HDFS入門(四)—— HDFS的讀寫流程(圖文詳解步驟2021)
文章目錄
- HDFS入門(四)—— HDFS的讀寫流程(圖文詳解步驟2021)
- 4.1 HDFS 寫資料流程
- 4.1.1 剖析檔案 寫入
- 4.1.2 網路拓撲- 節點 距離計算
- 4.1.3 機架 感知 (副本 存盤 節點 選擇)
- 1 )機架感知說明
- 2 )Hadoop3.1.3 副本節點選擇
- 4.2 HDFS 讀資料流程
4.1 HDFS 寫資料流程
4.1.1 剖析檔案 寫入
借用尚硅谷的一個架構圖:
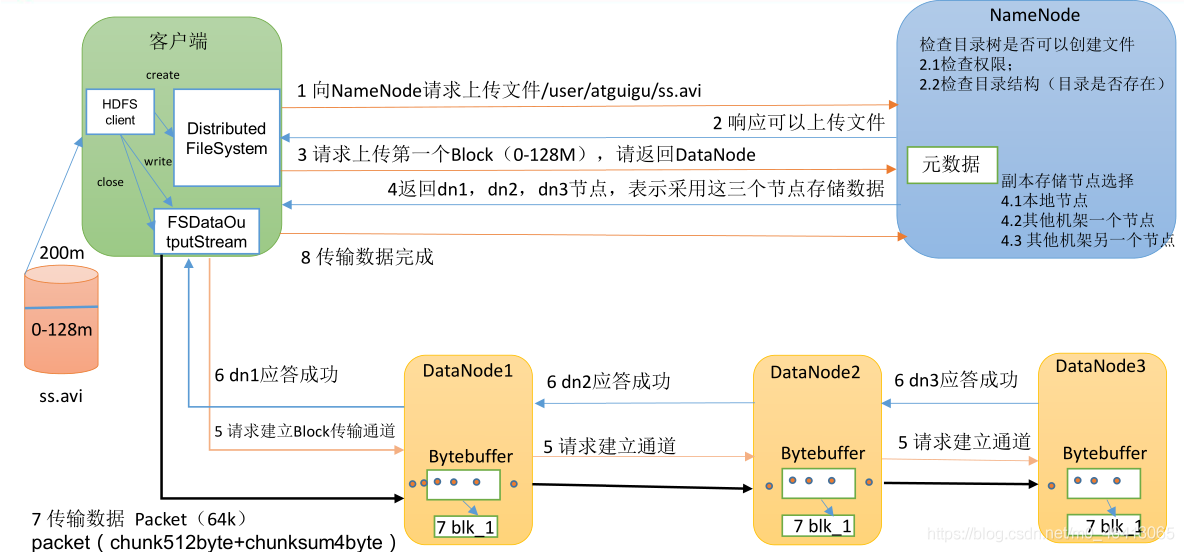
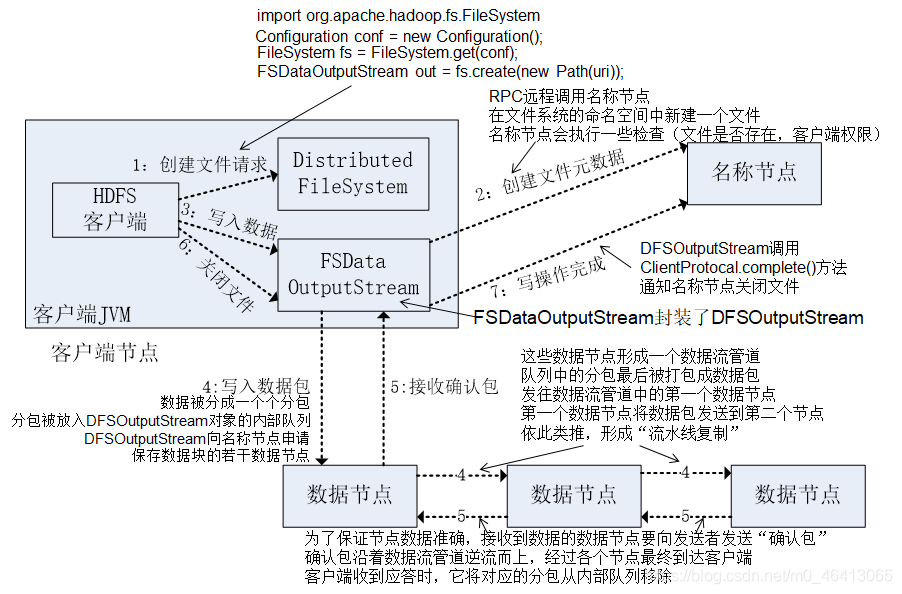
(1)客戶端通過 Distributed FileSystem 模塊向 NameNode 請求上傳檔案,NameNode 檢
]查目標檔案是否已存在,父目錄是否存在,
(2)NameNode 回傳是否可以上傳,
(3)客戶端請求第一個 Block 上傳到哪幾個 DataNode 服務器上,
(4)NameNode 回傳 3 個 DataNode 節點,分別為 dn1、dn2、dn3,
(5) 客戶端通過 FSDataOutputStream 模塊請求 dn1 上傳資料, dn1 收到請求會繼續呼叫
dn2,然后 dn2 呼叫 dn3,將這個通信管道建立完成,
(6)dn1、dn2、dn3 逐級應答客戶端,
(7) 客戶端開始往 dn1 上傳第一個 Block (先從磁盤讀取資料放到一個本地記憶體快取) ,
以 Packet 為單位,dn1 收到一個 Packet 就會傳給 dn2,dn2 傳給 dn3;dn1 每傳一個 packet
會放入一個應答佇列等待應答,
(8)當一個 Block 傳輸完成之后, 客戶端再次請求 NameNode 上傳第二個 Block 的服務
器,(重復執行 3-7 步),
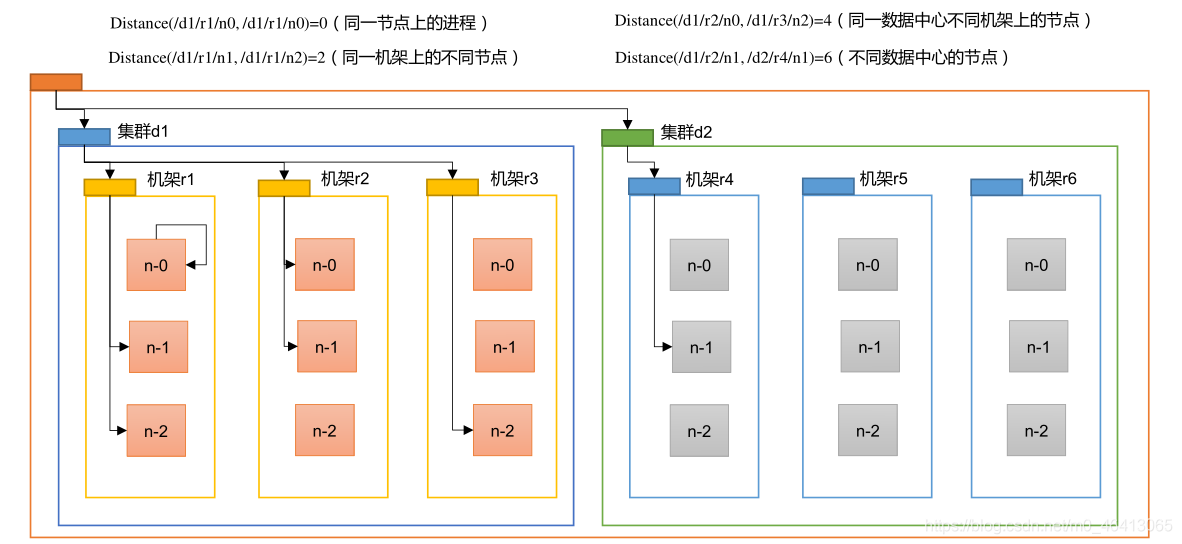
4.1.2 網路拓撲- 節點 距離計算
在 HDFS 寫資料的程序中,NameNode 會選擇距離待上傳資料最近距離的 DataNode 接
收資料,那么這個最近距離怎么計算呢?
節點距離:兩個節點到達最近的共同祖先的距離總和,
例如,假設有資料中心 d1 機架 r1 中的節點 n1,該節點可以表示為/d1/r1/n1,利用這種
標記,這里給出四種距離描述,
4.1.3 機架 感知 (副本 存盤 節點 選擇)
1 )機架感知說明
(1)官方說明
http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
(2)原始碼說明
Crtl + n 查找 BlockPlacementPolicyDefault,在該類中查找 chooseTargetInOrder 方法,
2 )Hadoop3.1.3 副本節點選擇
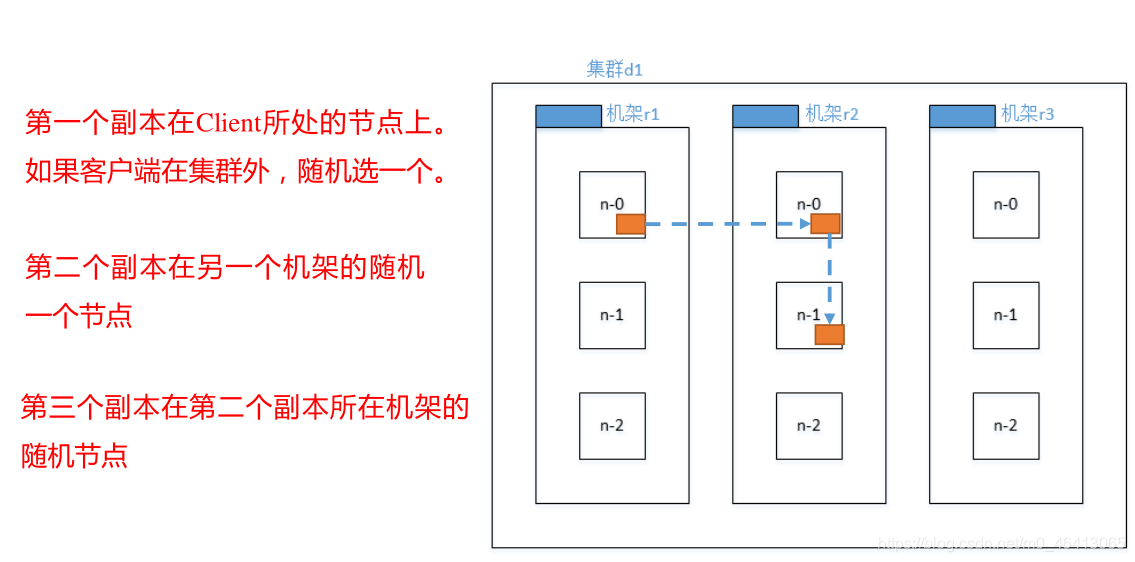
第一個選擇最近的節點
第二個節點跨機架保證副本的可靠性
第三個節點還是兼顧效率
4.2 HDFS 讀資料流程
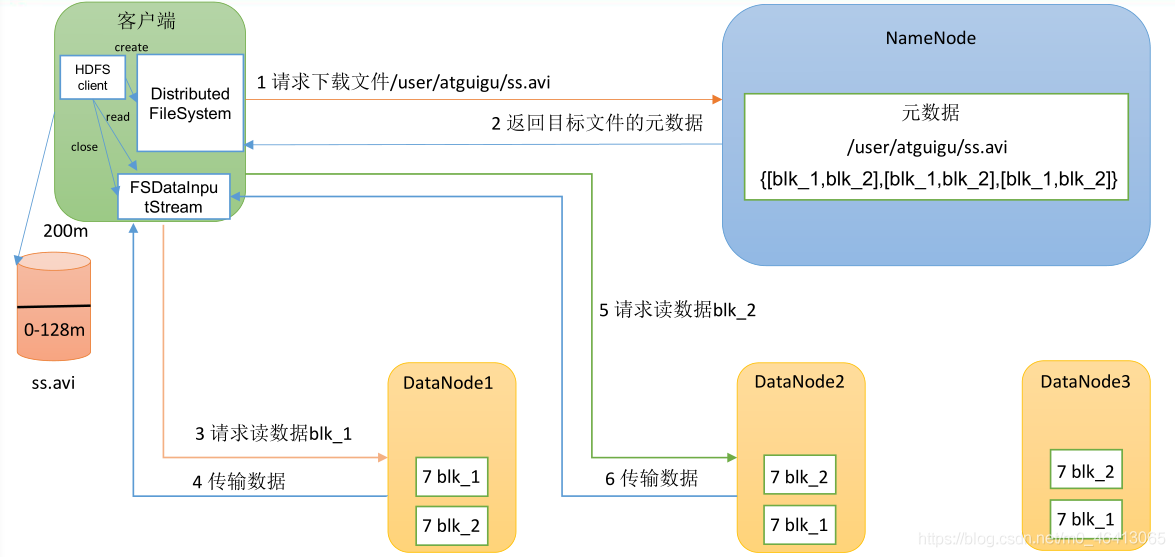
(1)客戶端通過 DistributedFileSystem 向 NameNode 請求下載檔案,NameNode 通過查詢元資料,找到檔案塊所在的 DataNode 地址,
(2)挑選一臺 DataNode(就近原則,然后隨機(會考慮當前節點的負載能力))服務器,請求讀取資料,
(3)DataNode 開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以 Packet 為單位來做校驗),
(4)客戶端以 Packet 為單位接收,先在本地快取,然后寫入目標檔案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283197.html
標籤:其他
上一篇:大資料Spark入門以及集群搭建
下一篇:Apache Hive基礎知識