一、概念
1、人工智能、機器學習、深度學習
(1)人工智能;
(2)機器學習(從資料中自動分析獲得的模型,并利用模型對未知資料進行預測)是人工智能的一個實作途徑,即選擇合適的演算法對模型訓練;
(3)深度學習是機器學習的一個方法發展而來,
2、人工智能三要素:資料、演算法、計算力;
3、人工智能主要分支
通訊、感知、行動是現代人工智能的三個關鍵能力,主要應用于以下領域:
(1)計算機視覺(CV);
(2)自然語言處理(NLP);
在NLP領域中,將覆寫文本挖掘/分類、機器翻譯和語音識別;
(3)機器人,
4、特征工程
使用專業背景知識和技巧處理資料,使得特征能在機器學習演算法上發揮更好的作用的程序;即資料和特征決定了機器學習的上限,而模型和演算法只是逼近這個上限而已;特征工程的目的是把原始的資料轉換為模型可用的資料,
5、特征工程內容:
1)、特征提取
又叫作“降維”,指使用映射或變換的方法將維數較高的原始特征轉換為維數較低的新的特征,目前線性特征的常用提取方法有主成分分析(Principle ComponentAnalysis,PCA)、線性判別分析(Linear Discriminant Analysis,LDA)和獨立成分分析(Independent Component Analysis,ICA),;
特征工程的目的是把原始的資料轉換為模型可用的資料,主要包括三個子問題:
2)、特征構造
特征構造一般是在原有特征的基礎上做“組合”操作,例如,對原有特征進行四則運算,從而得到新的特征,
3)、特征選擇
即從原始的特征中挑選出一些具有代表性、使模型效果更好的特征,
6、樣本、特征
在資料集中一般一行資料稱為一個樣本,一列資料稱為一個特征,
有些資料有目標值(標簽值),有些資料沒有目標值 ,
資料型別構成:
資料型別一:特征值+目標值(目標值是連續的和離散的)
資料型別二:只有特征值,沒有目標值,
機器學習一般將資料集會劃分為兩個部分:
訓練資料:用于訓練.構建模型 ;
測驗資料:在模型校驗時使用,用于評估模型是否有效,
劃分比例:
訓練集: 70 % 80 % 75 % ·
測驗集: 30 % 20 % 25 %
二、機器學習演算法分類
根據資料集組成不同,可以把機器學習演算法分為:監督學習、無監督學習、半監督學習、強化學習;(放圖,一目了然,有圖有真相)
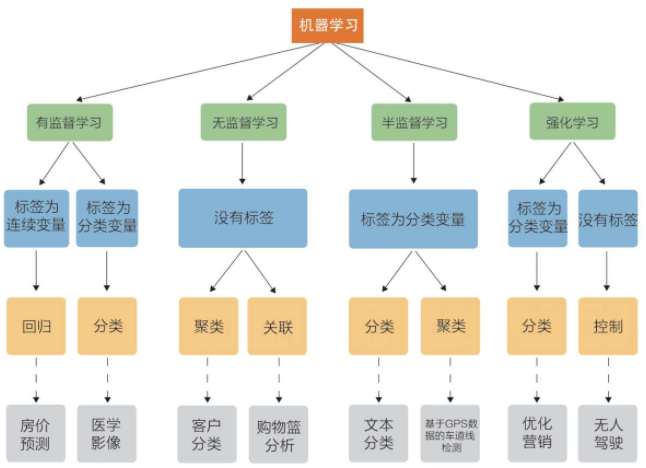
(1)監督學習:輸入資料是由輸入特征值和目標值所組成的;
詳解:當我們已經擁有一些資料及資料對應的類標時,就可以通過這些資料訓練出一個模型,再利用這個模型去預測新資料的類標,這種情況稱為有監督學習,有監督學習可分為回歸問題和分類問題兩大類,在回歸問題中,我們預測的結果是連續值;而在分類問題中,我們預測的結果是離散值,常見的有監督學習演算法包括線性回歸、邏輯回歸、K-近鄰、樸素貝葉斯、決策樹、隨機森林、支持向量機等,
(1.1)函式的輸出可以是一個連續的值(稱為回歸);
eg:預測房價,根據樣本擬合一條連續曲線,
(1.2)輸出是有限個離散值(稱作分類);
eg:電影根據劇情作分類,得到的結果是離散的,
(2)無監督學習:輸入資料是由輸入特征值組成,沒有目標值;
詳解:在無監督學習中是沒有給定類標訓練樣本的,這就需要我們對給定的資料直接建模,常見的無監督學習演算法包括K-means、EM演算法等
(2.1)輸入資料沒有被標記,也沒有確定的結果,樣本資料類別未知;
(2.2)需要根據樣本間的相似性對樣本集進行類別劃分;
eg:根據樣本集特征大致劃分,無目標值;
(3)半監督學習:訓練集同時包含有標記樣本資料和未標記樣本資料;
詳解:半監督學習介于有監督學習和無監督學習之間,給定的資料集既包括有類標的資料,也包括沒有類標的資料,需要在作業量(例如資料的打標)和模型的準確率之間取一個平衡點,
監督學習訓練方式;
半監督學習訓練方式;
(4)強化學習:
從不懂到通過不斷學習、總結規律,最終學會的程序便是強化學習,強化學習很依賴于學習的“周圍環境”,強調如何基于“周圍環境”而做出相應的動作,
(4.1)本質是make decisions即問題自動決策,并且可以做連續決策;
(4.2)強化學習的目標就是獲得最多的累計獎勵;
(4.3)主要包含5個元素:agent、action、reward、enviroment、observation.
(5)引申:
獨立同分布:在概率論理論中,如果變數序列或者其他隨機變數有相同的概率分布,并且相互獨立,那么這些隨機變數是獨立同分布(即每次抽樣之間獨立而且同分布(樣本服從同一分布));
三、模型評估
1、按照資料集的目標值不同,可以把模型評估分為分類模型評估和回歸模型評估,
1)、分類模型評估
準確度:預測正確的數占樣本總數的比例;
其他評價指標:精確度、召回率、AUC指標等,
2)、回歸模型評估
均方根誤差(RMSE),eg:房價預測準確度,
其他評估指標:相對平方誤差、平均絕對誤差、相對絕對誤差,
2、擬合
模型評估用于評價訓練好的模型的表現效果,其表現效果大致可以分為如下兩類(常見表現是在訓練集中的表現很好,誤差也不大,但是在測驗集上問題很多);
1)欠擬合:模型學習太過于粗糙,連訓練集中的樣本資料特征關系都沒有學習出來,
2)過擬合:所建的機器學習模型或者是深度學習模型在樣本訓練中表現得過于優越,導致在測驗資料集中表現不佳,
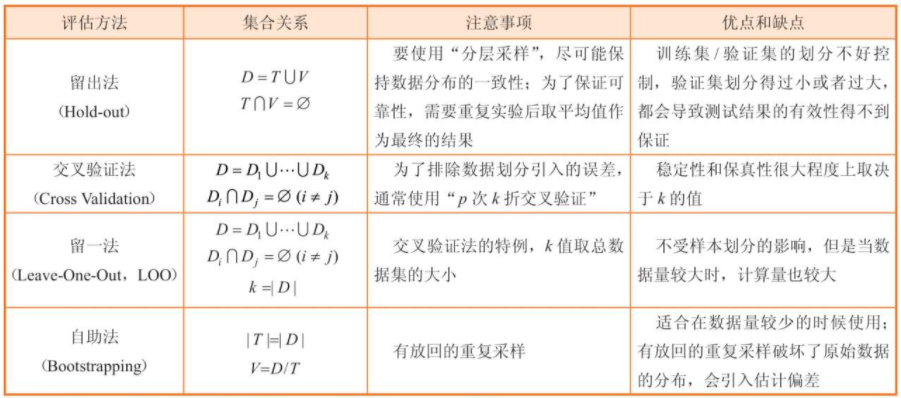
3、模型評估的常見方法:
留出法、交叉驗證法、留一法及自助法,
四、機器學習的一般流程
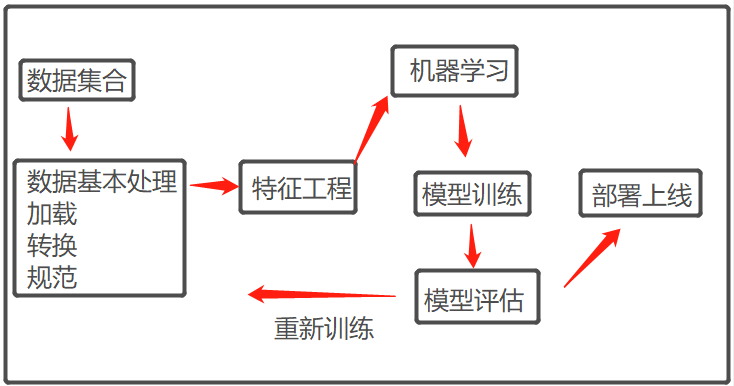
常用資料預處理的方式:
(1)歸一化
歸一化指將不同變化范圍內的值映射到一個固定的范圍里,例如,常使用min-max等方法將數值歸一化到[0,1]的區間內(有些時候也會歸一化到[-1,1]的區間內),歸一化的作用包括無量綱化[插圖]、加快模型的收斂速度,以及避免小數值的特征被忽略等,
(2)標準化
標準化指在不改變資料原分布的前提下,將資料按比例縮放,使之落入一個限定的區間,讓資料之間具有可比性,需要注意的是,歸一化和標準化各有其適用的情況,例如在涉及距離度量或者資料符合正態分布的時候,應該使用標準化而不是歸一化,常用的標準化方法有z-score等,
(3)離散化
離散化指把連續的數值型資料進行分段,可采用相等步長或相等頻率等方法對落在每一個分段內的數值型資料賦予一個新的統一的符號或數值,離散化是為了適應模型的需要,有助于消除例外資料,提高演算法的效率,
(4)二值化
二值化指將數值型資料轉換為0和1兩個值,例如通過設定一個閾值,當特征的值大于該閾值時轉換為1,當特征的值小于或等于該閾值時轉換為0,二值化的目的在于簡化資料,有些時候還可以消除資料(例如影像資料)中的“雜音”,
(5)啞編碼
啞編碼,又稱為獨熱編碼(One-Hot Encoding),作用是對特征進行量化,例如某個特征有三個類別:“大”“中”和“小”,要將這一特征用于模型中,必須將其數值化,很容易想到直接給它們編號為“1”“2”和“3”,但這種方式引入了額外的關系(例如數值間的大小關系),“誤導”模型的優化方向,一個更好的方式就是使用啞編碼,例如“大”對應編碼“100”,“中”對應編碼“010”,“小”對應編碼“001”,如果將其對應到一個三維的坐標系中,則每個類別對應一個點,且三個點之間的歐氏距離相等,
四、深度學習
是機器學習的一個分支,也稱為深度結構學習、或者深度機器學習,是一類演算法集合,
1、深度學習的應用
自然語言處理、語音識別與合成、影像領域
查閱和參考了不少資料,感謝各路大佬分享,如需轉載請注明出處,謝謝:https://www.cnblogs.com/huyangshu-fs/p/14722122.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285820.html
標籤:其他
上一篇:好文推薦 | 自然語言處理簡介