x, [indexes], axis) 可以實作根據索引號收集資料的目的,其中 x 表示輸入張量,[indexes]表示要獲取的資料索引,axis表示要獲取的維度,比如下面通過 tf.gather 獲取第0至第3張圖片:
# [b, w, h, c]
images = tf.random.normal([8, 28, 28, 3])
# 取第0至第3張圖片
images_0_3 = tf.gather(images, [0, 1, 2, 3], axis=0)
print("images_0_3的shape:", images_0_3.shape)
對于0~3這種連續索引的情況,也可直接通過索引實作,如下所示:
# 也可通過索引來實作
images_0_3 = images[:4,...]
print("images_0_3的shape:", images_0_3.shape)
對于 tf.gather() 來說,其特殊之處,在于對于非連續索引時操作更為方便,比如,加下來我們要對第0至3張圖片的第0和第2通道進行資料提取:
# 對第0和第2通道進行提取
out_image = tf.gather(images_0_3, [0, 2], axis=3)
print("out_image的shape:", out_image.shape)
可見,輸出的通道數變為了2:

(2)tf.gather_nd()
通過 tf.gather_nd,可以通過指定每次采樣的坐標來實作采樣多個點的目的,考慮班級成績冊的例子,共有 4 個班級,每個班級 35 個學生,8 門科目,保存成績冊的張量 shape 為[4,35,8],
x = tf.random.uniform([4,35,8],maxval=100,dtype=tf.int32)
現希望抽查第 2 個班級的第 2 個同學的所有科目,第 3 個班級的第 3 個同學的所有科目,第 4 個班級的第 4 個同學的所有科目,那么這 3 個采樣點的索引坐標可以記為:[1,1],[2,2],[3,3],我們將這個采樣方案合并為一個 List 引數:[[1,1],[2,2],[3,3]],通過tf.gather_nd 實作如下:
y = tf.gather_nd(x,[[1,1],[2,2],[3,3]])
抽查的3個學生的所有8個科目的成績資訊如下:

當然,也可以通過 tf.gather_nd 多維度坐標收集資料,例如抽出班級 1,學生 1 的科目 2;班級 2,學生 2 的科目 3;班級 3,學生 3 的科目 4 的成績,共有 3 個成績資料,結果匯總為一個 shape 為[3]的張量:
y1 = tf.gather_nd(x,[[1,1,2],[2,2,3],[3,3,4]])
輸出的對應資訊如下:

(3)tf.boolean_mask
除了可以通過給定索引號的方式采樣,還可以通過給定掩碼(mask)的方式采樣,繼續以 shape 為[4,35,8]的成績冊為例,這次我們以掩碼方式進行資料提取,
例如,我們要對第1個班級和第3個班級的資料進行提取,可以設定掩碼為:Mask=[True, False, True, False],然后進行如下操作:
x = tf.random.uniform([4,35,8],maxval=100,dtype=tf.int32)
y2 = tf.boolean_mask(x, mask=[True, False, True, False], axis=0)
print("y2.shape:", y2.shape)
獲得提取資料的shape為:

(4)scatter_nd
通過 tf.scatter_nd(indices, updates, shape)可以高效地重繪張量的部分資料,但是只能在全 0 張量的白板上面重繪,因此可能需要結合其他操作來實作現有張量的資料重繪功能,
如下圖所示,演示了一維張量白板的重繪運算,白板的形狀表示為 shape 引數,需要重繪的資料索引為 indices,新資料為 updates,其中每個需要重繪的資料對應在白板中的位置,根據 indices 給出的索引位置將 updates 中新的資料依次寫入白板中,并回傳更新后的白板張量,
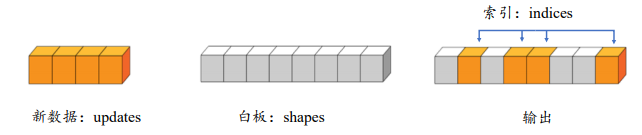
在索引4的位置插入4,在索引3的位置插入5,在索引1的位置插入1,在索引7的位置插入8,實作如下:
# 構造需要重繪資料的位置
indices = tf.constant([[4], [3], [1], [7]])
# 構造需要寫入的資料
updates = tf.constant([4, 5, 1, 8])
# 在長度為 8 的全 0 向量上根據 indices 寫入 updates
out = tf.scatter_nd(indices, updates, [8])
print("out:", out)
更新后的向量輸出out:

(5)meshgrid
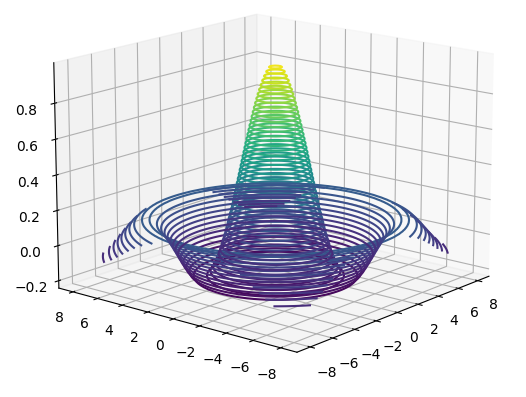
通過 tf.meshgrid 可以方便地生成二維網格采樣點坐標,方便可視化等應用場合,下面繪制 Sinc 函式在𝑥 ∈ [?8,8], 𝑦 ∈ [?8,8]區間的 3D 曲面,
首先在 x 軸上進行采樣 100 個資料點,y 軸上采樣 100 個資料點,然后通過tf.meshgrid(x, y)即可回傳這 10000 個資料點的張量資料,shape 為[100,100,2],為了方便計算,tf.meshgrid 會回傳在 axis=2 維度切割后的 2 個張量 a,b,其中張量 a 包含了所有點的 x 坐標,b 包含了所有點的 y 坐標,shape 都為[100,100],
TensorFLow2實作如下:
首先需要匯入相關庫:
import tensorflow as tf
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
然后,使用 tf.meshgrid() 進行如下操作,并采用 matplotlib 將結果顯示出來:
# 5. meshgrid()
x = tf.linspace(-8.,8,100) # 設定 x 坐標的間隔
y = tf.linspace(-8.,8,100) # 設定 y 坐標的間隔
x,y = tf.meshgrid(x,y) # 生成網格點,并拆分后回傳
# x.shape, y.shape # 列印拆分后的所有點的 x,y 坐標張量 shape
z = tf.sqrt(x**2+y**2)
z = tf.sin(z)/z # sinc 函式實作
fig = plt.figure()
ax = Axes3D(fig)
fig = plt.figure()
ax = Axes3D(fig)
# 根據網格點繪制 sinc 函式 3D 曲面
ax.contour3D(x.numpy(), y.numpy(), z.numpy(), 50)
plt.show()
最終,Sinc 函式在𝑥 ∈ [?8,8], 𝑦 ∈ [?8,8]區間的 3D 曲面圖如下所示:
本教程所有代碼會逐漸上傳github倉庫:https://github.com/Keyird/TensorFlow2-for-beginner
如果對你有幫助的話,歡迎star收藏~
最好的關系是互相成就,各位的「三連」就是【AI 菌】創作的最大動力,我們下期見!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283166.html
標籤:AI