hadoop離線day09--Apache Hive
目錄
hadoop離線day09--Apache Hive
今日內容大綱
1、HQL DDL 資料定義語言
磁區表
磁區表創建
磁區表加載資料
總結及注意事項
多重磁區表
分桶表
分桶表創建
分桶表加載資料
HQL DDL 資料定義語言
修改表
show場景語法
2、HQL DML 資料操縱語言
Dynamic partition inserts 動態磁區插入
匯出資料操作
3、HQL DQL 資料查詢語言
Common Table Expressions(CTE)
Hive join
4、Hive shell命令列 引數配置
今日內容大綱
#1、HQL DDL 資料定義語言
創建表
磁區表
分桶表
修改表 alter
常用的show命令
#2、HQL DML 資料操縱語言
load加載資料
insert插入資料
mysql:insert+values
hive:insert+select
動態磁區插入
資料匯出
#3、HQL DQL 資料查詢語言
select
hive自己特有的查詢
CTE語法
union語法
Hive join
inner join、left join
#4、Hive shell命令列 引數配置
bin/hive shell
bin/beeline jdbc
hive引數配置方式
1、HQL DDL 資料定義語言
-
磁區表
-
磁區表引入,產生背景
--創建一張表 映射一個檔案 create table t_user(id int,name string,country string) row format delimited fields terminated by ','; ? --能否在一張表的目錄下 映射多個檔案呢? --可以 保證多個檔案之間欄位、型別、個數、順序是一致 ? --查詢:找出來自于中國的用戶 select * from t_user where country ="china"; --問題:在where過濾的時候 需要進行全表掃描 判斷過濾條件十分滿足 --全表掃描性能不高 如何優化? ? --通過hdfs底層存盤格式 猜想:能否基于檔案去掃描指定的檔案,而不是全表掃描 效率不就提高了嗎?
-
磁區表創建
--基于業務分析 決定根據國家磁區 create table t_user_part(id int,name string,country string) partitioned by(country string) row format delimited fields terminated by ','; ? Error: Error while compiling statement: FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns --建表報錯 磁區欄位重復 ? create table t_user_part(id int,name string,country string) partitioned by(guojia string) row format delimited fields terminated by ','; ?
-
磁區表加載資料
--猜想方式1:使用hadoop fs -put 上傳表的目錄下 失敗 沒有指定該檔案屬于哪個磁區 沒有指定磁區值 --正確方式: load data語法 load data local inpath '/root/hivedata/chian.txt' into table t_user_part partition(guojia="zhongguo"); --加載china.txt檔案到磁區表中 并且指定該檔案屬于zhongguo磁區, ? load data local inpath '/root/hivedata/usa.txt' into table t_user_part partition(guojia="meiguo"); load data local inpath '/root/hivedata/japan.txt' into table t_user_part partition(guojia="riben");
-
磁區表使用
--查詢:找出來自于中國的用戶 select * from t_user where country ="china"; --非磁區欄位查詢 ? select * from t_user where guojia ="zhongguo"; --基于磁區表磁區欄位查詢
-
總結及注意事項
-
磁區表是一種優化表,主要是提高查詢效率,減少全表掃描,
-
磁區的欄位不能是表中已有的欄位?為什么 磁區欄位也會作為結果顯示查詢內容上,不能重復,
-
磁區欄位是虛擬的欄位,其內容不是來自于底層檔案的映射,來自于加載資料時指定,
-
磁區表底層形式就是在表的檔案夾下面繼續創建子檔案,子檔案的名字就是磁區欄位和磁區值組合
#非磁區表 /user/hive/warehouse/itcast.db/t_user china.txt japan.txt usa.txt #磁區表 /user/hive/warehouse/itcast.db/t_user_part /guojia=zhongguo china.txt /guojia=riben japan.txt /guojia=meiguo usa.txt -
企業中常見的磁區欄位
-
時間維度 年 月 天
-
地域維度 省 市
-
-
-
多重磁區表
-
Hive支持在多個磁區欄位,也就是所謂多重磁區表,常見的是2磁區表,
-
多磁區的意思是指在前一個磁區的基礎上繼續磁區
-
底層來看就是檔案夾下面繼續創建子檔案
--創建2磁區表 create table t_user_double_part(id int,name string,country string) partitioned by(guojia string,sheng string) row format delimited fields terminated by ','; ? --load load data local inpath '/root/hivedata/china_sh.txt' into table t_user_double_part partition(guojia="zhongguo",sheng="shanghai"); ? load data local inpath '/root/hivedata/china_bj.txt' into table t_user_double_part partition(guojia="zhongguo",sheng="beijing"); ? load data local inpath '/root/hivedata/usa_dz.txt' into table t_user_double_part partition(guojia="meiguo",sheng="dezhou"); ? --查詢 select * from t_user_double_part where guojia ="zhongguo"; ? select * from t_user_double_part where guojia ="zhongguo" and sheng ="shanghai";
-
-
-
分桶表
-
語法上剖析
[clustered by (col_name, col_name, ...) [sorted by (col_name [asc|desc], ...)] into num_buckets buckets] ? --精簡 clustered by xxx into N buckets ? clustered by xxx 根據xxx分在一起 into N buckets 分為幾桶 ? --通俗解釋:根據xxx欄位把表的資料分為N個部分, t_user(id,name,country) ? 根據誰分? clustered by xxx xxx就是分的欄位 ? 分為幾個部分?into N buckets N ? 如何分? --如果分桶的欄位xxx是數值型別欄位, xxx % N 余數相同的到一起 --如果分桶的欄位xxx是字串或者其他型別 xxx.hash % N 余數相同的到一起 --如果有需求 還可以知道每個分桶內排序規則 sorted by (col_name [asc|desc]) -
分桶表創建
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) clustered by(Sno) into 4 buckets row format delimited fields terminated by ',';
-
分桶表加載資料
--如何判斷分桶表的資料加載成功 1、正確決議顯示資料 2、底層檔案分成N個部分 --直接hadoop fs-put 和load加載都是不可以的 --分桶表采用insert+select 間接的方式才能加載資料 ? --step1:創建一個普通的表 并加載資料到普通表中 create table student(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ','; ? --step2: 開啟分桶功能 set hive.enforce.bucketing = true; ? --注意這個引數 hive.enforce.bucketing Default Value: Hive 0.x: false Hive 1.x: false Hive 2.x: removed, which effectively makes it always true (HIVE-12331) Added In: Hive 0.6.0 --step3: 把資料從普通表中查詢出來插入到分桶表中 ? insert into table stu_buck select * from student; -
分桶表使用
-
和正常表一樣使用,底層查詢時hive自動優化,
-
-
分桶表總結及注意事項
-
分桶表也是一種優化手段表,主要提高join查詢時候效率,減少笛卡爾積數量;
-
此外還可以方便抽樣查詢,
-
分桶表的欄位必須是表中已有欄位,
-
-
-
HQL DDL 資料定義語言
-
修改表
-
修改表的屬性資訊
-
修改表的磁區屬性資訊
-
修改表的欄位
-
-
語法核心關鍵字:alter
-
注意:在Hive中,修改表的操作使用不多,可以使用drop+create 替代,為什么?
#mysql中不這么干? create table--->insert values #意味著mysql加載資料的成本極高, ? #hive中為什么可以? create table--->映射已經存在的檔案(外部表保護檔案) # 洗掉再創建的成本極低
-
栗子
--增加磁區 先有磁區檔案 補充元資料 ALTER TABLE t_user_part ADD PARTITION (guojia='yingguo') location '/user/hive/warehouse/itcast.db/t_user_part/guojia=yingguo'; ? --洗掉磁區 ALTER TABLE t_user_part DROP IF EXISTS PARTITION (guojia='yingguo'); ? --修改磁區 重命名磁區 ALTER TABLE t_user_part PARTITION (guojia='yingguo') RENAME TO PARTITION (guojia='dydg'); ? --列操作 ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name STRING); --注:ADD 是代表新增一個欄位,新增欄位位置在所有列后面(partition 列前) --REPLACE 則是表示替換表中所有欄位, ALTER TABLE table_name RENAME TO new_table_name
show場景語法
--1、顯示所有資料庫 SCHEMAS和DATABASES的用法 功能一樣 show databases; show schemas; ? --2、顯示當前資料庫所有表 show tables; SHOW TABLES [IN database_name]; --指定某個資料庫 ? --3、顯示表磁區資訊,磁區按字母順序列出,不是磁區表執行該陳述句會報錯 show partitions table_name; ? ? --4、顯示表/磁區的擴展資訊 SHOW TABLE EXTENDED [IN|FROM database_name] LIKE table_name; show table extended like student; describe formatted itheima.student; ? --5、顯示表的屬性資訊 show tblproperties student; ? --6、顯示表建表陳述句 show create table student; ? --9、顯示表中的所有列,包括磁區列, SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name]; show columns in student; ? --10、顯示當前支持的所有自定義和內置的函式 show functions; ? --11、Describe desc --查看表資訊 desc extended table_name; --查看表資訊(格式化美觀) desc formatted table_name; --查看資料庫相關資訊 describe database database_name;
#探究
1、hive做了什么
將結構化檔案映射成為一張表 記錄著映射資訊(元資料)
2、MySQL中存盤的是什么資料
存盤著映射資訊 元資料
3、HDFS中存盤的是什么資料
存盤的是結構化檔案 表的真實的資料
?
#查看表的元資料資訊 hive記錄了這個表哪些資訊
desc formatted student;
2、HQL DML 資料操縱語言
-
load
-
功能:加載操作是將資料檔案移動到與 Hive表對應的位置的純復制/移動操作,
-
語法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
-
核心關鍵字--local
-
有local 表示從本地檔案系統加載到hive表中
-
沒有local 表示從hdfs檔案系統加載到hive表中
-
-
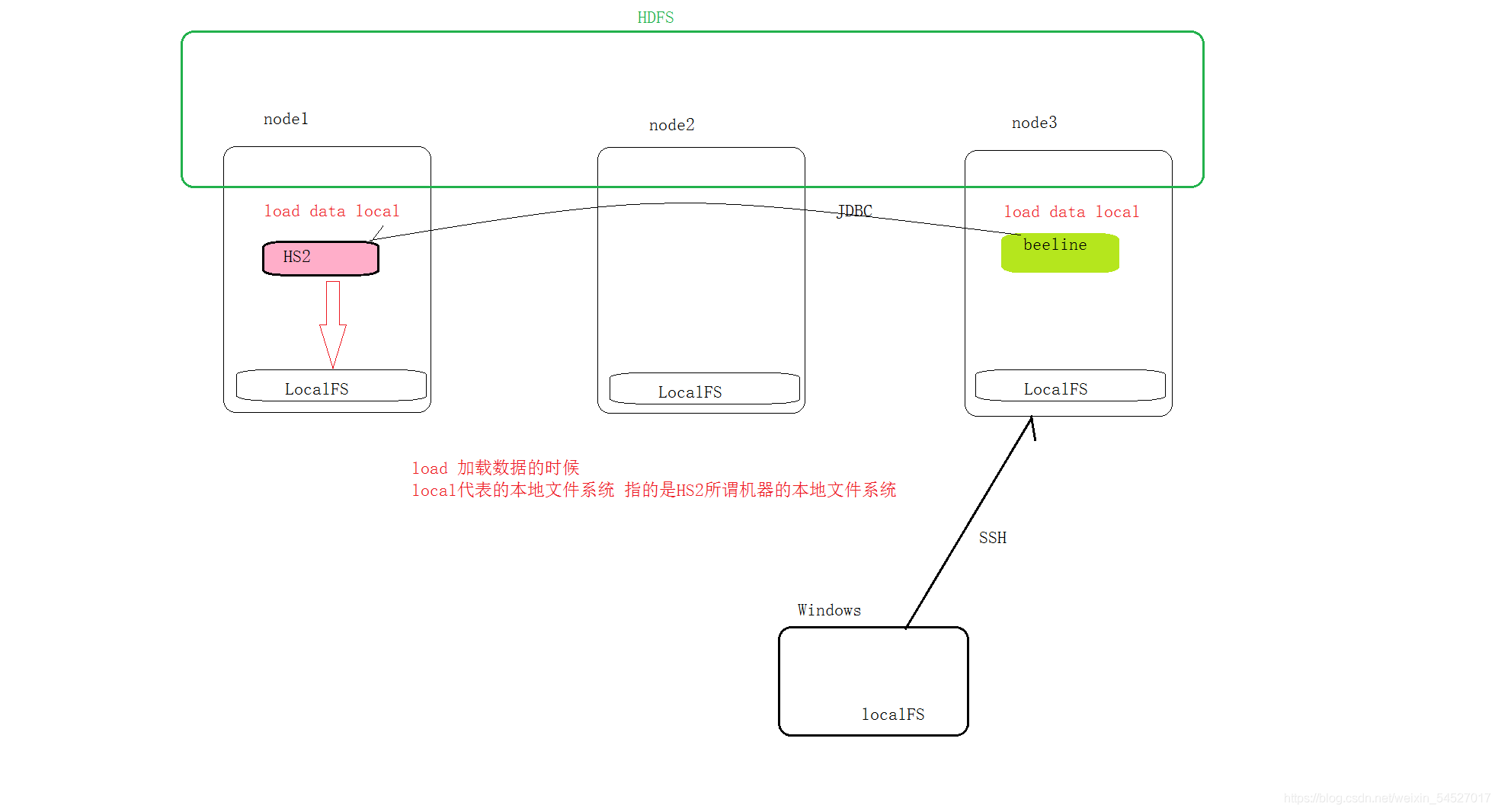
究竟哪個本地是本地檔案系統,
-
栗子
create table student_from_local(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ','; ? create table student_from_hdfs(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ','; ? --1、從本地加載資料到student_from_local load data local inpath '/root/hivedata/students.txt' into table student_from_local; --從本地加載的時候 是一個資料復制操作 --底層的本質就是 hadoop fs -put --2、從HDFS加載資料到student_from_hdfs load data inpath '/stu/students.txt' into table student_from_hdfs; --從hdfs加載的時候 是一個資料移動操作 --底層的本質就是 hadoop fs -mv -
結論:官方推薦使用load命令加載資料到Hive表中,實際上無論什么方式,只有把檔案放置在表的目錄下就可以,
-
-
insert插入資料
-
回顧
mysql: insert into table values(1,"zhangsan"); ? --insert +values語法在hive中能否使用, ? create table t_insert(id int,name string); ? insert into table t_insert values(1,"allen"); ? --語法可以在hive使用 但是效率較低, 推薦使用load加載資料方式,
-
insert在hive中如何
-
語法:insert+select
-
功能:把后面查詢回傳的結果作為內容插入到表中 也是ETL中常見的操作,
-
注意:查詢回傳結果的欄位型別、順序、含義、個數要和待插入表一致,
-
栗子
create table t_insert_1(name string); ? insert into t_insert_1 select name from t_insert; ? --如何插入的表是磁區表 還需要指定磁區值 insert into t_insert_1 partition() select name from t_insert;
-
-
開啟智能本地模式
SET hive.exec.mode.local.auto=true;
-
Multi Inserts 多重插入 多次插入
-
一次掃描,多次插入 減少全表掃描的次數
from source_table insert overwrite table test_insert1 select id insert overwrite table test_insert2 select name;
-
-
Dynamic partition inserts 動態磁區插入
-
探討
--動態磁區、靜態磁區 --研究的是:磁區表的磁區值是如何決定的? ? load data local inpath '/root/hivedata/usa.txt' into table t_user_part partition(guojia="meiguo"); ? usa.txt--->meiguo --sql中寫死的 靜態磁區 insert +seletc --根據查詢結果動態確定的磁區 動態磁區
-
栗子
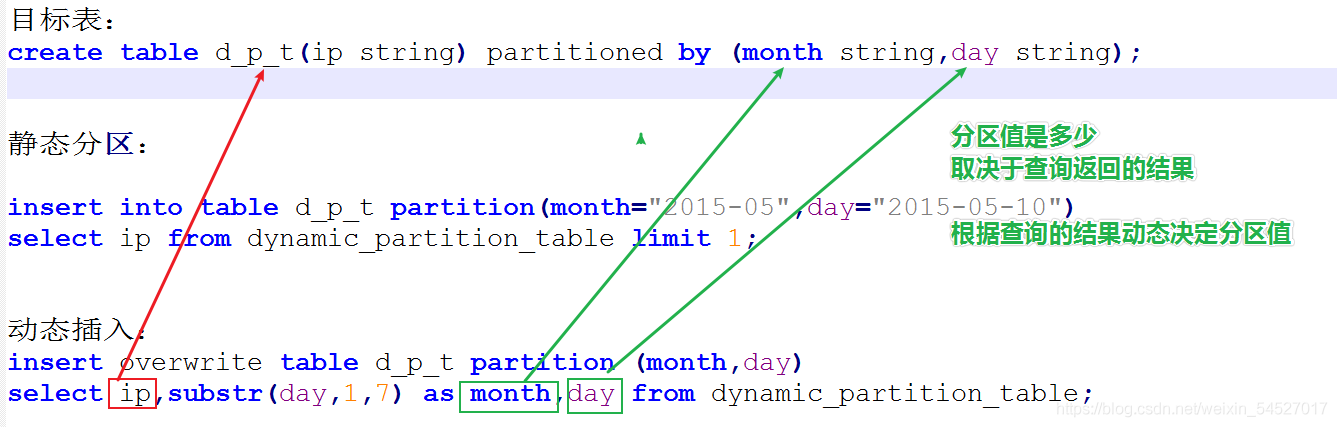
--step1: 開啟動態磁區功能 設定動態磁區的執行模式 set hive.exec.dynamic.partition=true; #是否開啟動態磁區功能,默認false關閉, set hive.exec.dynamic.partition.mode=nonstrict; #動態磁區的模式,默認strict,表示必須指定至少一個磁區為靜態磁區,nonstrict模式表示允許所有的磁區欄位都可以使用動態磁區, ? Error: Error while compiling statement: FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict (state=42000,code=10096) ? --理解嚴格 非嚴格模式 insert into table d_p_t partition(month="2015-05",day) select ip,day from dynamic_partition_table; --嚴格模式 ? insert into table d_p_t partition(month,day) --非嚴格模式 select ip,month,day from dynamic_partition_table; ? ? --step2:執行動態磁區 insert overwrite table d_p_t partition (month,day) select ip,substr(day,1,7) as month,day from dynamic_partition_table;
-
-
匯出資料操作
-
語法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...;
-
注意事項
-
local表示把資料匯出到HS2所在機器的本地檔案系統 否則就匯出到HDFS.
-
OVERWRITE表示把目錄下的資料給覆寫,
-
默認匯出的資料以\001作為欄位分隔符 也可以指定分隔符,
-
-
栗子
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/aaa' SELECT * FROM student; ? INSERT OVERWRITE DIRECTORY '/aaa' SELECT * FROM student;
-
-
3、HQL DQL 資料查詢語言
-
完整語法樹
[WITH CommonTableExpression (, CommonTableExpression)*] SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT [offset,] rows]; -
CLUSTER BY 分桶查詢
-
功能:根據指定的欄位把資料分成若干部分,每個部分中再根據這個欄位進行排序,只能正序
-
概況:根據欄位 分且排序動作,
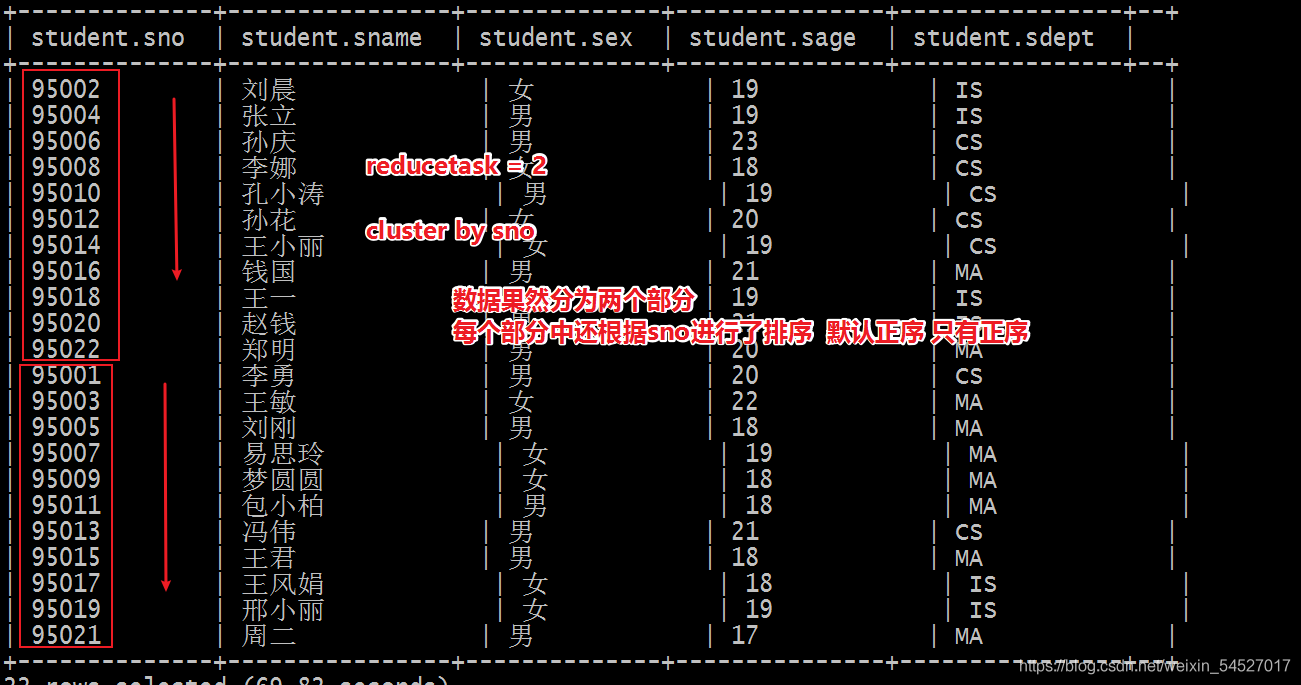
0: jdbc:hive2://node1:10000> select * from student; +--------------+----------------+--------------+---------------+----------------+--+ | student.sno | student.sname | student.sex | student.sage | student.sdept | +--------------+----------------+--------------+---------------+----------------+--+ ? --1、根據誰分 CLUSTER BY xxx ? --2、分成幾個部分 取決于底層reducetask的個數 個數如何決定的呢? 如果用戶不設定 自己根據資料量大小自動評估 如果用戶手動設定 就以設定的為準 ? --3、如何分 規則和分桶表的規則一模一樣 select * from student cluster by sno; ---默認情況下 根據輸入資料量來自動評估reducetask個數 Number of reduce tasks not specified. Estimated from input data size: 1 ? --手動設定reducetask個數 set mapreduce.job.reduces =2; Number of reduce tasks not specified. Defaulting to jobconf value of: 2 ? set mapreduce.job.reduces =3; Number of reduce tasks not specified. Defaulting to jobconf value of: 3 ? --需求:根據sno分為2個部分 每個部分中根據sage 倒序排序 set mapreduce.job.reduces =2; select * from student cluster by sno sort by sage desc; ? Error: Error while compiling statement: FAILED: SemanticException 1:45 Cannot have both CLUSTER BY and SORT BY clauses. Error encountered near token 'sage' (state=42000,code=40000) -
-
DISTRIBUTE BY + SORT BY
-
功能:DISTRIBUTE BY 只負責分 SORT BY只負責排序 兩個欄位還可以不一樣,
-
如果欄位一樣的話:CLUSTER BY(分且排序)= DISTRIBUTE BY(分) +SORT BY(排序)
set mapreduce.job.reduces =2; select * from student distribute by sno sort by sage desc;
-
-
ORDER BY 全域排序
-
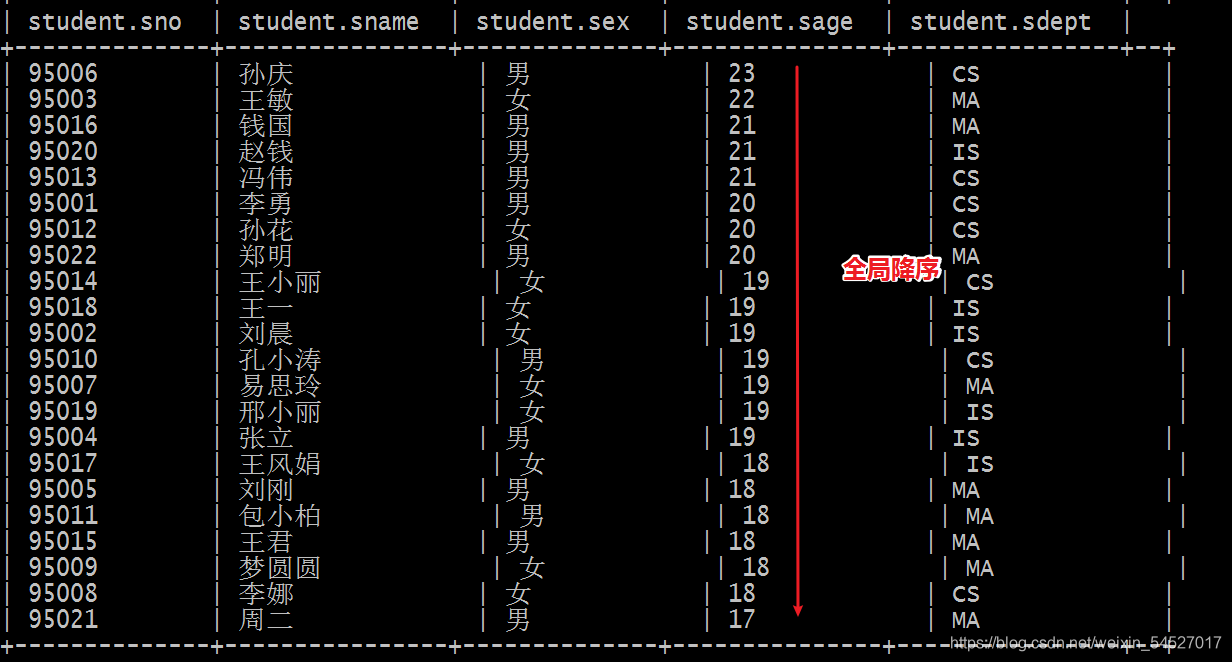
如何理解全域二字? 全域意味著所有的資料都必須在一個檔案中,意味著底層只能有一個reducetask.
-
為了滿足order by全域的實作,在編譯期間hive會強制將reducetask個數設定為1,
set mapreduce.job.reduces =4; select * from student order by sage desc; --在編譯期間 hive把個數設定為1 用戶設定的不生效 Number of reduce tasks determined at compile time: 1
-
order by 、sort by
-
sort by是在資料進行完拆分,每個部分內部排序 區域排序
-
order by是全域資料排序 不會對資料拆分 資料在一起的 完整 全域!!!
-
-
-
-
union聯合查詢
-
功能:將多個select查詢回傳的結果集合并為一個結果集,
-
語法:
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...; ? --1、union= union distinct 結果集去重 --2、union all 結果集不去重
-
栗子
select sno,sname from student_from_local UNION select sno,sname from student_from_hdfs; ? --和上面一樣 select sno,sname from student_from_local UNION DISTINCT select sno,sname from student_from_hdfs; ? --使用ALL關鍵字會保留重復行, select sno,sname from student_from_local UNION ALL select sno,sname from student_from_hdfs limit 2;
-
注意事項
-
如果想針對某一條select結果進行條件控制 使用嵌套子查詢包裹;
-
如果把條件控制寫在最后一個select后,對整個union之后的結果集進行操作,
-
-
-
Common Table Expressions(CTE)
-
以with關鍵字引導的一個子查詢 其命令可以在后續的查詢中多次使用,
-
語法糖,
--select陳述句中的CTE with q1 as (select sno,sname,sage from student where sno = 95002) select * from q1; ? --嵌套子查詢語法 select * from (select sno,sname,sage from student where sno = 95002) as q1; ? -- from風格 with q1 as (select sno,sname,sage from student where sno = 95002) from q1 select *; ? -- chaining CTEs 鏈式 with q1 as ( select * from student where sno = 95002), q2 as ( select sno,sname,sage from q1) select * from (select sno from q2) a; -
-
Hive join
-
-
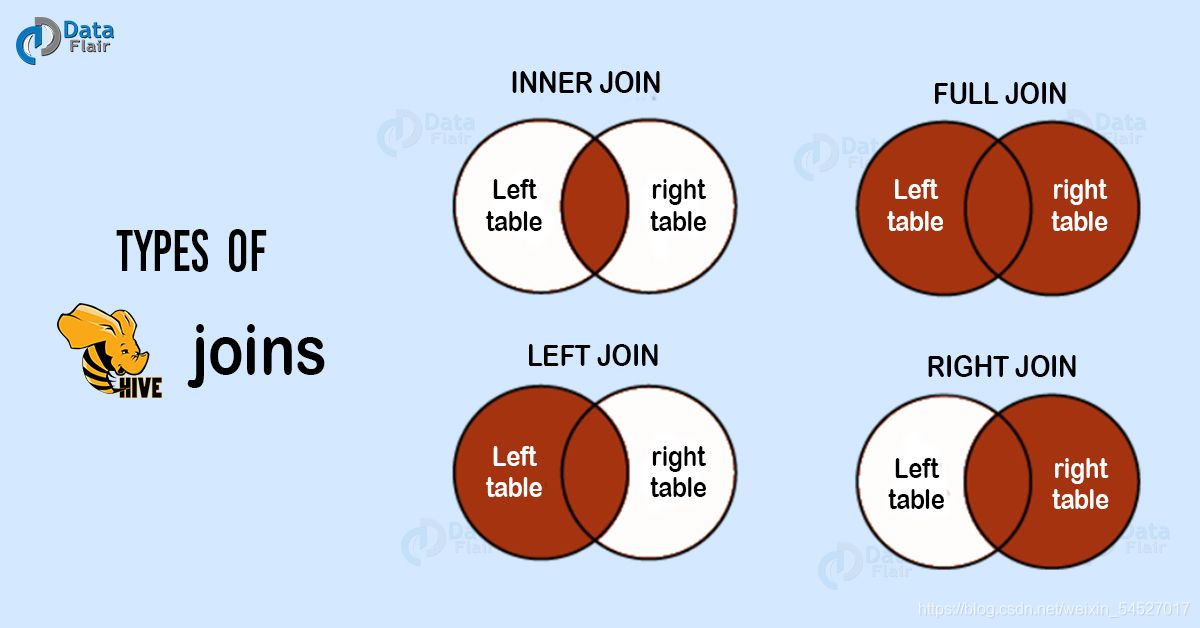
-
產生背景
#現實中 不會把所有的資料都存盤在一張表中 而是根據業務 應用分別存盤, ? #在某些查詢的需求中 又需要基于多張表共同查詢回傳結果 需要join關聯查詢,
-
6種join語法
join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition | table_reference LEFT SEMI JOIN table_reference join_condition | table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)-
inner join
inner join == join 默認就是內連接 ? --左右兩邊都滿足的回傳
-
outer join
full outer join == outer join 全外連接 外連接
-
left join
以左表為準,顯示左表的所有內容 右表與之關聯 關聯上的顯示 關聯不上的顯示null
-
right join
與left join相反
-
left semi join
左半開連接 == 效果等于內關聯只顯示左表的部分 ? select * from a left semi join b on a.id = b.id; +-------+--------- | a.id | a.name +-------+--------- | 2 | b | 3 | c | 7 | y +-------+--------- ? ? select a.* from a inner join b on a.id=b.id; +-------+--------- | a.id | a.name +-------+--------- | 2 | b | 3 | c | 7 | y +-------+---------
-
cross join(#慎用)
--笛卡爾積join 交叉相差 往往不帶on條件 ? --級聯求和 級聯累加 自己和自己join可以解決 ? --更好的方式 sum + windows function
-
-
注意事項
-
Hive 支持等值連接(a.id = b.id),不支持非等值(a.id>b.id)的連接,
select * from a join b on a.id = b.id; ? select * from a join b on a.id > b.id; --當下hive 2.1.0不支持,
-
-
難點
-
join的優化
-
map端join
-
reduce端join(common join)
-
bucket join
-
大小表join
-
大表join 空值處理問題
-
-
如何根據業務需求寫join陳述句
-
-
4、Hive shell命令列 引數配置
-
shell命令列
-
位置:bin/hive
-
功能1:啟動hive的相關服務
/export/server/hive/bin/hive --service hiveserver2|metastore
-
功能2:作為第一代客戶端訪問metastore服務
-
功能3:執行HQL腳本
#執行后面指定的sql /export/server/hive/bin/hive -e 'select sno from itcast.student limit 3' ? #執行后面指定的sql檔案 vim xxx.sql ? $HIVE_HOME/bin/hive -f /home/my/hive-script.sql $HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql ? #sql檔案后綴名 見名知意 通常以.sql結尾 可以任意后綴名 保證里面內容sql語法正確即可,
-
-
Hive引數配置及方式
-
配置引數在哪里
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
-
如何配置引數
-
方式1:hive-site.xml中 覆寫default,
影響的是這個安裝包的任何一種使用方式, 不管是啟動服務 還是基于本安裝包啟動客戶端 都會加載該檔案,
-
方式2:--hiveconf
/export/server/hive/bin/hive --service metastore ? /export/server/hive/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console ? 影響的服務的生命周期 客戶端的生命周期
-
方式3:使用set命令
set hive.exec.dynamic.partition=true; #是否開啟動態磁區功能,默認false關閉, set hive.exec.dynamic.partition.mode=nonstrict; ? 影響的客戶端和服務之間的session會話 ? session結束 設定引數失效 恢復默認值
-
-
企業開發中,推薦使用set命令
誰需要 誰設定 誰生效 影響其他人使用,
-
優先級:set命令最高
-
Hive作為基于Hadoop的軟體 還會把Hadoop的組態檔加載進來 作為自己的配置的一部分,
-
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286242.html
標籤:其他