@Author:Runsen
誰都無法否認,長得好看的人就是更具有吸引力,賞心悅目誰都喜歡,好看的人無論在職場或情場,都一定更占優勢,
但是,此「顏值」非彼「顏值」,一說到「顏值」,大部分想到的是臉蛋,
因此,對于我來說,希望模糊影像和視頻的人臉,在本篇博客中,你將學習如何使用 Python 中的 OpenCV 庫模糊影像和視頻中的人臉,
為了模糊影像中顯示的人臉,首先檢測這些人臉及其在影像中的位置,對此,查看之前的一篇關于人臉檢測的教程,在這里使用人臉檢測的源代碼,
我們使用基于SSD的人臉檢測,具體源代碼如下所示,
import cv2
import numpy as np
# 下載鏈接:https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# 下載鏈接:https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
image = cv2.imread("beauty.jpg")
h, w = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),(104.0, 177.0, 123.0))
model.setInput(blob)
output = np.squeeze(model.forward())
font_scale = 1.0
for i in range(0, output.shape[0]):
confidence = output[i, 2]
if confidence > 0.5:
box = output[i, 3:7] * np.array([w, h, w, h])
start_x, start_y, end_x, end_y = box.astype(np.int)
cv2.rectangle(image, (start_x, start_y), (end_x, end_y), color=(255, 0, 0), thickness=2)
cv2.putText(image, f"{confidence*100:.2f}%", (start_x, start_y-5), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), 2)
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.imwrite("beauty_detected.jpg", image)
高斯模糊
模糊的演算法有很多,其中有一種叫高斯模糊(Gaussian Blur),它將正態分布用于影像處理,
既然名稱為高斯濾波器,那么其和高斯分布(正態分布)是有一定的關系的,
“高斯函式”(Gaussian function)的一維形式是
f ( x ) = 1 σ 2 π e ? ( x ? μ ) 2 2 σ 2 f(x)=\frac{1}{ \sigma\sqrt{2\pi} }e^{-\frac{(x-μ)^2}{2{\sigma^2}}} f(x)=σ2π ?1?e?2σ2(x?μ)2?
根據 μ = 0 μ=0 μ=0的一維高斯函式,可以推導得到二維高斯函式:
h ( x , y ) = 1 2 π σ 2 e ? x 2 + y 2 2 σ 2 h(x,y)=\frac{1}{2\pi\sigma^2}e^{-\frac{x^2+y^2}{2{\sigma^2}}} h(x,y)=2πσ21?e?2σ2x2+y2?
所謂"模糊",可以理解成每一個像素都取周邊像素的平均值,

上圖中,2是中間點,周邊點都是1,
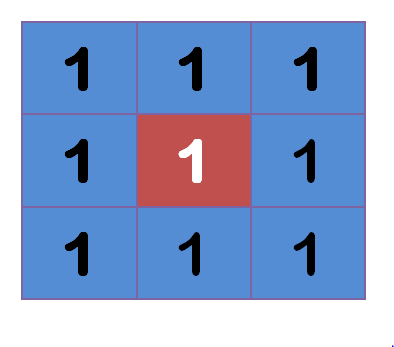
“中間點"取"周圍點"的平均值,就會變成1,在數值上,這是一種"平滑化”,在圖形上,就相當于產生"模糊"效果,"中間點"失去細節,
一般高斯模糊都有對應的權重矩陣,
假定中心點的坐標是(0,0),那么距離它最近的8個點的坐標如下:

為了計算權重矩陣,需要設定σ的值,假定σ=1.5,則模糊半徑為1的權重矩陣如下:

這9個點的權重總和等于0.4787147,如果只計算這9個點的加權平均,還必須讓它們的權重之和等于1,因此上面9個值還要分別除以0.4787147,得到最終的權重矩陣,
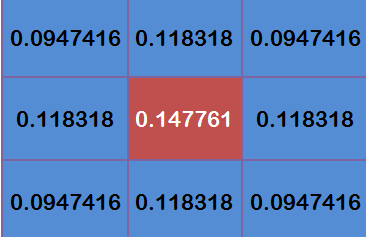
有了權重矩陣,就可以計算高斯模糊的值了,假設現有9個像素點,灰度值(0-255)如下:
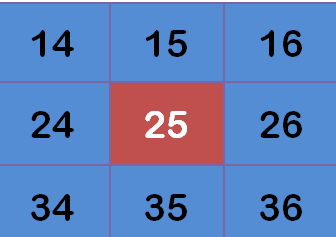
每個點乘以自己的權重值:
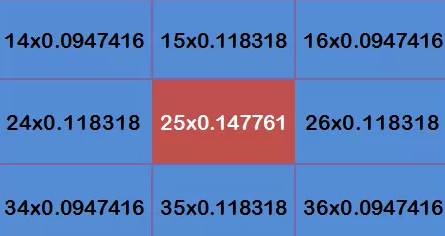
OpenCV 提供了 cv2.gaussianblur() 函式來對輸入源影像應用高斯平滑,以下是 GaussianBlur() 函式的語法:
dst = cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType=BORDER_DEFAULT]]] )
| 引數 | 描述 |
|---|---|
| src | 輸入影像 |
| dst | 輸出影像 |
| ksize | 高斯核大小(height 和 width而定),height 和 width 應該是奇數并且可以有不同的值,如果 ksize 設定為 [0 0],則 ksize 是根據 sigma 值計算的, |
| sigmaX | sigma 沿 X 軸(水平方向)的內核標準偏差, |
| sigmaY | sigma 沿 Y 軸(水平方向)的內核標準偏差, |
| borderType | 邊框型別 當內核應用于影像邊界時指定影像邊界,可能的值是: cv.BORDER_CONSTANT cv.BORDER_REPLICATE cv.BORDER_REFLECT cv.BORDER_WRAP cv.BORDER_REFLECT_101 cv.BORDER_TRANSPARENT cv.BORDER_REFLECT101 cv.BORDER_DEFAULT ISOLA. |
在 Python 中使用 OpenCV 實作高斯模糊的具體代碼
import cv2
import numpy as np
import sys
# https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
# 加載Caffe模型
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
image_file = "image.jpg"
# 讀取所需影像
image = cv2.imread(image_file)
# 獲取影像的寬度和高度
h, w = image.shape[:2]
# 高斯模糊核的大小取決于原始影像的寬度和高度
kernel_width = (w // 7) | 1
kernel_height = (h // 7) | 1
# 預處理影像:調整大小并執行平均減法
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
# 將影像輸入神經網路
model.setInput(blob)
# 進行推理并得到結果
output = np.squeeze(model.forward())
# output 是一個 numpy 陣列,它檢測了所有的人臉,讓我們迭代這個陣列,只模糊我們確信它是人臉的部分:
for i in range(0, output.shape[0]):
confidence = output[i, 2]
# get the confidence
# 如果置信度高于40%,則模糊邊界框(面)
if confidence > 0.4:
# 得到周圍的盒子cordinate和升級到原來的形象
box = output[i, 3:7] * np.array([w, h, w, h])
# 轉換為整數
start_x, start_y, end_x, end_y = box.astype(np.int)
# 獲取人臉影像
face = image[start_y: end_y, start_x: end_x]
# 對這張臉應用高斯模糊
face = cv2.GaussianBlur(face, (kernel_width, kernel_height), 0)
# 將模糊的人臉放入原始影像中
image[start_y: end_y, start_x: end_x] = face
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.imwrite("image_blurred.jpg", image)
在這里,我們不像之前在人臉檢測教程中我們為每個檢測到的人臉繪制邊界框,相反,我們在這里獲取框坐標并對其應用高斯模糊,
代碼決議
-
cv2.GaussianBlur()方法使用高斯濾波器模糊影像,將中值應用于內核大小內的中心像素,它接受輸入影像作為第一個引數,高斯核大小作為第二個引數中的元組,sigma 引數作為第三個引數,
-
我們從原始影像計算了高斯核大小,它必須是奇數和正整數,我將原始影像除以7,因此它取決于影像形狀,并執行按位或以確保結果值是奇數,當然可以自己設定內核大小,越大越模糊,


下面結合攝像頭模糊我這張的丑臉,具體代碼如下所示,
import cv2
import numpy as np
import time
# https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
cap = cv2.VideoCapture(0)
while True:
start = time.time()
_, image = cap.read()
h, w = image.shape[:2]
# 高斯模糊核的大小取決于原始影像的寬度和高度
kernel_width = (w // 7) | 1
kernel_height = (h // 7) | 1
# 預處理影像:調整大小并執行平均減法
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
# 將影像輸入神經網路
model.setInput(blob)
# 進行推理并得到結果
output = np.squeeze(model.forward())
# output 是一個 numpy 陣列,它檢測了所有的人臉,讓我們迭代這個陣列,只模糊我們確信它是人臉的部分:
for i in range(0, output.shape[0]):
confidence = output[i, 2]
# get the confidence
# 如果置信度高于40%,則模糊邊界框(面)
if confidence > 0.4:
# 得到周圍的盒子cordinate和升級到原來的形象
box = output[i, 3:7] * np.array([w, h, w, h])
# 轉換為整數
start_x, start_y, end_x, end_y = box.astype(np.int)
# 獲取人臉影像
face = image[start_y: end_y, start_x: end_x]
# 對這張臉應用高斯模糊
face = cv2.GaussianBlur(face, (kernel_width, kernel_height), 0)
# 將模糊的人臉放入原始影像中
image[start_y: end_y, start_x: end_x] = face
cv2.imshow("image", image)
if cv2.waitKey(1) == ord("q"):
break
time_elapsed = time.time() - start
fps = 1 / time_elapsed
print("FPS:", fps)
cv2.destroyAllWindows()
cap.release()

當然,在Opencv也支持視頻的傳輸,下面代碼是實作讀視頻的人臉的模糊,具體如下所示,
import cv2
import numpy as np
import time
import sys
# https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
video_file = "長的丑就是罪.mp4"
# 從視頻捕獲幀
cap = cv2.VideoCapture(video_file)
fourcc = cv2.VideoWriter_fourcc(*"XVID")
_, image = cap.read()
print(image.shape)
out = cv2.VideoWriter("output.avi", fourcc, 20.0, (image.shape[1], image.shape[0]))
while True:
start = time.time()
captured, image = cap.read()
if not captured:
break
h, w = image.shape[:2]
kernel_width = (w // 7) | 1
kernel_height = (h // 7) | 1
# 預處理影像:調整大小并執行平均減法
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
# 將影像輸入神經網路
model.setInput(blob)
# 進行推理并得到結果
output = np.squeeze(model.forward())
# output 是一個 numpy 陣列,它檢測了所有的人臉,讓我們迭代這個陣列,只模糊我們確信它是人臉的部分:
for i in range(0, output.shape[0]):
confidence = output[i, 2]
# get the confidence
# 如果置信度高于40%,則模糊邊界框(面)
if confidence > 0.4:
# 得到周圍的盒子cordinate和升級到原來的形象
box = output[i, 3:7] * np.array([w, h, w, h])
# 轉換為整數
start_x, start_y, end_x, end_y = box.astype(np.int)
# 獲取人臉影像
face = image[start_y: end_y, start_x: end_x]
# 對這張臉應用高斯模糊
face = cv2.GaussianBlur(face, (kernel_width, kernel_height), 0)
# 將模糊的人臉放入原始影像中
image[start_y: end_y, start_x: end_x] = face
cv2.imshow("image", image)
if cv2.waitKey(1) == ord("q"):
break
time_elapsed = time.time() - start
fps = 1 / time_elapsed
print("FPS:", fps)
out.write(image)
cv2.destroyAllWindows()
cap.release()
out.release()
原視頻:
長得丑就是罪
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286190.html
標籤:AI