我的hive學習筆記
一、簡介
Apache Hive是一個提供訪問HDFS上存盤資料的SQL介面的資料倉庫,適合存盤資料不會頻繁變化,且不需要快速回應給出結果的場景,Hive2.1.0暫不支持記錄級別的更新、洗掉,
二、架構

JobTracker負責分配任務和資源管理
TaskTracker負責具體執行
Driver負責SQL編譯、優化、執行
MetaStore存盤元資料
1 Hive陳述句的執行程序
- 客戶端接收到客戶端的SQL
- 呼叫Driver,
- 從MetaStore讀取元資料
- 轉換成運算子
- 呼叫Hadoop或其他執行引擎執行
- client回傳查詢結果
2 元資料的三種模式
1 單用戶模式(不建議使用此模式)
此模式連接到一個In-memory的資料庫Derby,同一時間只允許一個用戶連接
2 多用戶模式(推薦使用此模式)
通過網路連接遠程資料庫,允許多個用戶連接
3 遠程服務模式
多了一層封裝,可以提供用戶通過Thrift協議呼叫服務來訪問元資料
三、客戶端命令列工具
Hive Cli
Hive Cli是一個客戶端命令列界面,是和Hive互動的最常用的方式,使用Cli,用戶可以建表、匯入資料、查詢等等,
注意:Hive1.0.0 后 Hive Cli不推薦使用,推薦的是Beeline Cli
案例:·
# 切換到hdfs用戶
su hdfs
# 啟動Hive Cli
hive
# 查看所有資料庫
show Databases;
# 使用default資料庫
use default;
# 查看所有的表
show tables;
Hive Cli 官方參考檔案:
https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-RunningHiveCLI
Beeline Cli
Hive 1.0.0后推薦使用Beeline Cli
案例:
# 切換到hdfs用戶
su hdfs
# 啟動beeline
beeline
# 連接指定ip,port和用戶名密碼的HiveServer2
!connect jdbc:hive2://localhost:10000 username passward
# 查看所有資料庫
show databases;
# 使用default;
use default;
# 查看所有表
show tables;
Beeline 官方參考檔案:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-Beeline%E2%80%93NewCommandLineShell
四、資料型別
基本資料型別
| 型別 | 描述 | 示例 |
|---|---|---|
| tinyint | 1個位元組有符號整數 | 1 |
| smallint | 2個位元組有符號整數 | 2 |
| int | 4個位元組有符號整數 | 3 |
| bigint | 8個位元組有符號整數 | 4 |
| flout | 4個位元組單精度浮點數 | 1.0 |
| double | 8個位元組雙精度浮點數 | 1.0 |
| boolean | 布林值 | true |
| string | 字串,無長度限制 | “hello” |
復合資料型別
| 型別 | 描述 | 示例 |
|---|---|---|
| ARRAY | 有序串列,欄位型別必須相同 | array(1,2,3) |
| MAP | 無序key-value映射,key的型別必須為基本型別,value可以是任意型別,同一個MAP中key的型別必須相同,value的型別也必須相同 | map(“a”:1,“b”:2,“c”:3) |
| struct | 可以包含不同資料型別的元素,多個欄位為一組 | struct(“zhangsan”,23,3000) |
資料型別 官方參考檔案:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types#LanguageManualTypes-Overview
五、語法
這里只詳細記錄常用的,冷門操作可以看官方檔案
1 DDL
資料庫定義語言
DDL 官方檔案:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-Overview
- CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX
- DROP DATABASE/SCHEMA, TABLE, VIEW, INDEX
- TRUNCATE TABLE
- ALTER DATABASE/SCHEMA, TABLE, VIEW
- MSCK REPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS)
- SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, VIEWS, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS, CREATE TABLE
- DESCRIBE DATABASE/SCHEMA, table_name, view_name, materialized_view_name
1.1 Create/Drop/Alter/Use Database
資料庫的創建、洗掉、修改、使用操作
1.1.1 Create Database
創建資料庫
語法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
- DATABASE和SCHEMA是一個意思,類似Mysql里的Database
- COMMENT 備注,添加備注后,查看庫的時資訊可以看到
- LOCATION 默認庫的路徑,創建內部表后,內部表的默認父路徑
- MANAGEDLOCATION 默認的管理庫的路徑,創建外部表后,外部表的默認父路徑
- DBPROPERTIES 自定義設定一些屬性,比如可以指定username=zhangsan,create_time=2021-12-12 12:12:12
示例:
create database if not exists test_db_1
comment "test database"
with dbproperties (create_user=zhangsan);
1.1.2 Use Database
使用資料庫
語法:
USE database_name;
示例:
use test_db_1 ;
1.1.3 Drop Database
洗掉資料庫
語法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
- CASCADE 假如資料庫里有表,默認洗掉時會提示無法洗掉,此時加上CASCADE 即可強制洗掉(慎用)
案例:
# 強制洗掉資料庫,即使有表存在也會一起洗掉
drop database if exists test_db_1 cascade;
1.2 Create/Drop/Truncate Table
表的創建、洗掉、截斷操作
1.2.1 Create Table
語法:
-- 語法1-直接建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
-- 語法2-使用現有表建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
關鍵詞解釋:
- TEMPORARY 建表時添加這個關鍵字建好的表是臨時表,當前會話退出后表就會被洗掉,用的較少
- EXTERNAL 建表時指定external的表是外部表,什么是外部表下面有介紹
- IF NOT EXISTS 如果表不存在則創建,存在則正常退出
- db_name. 指定要創建的表位于哪個資料庫
- table_name 指定表名
- col_name data_type COMMENT col_comment 欄位名和欄位對應的型別,COMMENT的意思是申明欄位的備注,備注內容為col_comment;可以有多個
- COMMENT table_comment 申明表的備注,備注內容為table_comment
- PARTITIONED BY (col_name data_type [COMMENT col_comment], …) 指定根據哪些欄位磁區,col_name data_type COMMENT col_comment 指定磁區欄位名和欄位型別、備注和備注內容;可以有多個
- CLUSTERED BY (col_name, col_name, …) [SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS
CLUSTERED BY申明分桶,根據型別為欄位名為col_name等一個或多個欄位分桶,SORTED BY根據列名為col_name的欄位進行排序,asc是順序,desc是倒序,INTO num_buckets BUCKETS指定分幾個桶,桶的數量是num_buckets - SKEWED BY (col_name, col_name, …) 指定資料傾斜列,可以提高有資料傾斜列時的查詢性能
- ON ((col_value, col_value, …) 指定具體的傾斜列的傾斜的值
- STORED AS DIRECTORIES 指定使用串列桶,為傾斜的欄位的值創建子目錄,查詢時提高性能
- ROW FORMAT row_format 指定欄位、array、map、行按照什么規則切分,切分規則如下
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] – (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)] - STORED AS file_format 指定檔案格式,支持TEXTFILE(默認)、SEQUENCEFILE、RCFILE、ORC、PARQUET、AVRO、JSONFILE(Hive4.0.0后支持的型別,其他型別都是1.0.0版本之前就支持的型別)
- LOCATION hdfs_path 指定表在HDFS上的存盤路徑
- TBLPROPERTIES (property_name=property_value, …) 指定表的自定義屬性,既可以修改預先定義好的屬性也可以自定義添加新屬性,這里類似資料庫的自定義屬性
- AS select_statement 以查詢結果作為表結構
Hive表有四種,內部表,外部表,磁區表,分桶表
- 內部表是不指定external和temporary時默認的建表方式,這種方式創建的表被洗掉時,資料也會被一起洗掉,表定義和資料強關聯
- 外部表是指定external的表,這種方式創建的表被洗掉時,資料不會被一起洗掉,表定義和資料弱關聯
- 磁區表就是有磁區的表,磁區就是把資料安裝某個或多個欄位分別存在不同的目錄下,在查詢時可以根據磁區篩選資料,減少讀取的資料量
- 分桶表
案例:
-- 內部表
create table if not exists default.test_tb_1(
user_id int "user's id",
user_name string "user's name"
);
-- 外部表
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';
-- 磁區表
create external table if not exists default.test_tb_2(
user_id int "user's id",
user_name string "user's name"
)partitioned by (create_date string,org_num int);
-- 分桶表
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
1.2.2 Drop Table
洗掉表
語法:
DROP TABLE [IF EXISTS] table_name [PURGE];
關鍵字解釋:
- PURGE 跳過回收站,在不指定purge的默認情況下,資料會進入HDFS的.Trash/Current路徑下同時表定義會被完全洗掉,誤刪后可以通過次項找回,但指定purge后,資料將被跳過回收站直接洗掉(慎用)
案例:
drop table if exists default.test_tb_1;
1.2.3 Truncate Table
清空表,只能清空內部表或內部表磁區的資料
語法:
TRUNCATE TABLE table_name [PARTITION partition_spec];
關鍵字解釋:
- table_name 要清空的表名
- PARTITION partition_spec 要清空具體磁區
案例:
truncate table default.test_tb_1;
1.2.3 Alter Table/Partition/Column
修改表、磁區、列
內容較多,常用的不多,建議直接查看官方檔案
此部分內容的官方檔案:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterTable
2 DML
資料處理語言
2.1 將資料匯入表
注意:
- 多個磁區欄位是有先后順序的;
- 動態插入磁區表時需要開啟動態磁區(set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;);
- 匯入磁區表或動態插入磁區表時,磁區欄位必須按順序排到所有非磁區欄位后
2.1.1 Loading files into tables
將檔案匯入到表
語法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
關鍵詞意思:
- LOCAL 指定檔案存放在本地檔案系統,不指定LOCAL默認為HDFS檔案系統;從本地匯入時是復制,匯入表后原有資料仍舊存在;從HDFS匯入時,是移動,匯入后原路徑資料會消失;
- filepath 檔案的路徑
- OVERWRITE 指定清空表再匯入新資料,默認為append(追加)
- tablename 要匯入的表
- PARTITION (partcol1=val1, partcol2=val2 …) 如果上面的表是磁區表,那么需要指定要匯入的磁區;有多個磁區需要指定多個磁區
案例:
# 匯入本地的資料到非磁區表,追加匯入
LOAD DATA LOCAL INPATH '/home/admin/test/test.txt' INTO TABLE test_1;
# 匯入本地的資料到磁區表的指定磁區,追加匯入
LOAD DATA LOCAL INPATH '/home/admin/test/test.txt' INTO TABLE test_1 PARTITIO(pt='20200101');
# 匯入HDFS的資料到非磁區表,覆寫原有資料
LOAD DATA INPATH '/home/admin/test/test.txt' OVERWRITE INTO TABLE test_2;
# 匯入HDFS的資料到磁區表的指定磁區,覆寫原有資料
LOAD DATA INPATH '/home/admin/test/test.txt' OVERWRITE INTO TABLE test_1 PARTITIO(pt='20200101');
2.1.2 Inserting data into Hive Tables from queries
從查詢插入資料到hive表
語法:
# 標準語法
#覆寫原有資料
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
# 追加插入
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
# 動態磁區插入
INSERT OVERWRITE|INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement;
案例:
# 插入非磁區表,覆寫原有資料
insert overwrite table tablename1 select a, b, c from test_1;
# 插入非磁區表,覆寫原有資料
insert overwrite table tablename1 select a, b, c from test_1;
# 插入磁區表,以追加的方式
insert into table tablename1 partition (create_date='20210101',org='1') select a, b, c from test_1;
# 一個靜態磁區,一個動態磁區,插入磁區表
insert overwrite table page_view partition (dt='2008-06-08', country) select pvs.user_id, pvs.user_name from page_view_stg pvs;
# 動態插入磁區表,2個動態磁區,不包括靜態磁區
insert overwrite table test_1(create_date, org) select user_id, user_name,create_date,org from tablename1;
動態磁區需要注意調整的引數
| 引數名 | 默認值 | 意思 |
|---|---|---|
| hive.exec.dynamic.partition | true | 設定為true,表示開啟動態磁區 |
| hive.exec.dynamic.partition.mode | strict | 當處于strict模式時,用戶至少需要指定一個靜態磁區;在nonstrict 模式時,允許磁區都是動態磁區 |
| hive.exec.max.dynamic.partitions.pernode | 100 | 每個mapper/reducer被允許創建的動態磁區數的最大值 |
| hive.exec.max.dynamic.partitions | 1000 | 允許創建的動態磁區數的最大值 |
| hive.exec.max.created.files | 100000 | hive任務的mapper/reducer創建的檔案數的個數 |
| hive.error.on.empty.partition | false | 動態磁區插入產生空結果時是否拋出例外 |
2.1.3 Writing data into the filesystem from queries
將查詢出的資料匯出到檔案系統
語法:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] (Note: Only available starting with Hive 0.13)
案例:
# 將表資料匯出到本地檔案系統,分割符為逗號
insert OVERWRITE LOCAL DIRECTORY '/home/hadoop/local_test_output' ROW FORMAT DELIMITED FIELDS TERMINATED by ',' select * from test_1;
# 將表資料匯出到HDFS檔案系統,分隔符為逗號
insert OVERWRITE DIRECTORY '/home/hadoop/hdfs_test_output' ROW FORMAT DELIMITED FIELDS TERMINATED by ',' select * from test_1;
注意匯出到檔案系統時,啟動用戶要有輸出目錄的寫權限,
DML 官方檔案:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML
3 DQL
資料查詢語言
語法:
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
關鍵字解釋:
- WITH CommonTableExpression (, CommonTableExpression)*
定義CTE(公共表運算式),定義好后,一個查詢里可以多次參考定義好的公共表 - SELECT [ALL | DISTINCT] select_expr, select_expr, …
DISTINCT指定時,查詢回傳去重后的結果,不指定默認為ALL,回傳所有資料
select_expr 查詢的列或者運算式,例如user_id,max(user_id) - FROM table_reference
table_reference 表名 - WHERE where_condition
where_condition 篩選條件,對select到的列的值進行篩選,保留滿足條件的 - GROUP BY col_list
col_list 分組依據的列 - HAVING having_condition
having_condition 分組后,組內資料的篩選條件,保留滿足條件的 - ORDER BY col_list
col_list 根據指定的欄位排序,全域排序;order by 是在一個reduce里執行,所以資料量大時,速度很慢,可以通過嵌套排序加快速度 - CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list
CLUSTER BY col_list 根據指定的列排序,全域排序,只能降序
DISTRIBUTE BY col_list 根據指定的欄位磁區,同一個欄位的同一個值落在一個磁區里
SORT BY col_list 每個reducer里排序,非全域排序 - LIMIT [offset,] rows
限制回傳的條數,offset表示回傳的資料從第幾行開始,rows表示回傳幾行
案例:
# 定義公共表,查詢公共表
with
t1 as select * from test_1
select * from t1;
# 查詢
select org,sum(age)
from t_user
where user_id > 1
group by org
having avg(age) > 35
order by org;
3.1 陳述句執行順序
Hive SQL執行順序
-- 正常SQL順序
select … from … where … group by … having … order by … limit …
-- 真正執行順序
from … where … select … group by … having … order by … limit …
我的理解:
- from 找到從哪個或哪幾個表找資料
- where 根據where條件留下符合條件的資料,這個是過濾不需要的行
- select 留下要查詢的欄位,這個是過濾不需要的列
- group by 根據哪些欄位分組
- having 組內過濾
- order by 排序
- 限制回傳行數
3.2 運算子和用戶自定義函式
此部分內容較多,且官方檔案就很容易理解,直接看官方檔案即可
官方檔案:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
六、元資料
元資料詳解:
https://www.cnblogs.com/qingyunzong/p/8710356.html
元資料統計資訊收集思路:
https://blog.csdn.net/songjifei/article/details/104706737
元資料詳細資訊收集思路:
https://blog.csdn.net/sanbudeyu_008/article/details/102800508
七、Hive優化
1 設定合理的map/reduce 數量
1.1 調整map數量
目的就是讓單個map處理合適資料量的資料,
1.1.1 資料量小,減少map數
當有幾百個小檔案時,可以通過調整引數合并檔案,減少檔案數
設定如下引數:
# 設定map任務的檔案切割大小為100MB
set mapred.max.split.size=100000000;
# 設定每個節點的檔案切割大小為100MB
set mapred.min.split.size.per.node=100000000;
# 設定每個機架的檔案切割大小為100MB
set mapred.min.split.size.per.rack=100000000;
# 設定執行map前先合并檔案
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
前面三個引數確定合并檔案塊的大小,大于檔案塊大小128m的,按照128m來分隔,
小于128m,大于100m的,按照100m來分隔,把那些小于100m的(包括小檔案和分隔大檔案剩下的)進行合并,
1.1.2 資料量大,增加map數
當檔案很大,只用1個map去處理很費時間,此時可以增加map數量(按自己集群情況調整),
設定如下引數:
set mapred.map.tasks=10;
1.2 調整reduce數量
如果設定了mapred.reduce.tasks/mapreduce.job.reduces引數,那么Hive會直接使用它的值作為Reduce的個數;如果mapred.reduce.tasks/mapreduce.job.reduces的值沒有設定(也就是-1),那么Hive會根據輸入檔案的大小估算出Reduce的個數,根據輸入檔案估算Reduce的個數可能未必很準確,因為Reduce的輸入是Map的輸出,而Map的輸出可能會比輸入要小,所以最準確的數根據Map的輸出估算Reduce的個數,
reduce個數的設定極大影響任務執行效率,不指定reduce個數的情況下,Hive會猜測確定一個reduce個數,基于以下兩個設定:
hive.exec.reducers.bytes.per.reducer(每個reduce任務處理的資料量,默認為1000^3=1G)
hive.exec.reducers.max(每個任務最大的reduce數,默認為999)
計算reducer數的公式 N=min(引數2,總輸入資料量/引數1)
如果reduce的輸入(map的輸出)總大小不超過1G,那么只會有一個reduce任務;
1.2.1 方法1
調整如下引數
# 設定每個reduce處理的檔案大小設定為500MB
set hive.exec.reducers.bytes.per.reducer=500000000;
1.2.2 方法2
調整如下引數
# 設定reduce的數量為15
set mapred.reduce.tasks=15;
2 小檔案優化
小檔案產生可能的原因:
1 動態磁區插入資料,產生大量的小檔案,從而導致map數量劇增;
2 reduce數量越多,小檔案也越多(reduce的個數和輸出檔案是對應的);
3 資料源本身就包含大量的小檔案
小檔案的影響:
- 從Hive的角度看,小檔案會開很多map,一個map開一個JVM去執行,所以這些任務的初始化,啟動,執行會浪費大量的資源,嚴重影響性能,
- 在HDFS中,每個小檔案物件約占150byte,如果小檔案過多會占用大量記憶體,這樣NameNode記憶體容量嚴重制約了集群的擴展,
源頭解決思路:
1 減少reduce的數量(可以使用引數進行控制);
2 少用動態磁區,用時記得按distribute by磁區;
已有小檔案解決思路:
1 使用hadoop archive命令把小檔案進行歸檔;
2 重建表,建表時減少reduce數量;
3 通過引數進行調節,設定map/reduce端的相關引數
可調整的map/reduce引數:
# 每個Map最大輸入大小(這個值決定了合并后檔案的數量)
set mapred.max.split.size=100000000;
# 一個節點上split的至少的大小(這個值決定了多個DataNode上的檔案是否需要合并)
set mapred.min.split.size.per.node=100000000;
# 一個交換機下split的至少的大小(這個值決定了多個交換機上的檔案是否需要合并)
set mapred.min.split.size.per.rack=100000000;
# 執行Map前進行小檔案合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
# 設定map端輸出進行合并,默認為true
set hive.merge.mapfiles = true
# 設定reduce端輸出進行合并,默認為false
set hive.merge.mapredfiles = true
# 設定合并檔案的大小
set hive.merge.size.per.task = 256*1000*1000
# 當輸出檔案的平均大小小于該值時,啟動一個獨立的MapReduce任務進行檔案merge,
set hive.merge.smallfiles.avgsize=16000000
3 SQL優化
優化思路:
- 盡早盡量過濾資料,減少每個階段的資料量
- 減少job數
- 減少掃描的檔案數或磁區數
案例表
# t_order 訂單表
create table t_order(
order_id int "訂單編號",
user_id int "用戶編號",
create_date string "訂單創建時間"
);
# t_user 用戶表
create table t_user(
user_id int "用戶編號",
user_name string "用戶名",
create_date string "創建時間"
);
3.1 列剪裁
一個表中有多個欄位,查詢時只查詢需要的列
# 優化前
select * from t_user;
# 優化后
select user_id from t_user;
3.2 磁區剪裁
資料量大的表必須是磁區表,查詢時where里必須指定磁區的篩選條件
# 優化前
select * from tablename;
# 優化后
select order_id,order_name from t_order where create_date>='2020-01-01';
3.3 避免笛卡爾積
關聯查詢時必須加關聯條件
# 優化前
select order_id,user_name from t_order, t_user;
select order_id,user_name from t_order inner join t_user;
# 優化后
select order_id,user_name from t_order, t_user where t_order.user_id = t_user.user_id;
select order_id,user_name from t_order inner join t_user on t_order.user_id=t_user.user_id;
3.4 join前過濾無用資料
# 優化前
select o.order_id,u.user_name
from t_order o
join t_user u on (o,user_id=u.user_id)
where o.create_date = '2020-01-01' and u.create_date='2020-01-01';
# 優化后
select o2.order_id,u2.user_name from (select o.order_id,o.user_id from t_order o where o.create_date = '2020-01-01') o2 join (select user_id,user_name from t_user u where u.create_date='2020-01-01') u2 on o2.user_id = u2.user_id;
3.5 join時小表在前大表在右
在Reduce階段,位于join運算子左邊的表會先被加載到記憶體,載入條目較少的表可以有效的防止記憶體溢位(OOM),
# 優化前
select o.order_id,o.user_name from t_order o join t_user u on o.user_id=u.user_id;
# 優化后
select o.order_id,o.user_name from t_user u join t_order o on u.user_id=o.user_id;
3.6 mapjoin
join有兩種,一種是map join,一種是reduce join,當小表和大表進行join時,盡量采用mapjoin;如果把join的操作先在map join,到reduce后接收到的資料會更少,同時可以避免小表和大表join產生的資料傾斜;
注意:一般行數小于2000行,大小小于1M(擴容后可以適當放大)的表才能使用
有2種使用方式
1 自動mapjoin默認是已開啟的,只需要小表放左邊即可
2 顯示指定mapjoin
# 方式1
set hive.auto.convert.join = true;# 開啟自動mapjoin
set hive.mapjoin.smalltable.filesize = 6250000;# 設定小表存盤的檔案大小
select * from t_user
join t_order
on t_user.user_id=t_order.user_id;
# 方式2
set hive.ignore.mapjoin.hint=true;
select /*+ mapjoin(t_user) */ *
from t_user
join t_order
on t_user.user_id=t_order.user_id;
如果是mapjoin會有如下日志
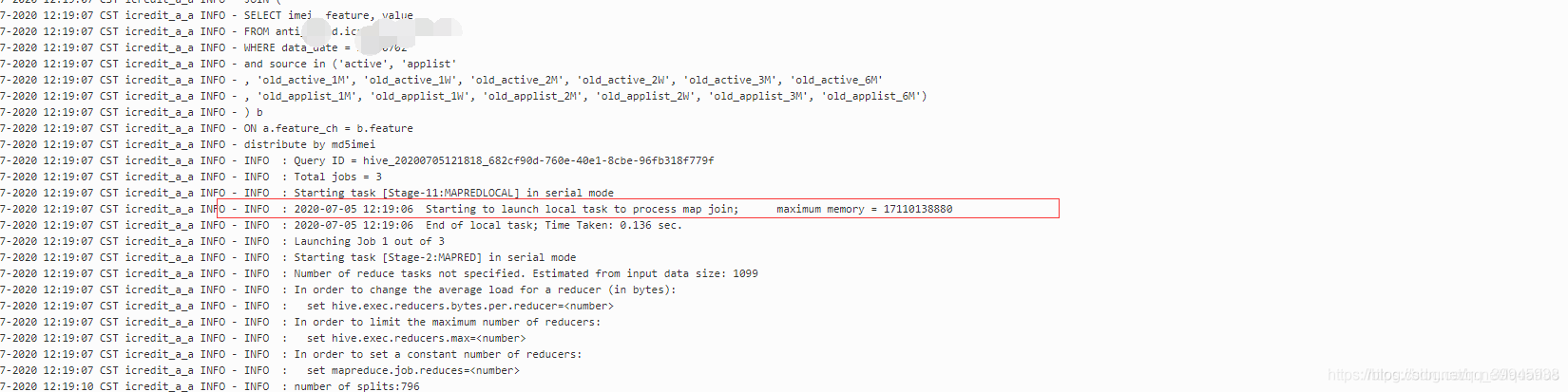
3.7 避免distinct
distinct使用一個reduce效率很慢,建議使用group by替代
# 優化前
select distinct user_id from t_order;
# 優化后
select user_id from t_order group by user_id;
3.8 explain查看hive查詢的執行計劃
可以根據執行計劃的情況,調整sql
語法:
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
關鍵字:
- EXTENDED 查看詳細資訊
- CBO 查看Calcite優化器生成的執行計劃,還可以查看每個操作花費的資源(cpu,io)
- AST 查看抽象語法樹
- DEPENDENCY 查看本次輸入的額外資訊,包括表或其他的一些屬性
- AUTHORIZATION 查看查詢權限
- LOCKS 查看本次查詢所需要的鎖
- VECTORIZATION 查看本次查詢不是向量化執行的原因
- ANALYZE 查看計劃和實際行數
案例:
EXPLAIN
FROM src INSERT OVERWRITE TABLE dest_g1 SELECT src.key, sum(substr(src.value,4)) GROUP BY src.key;
依賴圖:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 depends on stages: Stage-2
Stage-1是根步驟,Stage-2在Stage-2執行完之后執行,Stage-0在Stage-2執行完后執行,
STAGE PLANS:
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree:
src
Reduce Output Operator
key expressions:
expr: key
type: string
sort order: +
Map-reduce partition columns:
expr: rand()
type: double
tag: -1
value expressions:
expr: substr(value, 4)
type: string
Reduce Operator Tree:
Group By Operator
aggregations:
expr: sum(UDFToDouble(VALUE.0))
keys:
expr: KEY.0
type: string
mode: partial1
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.mapred.SequenceFileOutputFormat
name: binary_table
Stage: Stage-2
Map Reduce
Alias -> Map Operator Tree:
/tmp/hive-zshao/67494501/106593589.10001
Reduce Output Operator
key expressions:
expr: 0
type: string
sort order: +
Map-reduce partition columns:
expr: 0
type: string
tag: -1
value expressions:
expr: 1
type: double
Reduce Operator Tree:
Group By Operator
aggregations:
expr: sum(VALUE.0)
keys:
expr: KEY.0
type: string
mode: final
Select Operator
expressions:
expr: 0
type: string
expr: 1
type: double
Select Operator
expressions:
expr: UDFToInteger(0)
type: int
expr: 1
type: double
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.dynamic_type.DynamicSerDe
name: dest_g1
Stage: Stage-0
Move Operator
tables:
replace: true
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.dynamic_type.DynamicSerDe
name: dest_g1
這個例子里有2個map/reduce步驟和1個檔案系統相關的步驟,Stage-1是讀取src表的資料并做一些轉換;Stage-2做分組聚合;Stage-0最后將資料移動到表相關的目錄里,
explain 官方檔案:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain#LanguageManualExplain-EXPLAINSyntax
參考資料
Hive官方網站
《hive編程指南》
Hive優化(整理版)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283198.html
標籤:其他