KafkaProducer初始化引數
-
clientId沒主動設定clientId時,后臺都會生成一個client.id,producer-自增長的數字,producer-1,
-
partitioner決定訊息路由到Topic的哪個磁區里去的
-
metadata組件,生產端拉取Topic的元資料,包括Topic有哪些磁區,磁區的Leader位于哪個broker,有一個metadata.max.age引數默認是五分鐘,強制重新重繪資料,
-
request.max.size默認是1mb,一次請求最大為1mb,buffer.memory默認是32mb,異步用的緩沖區,max.block.ms用于控制send方法阻塞多久,默認60s,
-
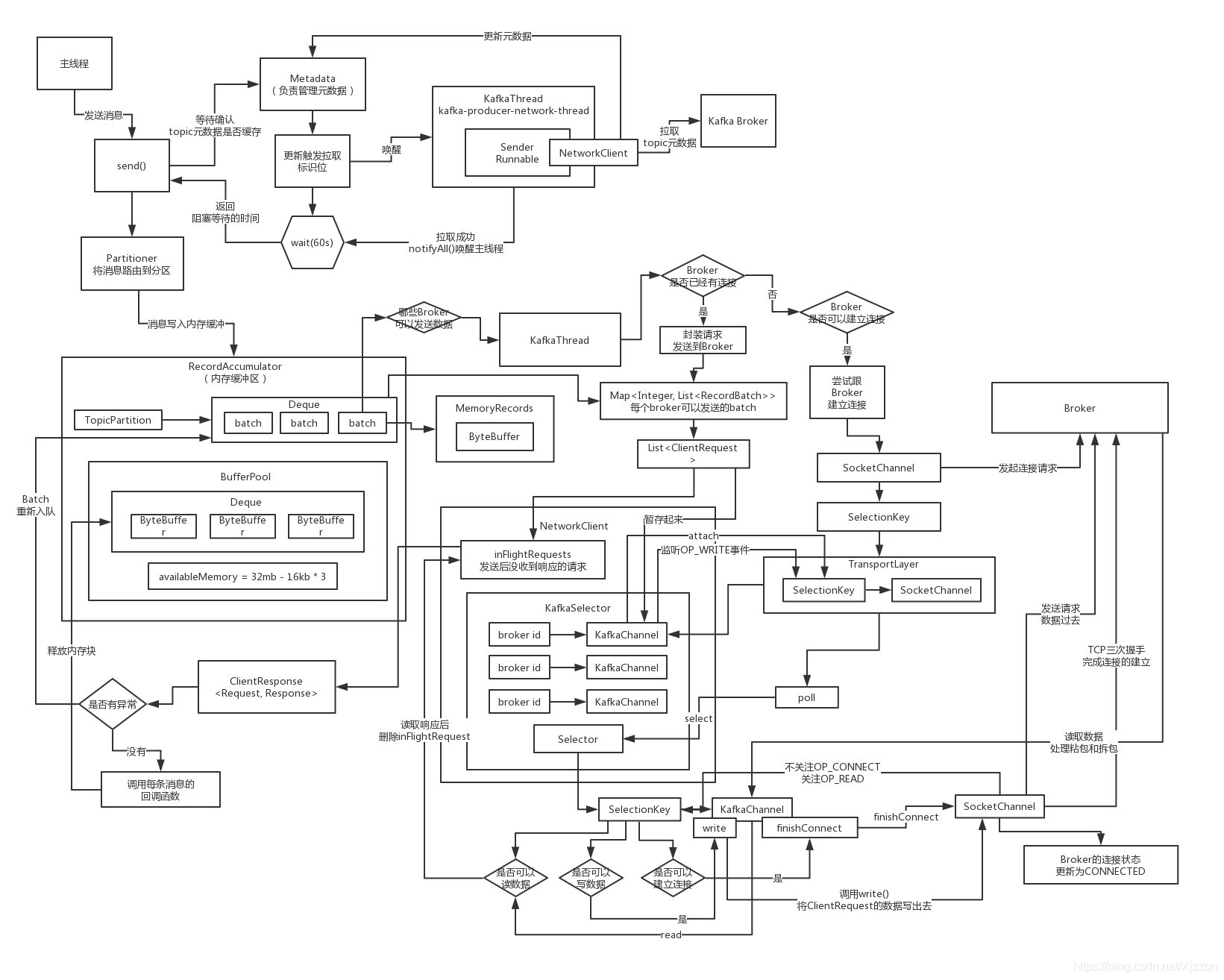
核心組件:RecordAccumulator,緩沖區,負責訊息的復雜的緩沖機制,發送到每個磁區的訊息會被打包成batch,一個broker上的多個磁區對應的多個batch會被打包成一個request,batch size(16kb),設定一個linger.ms,如果在指定時間范圍內,都沒湊出來一個batch把這條訊息發送出去,那么到了這個linger.ms指定的時間,比如說5ms,如果5ms還沒湊出來一個batch,那么就必須立即把這個訊息發送出去,
-
核心行為:始化的時候,直接呼叫Metadata組件的方法,去broker上拉取了一次集群的元資料過來,后面每隔5分鐘會默認重繪一次集群元資料,但是在發送訊息的時候,如果沒找到某個Topic的元資料,一定也會主動去拉取一次的
-
核心組件:網路通信的組件,NetworkClient,一個網路連接最多空閑多長時間(9分鐘),每個連接最多有幾個request沒收到回應(5個),重試連接的時間間隔(50ms),Socket發送緩沖區大小(128kb),Socket接識訓沖區大小(32kb)
-
核心組件:Sender執行緒,負責從緩沖區里獲取訊息發送到broker上去,request最大大小(1mb),acks(1,只要leader寫入成功就認為成功),重試次數(0,無重試),請求超時的時間(30s),執行緒類叫做“KafkaThread”,執行緒名字叫做“kafka-producer-network-thread”,此處執行緒直接被啟動,
-
核心組件:序列化組件,攔截器組件
集群元資料存盤
KafkaProducer在初始化的時候是不會去拉取集群的元資料的,做了一個最最基本的初始化,也就是僅僅把我們配置的那個broker的地址放了進去,在客戶端快取集群元資料的時候,采用了哪些資料結構,
- List<Node>,Kafka Broker節點,一臺機器
- unautorhizedTopics,沒有被授權訪問的Topic的串列,就是kafka是可以支持權限控制的,如果你的客戶端沒有被授權訪問某個Topic,那么就會放在這個串列里,
- Map<TopicParittion, PartitionInfo>,TopicPartition就代表了一個磁區,里面就是他的topic的名字,以及他在topic里的磁區號;PartitioinInfo,就代表了磁區的詳細資訊,屬于哪個topic,磁區號,每個磁區都有多個副本,Leader在哪個broker上,followers在哪些broker上,ISR串列,都在里面,
- partitionsByTopic,每個topic有哪些磁區
- availablePartitionsByTopic,每個topic有哪些當前可用的磁區,如果某個磁區沒有leader是存活的,此時那個磁區就不可用了,
- partitionsByNode,每個broker上放了哪些磁區,
- nodesById,broker.id -> Node
Producer.Send()
- 回呼自定義的攔截器
- 同步阻塞等待獲取topic元資料
如果你要往一個topic里發送訊息,必須是得有這個topic的元資料的,你必須要知道這個topic有哪些磁區,然后根據Partitioner組件去選擇一個磁區,然后知道這個磁區對應的leader所在的broker,才能跟那個broker建立連接,發送訊息,呼叫同步阻塞的方法,去等待先得獲取到那個topic對應的元資料,如果此時客戶端還沒快取那個topic的元資料,那么一定會發送網路請求到broker去拉取那個topic的元資料過來,但是下一次就可以直接根據快取好的元資料來發送了
- 序列化key和value
你的key和value可以是各種各樣的型別,比如說String、Double、Boolean,或者是自定義的物件,但是如果要發送訊息到broker,必須對這個key和value進行序列化,把那些型別的資料轉換成byte[]位元組陣列的形式
- 基于獲取到的topic元資料,使用Partitioner組件獲取訊息對應的磁區
- 檢查要發送的這條訊息是否超出了請求最大大小,以及記憶體緩沖最大大小
- 設定好自定義的callback回呼函式以及對應的interceptor攔截器的回呼函式
- 將訊息添加到記憶體緩沖里去,RecordAccumulator組件負責的
- 如果某個磁區對應的batch填滿了,或者是新創建了一個batch,此時就會喚醒Sender執行緒,讓他來進行作業,負責發送batch
Topic元資料細粒度按需加載及阻塞等待
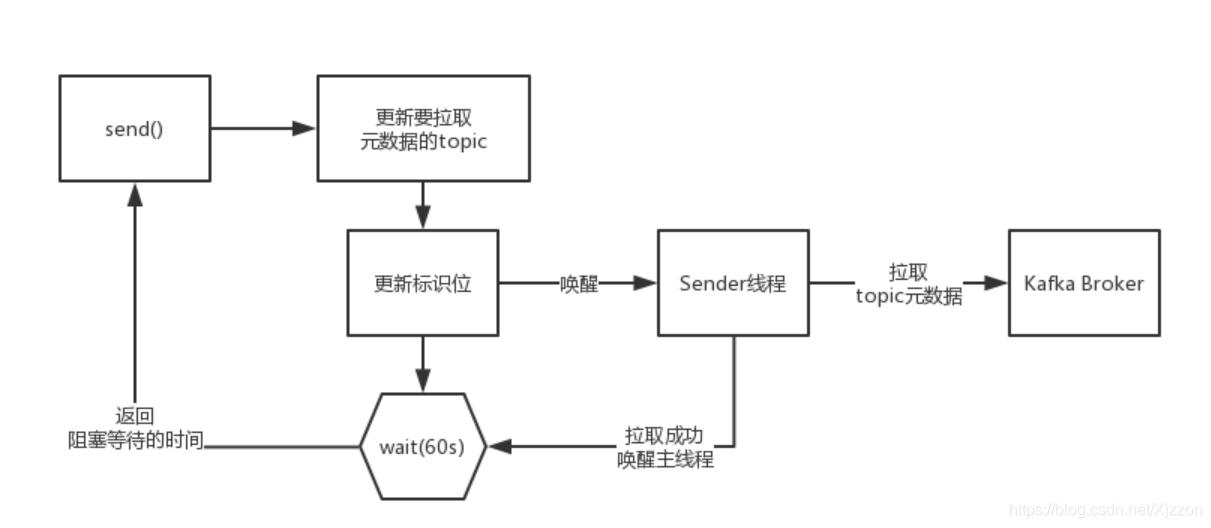
如果元資料拉取成功,那么version會加一,所以在喚醒后只需要判斷當前version是不是大于之前的version就可以判定元資料是否拉取成功,如果超時還沒判定成功,則認為是元資料拉取失敗,
Sender執行緒初始化
public KafkaThread(final String name, Runnable runnable, boolean daemon) {
super(runnable, name);
configureThread(name, daemon);
}
private void configureThread(final String name, boolean daemon) {
setDaemon(daemon);
setUncaughtExceptionHandler(new UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
log.error("Uncaught exception in thread '{}':", name, e);
}
});
}
如果沒指定磁區key是如何對訊息負載均衡分發到磁區的
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
初始值是一個隨機的integer型別的數字,接下來默認是遞增的,一定會保證是一個正整數,就是比如說topic有5個磁區,就會對這個遞增的數字(23),對topic的磁區數量進行取模,
Kafka的記憶體緩沖區
Kafka實作了一個BufferPool,緩沖池,可以利用它申請記憶體,
/**
有人的訊息是52kb,超出了16kb,分配的那個ByteBuffer就會是52kb,如果對52kb的ByteBuffer進行處理,當deallocate的時候他會直接釋放掉這塊記憶體,不去加入到free,讓gc掉,avaialbeMemory給加回去
*/
public BufferPool(long memory, int poolableSize, Metrics metrics, Time time, String metricGrpName) {
this.poolableSize = poolableSize;
this.lock = new ReentrantLock();
// 要釋放的ByteBuffer會放入free快取起來,避免重復向作業系統申請
// 這里只會將poolableSize的放入,也就是等于batch.size的
// 下次申請size等于poolableSize的ByteBuf就可以從free直接回傳
this.free = new ArrayDeque<>();
this.waiters = new ArrayDeque<>();
this.totalMemory = memory;
this.nonPooledAvailableMemory = memory;
this.metrics = metrics;
this.time = time;
this.waitTime = this.metrics.sensor(WAIT_TIME_SENSOR_NAME);
MetricName rateMetricName = metrics.metricName("bufferpool-wait-ratio",
metricGrpName,
"The fraction of time an appender waits for space allocation.");
MetricName totalMetricName = metrics.metricName("bufferpool-wait-time-total",
metricGrpName,
"The total time an appender waits for space allocation.");
this.waitTime.add(new Meter(TimeUnit.NANOSECONDS, rateMetricName, totalMetricName));
}
batches是Kafka實作的一個并發安全的Map即CopyOrWriteMap類,在put方法上加了synchronized,并且是使用的copy進行put,batches的Key是TopicPartition,value是Deque<ProducerBatch>,當嘗試將一條記錄寫入到batch失敗時,就會申請ByteBuf以創建新的Batch,并且將創建的Batch放入Dequeue中,
一條訊息是如何按照二進制協議規范寫入Batch的ByteBuf中的
offset | size | crc | magic | attibutes | timestamp | key size | key | value size | value
是嚴格的按照二進制協議的規范,他規范里規定了,就是先是幾個位元組的offset,然后是幾個位元組的size,然后是幾個位元組的crc,接著是幾個位元組的magic,以此類推,他就是完全按照規范來寫入ByteBuffer里去的,可以看到他最最底層的寫入ByteBuffer的IO流的方式,ByteBufferOutputStream包裹了ByteBuffer,持有一個針對ByteBuffer的輸出流,接著會把ByteBufferOutputStream給包裹在一個壓縮流里,gzip、lz4、snappy,如果是包裹在壓縮流里,寫入的時候會先進入壓縮流的緩沖區,壓縮流會把一條訊息放在緩沖區里,用壓縮演算法給壓縮了,再寫入底層的ByteBufferOutputStream里去,如果是非壓縮的模式,最最普通的情況下,就是DataOutputStream包裹了ByteBufferOutputSteram,然后寫入資料,Long、Byte、String,都會在底層轉換為位元組進入到ByteBuffer里去,
判斷Batch是否還有足夠空間寫入一條記錄
public boolean hasRoomFor(long timestamp, ByteBuffer key, ByteBuffer value, Header[] headers) {
if (isFull())
return false;
// We always allow at least one record to be appended (the ByteBufferOutputStream will grow as needed)
if (numRecords == 0)
return true;
final int recordSize;
if (magic < RecordBatch.MAGIC_VALUE_V2) {
recordSize = Records.LOG_OVERHEAD + LegacyRecord.recordSize(magic, key, value);
} else {
int nextOffsetDelta = lastOffset == null ? 0 : (int) (lastOffset - baseOffset + 1);
long timestampDelta = firstTimestamp == null ? 0 : timestamp - firstTimestamp;
recordSize = DefaultRecord.sizeInBytes(nextOffsetDelta, timestampDelta, key, value, headers);
}
// Be conservative and not take compression of the new record into consideration.
return this.writeLimit >= estimatedBytesWritten() + recordSize;
}
KafkaSender執行緒在做什么
1.確定哪些partition有已經寫滿的batch,batch創建的時間已經超過了linger.ms,此時就有可以發送出去的batch了,收集出來的PartitionLeader所在的broker,
// create produce requests
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
2.如果有一些partition對應的元資料沒拉取到,此時就必須標識一下,必須要在后面去嘗試拉取元資料,
3.檢查一下是否準備好可以向那些Borker發送資料了,就是說如果此時還沒跟某個Broker建立好連接,必須在這里把長連接準備好,TCP連接,然后才可以把資料發送過去,直接就是基于最底層的NIO來開發的,
4.你有很多Partiton可以發送資料,有一些Partition Leader是在同一個Broker上,此時按照Broker對Partition進行分組,找到一個Broker對應的多個Partition的Batch,如果一個batch已經在記憶體緩沖里停留超過60s,超時不要了,
5.對每個Broker都創建一個ClientRequest,包括了多個Batch,就是在這個Broker上的多個LeaderPartition所對應的Batch,聚合起來組成一個ClientRequest,形成一個請求,將他設定到Sender變數中,等待NetWorkClient發送,
6.通過NetWorkClient走底層的網路通信,把每個Broker的ClientRequest給發送過去就可以了,poll方法,他是負責實際的 進行網路IO通信操作的一個核心的方法,負責發送資料出去,也包括讀取回應回來,
Batch何時判定為可以發送出去
ProducerBatch batch = deque.peekFirst();
if (batch != null) {
long waitedTimeMs = batch.waitedTimeMs(nowMs);
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
boolean full = deque.size() > 1 || batch.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough
// since we'll just wake up and then sleep again for the remaining time.
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
剛開始的時候,默認情況下,發送一個Batch,肯定是不涉及到重試,attempts就一定是0,一定沒有進入重試的狀態,waitedTimeMs:當前時間減去上一次發送這個Batch的時間,假設一個Batch從來沒有發送過,此時當前時間減去這個Batch被創建出來的那個時間,這個Batch從創建開始到現在已經等待了多久了,timeToWaitMs:這個Batch從創建開始算起,最多等待多久就必須去發送,如果是在重試的階段,這個時間就是重試間隔,但是在非重試的初始階段,就是linger.ms的時間(100ms),full:Batch是否已滿,如果說Dequeue里超過一個Batch了,說明這個peekFirst回傳的Batch就一定是已經滿的,另外就是如果假設Dequeue里只有一個Batch,但是判斷發現這個Batch達到了16kb的大小,也是已滿,expired:當前Batch已經等待的時間大于等于前面計算的最多只能等待的時間,如果linger.ms默認是0,就意味著說,只要Batch創建出來了,在這個地方一定是expired = true,sendable:綜合上述所有條件來判斷,這個Batch是否需要發送出去,如果Bach已滿必須得發送,如果Batch沒有寫滿但是expired也必須得發送出去,如果說Batch沒有寫滿而且也沒有expired,但是記憶體已經消耗完畢也要發送,flushInProgress()就是客戶端關閉了,此時也會發送,這里判斷成功,是將Node即broker加入到readNodes中,
判定readyNodes里哪些node是可以發送資料過去的
(1)有一個Broker連接狀態的快取,先查一下這個快取,當前這個Broker是否已經建立了連接了,如果是的話,才可以繼續判斷其他的條件,
(2)Selector,你大概可以認為底層封裝的就是Java NIO的 Selector,但凡是看過我的NIO課程,跟著做NIO研發分布式檔案系統,Selector上要注冊很多Channel,每個Channel就代表了跟一個Broker建立的連接,
(3)inFlightRequests,有一個引數可以設定這個東西,默認是對同一個Broker同一時間最多容忍5個請求發送過去但是還沒有收到回應,所以如果對一個Broker已經發送了5個請求,都沒收到回應,此時就不可以繼續發送了,
Producer與broker連接
public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {
ensureNotRegistered(id);
SocketChannel socketChannel = SocketChannel.open();
SelectionKey key = null;
try {
configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize);
// 異步的,不一定真一下連上了
boolean connected = doConnect(socketChannel, address);
// 向selector表示對連接感興趣,如果上一步此時沒連上,在selector有個事件出來的
key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);
if (connected) {
// OP_CONNECT won't trigger for immediately connected channels
log.debug("Immediately connected to node {}", id);
immediatelyConnectedKeys.add(key);
key.interestOps(0);
}
} catch (IOException | RuntimeException e) {
if (key != null)
immediatelyConnectedKeys.remove(key);
channels.remove(id);
socketChannel.close();
throw e;
}
}
工業級NIO底層應該設定哪些網路引數
// 非阻塞
socketChannel.configureBlocking(false);
Socket socket = socketChannel.socket();
// 長連接
socket.setKeepAlive(true);
// 發送緩沖區
if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setSendBufferSize(sendBufferSize);
// 接受緩沖區
if (receiveBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setReceiveBufferSize(receiveBufferSize);
// 非延遲,送出去的資料包立馬就是通過網路傳輸過去
socket.setTcpNoDelay(true);
在不斷輪詢的poll方法中如何將request發送出去
如果說已經發送完畢資料了,那么就可以取消對OP_WRITE事件的關注,否則如果一個Request的資料都沒發送完畢,此時還需要保持對OP_WRITE事件的關注,而且如果發送完畢了,就會放到completedSends里面去,
對于已經發送給Broker的請求會進行什么樣的后續處理
expectResponse應該是通過acks計算出來的,如果說acks = 0的話,也就是不需要對一個請求接收回應,此時expectResponse應該就是false,這個時候直接就會把這個Request從inFlightRequests里面移出去,直接就可以回傳一個回應了,其實就是做一個回呼,
Kafka的生產端發送時如何處理拆包問題
如果說一個請求對應的ByteBuffer中的二進制位元組資料一次write沒有全部發送完畢,如果說一次請求沒有發送完畢,此時肯定remaining是大于0,此時就不會取消對OP_WRITE事件的監聽,假設此時針對某個Broker是說,此時是可以再次發送一個Request了,必須得先判斷一下,這個Broker上一次發送的Request請求是否發送完畢了,那個request中的資料是否發送完了呢?即使發送完畢了,還得限制為最多只發送5個request是沒有收到回應的,如果說上一次 request出現了類似拆包的問題,一次請求沒有發送完畢,此時下次就不會繼續往這個broker發送請求了,但是此時針對這個broker還是保持著OP_WRITE的監聽,下次呼叫poll,會發現對這個broker可以再次執行WRITABLE事件,最侄訓再次對SocketChannel呼叫write方法,把ByteBuffer里剩余的資料繼續往Broker去寫,上述的程序重復多次,一定會把這個請求發送完畢的,
Kafka的生產端在讀取資料時如何解決粘包問題
要解決粘包問題,就是每個回應中間必須插入一個特殊的幾個位元組的分隔符,一般來說用作分隔符比如很經典的就是在回應訊息前面先插入4個位元組(integer型別的)代表回應訊息自己本身資料大小的數字
回應訊息1,199個位元組;回應訊息2,238個位元組;回應訊息3,355個位元組
199回應訊息(1)238回應訊息(2)355回應訊息(3)
此時會從channel中讀取4個位元組的數字,寫入到一個叫變數名稱為size的ByteBuffer(4個位元組),就是如果已經讀取到了4個位元組,position就會變成4,就會跟limit是一樣的,此時就代表著size ByteBuffer的4個位元組已經讀滿了,意味著size讀到了,可以直接讀實際資料了,ByteBuffer.rewind,把position設定為0,一個ByteBuffer寫滿之后,呼叫rewind,把position重置為0,此時就可以從ByteBuffer里讀取資料了,ByteBuffer.getInt(),就會默認從ByteBuffer當前position的位置獲取4個位元組,轉換為一個int型別的數字回傳給你,接下來就會直接把channel里的一條回應訊息的資料讀取到一個跟他的大小一致的ByteBuffer中去,粘包問題的解決,就是完美的通過每條訊息基于一個4個位元組的int數字(他們自己的大小)來進行分割,拆包,假如說size是4個位元組,你一次read就讀取到了2個位元組,連size都沒有讀取完畢,出現了拆包,此時怎么辦呢?或者你讀取到了一個size,199個位元組,但是在讀取回應訊息的時候,就讀取到了162個位元組,拆包問題,回應訊息沒有讀取完畢,對于前者szie buffer還沒讀滿,會接著讀size buffer,對于后者,buffer沒讀完,也要接著讀,
如果broker回應為例外,producer將如何處理
判斷重試次數,將batch重新加入給放回到Accumulator里的Queue去,會直接放到頭部去,
重新在記憶體緩沖里入隊的Batch在什么時機下會判定可以重試
其實就是前面判斷batch能否發送的代碼,已經考慮了重試的情況了,
如果一個inFlightRequest一直沒有收到回應,會怎么處理
如果說發現有節點對請求是超時回應的,過了60s還沒回應,此時會關閉掉跟那個Broker的連接,認為那個Broker已經故障了 ,做很多記憶體資料結構的清理,再次標記為需要去重新拉取元資料
整體流程
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286238.html
標籤:其他
上一篇:再見了,學術碩士!
下一篇:sersync 實作實時資料同步