序
since:2021年6月3日 19:32
suth: Hadi
注:由于為公司專案,所以大多數內容進行了屏蔽或洗掉處理,記錄此只是希望大家繼續學習,如果發現任何ip、人物、服務器等資訊,請立即私信我進行更改,請勿走上違法犯罪道路!
前言
5月26號接到上級命令,協助優化Flink推送資料,現在問題有資料掉落,資料重復,資料積壓,資料損壞等等,基本能遇到的資料推送的問題全都有了,所用核心數為105核(本文所有的資源與資料量都是以A預處理集群進行討論的),單核單位MEM為4G,資料量大概為500億/天,高峰在8點~20點(其中10點和14點最高峰),所以按照常理來順澩應該是完全足夠的,流程為從預處理節點進行資料消費后直接推送到核心節點進行對外資料共享,
環境介紹
資源情況
預處理集群Kafka為21臺服務器,核心Kafka為10臺,帶寬140G(在6月2日進行了升級到400G),這個帶寬會與其他資料量共用,預處理服務器單臺64 CPU,251G MEM,65T 機械硬碟,核心CPU和MEM與預處理相同,100T 機械(部分SSD),預處理Kafka監控沒有,實時程式執行情況沒有,核心Kafka監控沒有,
架構情況
預處理處理資料在各個預處理集群,有N個較小的集群作為預處理集群,我們稱之為預處理集群,后續只會提到兩個預處理集群為A和B,
預處理完畢后在中央核心集群進行進一步加工等其他操作,稱之為核心集群,
環境改造
總體監控設計
由于排查問題為預處理集群資料量大的都存在該問題,故先把沒有的監控搭建上,包含預處理Kafka Manager、實時程式 pushgetway,核心Kafka Manager,
剛好一個月前搭建了一個Promethues用于NiFi預處理的積壓監控,網路也是互通的,故在此上面進行監控配置升級,
首先搭建KafkaManager在核心,一共兩個KafkaManager用于核心和預處理節點的Kafka集群監控,然后在Promethues中配置各類Metrics指標抓取,最后由Grafana進行展示,效果如下圖
在進行監控搭建的程序中,也發現了各種奇葩的報錯與問題,比如核心集群與預處理集群的Kafka配置全為默認值,B預處理kafka集群與某其他程式在同一服務器,其中這個程式固定吃200G記憶體,但CPU占用不到5%,嚴重影響資源配比,
現在回過頭來看看監控,最嚴重的的省份就是 A和B兩個集群,我們這里挑最嚴重的A和B進行排查,
預處理Kafka集群
剛剛也說過了,在預處理的Kafka與核心的Kafka配置皆為默認值,直接登錄進行修改配置吧,
登錄Ambari進行Kafka更改
KafkaManager 各省配置
直接上部分更改配置:
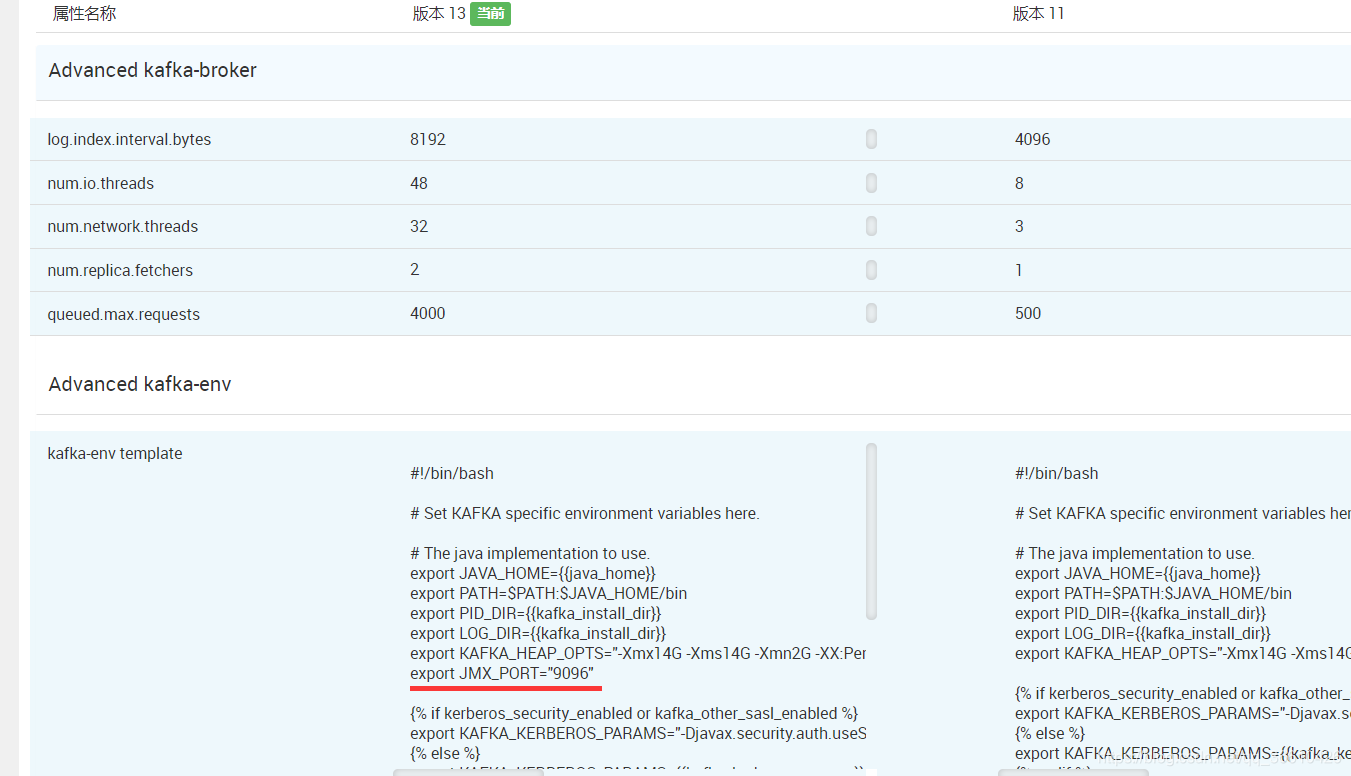
記憶體使用從4G提到12G,
PS:預處理Kafka集群此前并沒有配置log列印資訊,但預處理Kafka集群問題不明顯,只是會影響消費資料入庫和消費速度,故沒有繼續精細化配置,
可以參考的kafka端配置有:
| 配置名 | 內容 | 備注 |
| message.max.bytes | 訊息體的最大大小,單位是位元組 |
|
| num.network.threads | broker 處理訊息的最大執行緒數 |
|
| num.io.threads | broker處理磁盤IO 的執行緒數 |
|
| background.threads | 后臺任務處理的執行緒數 | 洗掉檔案執行緒池 |
| queued.max.requests | 等待IO執行緒處理的請求佇列最大數 | 熔斷 |
| socket.send.buffer.bytes | socket的發送緩沖區 |
|
| socket.receive.buffer.bytes | socket的接受緩沖區 |
|
| socket.request.max.bytes | socket請求的最大數值 |
|
| log.segment.bytes | segment檔案大小 |
|
| log.cleaner.min.cleanable.ratio | 日志清理的頻率控制 |
|
核心Kafka集群
核心kafka集群在排憂的程序中,進行了一次擴容操作,從10擴容到23,更改與上述差不多的配置,由于是對外提供服務器的kafka集群,所以采用了配置滾動重啟的方式進行配置重啟,
其中有一臺Kafka服務器,至今也無法連入其他Kafka服務器,所以只能進行下線操作,這個排錯還在進行中,
Flink推送程式
在入手Flink程式的時候,就很樸實無華,消費寫出,完事,
之前也提到了,問題就比較少,就是資料多了,資料少了,資料不完整了,資料有時延了,資料有重復了,
那么久先查看下實時程式吧:大概使用checkpoint進行offset提交預處理消費,producer推送到核心kafka,那為什么這么慢?以B預處理集群為例,每天500億的結果資料推送到核心集群kafka,使用批量推送,每次1k條,
問題點:
使用checkpoint的時候,sink端需要進行冪等性操作,不然會在程式失敗的時候導致重復寫入,
批量推送沒有問題,但是并沒有進行壓縮操作,導致資料大小太大,進行遠距離訊息傳輸所需帶寬增大,
使用的kafka-connect 和kafkaSink版本過低,
解決三個問題:
手動提交或使用事務操作,由于是海量資料,故選擇手動提交offset操作,避免資料重復提交,
在producer端添加lz4壓縮,為方便consumer端方便操作,直接將topic也進行了compressType的更改,
將kafka-connect和KafkaSink版本升級,使用最新版本的jar包進行資料推送,
在升級jar包的時候發生了一個報錯:
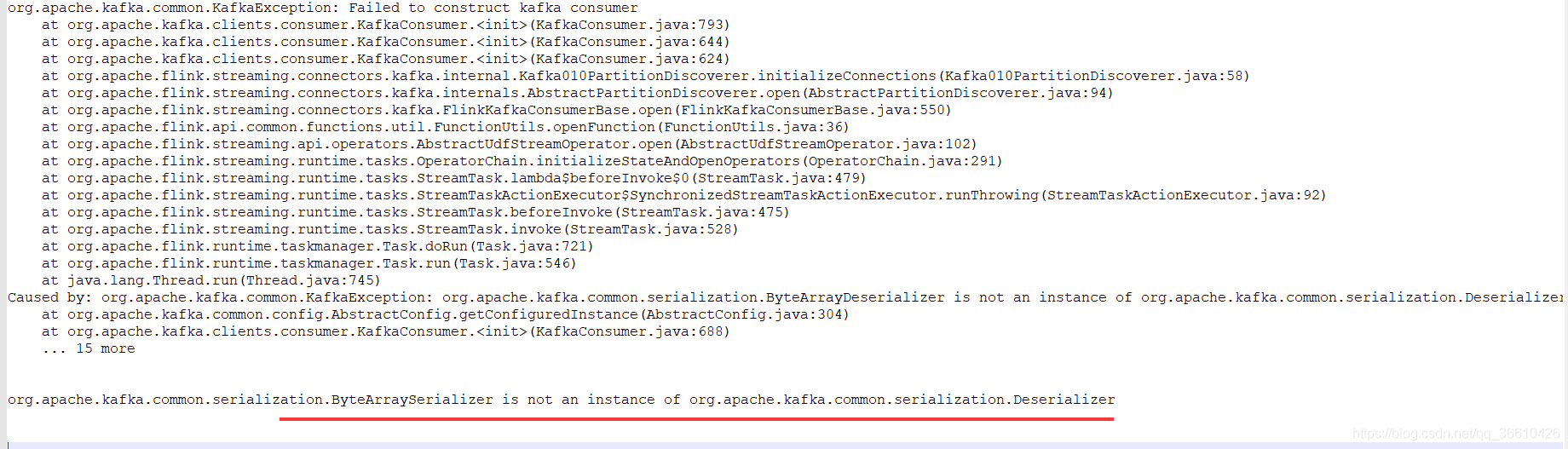
這個可能是將序列化和序列化決議弄反了,但是在Flink代碼中并沒有這個錯誤發生,最后發現是pom檔案引入該包時使用了complie,而Flink提交時指定的庫也有相同包,進行了更改報錯消失,所以也算是莫名其妙,
上述問題看著簡單,其實確實簡單,但在巨量資料面前,問題就頻頻爆發,
但就算進行了上述更改,在資料量超過300MB/s的時候,還是發現有如下報錯:
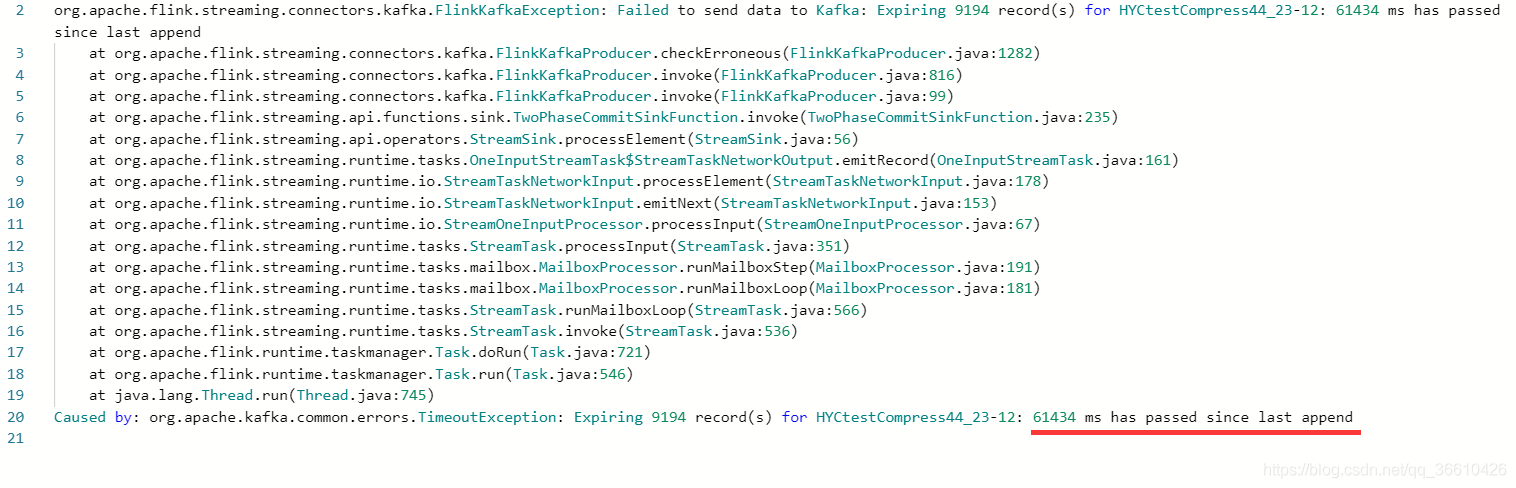
這個錯誤網上也有很多描述:
大多數都是說將request.timeout.ms 提高,batch-size 和liner-ms 調到比較合適的值, 但是其實這個原因的本質錯誤在org.apache.kafka.clients.producer.internals.ProducerBatch#maybeExpire中,(注意老版本不會區分以下三個報錯)
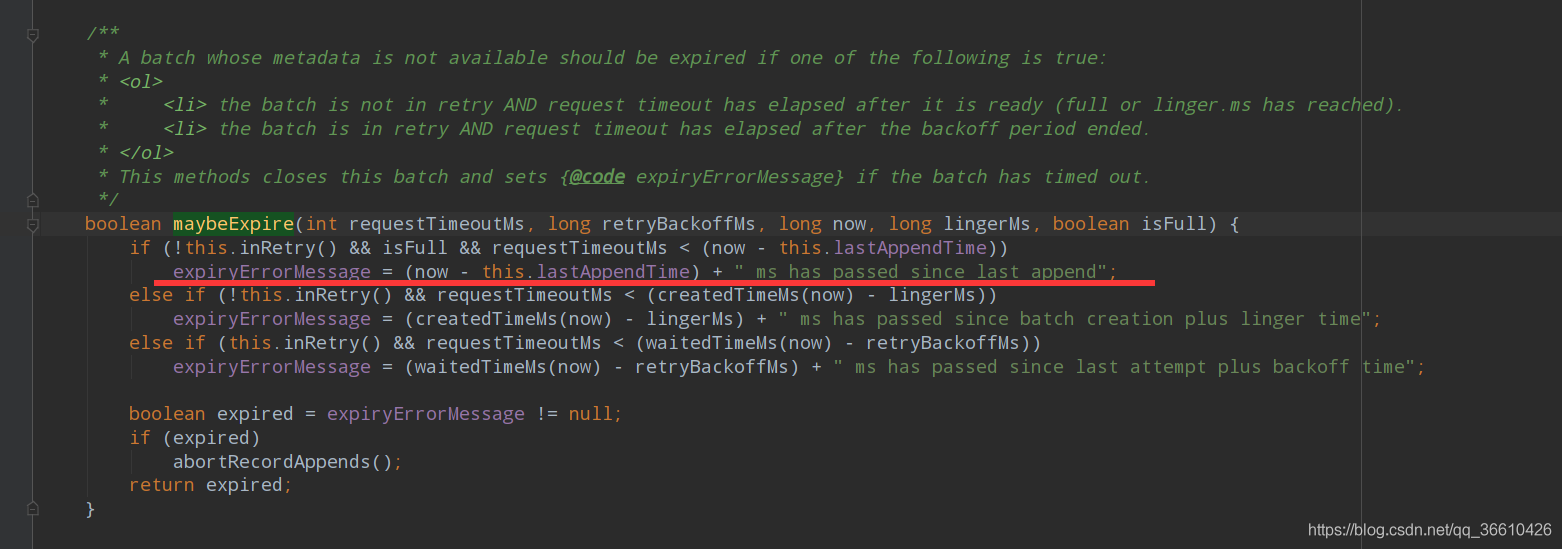
可以看到這個報錯時第一種型別,原理描述可以如下:
一個partition只會有隊頭的batch被發送,sender執行緒不會對發送中partition的其余batch檢查過期,指向同一個broker的多個partition的batch能夠合并成一個request發送,其中前兩點是由Accumulator里的muted變數來保證,注意是只有muted的partition才不會對其余batch檢查過期,在把batch組裝成request即將發送時才會把partition添加進muted,
如果在發送程序中網路抖動發送失敗,那么就會把retry的batch添加到deque的頭部等待下一次request組裝,但如果由于網路抖動時長requestTimeoutMs不能組裝成request,該retry的batch也會被sender執行緒檢查過期,并立即回傳callback,
所以這個超時就是我已經添加了資料到緩沖中,在緩沖中進行資料的發送,如果緩沖裝滿了,并且最后裝入的時間大于了requestTimeoutMs,那么就會報錯,
解決辦法除了剛剛上述兩個引數的調整,最重要的是不要用統一producer異步發送給多個partition,就能避免異步發送被任何后序barch超時例外擾亂的可能,所以改造方案最佳方案是 一個producer盡量只對一個partition進行資料的同時發送,
一個是異步發送能做到,一個是同步發送時的多執行緒發送各個partition能做到,所以單執行緒挨個partition的同步發送是不用擔心的,正常來說對一個topic進行異步發送或多執行緒同步發送是沒什么問題的,
同時經過kafka社區大神的認同,上面提到的request發送失敗進行retry,很大的原因就是同一個request發送了多個partition的batch,雖然指向同一broker的多個partition的batch可以合并以提高并發效率,但每個batch達到broker之后要被各自不同的follower復制,全部都完成之后才會一起回傳一個response,很明顯總耗時很容易拉長導致producer超時retry,
摘自: https://www.jianshu.com/p/e0fcc4c30b38
問題是有這個解決辦法,但其實后續我們發現就算更改后一樣會有類似的報錯出現,導致TaskManager重啟,所以開啟JVM的排查,
JVM排查
先在Flink頁面查看TaskManager 的運行時長,比如
就是重啟過的服務器*(后期進行的截圖),
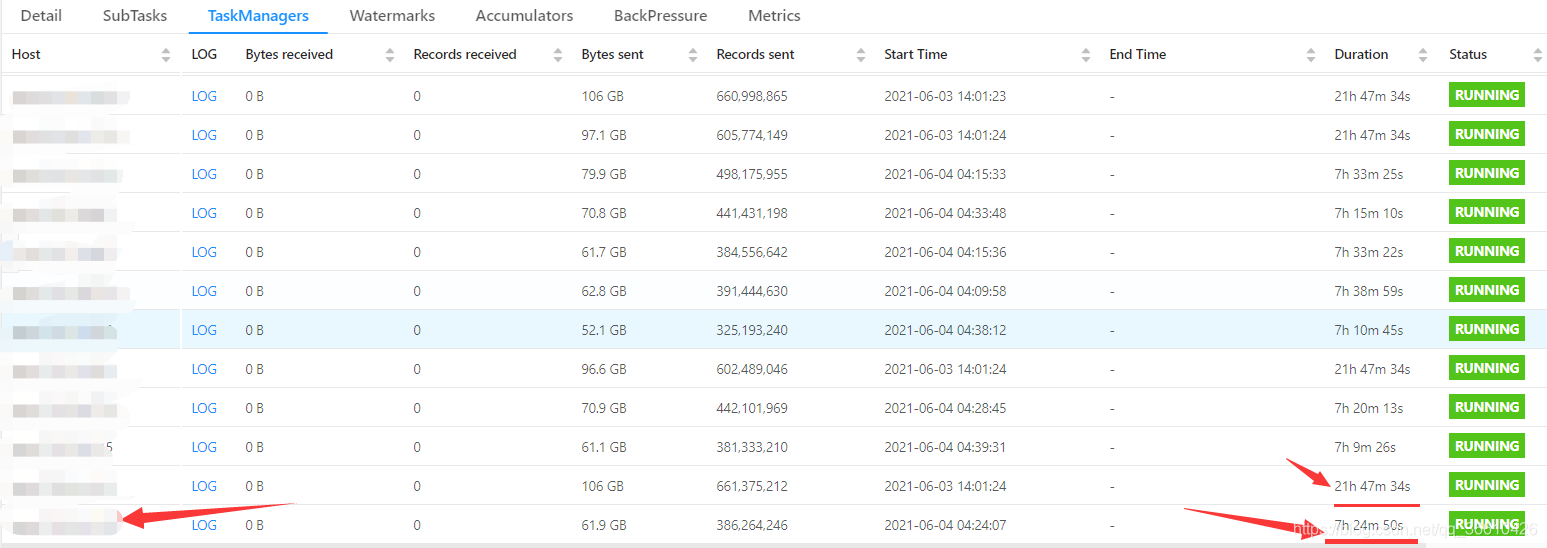
我們Flink沒有開啟webShell,就直接進服務器進行查看吧,
ps -ef |grep applicationId
篩選出taskManager的運行PID,
使用 jmap -J-d64 -heap 58071,演示效果如下:
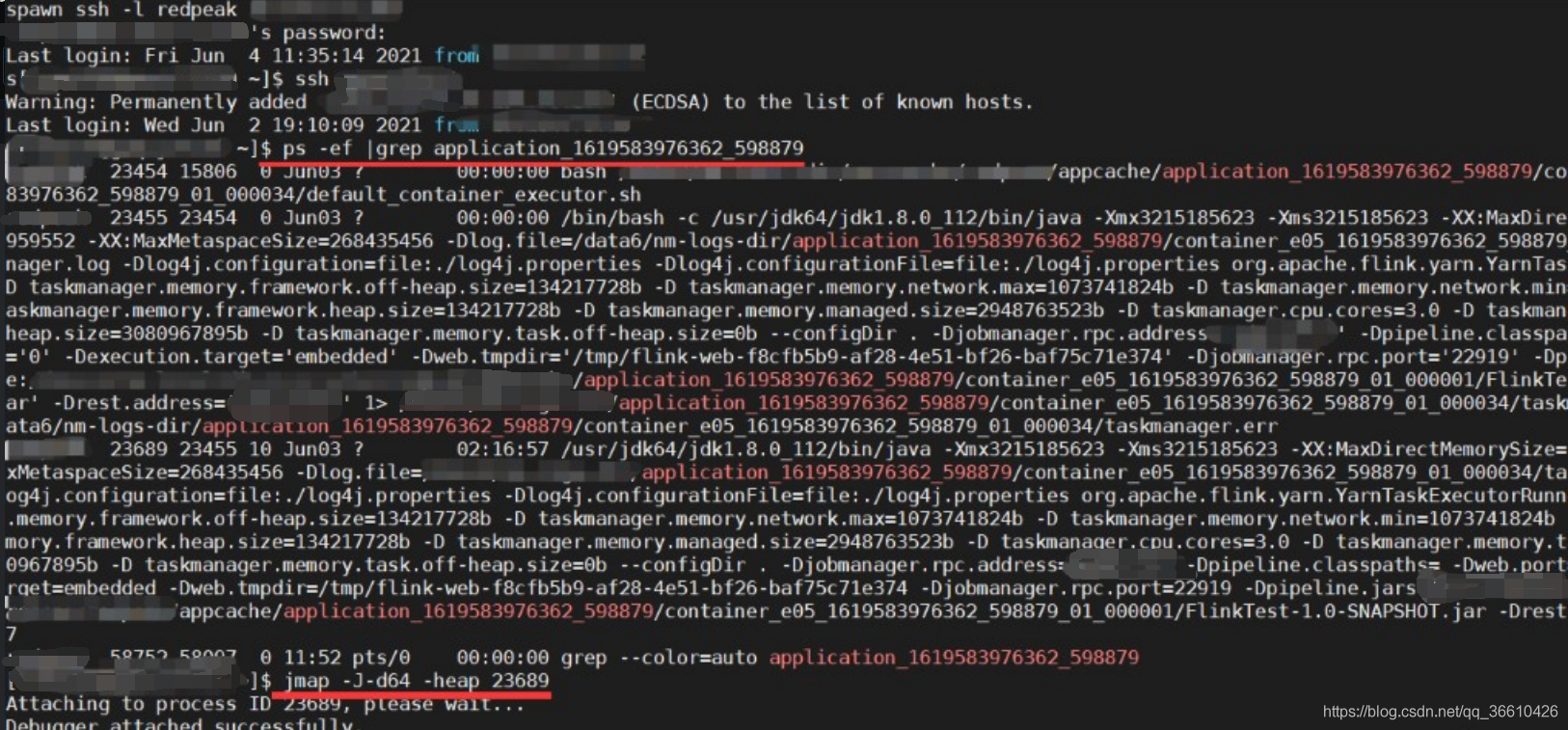
以上圖片為操作演示,以下圖片為真實截圖:
先查看heap堆的情況:jmap -J-d64 -heap 6956
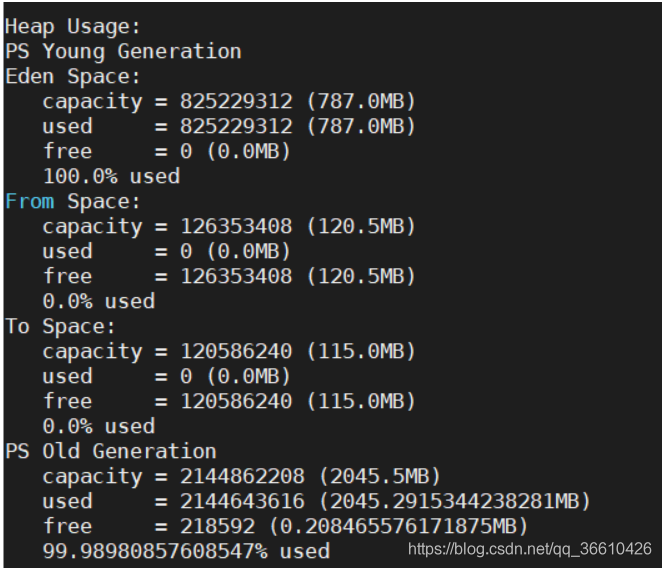
這里采用的是Java 1.8 默認GC ParallelGC收集器,新生代比例還是比較健康8:1:1,如果對GC不熟悉的童鞋,我建議重學JVM部分,推薦清單=>

老年代99.98%,那么就看看記憶體占用情況吧:jmap -histo:live 6956 |head -n 20
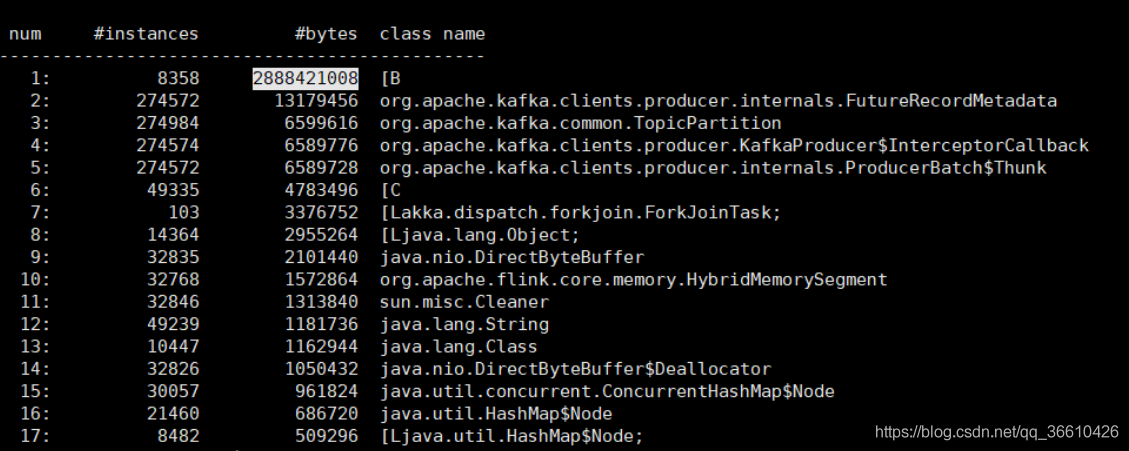
可以看到占空間最大的是byte[],簡單介紹下:
[C is a char[] [S is a short[] [I is a int[] [B is a byte[] [I is a int[]]
其實估摸著能猜出來是什么,因為 2、3、4、5名都是producer端關于資料發送的如下圖:
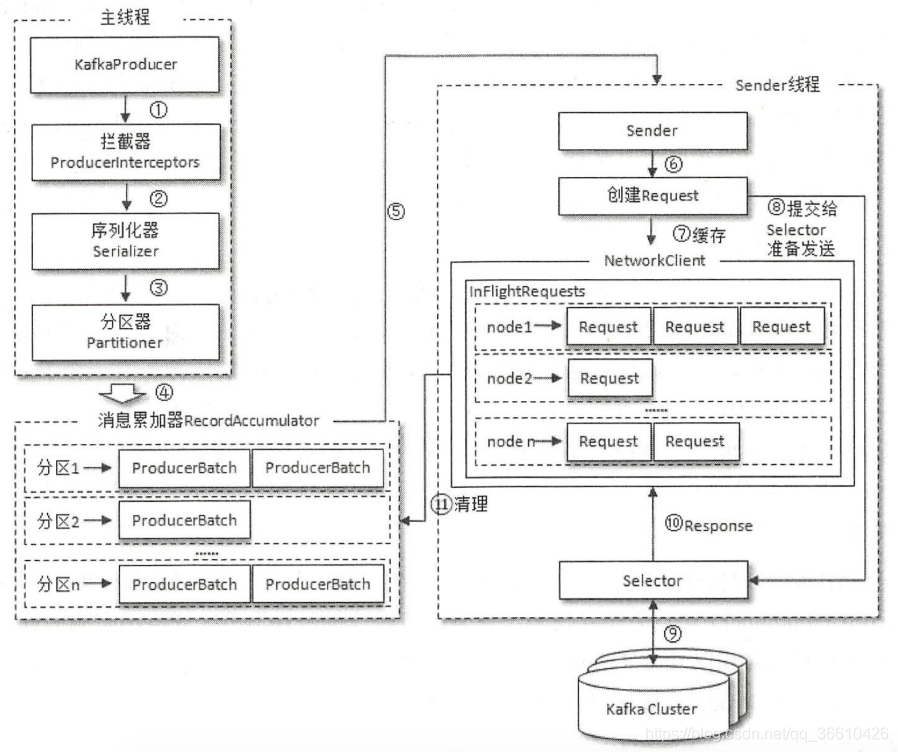
大概就是資料堆積無法發送,導致GC失敗,(但在TaskManager中的日志并沒看到GC相關報錯,很奇怪),觸發了OOM的:
java.lang.OutofMemoryError: GC overhead limit exceeded
查看下GC耗時:jstat -gcutil 6956 1s
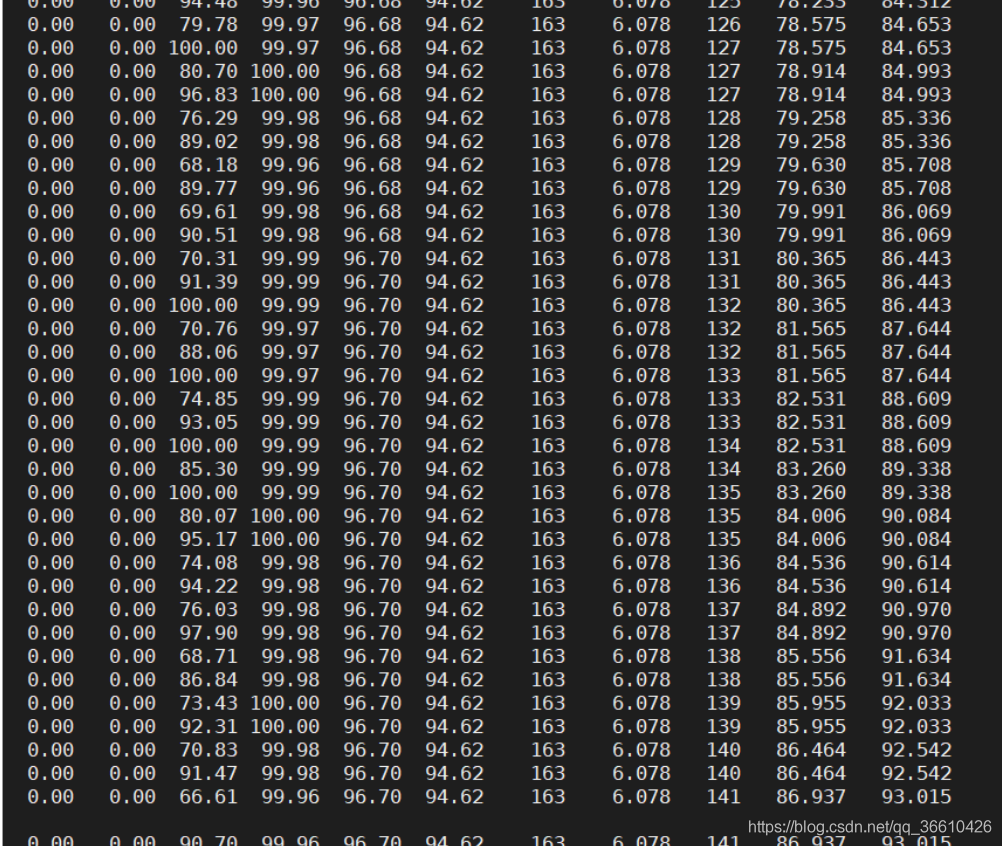
那么就dump JVM記憶體,看看到底裝了啥btye[],裝了這么多吧,4G的hprof檔案從服務器上下載下來:
jmap -dump:format=b,file=myHeap.hprof 6956
使用jvisualvm打開,查看
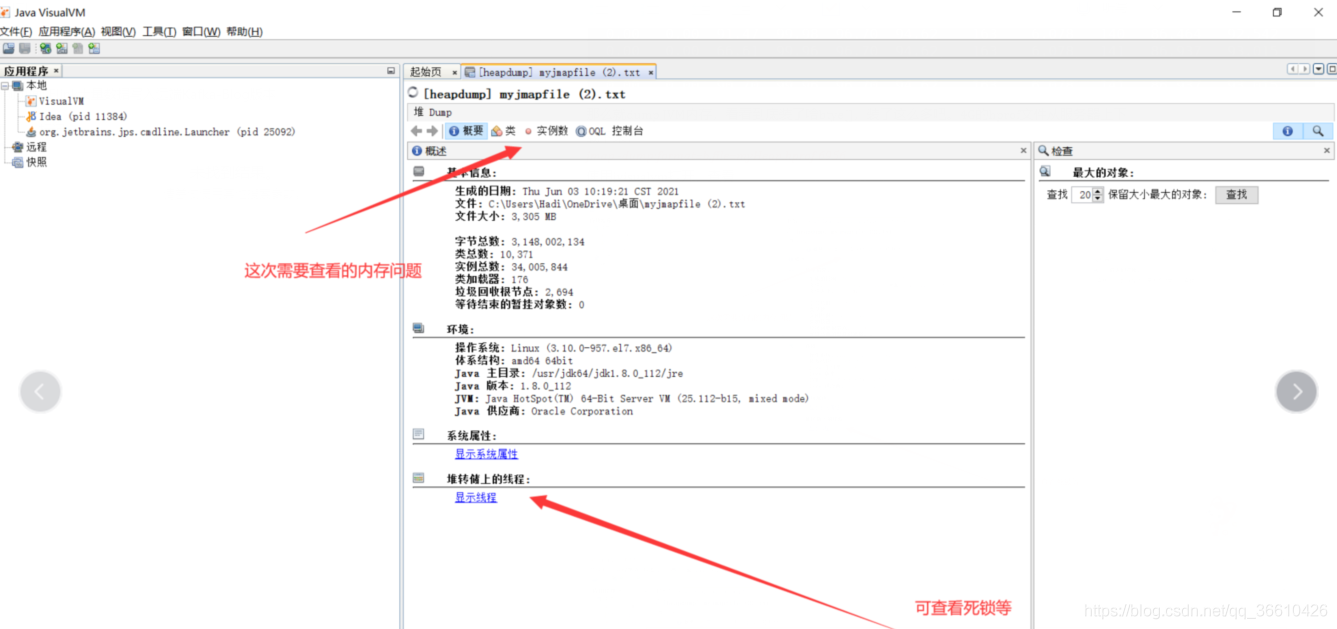
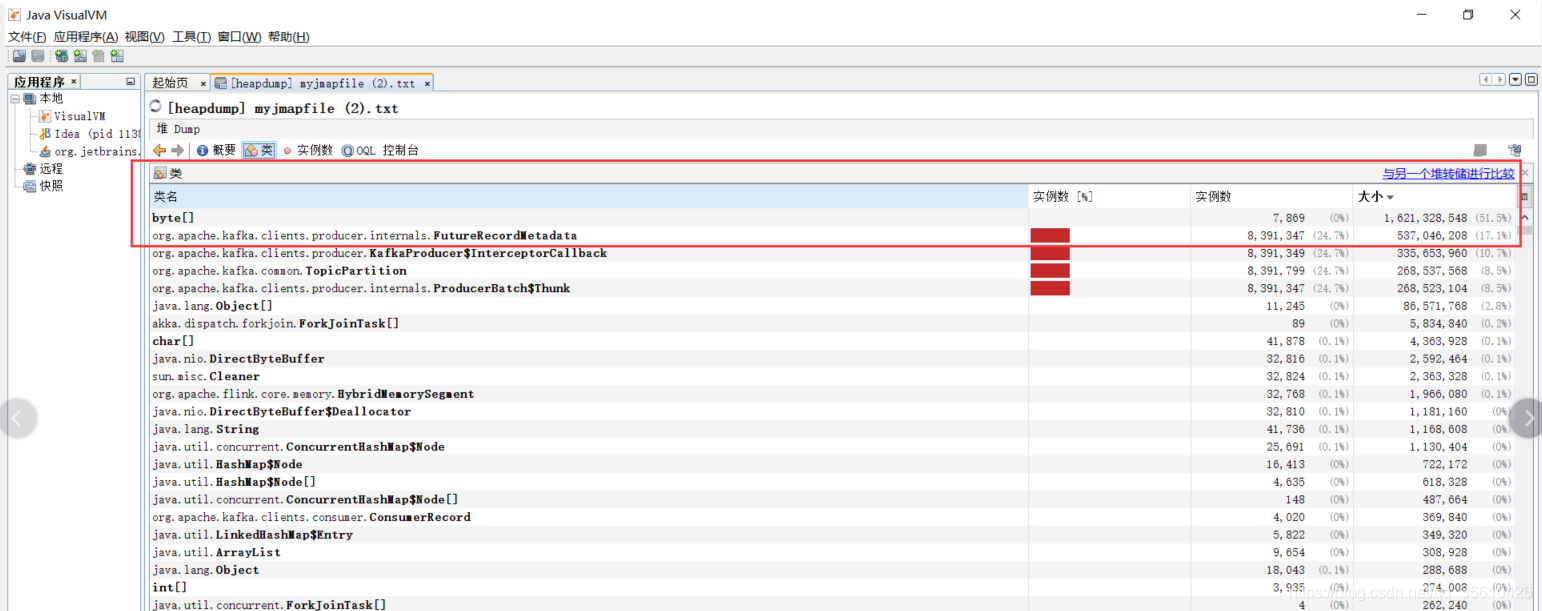
這里down出 byte陣列:
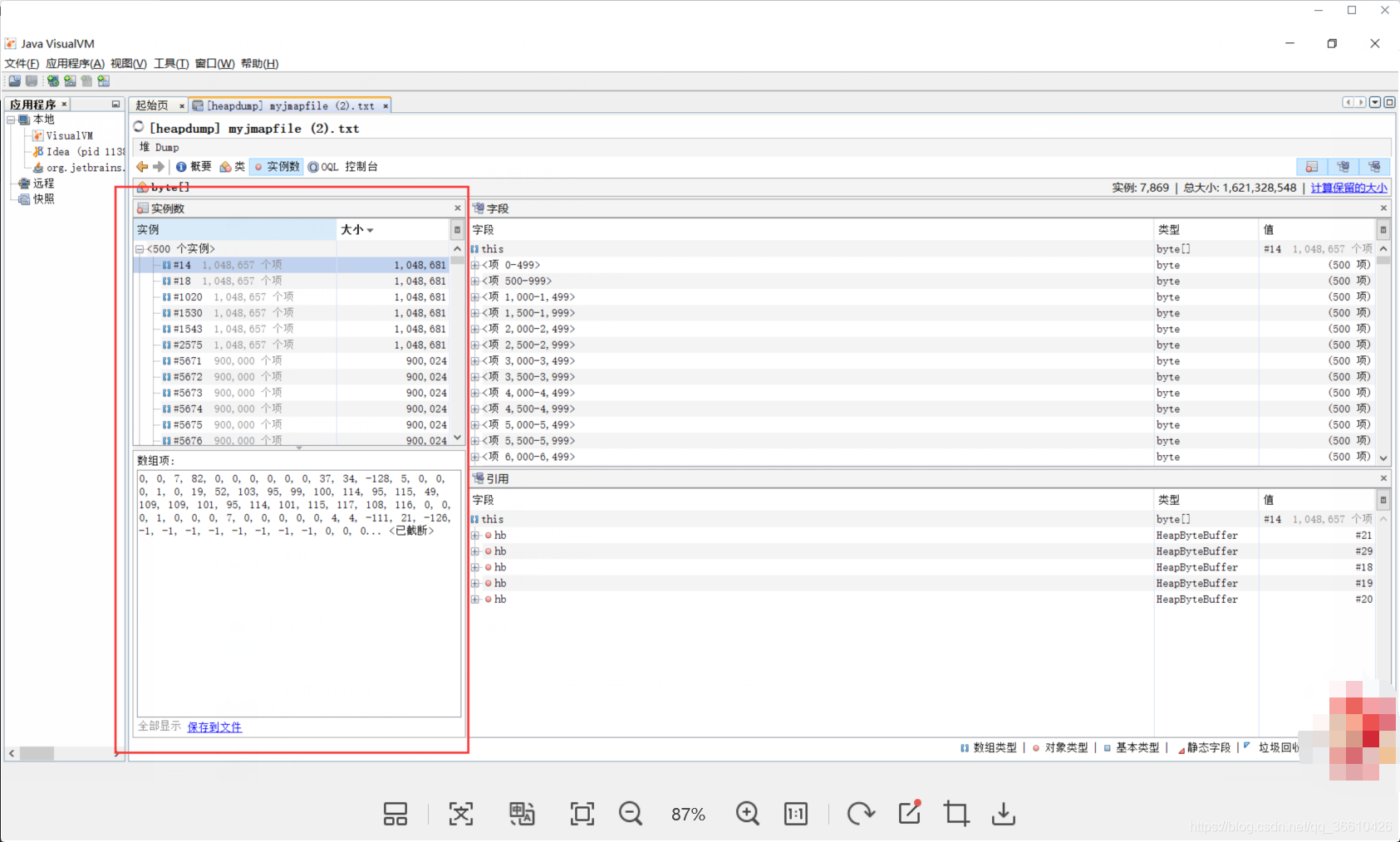
down出的檔案如下:
將byte進行檔案塑化后得出:
可以明確地看出來,這個就是從 source端取出的一條條資料,那么為什么這么多呢?因為緩沖區,
在上圖中 RecordAccumulator中存盤的ProducerBatch會存盤這么多資料等待發射,具體上面也講過了,怪不得這些資料無法被GC掉,因為是強參考,只有request成功后才會被清除掉,
所以將實時程式中對緩沖區相關的記憶體調小,整個GC問題就解決掉了,
優化后效果
消費速度:
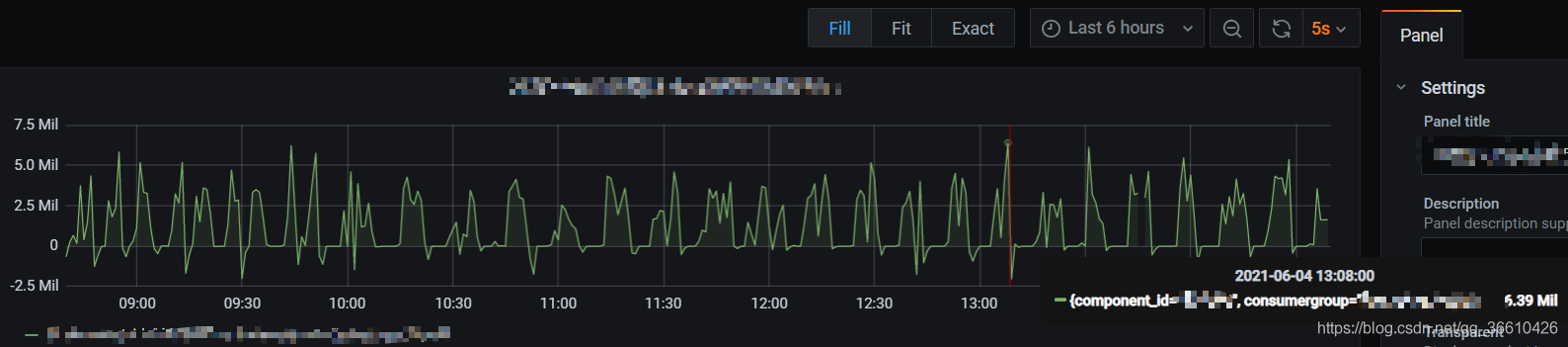
核心寫入速度:
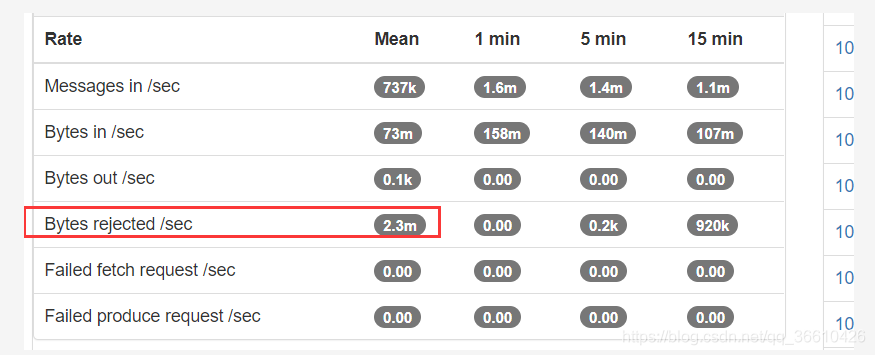
實測最高峰可達500mb/s (lz4壓縮后),5million/s 條,
后續
后續,測驗三天查看穩定性后進行所有預處理集群部署,意味著這次更新對下游會產生影響(之前都是無感更新操作),
后記
整個排查的程序,這里寫的挺粗糙的,原理都很簡單,基本上就是別犯錯,
但是很明顯在開發程序中留下的都是不停催促的痕跡:
- 搭建的kafka,基礎調參都沒有,
- 整體監控,沒有,對于我們這種超多集群環境的掌控,沒有確實的監控,或者可以說有監控沒人來看,或者說看了也都懶得處理,在這次排查程序中盡顯無疑,對某些人來說拖一拖就拖一拖;“我不會呀”也能打發我很久,某些操作人員根本不考慮后果和影響,直接蠻干,點完就完事的心態,比如A預處理集群Kafka遷移,雖然我們服務器總量大,但其實還是很吃緊,擴容能緩解但并不是最終最好的方案,
- 不懂真正引數意義,只能嘗試,這個可以理解為技術力欠缺,需要積累,不知道參與這次問題排查的人員記錄了多少,又學習了多少,
- 望各位看到此貼的朋友不要當惡人,
再次宣告
本blog只在CSDN發布,每個地方發布的版本不相同,有Hadi式加密手段(包含圖片或段落文字),請勿進行傳播擴散,僅供學習使用,
由于為公司專案,所以大多數內容進行了屏蔽或洗掉處理,記錄此只是希望大家繼續學習,如果發現任何ip、人物、服務器等資訊,請立即私信我進行更改,請勿走上違法犯罪道路!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286252.html
標籤:其他