目錄
- 1. Spark 概述
- 1.1. Spark是什么
- 1.2. Spark的特點(優點)
- 1.3. Spark組件
- 1.4. Spark和Hadoop的異同
- 2. Spark 集群搭建
- 2.1. Spark 集群結構
- 2.2. Spark 集群搭建
- 2.3. Spark 集群高可用搭建
- 2.4. 第一個應用的運行
- 3. Spark 入門
- 3.1. Spark shell 的方式撰寫 WordCount
- 3.2. 讀取 HDFS 上的檔案
- 3.4. 撰寫獨立應用提交 Spark 任務
1. Spark 概述
目標
- Spark 是什么
- Spark 的特點
- Spark 生態圈的組成
1.1. Spark是什么
目標
- 了解 Spark 的歷史和產生原因, 從而淺顯的理解 Spark 的作用
-
Spark的歷史
2009 年由加州大學伯克利分校 AMPLab 開創2010 年通過BSD許可協議開源發布2013 年捐贈給Apache軟體基金會并切換開源協議到切換許可協議至 Apache2.02014 年 2 月,Spark 成為 Apache 的頂級專案2014 年 11 月, Spark的母公司Databricks團隊使用Spark重繪資料排序世界記錄
-
Spark是什么
Apache Spark 是一個快速的, 多用途的集群計算系統, 相對于 Hadoop MapReduce 將中間結果保存在磁盤中, Spark 使用了記憶體保存中間結果, 能在資料尚未寫入硬碟時在記憶體中進行運算.Spark 只是一個計算框架, 不像 Hadoop 一樣包含了分布式檔案系統和完備的調度系統, 如果要使用 Spark, 需要搭載其它的檔案系統和更成熟的調度系統
-
為什么會有Spark
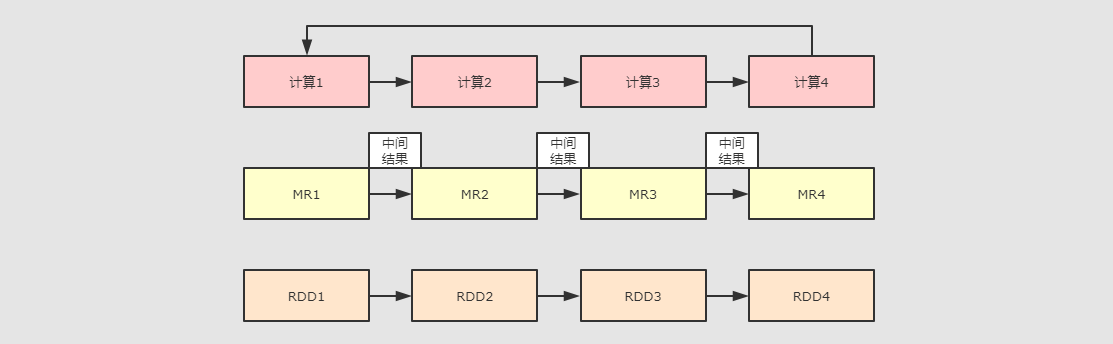 Spark 產生之前, 已經有非常成熟的計算系統存在了, 例如 MapReduce, 這些計算系統提供了高層次的API, 把計算運行在集群中并提供容錯能力, 從而實作分布式計算.雖然這些框架提供了大量的對訪問利用計算資源的抽象, 但是它們缺少了對利用分布式記憶體的抽象, 這些框架多個計算之間的資料復用就是將中間資料寫到一個穩定的檔案系統中(例如HDFS), 所以會產生資料的復制備份, 磁盤的I/O以及資料的序列化, 所以這些框架在遇到需要在多個計算之間復用中間結果的操作時會非常的不高效.而這類操作是非常常見的, 例如迭代式計算, 互動式資料挖掘, 圖計算等.認識到這個問題后, 學術界的 AMPLab 提出了一個新的模型, 叫做
Spark 產生之前, 已經有非常成熟的計算系統存在了, 例如 MapReduce, 這些計算系統提供了高層次的API, 把計算運行在集群中并提供容錯能力, 從而實作分布式計算.雖然這些框架提供了大量的對訪問利用計算資源的抽象, 但是它們缺少了對利用分布式記憶體的抽象, 這些框架多個計算之間的資料復用就是將中間資料寫到一個穩定的檔案系統中(例如HDFS), 所以會產生資料的復制備份, 磁盤的I/O以及資料的序列化, 所以這些框架在遇到需要在多個計算之間復用中間結果的操作時會非常的不高效.而這類操作是非常常見的, 例如迭代式計算, 互動式資料挖掘, 圖計算等.認識到這個問題后, 學術界的 AMPLab 提出了一個新的模型, 叫做 RDDs.RDDs是一個可以容錯且并行的資料結構, 它可以讓用戶顯式的將中間結果資料集保存在內中, 并且通過控制資料集的磁區來達到資料存放處理最優化.同時RDDs也提供了豐富的 API 來操作資料集.后來 RDDs 被 AMPLab 在一個叫做 Spark 的框架中提供并開源.
總結
- Spark 是Apache的開源框架
- Spark 的母公司叫做 Databricks
- Spark 是為了解決 MapReduce 等過去的計算系統無法在記憶體中保存中間結果的問題
- Spark 的核心是 RDDs, RDDs 不僅是一種計算框架, 也是一種資料結構
1.2. Spark的特點(優點)
目標
- 理解 Spark 的特點, 從而理解為什么要使用 Spark
-
速度快
Spark 的在記憶體時的運行速度是 Hadoop MapReduce 的100倍基于硬碟的運算速度大概是 Hadoop MapReduce 的10倍Spark 實作了一種叫做 RDDs 的 DAG 執行引擎, 其資料快取在記憶體中可以進行迭代處理
-
易用
df = spark.read.json("logs.json") df.where("age > 21") \ .select("name.first") \ .show()Spark 支持 Java, Scala, Python, R, SQL 等多種語言的API.Spark 支持超過80個高級運算子使得用戶非常輕易的構建并行計算程式Spark 可以使用基于 Scala, Python, R, SQL的 Shell 互動式查詢. -
通用
Spark 提供一個完整的技術堆疊, 包括 SQL執行, Dataset命令式API, 機器學習庫MLlib, 圖計算框架GraphX, 流計算SparkStreaming用戶可以在同一個應用中同時使用這些工具, 這一點是劃時代的
-
兼容
Spark 可以運行在 Hadoop Yarn, Apache Mesos, Kubernets, Spark Standalone等集群中Spark 可以訪問 HBase, HDFS, Hive, Cassandra 在內的多種資料庫
總結
- 支持 Java, Scala, Python 和 R 的 API
- 可擴展至超過 8K 個節點
- 能夠在記憶體中快取資料集, 以實作互動式資料分析
- 提供命令列視窗, 減少探索式的資料分析的反應時間
1.3. Spark組件
目標
- 理解 Spark 能做什么
- 理解 Spark 的學習路線
Spark 最核心的功能是 RDDs, RDDs 存在于 spark-core 這個包內, 這個包也是 Spark 最核心的包.
同時 Spark 在 spark-core 的上層提供了很多工具, 以便于適應不用型別的計算.
-
Spark-Core 和 彈性分布式資料集(RDDs)
Spark-Core 是整個 Spark 的基礎, 提供了分布式任務調度和基本的 I/O 功能Spark 的基礎的程式抽象是彈性分布式資料集(RDDs), 是一個可以并行操作, 有容錯的資料集合RDDs 可以通過參考外部存盤系統的資料集創建(如HDFS, HBase), 或者通過現有的 RDDs 轉換得到RDDs 抽象提供了 Java, Scala, Python 等語言的APIRDDs 簡化了編程復雜性, 操作 RDDs 類似通過 Scala 或者 Java8 的 Streaming 操作本地資料集合
-
Spark SQL
Spark SQL 在
spark-core基礎之上帶出了一個名為 DataSet 和 DataFrame 的資料抽象化的概念Spark SQL 提供了在 Dataset 和 DataFrame 之上執行 SQL 的能力Spark SQL 提供了 DSL, 可以通過 Scala, Java, Python 等語言操作 DataSet 和 DataFrame它還支持使用 JDBC/ODBC 服務器操作 SQL 語言 -
Spark Streaming
Spark Streaming 充分利用
spark-core的快速調度能力來運行流分析它截取小批量的資料并可以對之運行 RDD Transformation它提供了在同一個程式中同時使用流分析和批量分析的能力 -
MLlib
MLlib 是 Spark 上分布式機器學習的框架. Spark分布式記憶體的架構 比 Hadoop磁盤式 的 Apache Mahout 快上 10 倍, 擴展性也非常優良MLlib 可以使用許多常見的機器學習和統計演算法, 簡化大規模機器學習匯總統計, 相關性, 分層抽樣, 假設檢定, 隨即資料生成支持向量機, 回歸, 線性回歸, 邏輯回歸, 決策樹, 樸素貝葉斯協同過濾, ALSK-meansSVD奇異值分解, PCA主成分分析TF-IDF, Word2Vec, StandardScalerSGD隨機梯度下降, L-BFGS
-
GraphX
GraphX 是分布式圖計算框架, 提供了一組可以表達圖計算的 API, GraphX 還對這種抽象化提供了優化運行
總結
- Spark 提供了 批處理(RDDs), 結構化查詢(DataFrame), 流計算(SparkStreaming), 機器學習(MLlib), 圖計算(GraphX) 等組件
- 這些組件均是依托于通用的計算引擎 RDDs 而構建出的, 所以
spark-core的 RDDs 是整個 Spark 的基礎
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-m7TyO6sl-1620117932871)(https://doc-1256053707.cos.ap-beijing.myqcloud.com/site/20190506/WseAzPXovsHa.png)]
1.4. Spark和Hadoop的異同
| Hadoop | Spark | |
|---|---|---|
| 型別 | 基礎平臺, 包含計算, 存盤, 調度 | 分布式計算工具 |
| 場景 | 大規模資料集上的批處理 | 迭代計算, 互動式計算, 流計算 |
| 延遲 | 大 | 小 |
| 易用性 | API 較為底層, 演算法適應性差 | API 較為頂層, 方便使用 |
| 價格 | 對機器要求低, 便宜 | 對記憶體有要求, 相對較貴 |
2. Spark 集群搭建
目標
- 從 Spark 的集群架構開始, 理解分布式環境, 以及 Spark 的運行原理
- 理解 Spark 的集群搭建, 包括高可用的搭建方式
2.1. Spark 集群結構
目標
- 通過應用運行流程, 理解分布式調度的基礎概念
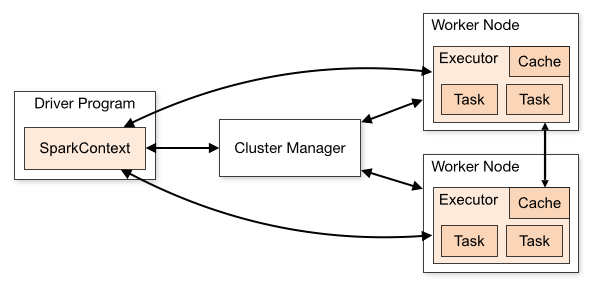
| Spark 如何將程式運行在一個集群中?[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-4mVRkg2c-1620117932873)(https://doc-1256053707.cos.ap-beijing.myqcloud.com/site/20190506/Xr4bx4UiKJpH.png)]Spark 自身是沒有集群管理工具的, 但是如果想要管理數以千計臺機器的集群, 沒有一個集群管理工具還不太現實, 所以 Spark 可以借助外部的集群工具來進行管理整個流程就是使用 Spark 的 Client 提交任務, 找到集群管理工具申請資源, 后將計算任務分發到集群中運行 | |
|---|---|
-
名詞解釋
Driver該行程呼叫 Spark 程式的 main 方法, 并且啟動 SparkContextCluster Manager該行程負責和外部集群工具打交道, 申請或釋放集群資源Worker該行程是一個守護行程, 負責啟動和管理 ExecutorExecutor該行程是一個JVM虛擬機, 負責運行 Spark Task
-
運行一個 Spark 程式大致經歷如下幾個步驟
啟動 Drive, 創建 SparkContextClient 提交程式給 Drive, Drive 向 Cluster Manager 申請集群資源資源申請完畢, 在 Worker 中啟動 ExecutorDriver 將程式轉化為 Tasks, 分發給 Executor 執行
-
問題一: Spark 程式可以運行在什么地方?
集群: 一組協同作業的計算機, 通常表現的好像是一臺計算機一樣, 所運行的任務由軟體來控制和調度****集群管理工具: 調度任務到集群的軟體常見的集群管理工具: Hadoop Yarn, Apache Mesos, KubernetesSpark 可以將任務運行在兩種模式下:單機, 使用執行緒模擬并行來運行程式集群, 使用集群管理器來和不同型別的集群互動, 將任務運行在集群中Spark 可以使用的集群管理工具有:Spark StandaloneHadoop YarnApache MesosKubernetes
-
問題二: Driver 和 Worker 什么時候被啟動?
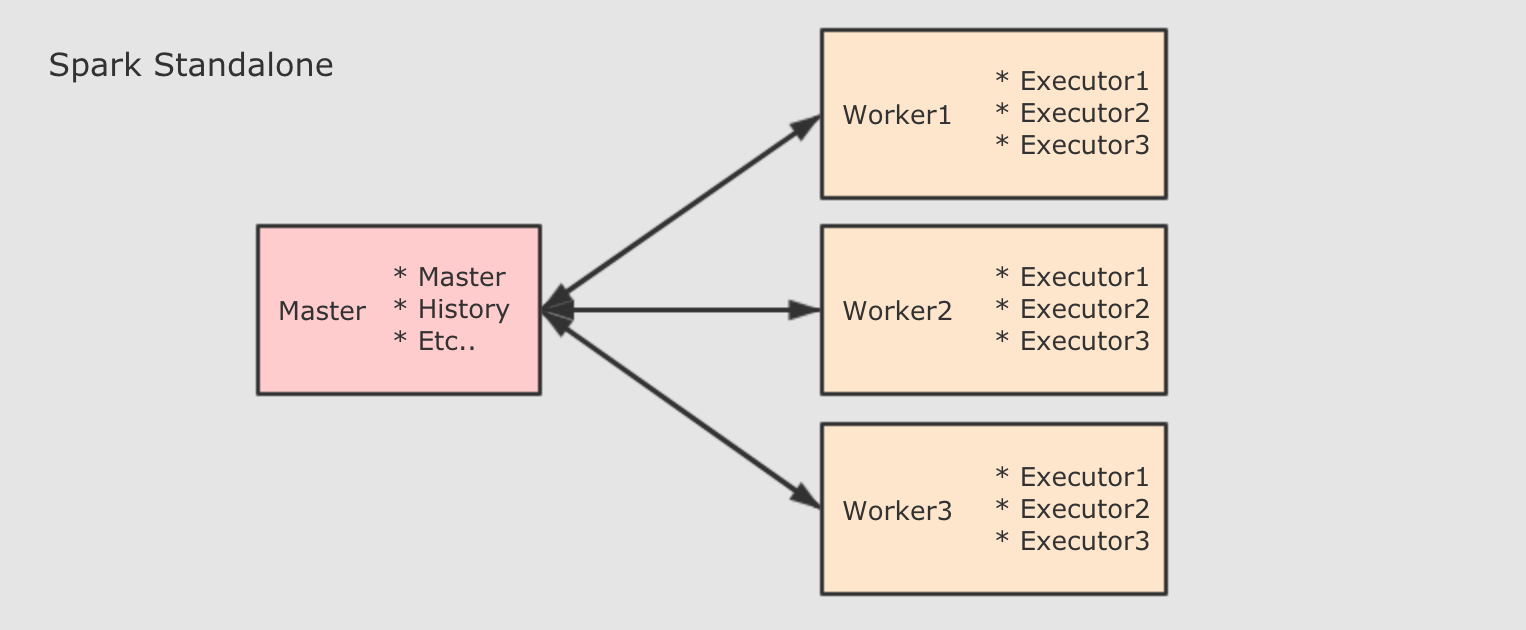 Standalone 集群中, 分為兩個角色: Master 和 Slave, 而 Slave 就是 Worker, 所以在 Standalone 集群中, 啟動之初就會創建固定數量的 WorkerDriver 的啟動分為兩種模式: Client 和 Cluster. 在 Client 模式下, Driver 運行在 Client 端, 在 Client 啟動的時候被啟動. 在 Cluster 模式下, Driver 運行在某個 Worker 中, 隨著應用的提交而啟動
Standalone 集群中, 分為兩個角色: Master 和 Slave, 而 Slave 就是 Worker, 所以在 Standalone 集群中, 啟動之初就會創建固定數量的 WorkerDriver 的啟動分為兩種模式: Client 和 Cluster. 在 Client 模式下, Driver 運行在 Client 端, 在 Client 啟動的時候被啟動. 在 Cluster 模式下, Driver 運行在某個 Worker 中, 隨著應用的提交而啟動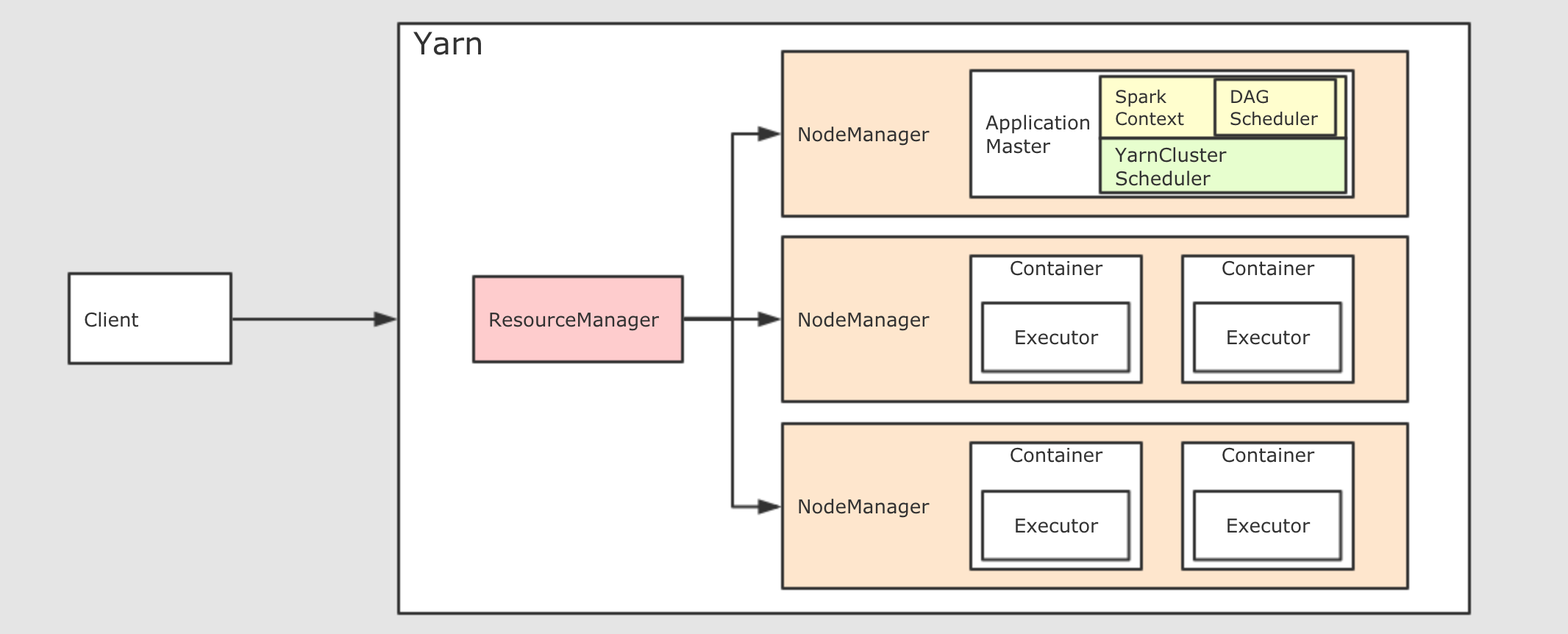 在 Yarn 集群模式下, 也依然分為 Client 模式和 Cluster 模式, 較新的版本中已經逐漸在廢棄 Client 模式了, 所以上圖所示為 Cluster 模式如果要在 Yarn 中運行 Spark 程式, 首先會和 RM 互動, 開啟 ApplicationMaster, 其中運行了 Driver, Driver創建基礎環境后, 會由 RM 提供對應的容器, 運行 Executor, Executor會反向向 Driver 反向注冊自己, 并申請 Tasks 執行在后續的 Spark 任務調度部分, 會更詳細介紹
在 Yarn 集群模式下, 也依然分為 Client 模式和 Cluster 模式, 較新的版本中已經逐漸在廢棄 Client 模式了, 所以上圖所示為 Cluster 模式如果要在 Yarn 中運行 Spark 程式, 首先會和 RM 互動, 開啟 ApplicationMaster, 其中運行了 Driver, Driver創建基礎環境后, 會由 RM 提供對應的容器, 運行 Executor, Executor會反向向 Driver 反向注冊自己, 并申請 Tasks 執行在后續的 Spark 任務調度部分, 會更詳細介紹
總結
Master負責總控, 調度, 管理和協調 Worker, 保留資源狀況等Slave對應 Worker 節點, 用于啟動 Executor 執行 Tasks, 定期向 Master匯報Driver運行在 Client 或者 Slave(Worker) 中, 默認運行在 Slave(Worker) 中
2.2. Spark 集群搭建
目標
-
大致了解 Spark Standalone 集群搭建的程序
這個部分的目的是搭建一套用于測驗和學習的集群, 實際的作業中可能集群環境會更復雜一些
| Node01 | Node02 | Node03 |
|---|---|---|
| Master | Slave | Slave |
| History Server |
-
Step 1 下載和解壓
此步驟假設大家的 Hadoop 集群已經能夠無礙的運行, 并且 Linux 的防火墻和 SELinux 已經關閉, 時鐘也已經同步, 如果還沒有, 請參考 Hadoop 集群搭建部分, 完成以上三件事下載 Spark 安裝包, 下載時候選擇對應的 Hadoop 版本(資料中已經提供了 Spark 安裝包, 直接上傳至集群 Master 即可, 無需遵循以下步驟)
https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz``# 下載 Spark cd /export/softwares wget https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz解壓并拷貝到export/servers``# 解壓 Spark 安裝包 tar xzvf spark-2.2.0-bin-hadoop2.7.tgz # 移動 Spark 安裝包 mv spark-2.2.0-bin-hadoop2.7.tgz /export/servers/spark修改組態檔spark-env.sh, 以指定運行引數進入配置目錄, 并復制一份新的組態檔, 以供在此基礎之上進行修改cd /export/servers/spark/conf cp spark-env.sh.template spark-env.sh vi spark-env.sh將以下內容復制進組態檔末尾# 指定 Java Home export JAVA_HOME=/export/servers/jdk1.8.0 # 指定 Spark Master 地址 export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077 -
Step 2 配置
修改組態檔
slaves, 以指定從節點為止, 從在使用sbin/start-all.sh啟動集群的時候, 可以一鍵啟動整個集群所有的 Worker進入配置目錄, 并復制一份新的組態檔, 以供在此基礎之上進行修改cd /export/servers/spark/conf cp slaves.template slaves vi slaves配置所有從節點的地址node02 node03配置HistoryServer默認情況下, Spark 程式運行完畢后, 就無法再查看運行記錄的 Web UI 了, 通過 HistoryServer 可以提供一個服務, 通過讀取日志檔案, 使得我們可以在程式運行結束后, 依然能夠查看運行程序復制spark-defaults.conf, 以供修改cd /export/servers/spark/conf cp spark-defaults.conf.template spark-defaults.conf vi spark-defaults.conf將以下內容復制到spark-defaults.conf末尾處, 通過這段配置, 可以指定 Spark 將日志輸入到 HDFS 中spark.eventLog.enabled true spark.eventLog.dir hdfs://node01:8020/spark_log spark.eventLog.compress true將以下內容復制到spark-env.sh的末尾, 配置 HistoryServer 啟動引數, 使得 HistoryServer 在啟動的時候讀取 HDFS 中寫入的 Spark 日志# 指定 Spark History 運行引數 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"為 Spark 創建 HDFS 中的日志目錄hdfs dfs -mkdir -p /spark_log -
Step 3 分發和運行
將 Spark 安裝包分發給集群中其它機器
cd /export/servers scp -r spark root@node02:$PWD scp -r spark root@node03:$PWD啟動 Spark Master 和 Slaves, 以及 HistoryServercd /export/servers/spark sbin/start-all.sh sbin/start-history-server.sh
目標
Spark 的集群搭建大致有如下幾個步驟
- 下載和解壓 Spark
- 配置 Spark 的所有從節點位置
- 配置 Spark History server 以便于隨時查看 Spark 應用的運行歷史
- 分發和運行 Spark 集群
2.3. Spark 集群高可用搭建
目標
- 簡要了解如何使用 Zookeeper 幫助 Spark Standalone 高可用
| 對于 Spark Standalone 集群來說, 當 Worker 調度出現問題的時候, 會自動的彈性容錯, 將出錯的 Task 調度到其它 Worker 執行但是對于 Master 來說, 是會出現單點失敗的, 為了避免可能出現的單點失敗問題, Spark 提供了兩種方式滿足高可用使用 Zookeeper 實作 Masters 的主備切換使用檔案系統做主備切換使用檔案系統做主備切換的場景實在太小, 所以此處不再花費筆墨介紹 | |
|---|---|
-
Step 1 停止 Spark 集群
cd /export/servers/spark sbin/stop-all.sh -
Step 2 修改組態檔, 增加 Spark 運行時引數, 從而指定 Zookeeper 的位置
進入
spark-env.sh所在目錄, 打開 vi 編輯cd /export/servers/spark/conf vi spark-env.sh編輯spark-env.sh, 添加 Spark 啟動引數, 并去掉 SPARK_MASTER_HOST 地址
# 指定 Java Home export JAVA_HOME=/export/servers/jdk1.8.0_141 # 指定 Spark Master 地址 # export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077 # 指定 Spark History 運行引數 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log" # 指定 Spark 運行時引數 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark" -
Step 3 分發組態檔到整個集群
cd /export/servers/spark/conf scp spark-env.sh node02:$PWD scp spark-env.sh node03:$PWD -
Step 4 啟動
在
node01上啟動整個集群cd /export/servers/spark sbin/start-all.sh sbin/start-history-server.sh在node02上單獨再啟動一個 Mastercd /export/servers/spark sbin/start-master.sh -
Step 5 查看
node01 master和node02 master的 WebUI你會發現一個是
ALIVE(主), 另外一個是STANDBY(備) 如果關閉一個, 則另外一個成為
如果關閉一個, 則另外一個成為ALIVE, 但是這個程序可能要持續兩分鐘左右, 需要耐心等待# 在 Node01 中執行如下指令 cd /export/servers/spark/ sbin/stop-master.sh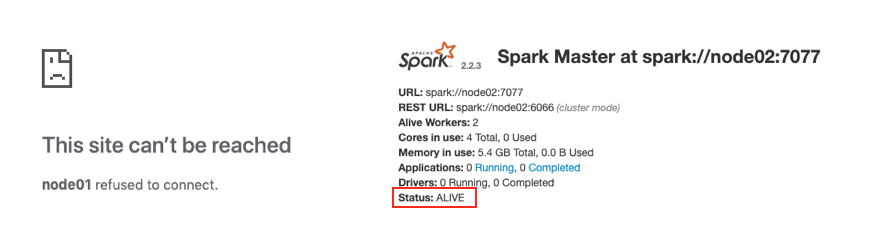
| Spark HA 選舉Spark HA 的 Leader 選舉使用了一個叫做 Curator 的 Zookeeper 客戶端來進行Zookeeper 是一個分布式強一致性的協調服務, Zookeeper 最基本的一個保證是: 如果多個節點同時創建一個 ZNode, 只有一個能夠成功創建. 這個做法的本質使用的是 Zookeeper 的 ZAB 協議, 能夠在分布式環境下達成一致. | |
|---|---|
| Service | port |
|---|---|
| Master WebUI | node01:8080 |
| Worker WebUI | node01:8081 |
| History Server | node01:4000 |
2.4. 第一個應用的運行
目標
- 從示例應用運行中理解 Spark 應用的運行流程
-
流程
Step 1 進入 Spark 安裝目錄中
cd /export/servers/spark/Step 2 運行 Spark 示例任務bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://node01:7077,node02:7077,node03:7077 \ --executor-memory 1G \ --total-executor-cores 2 \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.3.jar \ 100Step 3 運行結果Pi is roughly 3.141550671141551
剛才所運行的程式是 Spark 的一個示例程式, 使用 Spark 撰寫了一個以蒙特卡洛演算法來計算圓周率的任務蒙特卡洛演算法概述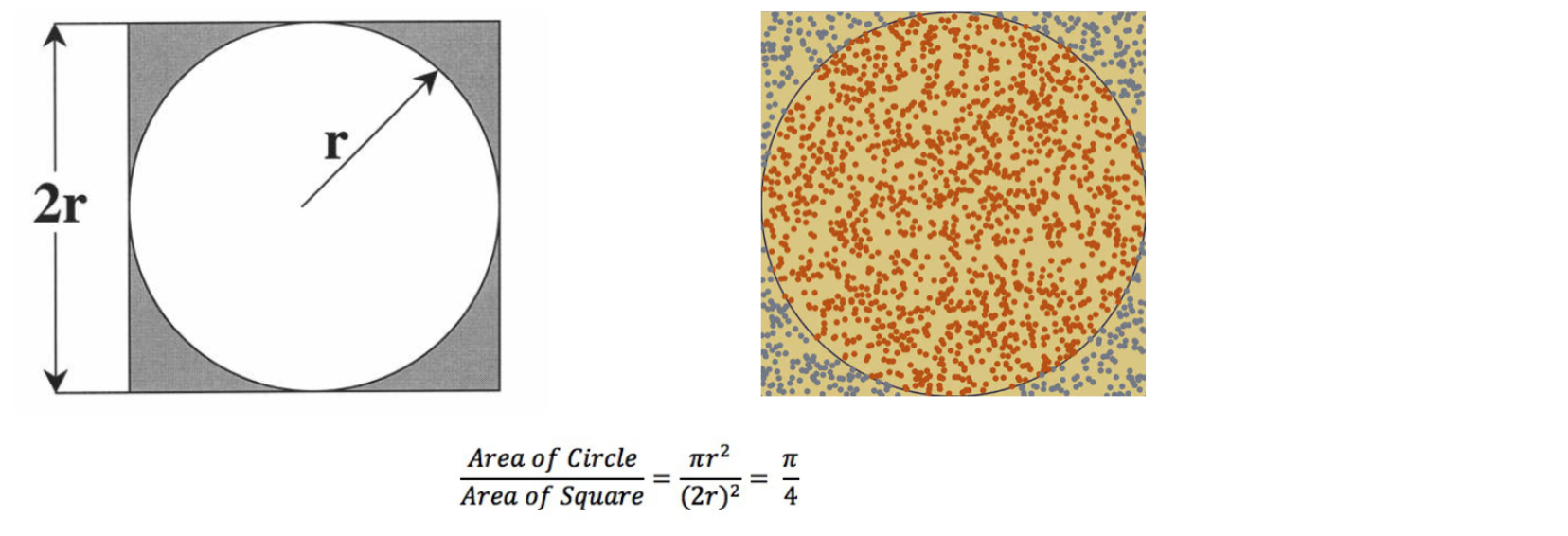 在一個正方形中, 內切出一個圓形 在一個正方形中, 內切出一個圓形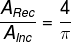 隨機向正方形內均勻投 n 個點, 其落入內切圓內的內外點的概率滿足如下 隨機向正方形內均勻投 n 個點, 其落入內切圓內的內外點的概率滿足如下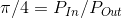 以上就是蒙特卡洛的大致理論, 通過這個蒙特卡洛, 便可以通過迭代回圈投點的方式實作蒙特卡洛演算法求圓周率 以上就是蒙特卡洛的大致理論, 通過這個蒙特卡洛, 便可以通過迭代回圈投點的方式實作蒙特卡洛演算法求圓周率 | |
|---|---|
-
計算程序
不斷的生成隨機的點, 根據點距離圓心是否超過半徑來判斷是否落入園內通過 [外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-3durRgfI-1620117932891)(images/Spark01-cfb9a.png)] 來計算圓周率不斷的迭代
-
思考1: 迭代計算
如果上述的程式使用 MapReduce 該如何撰寫? 是否會有大量的向 HDFS 寫入, 后再次讀取資料的做法? 是否會影響性能?
Spark 為什么擅長這類操作? 大家可以發揮想象, 如何解決這種迭代計算的問題
-
思考2: 資料規模
剛才的計算只做了100次, 如果迭代100億次, 在單機上運行和一個集群中運行誰更合適?
3. Spark 入門
目標
- 通過理解 Spark 小案例, 來理解 Spark 應用
- 理解撰寫 Spark 程式的兩種常見方式
- spark-shell
- spark-submit
-
Spark 官方提供了兩種方式撰寫代碼, 都比較重要, 分別如下
spark-shellSpark shell 是 Spark 提供的一個基于 Scala 語言的互動式解釋器, 類似于 Scala 提供的互動式解釋器, Spark shell 也可以直接在 Shell 中撰寫代碼執行 這種方式也比較重要, 因為一般的資料分析任務可能需要探索著進行, 不是一蹴而就的, 使用 Spark shell 先進行探索, 當代碼穩定以后, 使用獨立應用的方式來提交任務, 這樣是一個比較常見的流程spark-submitSpark submit 是一個命令, 用于提交 Scala 撰寫的基于 Spark 框架, 這種提交方式常用作于在集群中運行任務
3.1. Spark shell 的方式撰寫 WordCount
概要
在初始階段作業可以全部使用 Spark shell 完成, 它可以加快原型開發, 使得迭代更快, 很快就能看到想法的結果. 但是隨著專案規模越來越大, 這種方式不利于代碼維護, 所以可以撰寫獨立應用. 一般情況下, 在探索階段使用 Spark shell, 在最終使用獨立應用的方式撰寫代碼并使用 Maven 打包上線運行
接下來使用 Spark shell 的方式撰寫一個 WordCount
Spark shell 簡介啟動 Spark shell 進入 Spark 安裝目錄后執行 spark-shell --master master 就可以提交Spark 任務Spark shell 的原理是把每一行 Scala 代碼編譯成類, 最終交由 Spark 執行 | |
|---|---|
Master地址的設定Master 的地址可以有如下幾種設定方式Table 3. master地址解釋local[N]使用 N 條 Worker 執行緒在本地運行spark://host:port在 Spark standalone 中運行, 指定 Spark 集群的 Master 地址, 埠默認為 7077mesos://host:port在 Apache Mesos 中運行, 指定 Mesos 的地址yarn在 Yarn 中運行, Yarn 的地址由環境變數 HADOOP_CONF_DIR來指定 | |
|---|---|
-
Step 1 準備檔案
在 Node01 中創建檔案
/export/data/wordcount.txt``hadoop spark flume spark hadoop flume hadoop -
Step 2 啟動 Spark shell
cd /export/servers/spark bin/spark-shell --master local[2] -
Step 3 執行如下代碼
scala> val sourceRdd = sc.textFile("file:///export/data/wordcount.txt") sourceRdd: org.apache.spark.rdd.RDD[String] = file:///export/data/wordcount.txt MapPartitionsRDD[1] at textFile at <console>:24 scala> val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1)) flattenCountRdd: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:26 scala> val aggCountRdd = flattenCountRdd.reduceByKey(_ + _) aggCountRdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:28 scala> val result = aggCountRdd.collect result: Array[(String, Int)] = Array((spark,2), (hadoop,3), (flume,2))
sc上述代碼中 sc 變數指的是 SparkContext, 是 Spark 程式的背景關系和入口正常情況下我們需要自己創建, 但是如果使用 Spark shell 的話, Spark shell 會幫助我們創建, 并且以變數 sc 的形式提供給我們呼叫 | |
|---|---|
-
運行流程
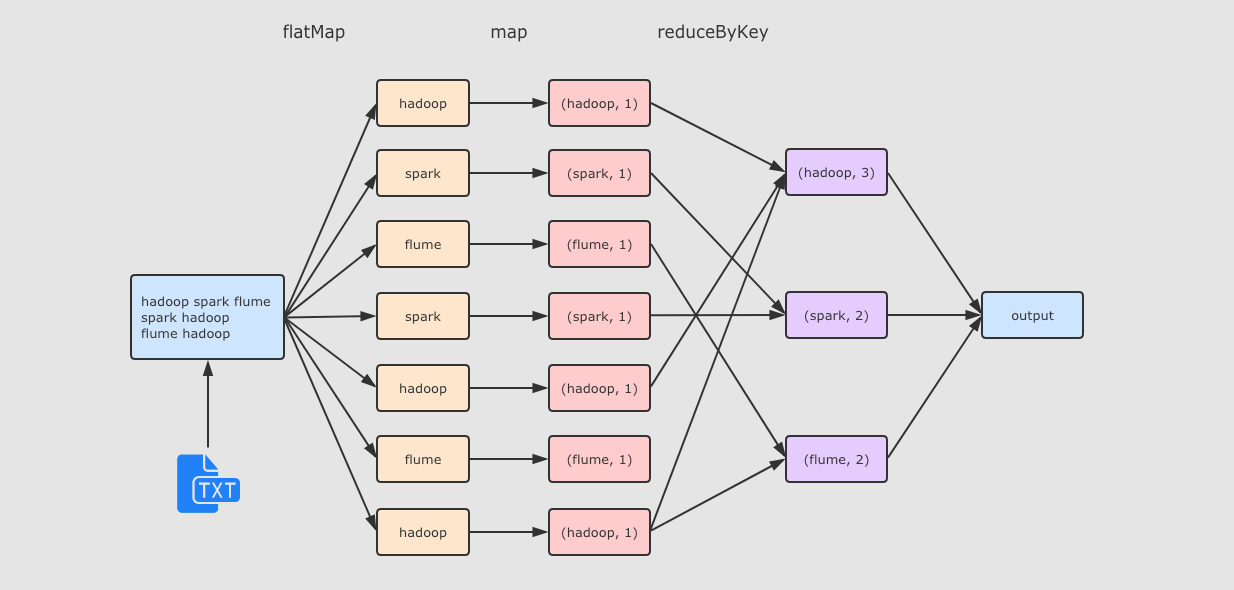
flatMap(_.split(" "))將資料轉為陣列的形式, 并展平為多個資料map_, 1將資料轉換為元組的形式reduceByKey(_ + _)計算每個 Key 出現的次數
總結
- 使用 Spark shell 可以快速驗證想法
- Spark 框架下的代碼非常類似 Scala 的函式式呼叫
3.2. 讀取 HDFS 上的檔案
目標
- 理解 Spark 訪問 HDFS 的兩種方式
-
Step 1 上傳檔案到 HDFS 中
cd /export/data hdfs dfs -mkdir /dataset hdfs dfs -put wordcount.txt /dataset/ -
Step 2 在 Spark shell 中訪問 HDFS
val sourceRdd = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt") val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1)) val aggCountRdd = flattenCountRdd.reduceByKey(_ + _) val result = aggCountRdd.collect
如何使得 Spark 可以訪問 HDFS?可以通過指定 HDFS 的 NameNode 地址直接訪問, 類似于上面代碼中的 sc.textFile("hdfs://node01:8020/dataset/wordcount.txt") 也可以通過向 Spark 配置 Hadoop 的路徑, 來通過路徑直接訪問1.在 也可以通過向 Spark 配置 Hadoop 的路徑, 來通過路徑直接訪問1.在 spark-env.sh 中添加 Hadoop 的配置路徑export HADOOP_CONF_DIR="/etc/hadoop/conf"2.在配置過后, 可以直接使用 hdfs:///路徑 的形式直接訪問 3.在配置過后, 也可以直接使用路徑訪問 3.在配置過后, 也可以直接使用路徑訪問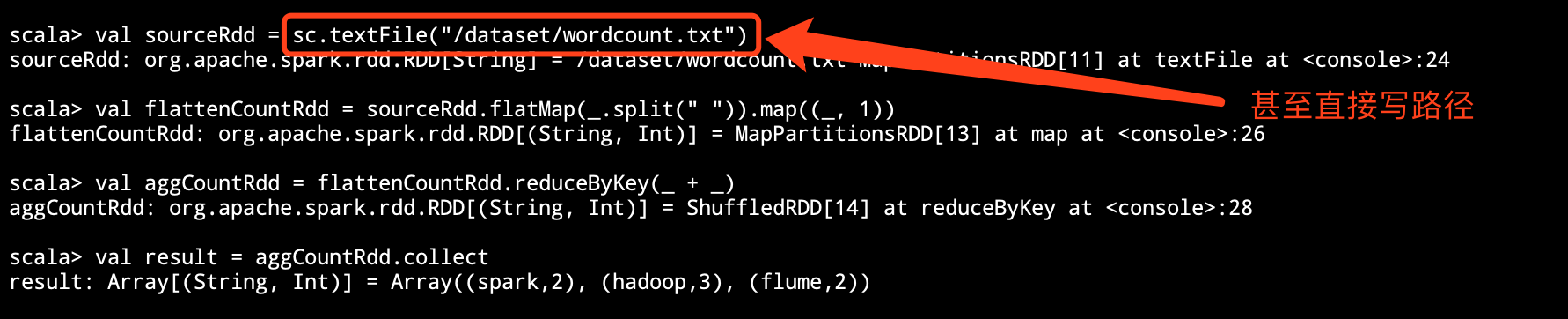 | |
|---|---|
3.4. 撰寫獨立應用提交 Spark 任務
目標
- 理解如何撰寫 Spark 獨立應用
- 理解 WordCount 的代碼流程
-
Step 1 創建工程
創建 IDEA 工程
 →
→  →
→ 
 →
→  →
→  增加 Scala 支持右鍵點擊工程目錄
增加 Scala 支持右鍵點擊工程目錄  選擇增加框架支持
選擇增加框架支持  選擇 Scala 添加框架支持
選擇 Scala 添加框架支持 -
Step 2 撰寫 Maven 組態檔
pom.xml工程根目錄下增加檔案
pom.xml添加以下內容<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId> <artifactId>spark</artifactId> <version>0.1.0</version> <properties> <scala.version>2.11.8</scala.version> <spark.version>2.2.0</spark.version> <slf4j.version>1.7.16</slf4j.version> <log4j.version>1.2.17</log4j.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>jcl-over-slf4j</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass></mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>因為在pom.xml中指定了 Scala 的代碼目錄, 所以創建目錄src/main/scala和目錄src/test/scala創建 Scala objectWordCount -
Step 3 撰寫代碼
object WordCounts { def main(args: Array[String]): Unit = { // 1. 創建 Spark Context val conf = new SparkConf().setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) // 2. 讀取檔案并計算詞頻 val source: RDD[String] = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt", 2) val words: RDD[String] = source.flatMap { line => line.split(" ") } val wordsTuple: RDD[(String, Int)] = words.map { word => (word, 1) } val wordsCount: RDD[(String, Int)] = wordsTuple.reduceByKey { (x, y) => x + y } // 3. 查看執行結果 println(wordsCount.collect) } }和 Spark shell 中不同, 獨立應用需要手動創建 SparkContext -
Step 4 運行
運行 Spark 獨立應用大致有兩種方式, 一種是直接在 IDEA 中除錯, 另一種是可以在提交至 Spark 集群中運行, 而 Spark 又支持多種集群, 不同的集群有不同的運行方式直接在 IDEA 中運行 Spark 程式在工程根目錄創建檔案夾和檔案
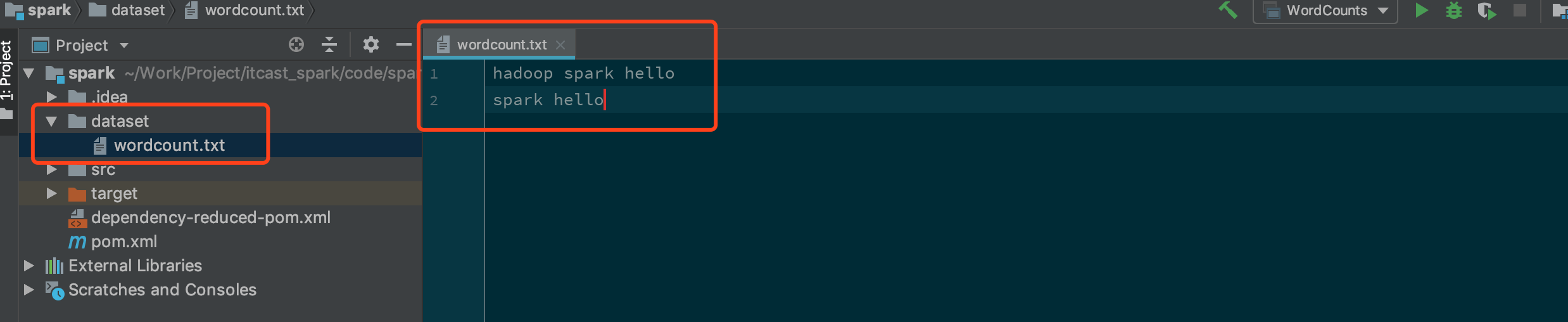 修改讀取檔案的路徑為
修改讀取檔案的路徑為dataset/wordcount.txt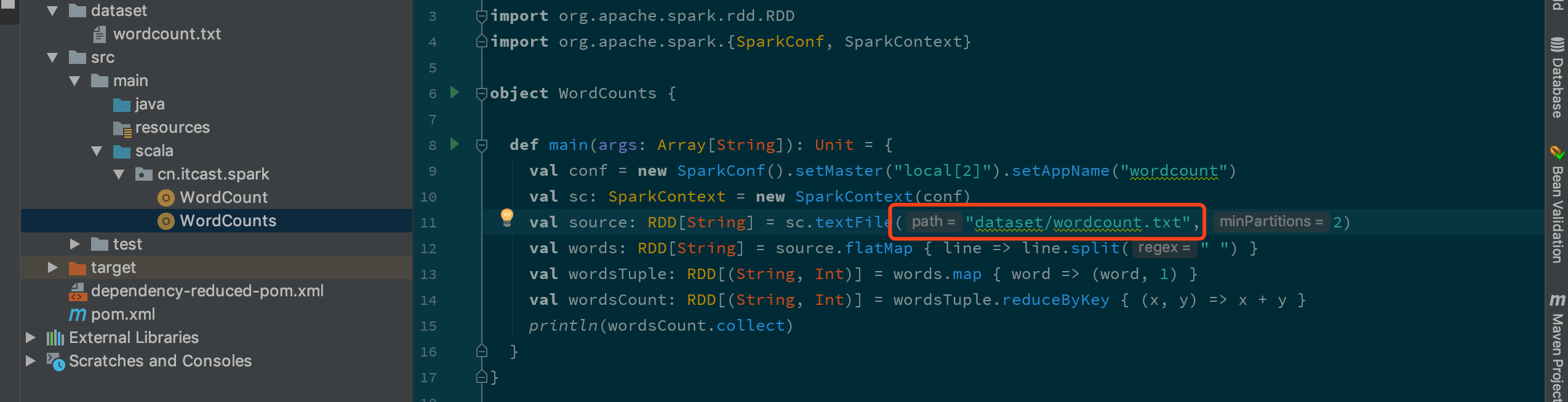 右鍵運行 Main 方法
右鍵運行 Main 方法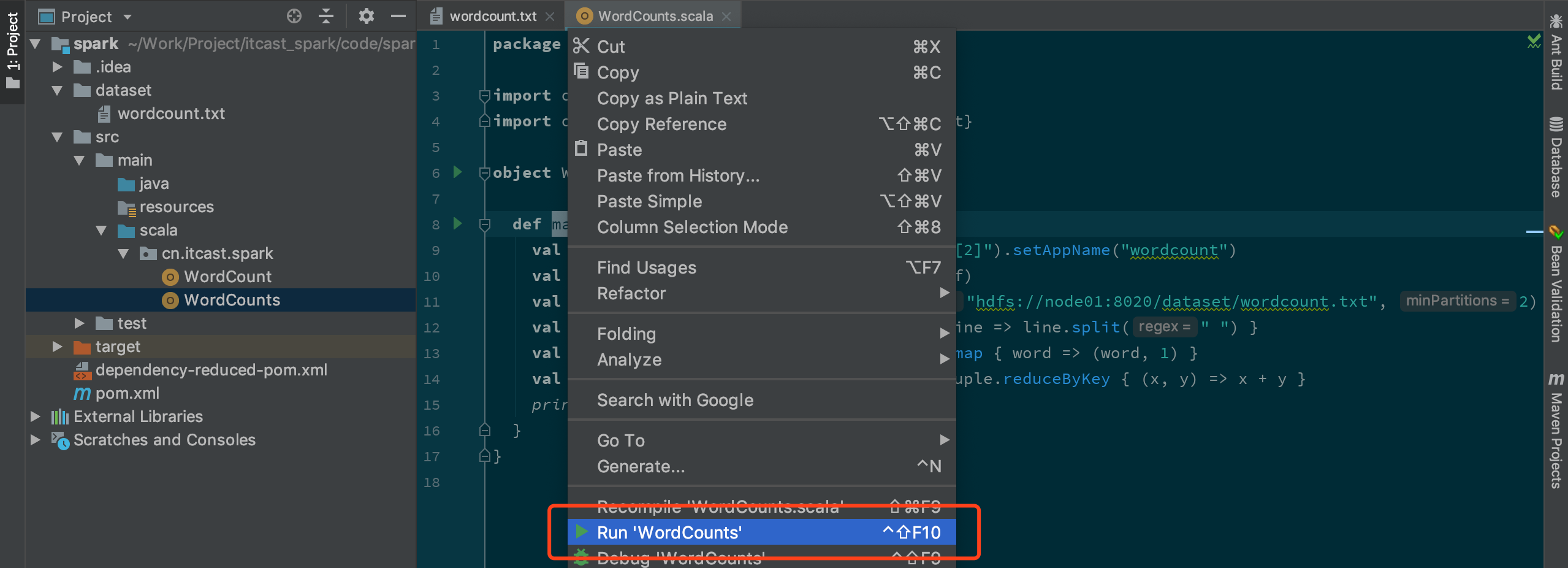 spark-submit 命令
spark-submit 命令spark-submit [options] <app jar> <app options>``app jar程式 Jar 包app options程式 Main 方法傳入的引數options提交應用的引數, 可以有如下選項Table 4. options 可選引數引數解釋--master <url>同 Spark shell 的 Master, 可以是spark, yarn, mesos, kubernetes等 URL--deploy-mode <client or cluster>Driver 運行位置, 可選 Client 和 Cluster, 分別對應運行在本地和集群(Worker)中--class <class full name>Jar 中的 Class, 程式入口--jars <dependencies path>依賴 Jar 包的位置--driver-memory <memory size>Driver 程式運行所需要的記憶體, 默認 512M--executor-memory <memory size>Executor 的記憶體大小, 默認 1G提交到 Spark Standalone 集群中運行在 IDEA 中使用 Maven 打包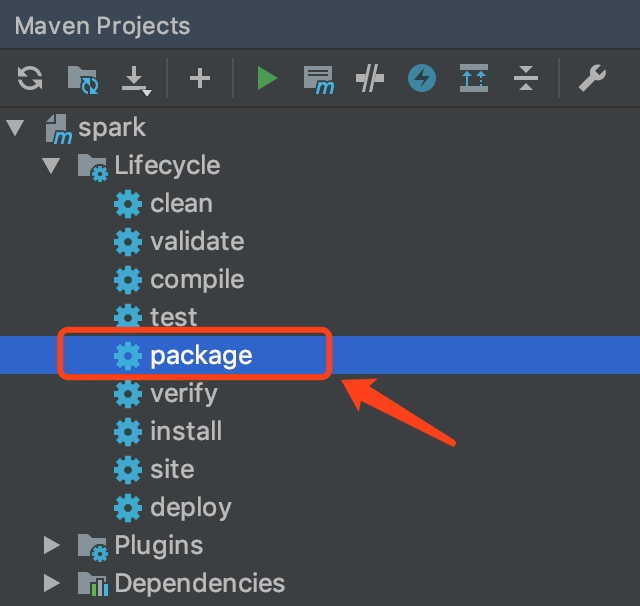 拷貝打包的 Jar 包上傳到 node01 中
拷貝打包的 Jar 包上傳到 node01 中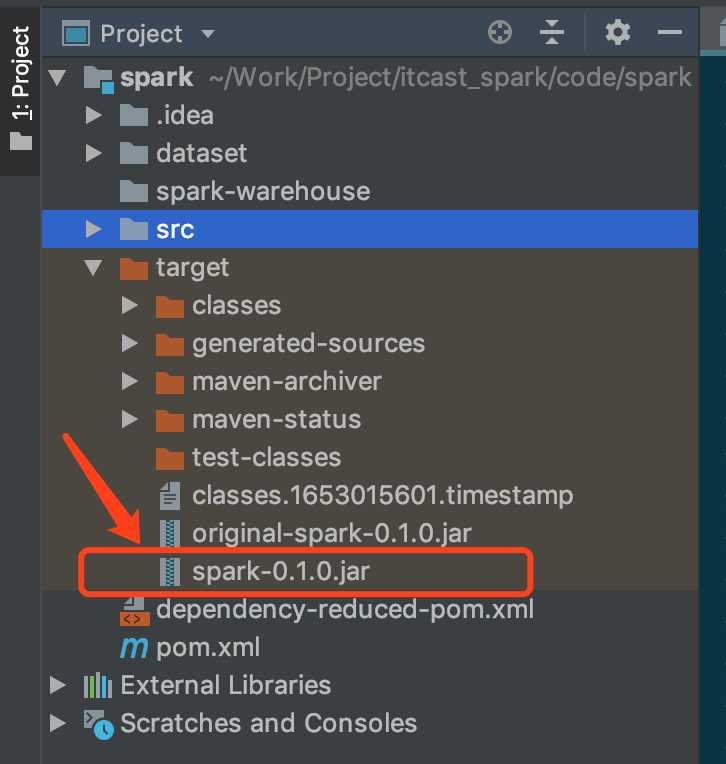 在 node01 中 Jar 包所在的目錄執行如下命令
在 node01 中 Jar 包所在的目錄執行如下命令spark-submit --master spark://node01:7077 \ --class cn.itcast.spark.WordCounts \ original-spark-0.1.0.jar如何在任意目錄執行 spark-submit 命令?在/etc/profile中寫入如下export SPARK_BIN=/export/servers/spark/bin export PATH=$PATH:$SPARK_BIN執行/etc/profile使得配置生效source /etc/profile
總結: 三種不同的運行方式
-
Spark shell
作用一般用作于探索階段, 通過 Spark shell 快速的探索資料規律當探索階段結束后, 代碼確定以后, 通過獨立應用的形式上線運行功能Spark shell 可以選擇在集群模式下運行, 還是在執行緒模式下運行Spark shell 是一個互動式的運行環境, 已經內置好了 SparkContext 和 SparkSession 物件, 可以直接使用Spark shell 一般運行在集群中安裝有 Spark client 的服務器中, 所以可以自有的訪問 HDFS
-
本地運行
作用在撰寫獨立應用的時候, 每次都要提交到集群中還是不方便, 另外很多時候需要除錯程式, 所以在 IDEA 中直接運行會比較方便, 無需打包上傳了功能因為本地運行一般是在開發者的機器中運行, 而不是集群中, 所以很難直接使用 HDFS 等集群服務, 需要做一些本地配置, 用的比較少需要手動創建 SparkContext
-
集群運行
作用正式環境下比較多見, 獨立應用撰寫好以后, 打包上傳到集群中, 使用
spark-submit來運行, 可以完整的使用集群資源功能同時在集群中通過spark-submit來運行程式也可以選擇是用執行緒模式還是集群模式集群中運行是全功能的, HDFS 的訪問, Hive 的訪問都比較方便需要手動創建 SparkContext
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283196.html
標籤:其他