一.流處理的相關概念
資料的時效性
日常作業中,一般會先把資料存盤在表,然后對表的資料進行加工、分析,既然先存盤在表中,那就會涉及到時效性概念,
如果處理以年,月為單位的級別的資料處理,進行統計分析,個性化推薦,那么資料的的最新日期離當前有幾個甚至上月都沒有問題,但是如果處理的是以天為級別,或者一小時甚至更小粒度的資料處理,那么就要求資料的時效性更高了,比如:
對網站的實時監控
對例外日志的監控
這些場景需要作業人員立即回應,這樣的場景下,傳統的統一收集資料,再存到資料庫中, 再取出來進行分析就無法滿足高時效性的需求了,
流式計算和批量計算
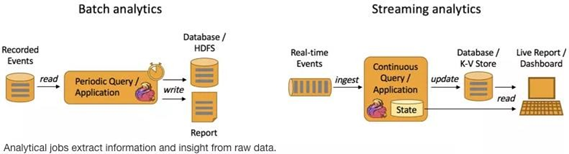
Batch Analytics 批量計算: 統一收集資料->存盤到DB->對資料進行批量處理,就是傳統意義上使用類似于 Map Reduce、Hive、Spark Batch 等,對作業進行分析、處理、生成離線報表
Streaming Analytics 流式計算:顧名思義,就是對資料流進行處理,如使用流式分析引擎如 Storm,Flink 實時處理分析資料,應用較多的場景如實時大屏、實時報表,
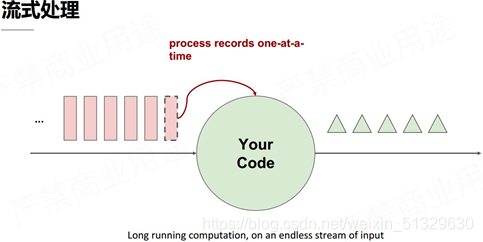
它們的主要區別是:
與批量計算,慢慢積累資料不同,流計算立刻計算,資料持續流動,完成之后就丟棄;
批量計算是維護一張表,對表進行實施各種計算邏輯,流式計算相反,是必須先定義好計算邏輯,提交到流式計算系統,這個計算作業邏輯在整個運行期間是不可更改的;
計算結果上,批量計算對全部資料進行計算后傳輸結果,流式計算是每次小批量計算后,結果可以立刻實時化展現;
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
2. DataStream
任何型別的資料都可以形成一種事件流,信用卡交易、傳感器測量、機器日志、網站或移動應用程式上的用戶互動記錄,所有這些資料都形成一種流,
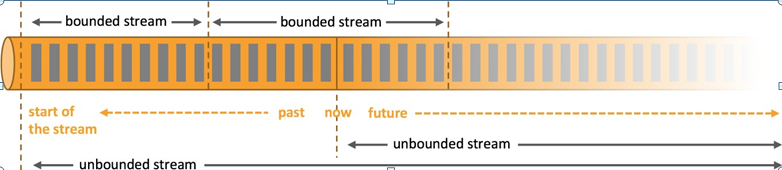
資料可以被作為 無界(unbounded) 或者 有界(bounded) 資料流來處理:
有邊界流(bounded stream):有定義流的開始,也有定義流的結束,有界流可以在攝取所有資料后再進行計算,有界流所有資料可以被排序,所以并不需要有序攝取,有界流處理通常被稱為批處理,
無邊界流(unbound stream):有定義流的開始,但沒有定義流的結束,它們會無休止地產生資料,無界流的資料必須持續處理,即資料被攝取后需要立刻處理,不能等到所有資料都到達再處理,因為輸入是無限的,在任何時候輸入都不會完成,處理無界資料通常要求以特定順序攝取事件,例如事件發生的順序,以便能夠推斷結果的完整性,
DataStream(資料流)官方定義:
 ]
]
DataStream(資料流)原始碼中定義:

DataStream資料流有5個子類,截圖如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286241.html
標籤:其他