要爬取吉林省人民政府網站,但是發現
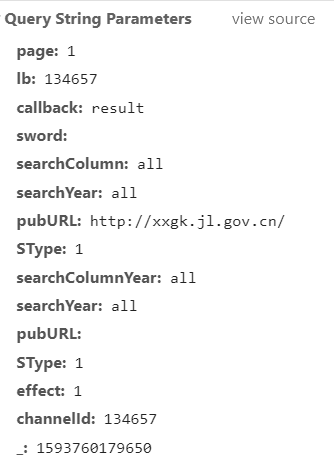 如圖所示的channelID是隨機變化的,無法通過引數請求獲取網頁資訊。請問大神們,該怎么處理呢?
如圖所示的channelID是隨機變化的,無法通過引數請求獲取網頁資訊。請問大神們,該怎么處理呢?
uj5u.com熱心網友回復:
你要爬哪個頁面?頁面顯示是什么?頁面原始碼是什么?uj5u.com熱心網友回復:
debug看看是怎么生成的uj5u.com熱心網友回復:
已經解決了,用selenium能爬出來,現在就是在想怎么把selenium和scrapy集成起來uj5u.com熱心網友回復:
可以把selenium寫spider中,或者寫middlerware中uj5u.com熱心網友回復:
嗯嗯,我看好多教程在setting,middlerware里面都有改動,有點懵,爬蟲小白還要摸索
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/28356.html
上一篇:新生請教Python切片問題