我用requests模塊爬取豆瓣top250 出現亂碼 我看網頁的編碼方式也是utf-8 我設定的也是utf-8 為什么還會亂碼呢我用requests模塊爬取豆瓣top250 出現亂碼 我看網頁的編碼方式也是utf-8 我設定的也是utf-8 為什么還會亂碼呢

uj5u.com熱心網友回復:
是不是亂碼要看你的代碼源檔案,網頁源檔案,response設定,print輸出控制臺是不是都是統一編碼uj5u.com熱心網友回復:
response.apparent_encoding#查看網頁編碼你這個應該是自己終端編碼 設定的問題,是linux終端?
uj5u.com熱心網友回復:
window電腦gbkuj5u.com熱心網友回復:
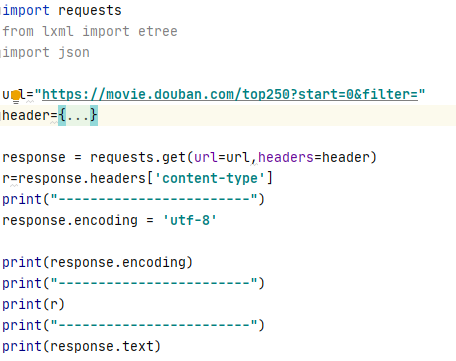
為什么我沒有亂碼import requests
url='https://movie.douban.com/top250?start=0&filter='
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
response=requests.get(url=url,headers=headers)
print(response.text)
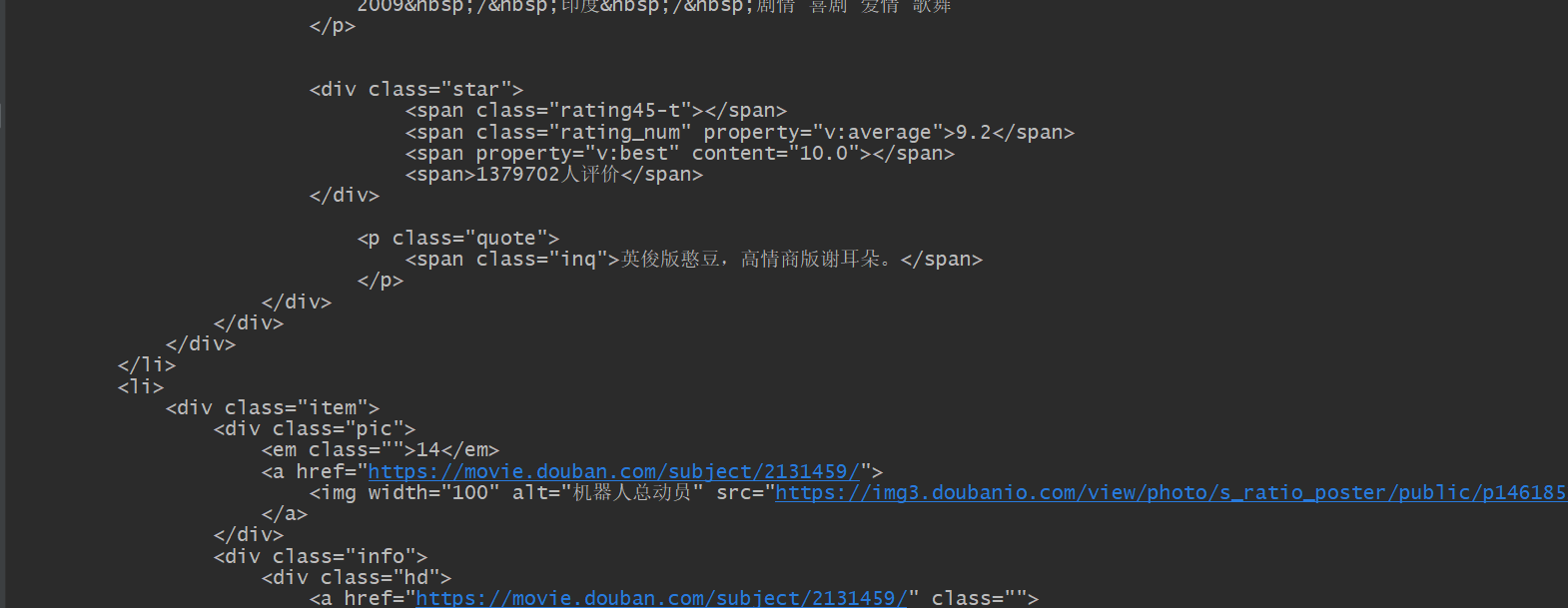
運行結果:

uj5u.com熱心網友回復:
你的輸出端是不是utf-8編碼?轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/28361.html