?大家好,我是羽峰,公眾號:羽峰碼字,歡迎來撩,
接下來本文要講的是YOLOv1--YOLOv3演算法的原理,及YOLOv3的實作,一文帶你了解YOLO的來龍去脈,希望各位讀完本文會有所識訓,
目錄
YOLOv1
YOLOv1結構
YOLOv1損失函式
YOLOv2
YOLOv2相對于YOLOv1的主要改進
Anchor 機制
YOLOv3
YOLOv3的改進?
YOLOv3代碼實戰
1. 資料集標注
2. 資料預處理
3. 訓練和測驗
YOLO系列總結
YOLOv1
YOLOv1演算法是YOLO系列演算法的基礎,理解YOLOv1可以更好的理解YOLO系列演算法,
YOLOv1結構
首先我們要理解的是yolo的網路結構,如圖1所示,
其實網路結構比較簡單,就是簡單的CNN網路,池化操作,以及全連接網路,
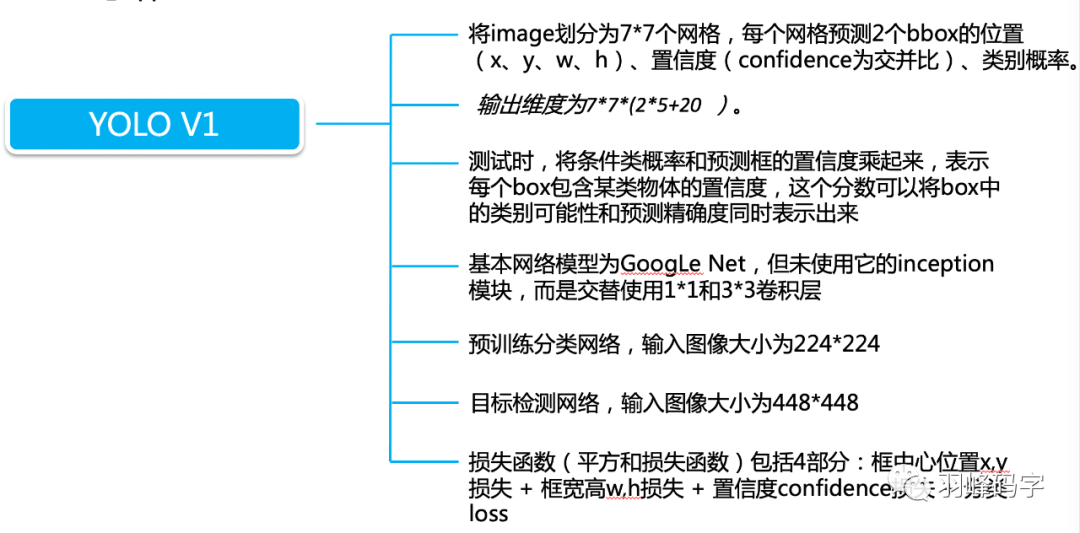
我們主要理解輸入與輸出之間的映射關系,中間網路只是求取這種映射關系的一種工具,網路的輸入是448*448*3的一個彩色影像,而網路的輸出是7*7*30的多維向量,下面我們將詳細的來解釋這種映射關系,這種映射關系也是YOLOv1的根本,
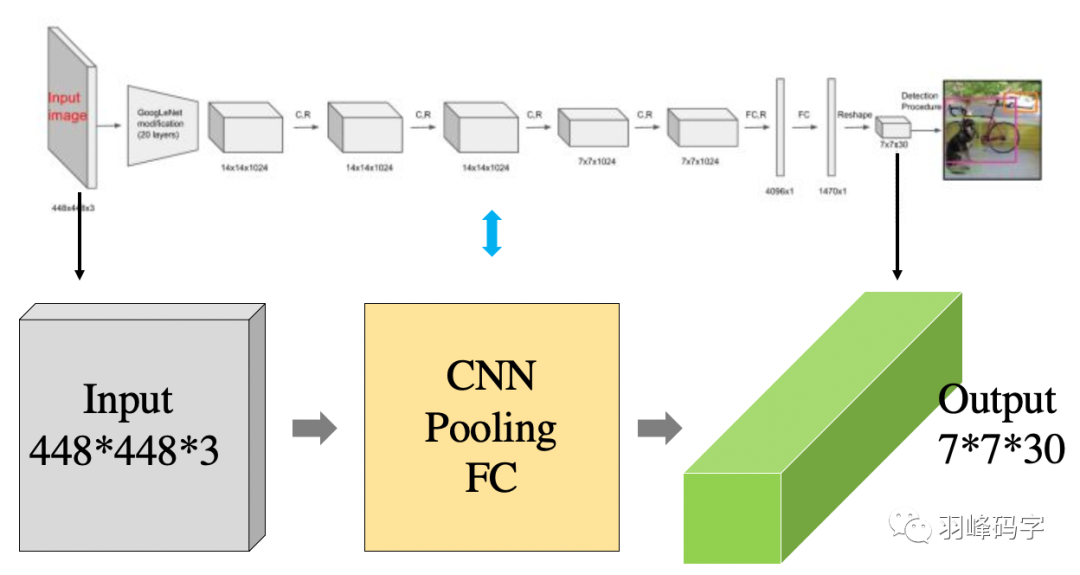
圖1
YOLO的輸入與輸出如圖2所示,左邊是一張圖片,中間的圓形可看作是目標物體,當圖片輸入到網路中,YOLOv1首要做的是將圖片分成7*7的網格,從中間影像中可以看出,紅色代表的是網格,藍色代表的是目標物體的中心,然后黃色代表的是真實的物體邊框,
這里有個最重要的一個概念就是:當物體中心落在某個網格中心時,那么這個網格就負責預測這個物體,這是yolov1的一個基礎,
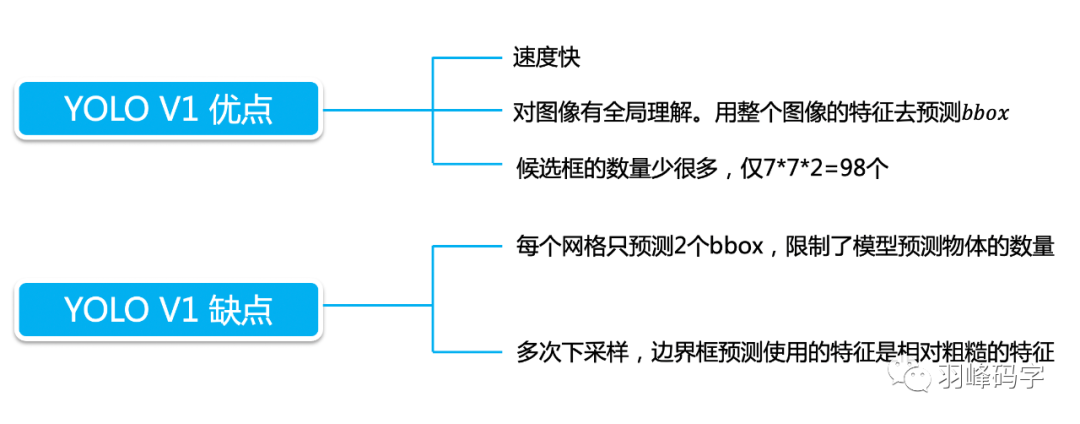
每個網格預先都會生成兩個預測框,這樣YOLOv1一共生成7*7*2=98個預測框,相比于faster rcnn 成百上千的預測框來說,YOLO的預測框明顯少了很多,這是YOLO非常快速的一個原因,
每個預測框都會對應一個30維的向量,這30維向量是2*5+20得來的,其中20是20個類別,這里之所以為20,是因為原論文所做的就是對20個物體進行分類,如果我們自己的資料集有n個類別,那么這里的20就可以改為n個類別,
然后2代表的是2個邊框,因為最開始每個網格會生成兩個預測框,而5則代表每個邊框中有五個參量,分別是邊框的中心坐標(x, y),邊框的寬w和高h,還有一個是框的置信度,置信度公式計算如圖公式所示,置信度大的那一個預測框就會被選為該網格的預測邊框,
網路的輸出就是7*7*30維的向量,與輸入存在一個數學上的映射關系,而中間的yolo網路只是求這個映射關系的一種工具,接下來我們將重點研究一下yolo的損失函式,
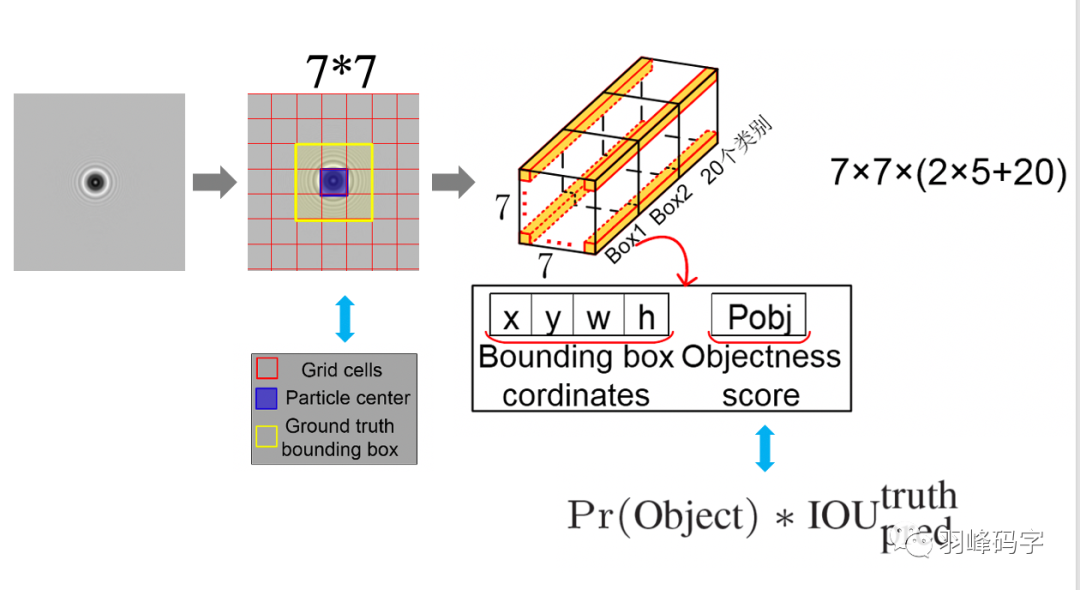
圖2 輸入與輸出的映射關系
YOLOv1損失函式
損失函式大致分為3個部分,第一個是坐標的預測,分別是邊框的x, y, w, h,
第二個是物體的置信度預測,
第三個是物體的類別預測,
損失函式與7*7*30維的向量相對應,是求取輸入與輸出之間映射關系誤差的“數學運算式”,
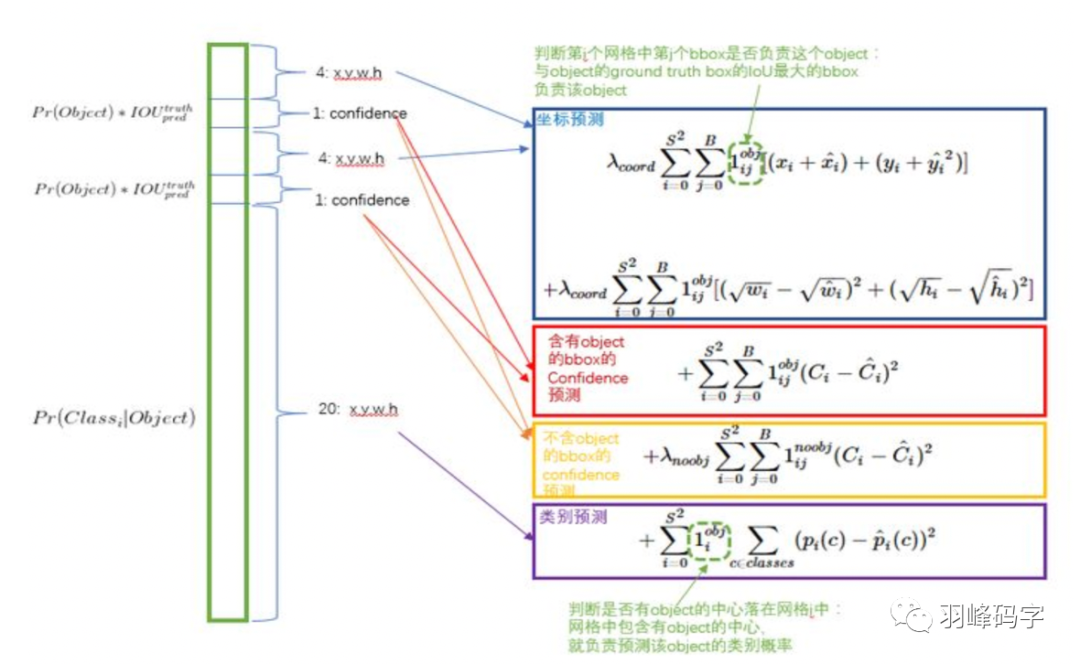
圖3 YOLOv1的損失函式
首先我們看一下坐標損失函式,如圖4所示,
每個引數的意義如圖所示,之所以采用根號來計算物體的長和寬,是因為根號后的大物體的長寬損失與小物體的長寬損失相近,這樣整個損失函式不會被大物體所操縱,若不采用根號計算,那么大物體的損失要比小物體損失大很多,那么這個損失函式會對大物體比較準確而忽略了小物體,
公式前的系數是一個超引數,這是設定為5,因為物體檢測程序中,我們所要檢測的物體相對與背景來說要少的很多,所以加入這個超引數是為了平衡“非物體”對結果的影響,
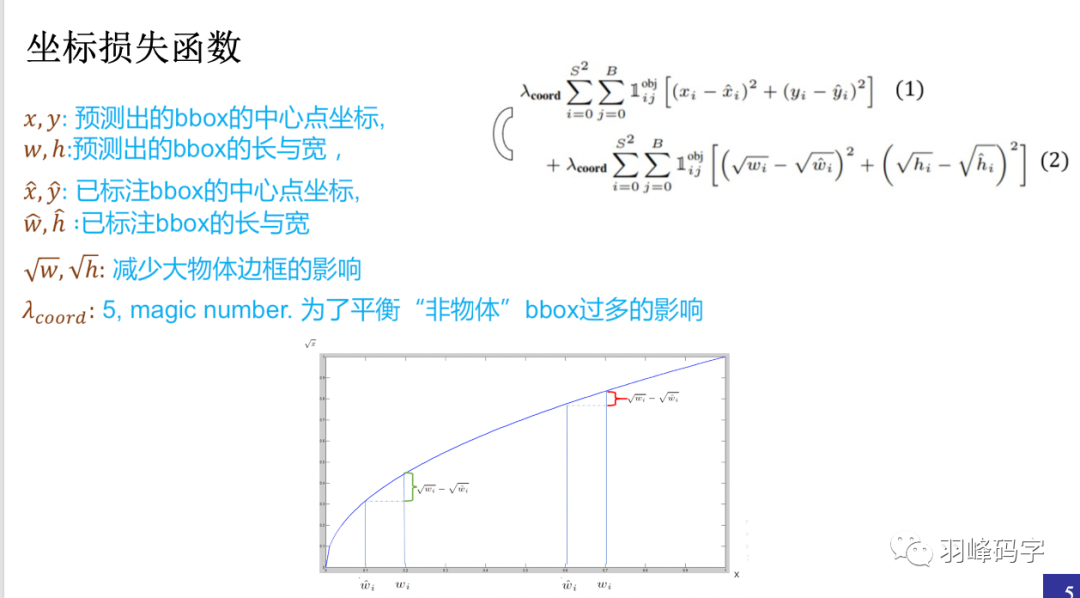
圖4 坐標損失函式
置信度的損失函式如圖5所示,每個引數的意義如圖所示,
這里為什么要加入“非物體”的置信度呢,是因為網路要想學習分類n個物體,那他實際要學n+1個類別,那多出的“1”是背景或者就是真實意義上的非物體,這一類是占有很大一部分比例的,所以必須要學習這一類,才能保證網路的準確性,
那這里為什么要在“非物體”的置信度前邊加上超引數呢?
也是因為我們所檢測的目標物體相對于“非物體”是很少的,如果不加入這個超引數,那么“非物體”的置信度損失就會很大,所占權重比較大,這樣會導致網路只學習到了“非物體”特征,而忽略了目標物體特征,

圖5 置信度損失函式
最后則是類別損失函式,如圖6所示,類別損失是一個很粗暴的兩個類別做減法,這是YOLOv1不可取的一部分,當然后續就改掉了,

圖6 類別損失函式
最后我們來做個總結,YOLO的優點就是速度快,YOLOv1缺點也很明顯,
-
對擁擠物體檢測不太好:因為擁擠物體的中心有可能都落在一個網格中心,那么這個網格可能就要預測兩個物體,這是很不好的,
-
對小物體檢測效果不好,小物體損失雖然使用的超引數或者根號進行了平衡,但小物體的損失占比還是小,網路主要學習的還是大物體特征,
-
對非常規的物體形狀或者比例,檢測效果不好
-
沒有batch normalize.
YOLOv2
YOLOv2相對于YOLOv1的主要改進
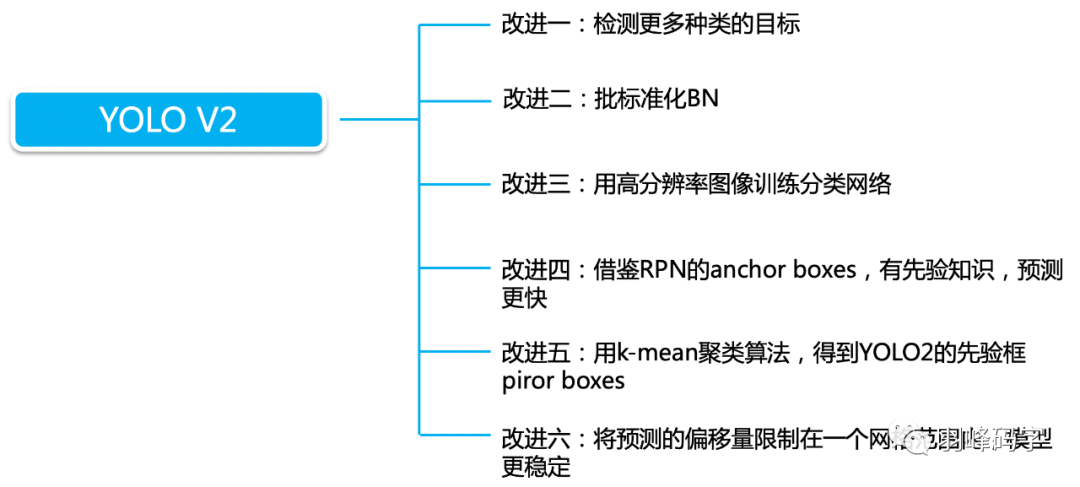
YOLOv2的第一個改進就是網路的改進,使用DarckNet19代替了YOLOv1的GoogLeNet網路,這里主要改進是去掉了全連接層,用卷積和softmax進行代替,
YOLOv2的第二個改進是在網路中加入了Batch Normalization,使用Batch Normalization對網路進行優化,讓網路提高了收斂性,同時還消除了對其他形式的正則化(regularization)的依賴,
YOLOv2的第三個改進是增加了HighResolution Classifier,具體做法是:首先在448×448的全解析度下在ImageNet上微調分類網路的10個epoch,這使網路有時間調整其過濾器,使其在更高解析度的輸入上更好地作業,然后,我們根據檢測結果對網路進行微調,這種高解析度分類網路使我們的mAP幾乎提高了4%,
YOLOv2的第四個改進是Multi-ScaleTraining,讓網路在不同的輸入尺寸上都能達到一個很好的預測效果,同一網路能在不同解析度上進行檢測,當輸入圖片尺寸比較小的時候跑的比較快,輸入圖片尺寸比較大的時候精度高,
Anchor 機制
YOLOv2的第五個改進是加入了Anchor機制,這個是最重要的一個改進,也是本文將重點講解的一個改進,
首先我們要了解什么是Anchor機制,Anchor首先要預設好幾個虛擬框,在用回歸的方法確定最終的預測框,
在YOLOv2中,使用K-means演算法來生成Anchor bbox,如圖7所示,當k=5時,模型的復雜度與召回率達到了一個比較好的平衡,所以YOLOv2使用了5個Anchor bbox ,

圖7
將YOLOv1的輸出與YOLOv2輸出進行對比,如圖2所示,
YOLOv1是的輸出7*7*30的多維向量,其中7*7是解析度,對原圖進行了7*7的分割,每個網格對應一個包含30個引數的向量,每個向量中包含兩個bbox,每個bbox中包含5個向量,分別是bbox的質心坐標(x,y)和bbox的長和寬,還有一個bbox的置信度,剩下20個則是類別概率,
而YOLOv2對此進行了修改,YOLOv2輸出的是13*13*5*25的一個多維向量,其中13*13是解析度,也就是說網路將輸入圖片分成了13*13的網格,每一個網格對應一個包含5*25=125個引數的一維向量,其中5代表5個Anchor bbox,每個Anchor bbox中包含25個引數,分別是bbox的質心坐標(x,y)和bbox的長和寬,還有一個bbox的置信度,剩下20個則是類別概率,
這樣的好處是YOLOv2可以對一個區域進行多個標簽的預測,比如一個“人”的目標物體,他可以屬于“人”這個標簽,也可以屬于“男”或者“女”這個標簽,也可以是“老師”,“學生”或者“職工”等這些標簽,而YOLOv1只能預測目標物體的一個類別,這里所做的最主要的改變是:bbox的四個位置引數的損失函式計算方法發生了改變,
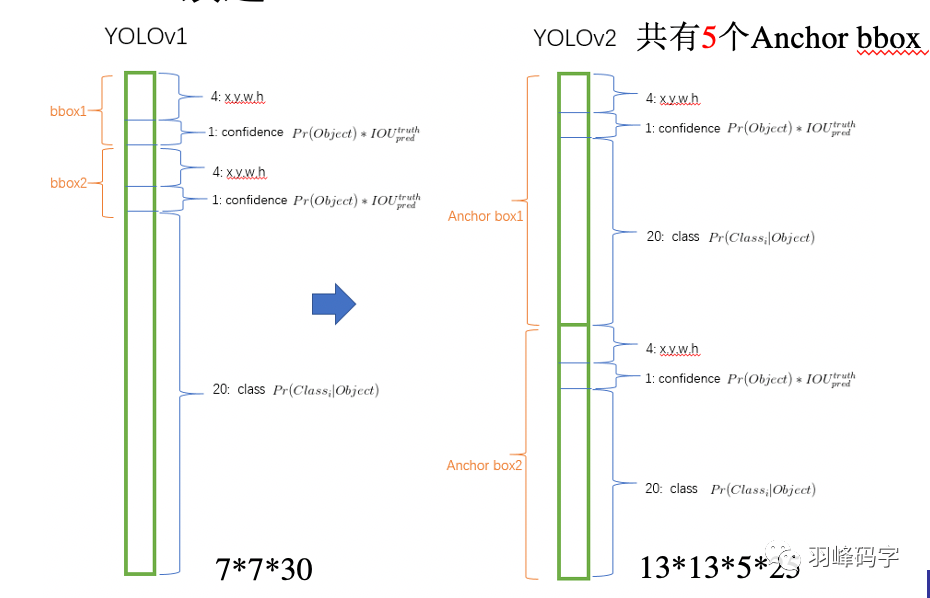
圖8 輸出對比
首先我們來認識一下Anchor bbox, Predicated bbox以及Ground truth bbox 三者之間的關系,
如圖9所示,紅色框代表了Anchor bbox,藍色框代表了 Predicated bbox,綠色框則代表了Ground truth bbox,
我們希望的是Anchor bbox 接近于Ground truth bbox,但Anchor bbox是預先設定好的,不可以更改,
但Anchor bbox可以生成不同的Predicated bbox,所以我們將我們目標轉化為:Predicated bbox更接近于Ground truth bbox, 將這個目標轉化為數學運算式就是f(x),具體如圖所示,那么我們的目標就變成了數學上的 tp 更加接近于tg,式子中都做了歸一化,防止大物體干擾整個計算結果,

圖9三者之間關系
其次我們要了解一下坐標轉換的概念,YOLOv1的坐標是相對于整個影像的,而YOLOv2的坐標是相對于每個網格的,那如何得到相對網格的這個坐標呢,又是如何計算loss值的呢?
如圖10所示,最開始我們會生成Anchor bbox,這時候的這個bbox是相對于整個影像來說的,所以此時我們要進行歸一化,歸一到[0,1]之間,
YOLOv2的解析度是13*13,所以我們要將這個[0,1]之間的坐標乘上13,使得bbox的坐標是相對于13個網格的,此時坐標范圍在[0,13]之間,此時我們在進行歸一化操作,使得此時的坐標是相對于單獨一個網格的,歸一化計算公式是xf = x-i, yf = y-j, wf = log(w/anchors[0]),hf = log(h/anchors[1]),這里我們可以舉個粒子,加入x = 9.6(x的范圍是[0,13]),那么此時的i是x的整數部分,也就是i = 9, 所以xf = 0.6,此時這個0.6就是相對于軸向第10個網格的x軸坐標,

圖10 坐標變換
最后就是的loss 計算,如圖11所示,圖片中間的公式就是YOLOv2 loss的計算公式,這個計算公式坐標計算是相對于網格的,而其對應的f(x)則是相當于整個影像的,
網路會計算得到δ(tx),δ(ty),其中δ是sigmoid函式,將網路輸出歸一化到[0,1]之間,這樣就會得到相對于某個網格的質心位置,加上該網格相對于整個13*13網格的偏移值,就會得到預測bbox的質心位置,高和寬,調整這個值,使其更加接近于真實的bbox,
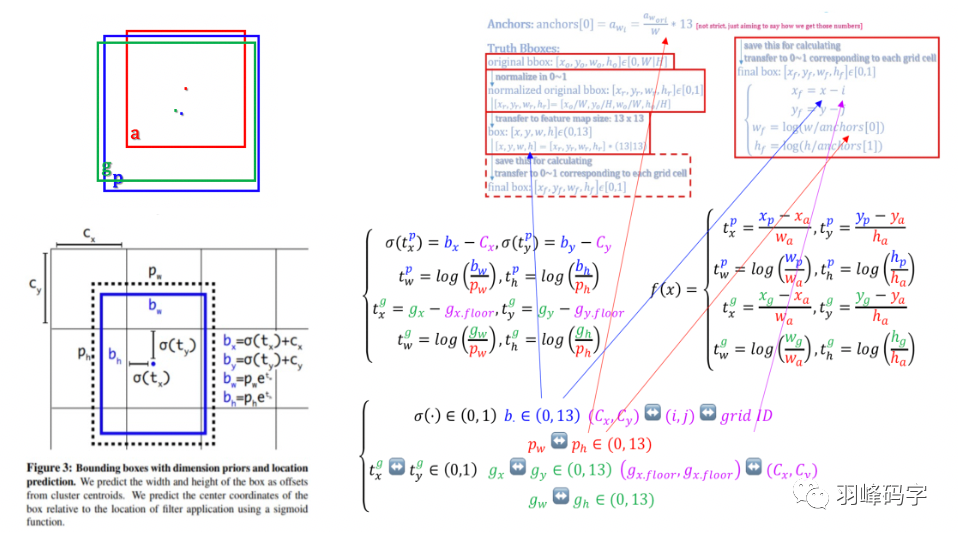
圖11 總結
YOLOv3
YOLOv3的改進?
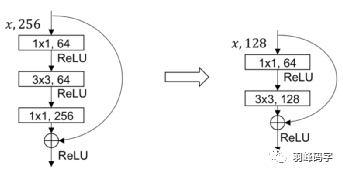
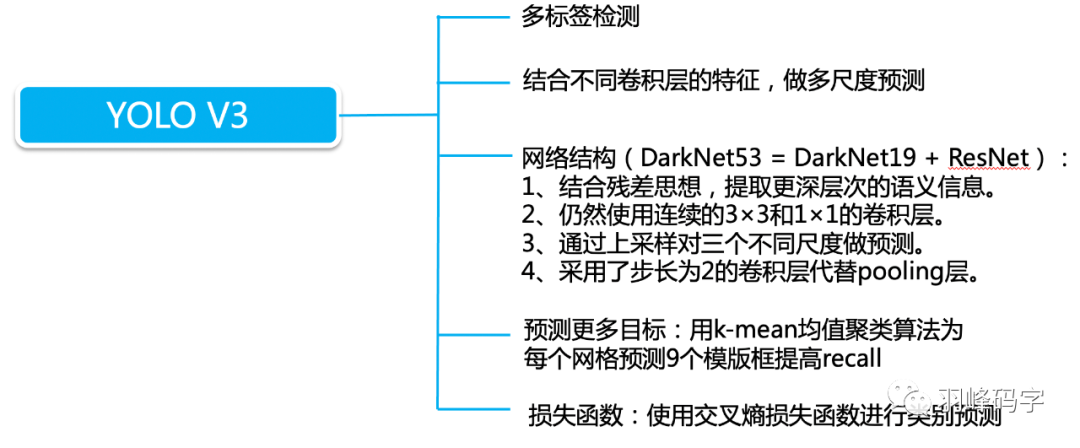
YOLOv3的第一個改進是網路的結構的改變,引入了ResNet思想,但是如果將ResNet模塊完全引進是整個模型就很大,所以直接將ResNet模塊的最后一層1*1*256去掉,而且將倒數第二層3*3*64直接改成3*3*128,整個網路結構如圖所示,輸入的是416*416*3的RGB影像,網路會輸出三種尺度的輸出,最后輸出每個目標物體的類別和邊框,
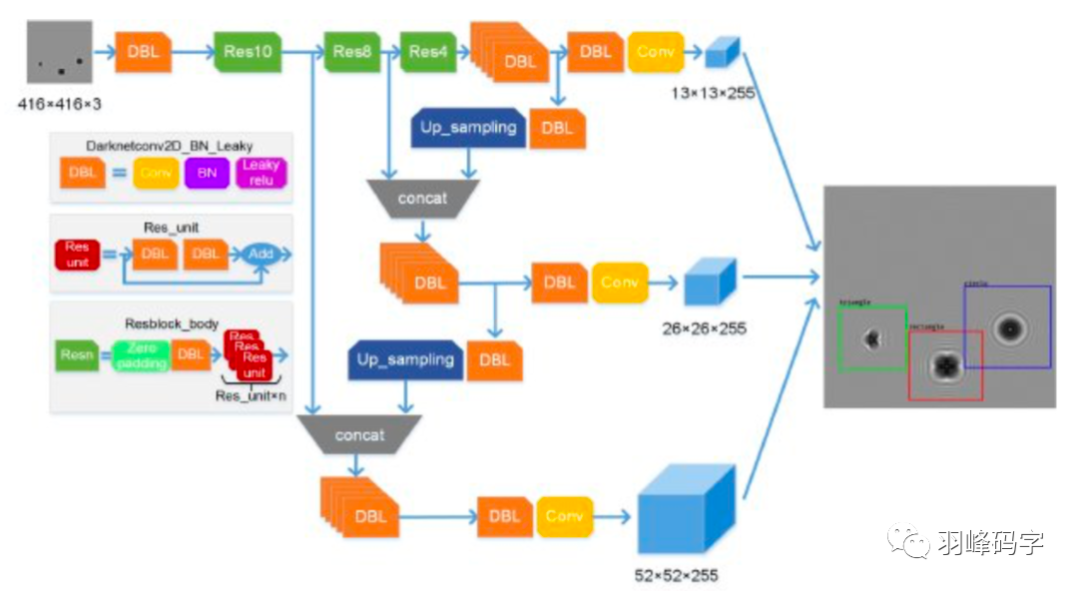
YOLOv3的第二個改進是多尺度訓練,是真正的多尺度,一共有3種尺度,分別是13*13,26*26,52*52三種解析度,分別負責預測大,中,小的物體邊框,這種改進對小物體檢測更加友好,

YOLOv3多尺度訓練的原理如圖所示,首先一個影像輸入,被YOLOv3分割成13*13,26*26,52*52的網格,每種解析度的每個網格分別對應一個多維向量,每個向量包括三個邊框,每個邊框中包含85個引數,分別是邊框的中心位置(x,y),邊框的置信度,還有80個類別概率,最后輸出每個物體的類別概率和邊框,
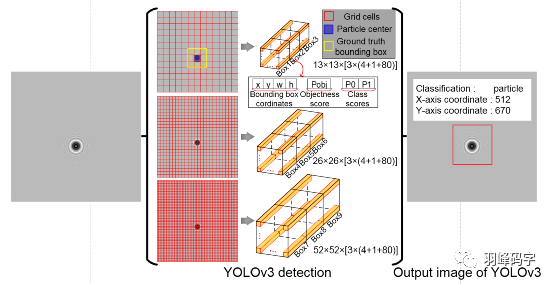
YOLOv3代碼實戰
1. 資料集標注
訓練YOLOv3首先要進行LabelImg標注,
LabelImg的網址為:https://github.com/tzutalin/labelImg,
安裝程式如圖所示:

安裝好之后,界面如圖所示:
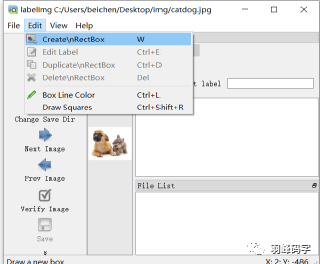
首先點擊”open”打開圖片,如圖所示,打開的是一個狗和貓的圖片,然后選擇邊框進行標注,
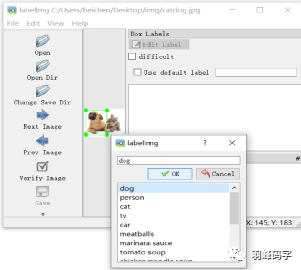
標注好之后應該,應該備注目標物體類別,如圖所示:
標注好之后會生成“catdog.xml”檔案,
檔案內容如圖所示:

最后分別將圖片(catdog)放入 ./VOCdevkit/VOC2007/JpegImages, LabelImg標注影像放進“Annotations”中,如圖所示:

2. 資料預處理
當圖片和xml檔案都準備好之后 ,運行“voc2yolo3.py”程式,生成資料集串列檔案,將圖片上對應的”voc_classes.txt”換成你自己的分類標簽,如果有多個類別,請將每個類別單獨放一行,
為了方便展示,我這里是臨時加入了一些圖片資料,不是本YOLOv3所執行的,后邊圖片中的資料都是原yolov3的資料,所以有些資料對應不上,但執行整個程序是接下來要說的,如果訓練自己的資料集,需要將自己的資料粘貼到對應位置,
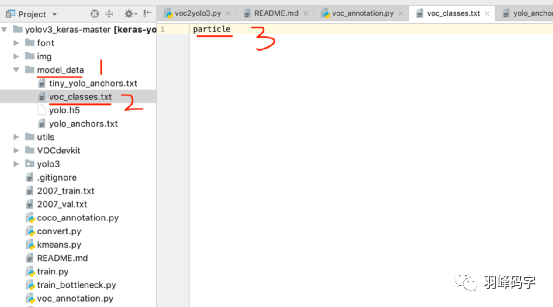
之后在運行“voc_annotation.py”程式,運行之前,首先將程式中的類別改成你自己的類別,我這里類別只有一個“particle”,
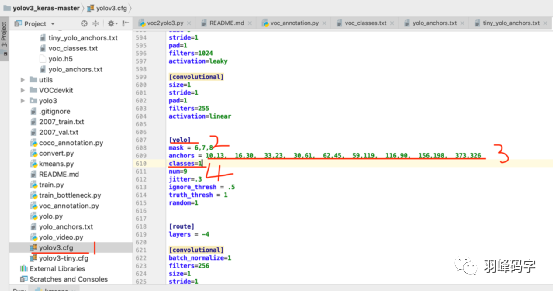
之后在運行“kmeans.py”程式,運行好之后會生成k anchor,這些數字代表了你的預生成的標注框大小,將這些標注框資料首先放入如圖所示的位置,并按照“yolo_anchors.txt”原有格式進行修改,
接下來在復制這些數字到“yolov3.cfg”中,搜索”yolo”將對應的anchors 和classes 進行修改,classes選擇你要分類的類別,我這里只有1個類別,就改成了1,一共有3個“yolo”,都要修改,
3. 訓練和測驗
當所有作業都做好之后,就可以訓練了,直接執行 “train.py”就可以了,注意權重的保存路徑和一些引數的調整就可以了,
訓練完成之后,執行“yolo_video.py”進行測驗就行,如果是從我公眾號下載的yolov3,需要將yolo_video.py做如下修改:


YOLO系列總結
以上 就是我今天要分享的內容,謝謝各位,如有錯誤,歡迎批評指正,
如果想要YOLOv3代碼,歡迎關注“羽峰碼字”公眾號,并回復“YOLOv3”獲取相應代碼,
我是羽峰,公眾號:羽峰碼字,我們下期見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286189.html
標籤:AI