文章目錄
- Prometheus + Grafana 監控效果圖
- 一、Prometheus 簡介
- Prometheus成長歷程
- Prometheus誕生背景
- 云時代的到來
- Prometheus 監控特點
- 二、Prometheus 架構模型
- Prometheus 核心組件
- 三、Prometheus 指標設計
- 指標設計規范的誕生
- 四、Prometheus 存盤模型
- LSM 結構模型
- LSM 模型—寫操作
- LSM 模型—讀操作
- LevelDb 結構模型
- LevelDb模型—寫操作
- LevelDb模型—讀操作
- Prometheus 存盤引擎
- 時間分片策略
- 時間分片策略優勢
- 磁盤檔案結構
- block
- meta.json
- chunks
- Cut切分策略
- Index
- 索引生效程序
- tombstones
- 資料壓縮「Data Compress」
- Chunk Compress
- 雙增量策略「delta-of-delta」
- XOR策略
- 五、Prometheus集群部署
- 單小集群解決方案
- 部署架構
- 多集群部署解決方案
- 聯邦策略
- Thanos 高可用解決方案
- 部署架構
- 大集群場景解決方案
- 分片策略
- Q&A
- 附錄
?? 普羅米修斯?古希臘泰坦之神?異形? 都不是,Prometheus是新一代企業級實時監控組件,大小廠牌都在用,監控屆扛把子的存在,
??掌握了這個——普羅米修斯,大小廠牌作業任你挑選,升職加薪如絲般順滑,
??下面給大家**全方位刨析一下 Prometheus **,
注:本文對初級同學相對存在門檻,可以收藏關注,在成長中積累….
Prometheus + Grafana 監控效果圖
??這里先放個 Prometheus + Grafana 集成效果圖,讓剛認識 Prometheus 監控系統的同學腦海中有個基本概念,
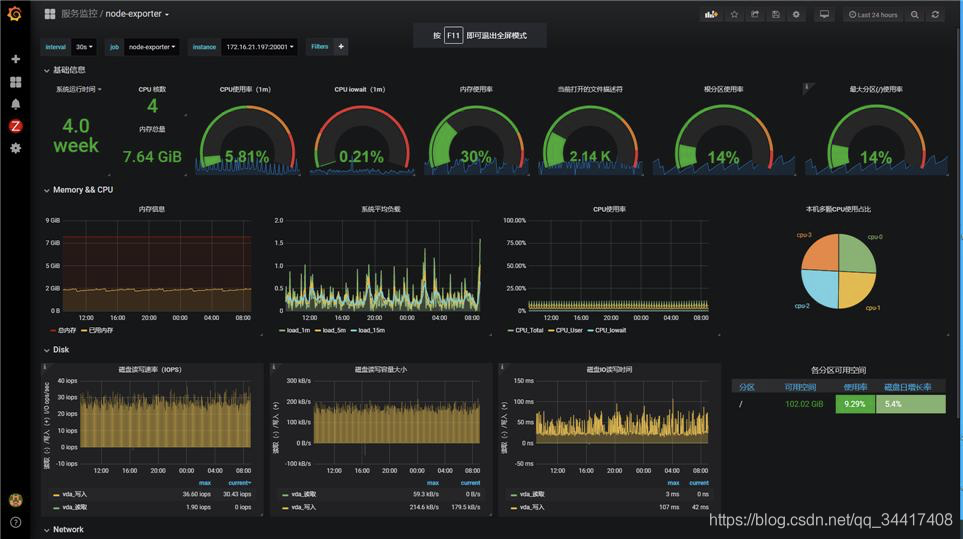
對,這樣式的就是企業級實時監控可視化面板,下面還有…
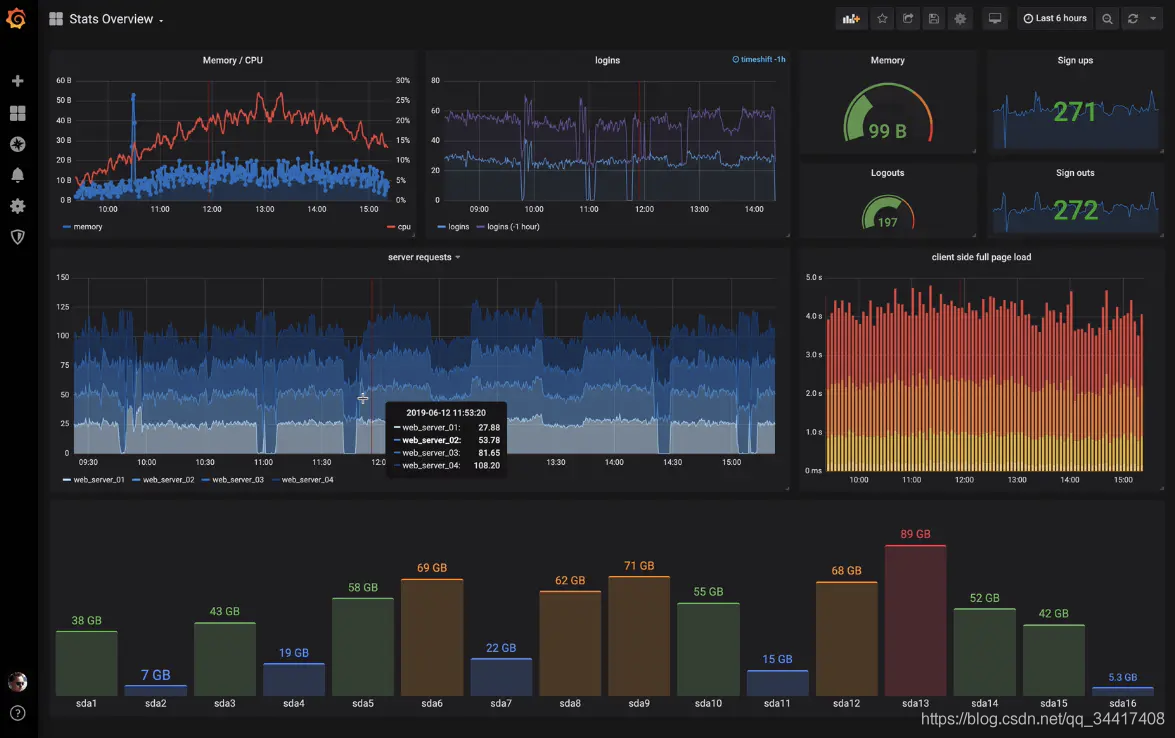
感覺怎么樣?看著還行吧,哈哈哈,下面進入正題,刨析一下 Prometheus …細品,品…
一、Prometheus 簡介
??Prometheus 作為新一代的開源實時監控系統,提供了 Kubernetes ,資料庫,訊息佇列,基礎架構等各類技術組件的監控能力,實時洞察在線服務各個指標動態變化,幫助快速資料分析及問題定位,
??在全面擁抱云原生時代中,為云原生架構提供安全保障,形成市場競爭中真正的敏捷力量!
Prometheus成長歷程
- 2012年
SoundCloud 啟動 Prometheus范訓專案, - 2015年
Prometheus在GitHub 完全開源后,STAR數直逼9K,同時被很多公司作為監控方案采用, - 2016年
Prometheus 加入 CNCF(Cloud Native Computing Foundation),繼 Kubernetes 加入后的第二個專案成員, - 2017年
Prometheus 2.0 發布,這是Prometheus的一個重要的里程碑,在集成TSDB后的Prometheus 2.0,與Prometheus 1.8相比,CPU使用率降低到20%-40%,磁盤I/O、磁盤空間使用率降低到33%-50%,查詢負載通常平均<1%, 可以支持單機每秒1000w個指標的收集, - 2020年
現在 Prometheus STAR數已超40K,已經是云原生架構中不可分割的重要一部分……
Prometheus誕生背景
Prometheus 順應云時代浪潮滾滾而來,推動技術架構走向敏捷,面向未來…
云時代的到來
軟體正在吞噬世界, ???????? ——Mark Andreessen
??正如 Mark 所說“軟體正在吞噬這個世界“,21世紀軟體服務已經滲透到了世界的各個角落,云服務也是其中的一個,悄無聲息地蔓延開來….
??隨著云基礎設施「包含公有云、私有云、混合云」的蓬勃發展,應用服務上云的浪潮來勢洶洶……
??基于云原生的架構,云可以提供彈性、自主的提供和釋放計算、網路、存盤等資源;同時服務的部署更加安全、迅速,軟體交付、持續服務、用戶體驗能力無限提升;使公司在市場競爭中擁有最敏捷的力量優勢,
??服務上云已經勢不可擋! 上云,伴隨而來的是需要大量新的技術組件提供云特性支持,而 Prometheus 就是其中一員,
??Prometheus 擁抱云原生,作為 CNCF 第二大專案,對云基礎設施提供全面的兼容服務,實時動態監測服務節點及容器各項指標,是云原生架構中安全及業務性能強有力的保障,是其不可或缺的一部分,
Prometheus 監控特點
??Prometheus 順應云原生而誕生,對云原生提倡的 容器化、容器編排、服務代理、發現和治理…等方案都做了兼容,這也是其最突出的特色,
- 1、具有 Metrics 名稱和 key/value 對標識的時間序列資料的多維資料模型
- 2、利用資料模型進行有效的警報和圖形展示的查詢語言
- 3、支持本地存盤,不依賴分布式存盤檔案系統
- 4、通過 HTTP WEB 互動方式獲取時間序列資料
- 5、可配置推送的方式進行時間序列資料采集
- 6、支持 Client 通過服務發現和靜態配置發現
- 7、兼容多種視圖模式
- 8、Docker、Kubernetes 原生支持
- 9、…
??那么,是什么樣的設計滿足這些特色能力呢?好奇感十足,下面拋出具體的架構圖,來分析分析,它咋那么牛!!!
二、Prometheus 架構模型
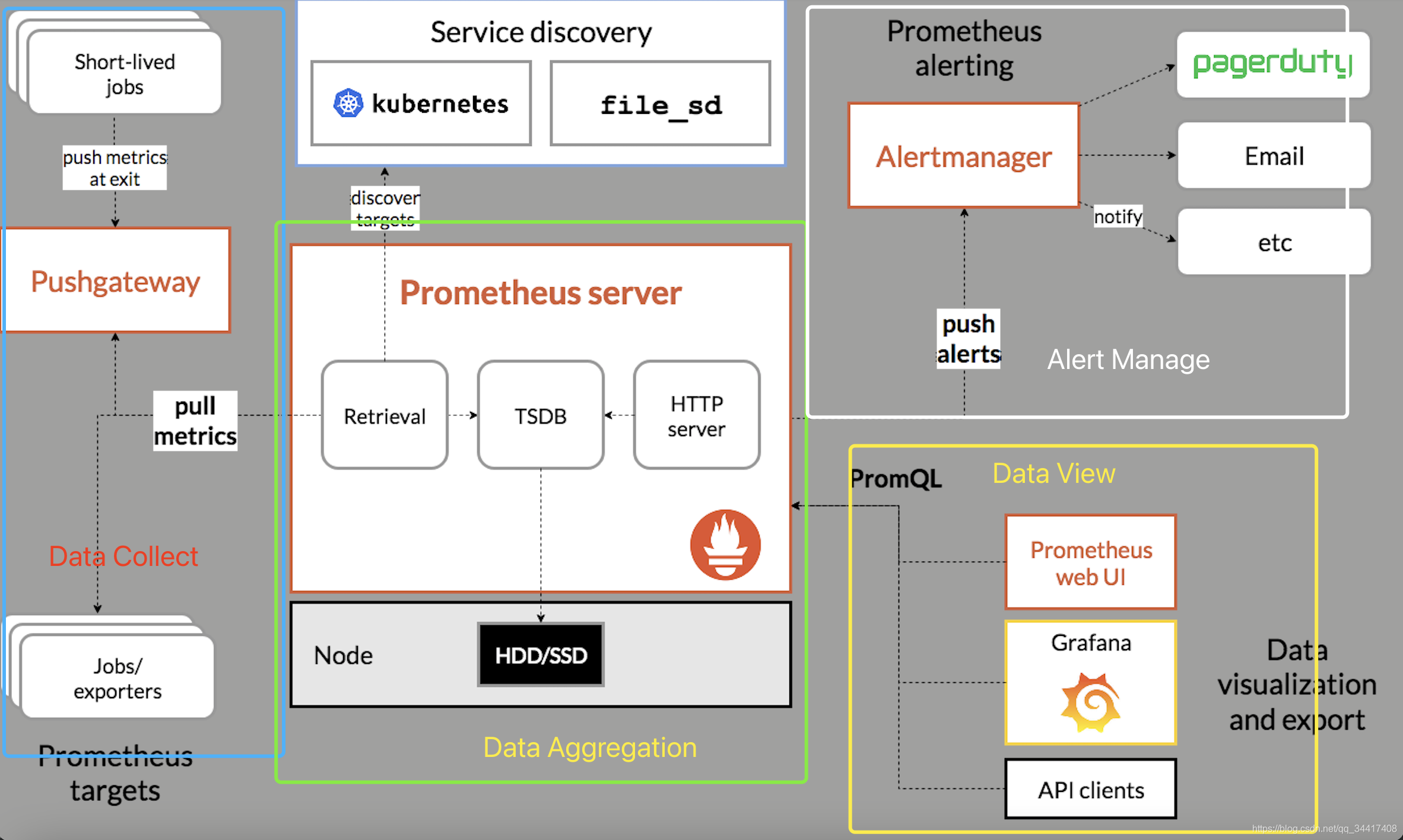
??Prometheus 組件可分為資料采集、資料聚合、資料展示、告警四部分,
- 資料采集可采用 “侵入式” 或 “ Explore 格式轉換「非侵入式」” 的方式收集,按照配置的刮擦粒度以 “ API ” 的形式與資料聚合模塊互動
- 資料分析將采集到的指標資料進行存盤,本地存盤使用類 LeveDB 結構模型
- 資料展示通過使用 PromQL 過濾資料,渲染可視化面板、視圖
- 資料告警把符合配置閾值條件的資料推送給用戶,進行告警調度
Prometheus 核心組件
??Prometheus 擁有四大核心組件,分別為 Prometheus Server、Pushgateway、Alertmanager、Exporter 完成主要監控任務,
- Prometheus Server:用于刮擦目標 Job Metric、存盤本地TSDB資料
- Pushgateway:推送網關,以 Push 模式將本地 Metrics 資料推送到PushGateway
- Alertmanager:警報組件,配置分組、警報發送源
- Exporter:暴露本地 Metrics 給 Prometheus ,讓Prometheus 通過 Pull 模式刮擦目標Job指標資料
這里講了架構和核心組件,大概曉得了基本配置,可具體用的時候呢?起步姿勢是啥呢?來來來,下面來聊下,先從監控資料設計入手…
三、Prometheus 指標設計
??Prometheus 指標由兩部分組成,可簡單概括為
K『 k「metricName」+ v「key/val」+ T「 timestamp 」』—— V『sample』
- K:— k「metricName」-v「key/val」+T「 timestamp 」
- V:— sample

??內層k/v對代表了資料維度,每個 metricName 標識了監控指標的唯一身份,T為時間戳,Sample 則是當前指標的數值,
??外層Key包含 Metric Name、Labels、Timestamp;Value 包含 Sample ,
指標設計規范的誕生
??為什么這樣式約束監控指標呢/?令人深思的問題!Why?
??仔細品品之后,發現!!!
在實時監控系統中,需要實時監聽個目標Job的各項資料,統計實時資料及勾勒時間為軸的各類可視化面板,
- 從資料屬性來看,自帶時間屬性,天然時序資料,
- 從資料讀寫來看,是垂直寫,水平讀的場景,讀寫比例占比很大,

??綜合上述,選擇了K-V資料模型有了充分的理由,沒毛病!!
資料已經有了,那么怎么進行資料聚合存盤呢?不慌,下面就刨析存盤模型!!
四、Prometheus 存盤模型
資料模型建立在存盤模型之上,??——《 Data Structure Design 》
??首先在基于云服務的實時監控場景中,存盤模型它需要滿足這幾個條件:
在自動彈性伸縮的云原生環境中, 實體的產生和消亡更加頻繁,即系統中將會存在大量時序資料指標,但其中只有部分處于活躍狀態,這會在很多方面帶來挑戰:
- 1、有限的本地存盤,如何存盤大量時序避免資源浪費?
- 2、海量資料中,如何定位被查詢的少數幾個時序?
??圍繞這幾個條件,Prometheus 本地存盤存盤模型選擇了,基于 LSM 結構的類 LevelDB 組件,但是,為什么呢?下面來說道說道!!!
LSM 結構模型
??LSM 思想模型中將資料讀寫進行分層,提升讀寫性能,主要針對的場景是寫密集、少量查詢的場景,
??主要在 key-value 存盤系統中應用,如 LevelDB,RocksDB,還有分布式行式存盤資料庫 Cassandra 也用了基于 LSM-tree 的存盤模型,
??在實際生產環境中,日常的日志存盤,一般都是先把日志在記憶體快取,批量以追加的形式寫入磁盤,
??LSM ,顧名思義,Log Structured「日志結構」、Merge「合并」是像寫日志一樣的思想模型,資料模型如下:
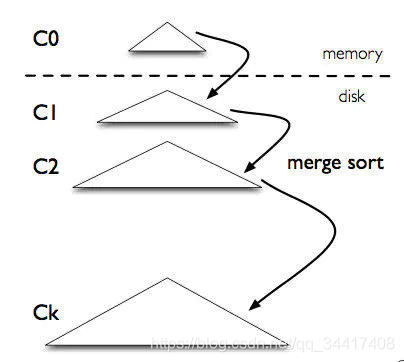
??LSM 模型是一個多層結構,就像一個樹一樣,上小下大,
??首先是記憶體的 C0 層,保存了所有最近寫入的 (k,v),這個記憶體結構是有序的,并且可以隨時原地更新,同時支持隨時查詢,剩下的 C1 到 Ck 層都在磁盤上,每一層都是一個在 key 上有序的結構,
LSM 模型—寫操作
1、首先寫入資料到 memory 中 C0 層,
當 C0 層的資料達到一定大小,就把 C0 層 和 C1 層合并,類似歸并排序,這個程序就是 Compaction(合并),
2、合并出來的新的 new-C1 會順序寫磁盤,替換掉原來的 old-C1,當 C1 層達到一定大小,會繼續和下層合并,合并之后所有舊檔案都可以刪掉,留下新的,
- 「注意資料的寫入可能重復,新版本需要覆寫老版本,什么叫新版本,我先寫(a=1),再寫(a=233),233 就是新版本了,假如 a 老版本已經到 Ck 層了,這時候 C0 層來了個新版本,這個時候不會去管底下的檔案有沒有老版本,老版本的清理是在合并的時候做的,」
- 「寫入程序基本只用到了記憶體結構,Compaction 可以后臺異步完成,不阻塞寫入,」
LSM 模型—讀操作
最新的資料在 C0 層,最老的資料在 Ck 層,所以查詢也是先查 C0 層,如果沒有要查的 k,再查 C1,逐層查,
LSM 盤的差不多了,不過 Prometheus 只是借鑒了模型,離實際實作還有一步——看看 LevelDB…
LevelDb 結構模型
??Prometheus 本地是基于 LevelDb 完成監控指標的存盤,LevelDb 是一款基于K-V的時序資料庫,
??其設計基于 LSM ,但又不同于 LSM ,在讀寫性能上繼承 LSM 優異的水平,在結構上更加嚴謹,更具實操意義,
??LeveDb 結構圖大體類似 LSM ,有細節不同:
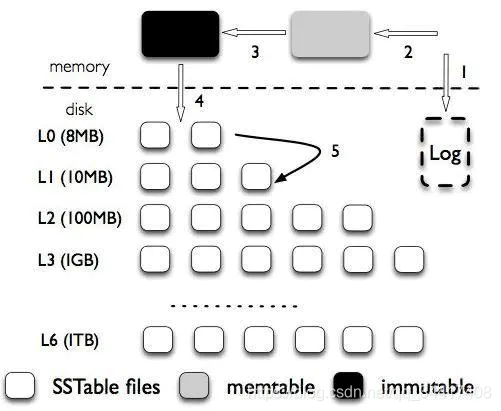
??LSM-tree 被分成三種檔案,第一種是記憶體中的兩個 memtable,一個是正常的接收寫入請求的 memtable ,一個是不可修改的 immutable memtable ,另外一部分是磁盤上的 SStable (Sorted String Table),有序字串表,這個有序的字串就是資料的 key ,SStable 一共有七層(L0 到 L6),下一層的總大小限制是上一層的 10 倍,
加入了WAL機制,提高生產環境中的容災能力;
在資料層級中,做了層級限制,以提升有限資源利用率;
……
LevelDb模型—寫操作
1、首先將寫入操作寫 WAL 日志中,接下來把資料寫到 memtable中,當 memtable 滿了,就將這個 memtable 切換為不可更改的 immutable memtable,并新開一個 memtable 接收新的寫入請求,而這個 immutable memtable 就可以刷磁盤了,這里刷磁盤是直接刷成 L0 層的 SSTable 檔案,并不直接跟 L0 層的檔案合并,
2、每一層的所有檔案總大小是有限制的,每下一層大十倍,一旦某一層的總大小超過閾值了,就選擇一個檔案和下一層的檔案合并,
- 「資料重復場景:L0 層的多個檔案在同一層,有先后關系的,后面的同個 key 的資料也會覆寫前面的,會為每個 key-value 加個版本號,在 Compaction 時候應該只會留下最新的版本」
LevelDb模型—讀操作
先查 memtable,再查 immutable memtable ,然后查 L0 層的所有檔案,最后一層一層往下查,
LevelDb 存盤模型就是這樣,大的框架流程,我們已經了解了,下面結合業務資料走進Prometheus 存盤引擎吧!!!
Prometheus 存盤引擎
??Prometheus 存盤引擎基于 LevelDb,結合自身業務特點,設計實作自身的存盤引擎,
時間分片策略
??Prometheus 存盤引擎將所有時序資料按時間分片,在時間維度上將資料劃分成互不重疊的 blocks,如圖:
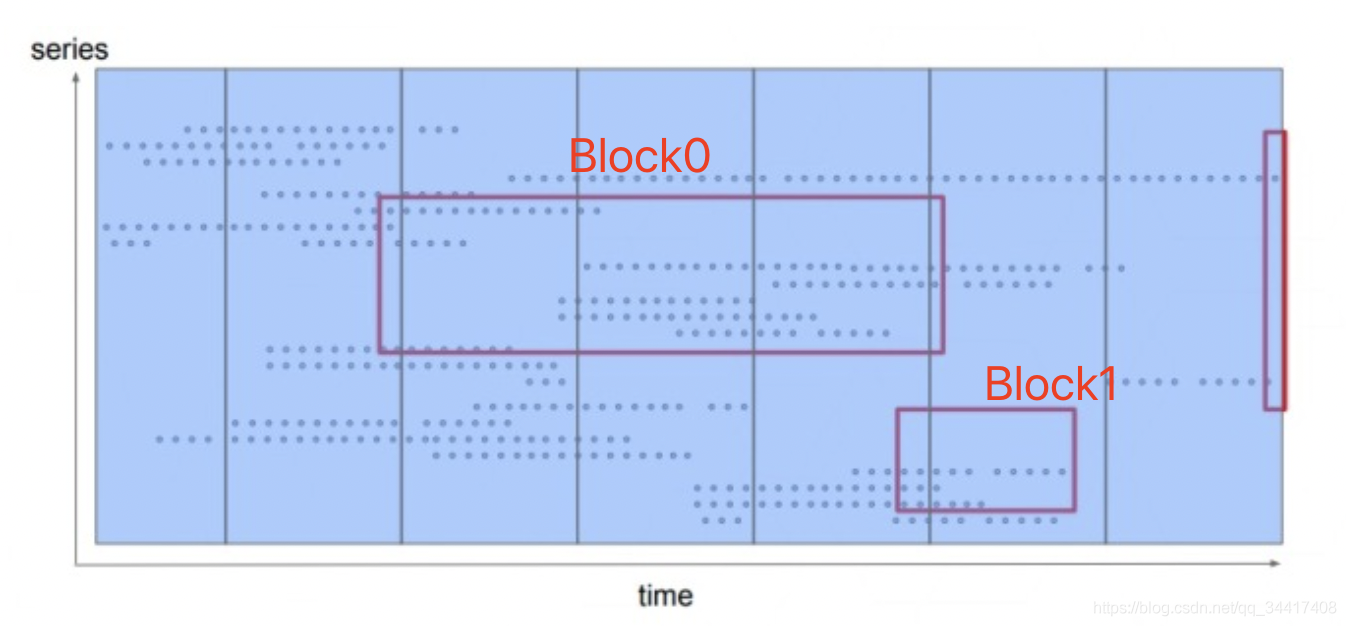
??那么為什么要以時間分片這種形式存盤呢?一個監控指標一個檔案是不是也可以?
時間分片策略優勢
??以時間分片這種形式是經過 Prometheus1.0、2.0、3.0版本之后,最終確定的版本,也是最優的、最適合這種場景的方式,它具有以下幾個優勢:
1、當查詢某個時間范圍內的資料,通過時序直接定位至目標 blocks,加快查詢速度
2、寫完一個 block 后,我們可以將輕易地其持久化到磁盤中,只涉及到少量幾個檔案的寫入,減輕磁盤IO壓力
3、新的資料,也是最常被查詢的資料會處在記憶體中,提高查詢效率
4、每個 chunk 大小不固定,我們可以選擇任意合適的大小,選擇合適的壓縮方式,提升資源利用率
5、洗掉超過留存時間的資料變得例外簡單,直接洗掉整個檔案夾即可
磁盤檔案結構
??引擎存盤在磁盤中的檔案結構如下圖:
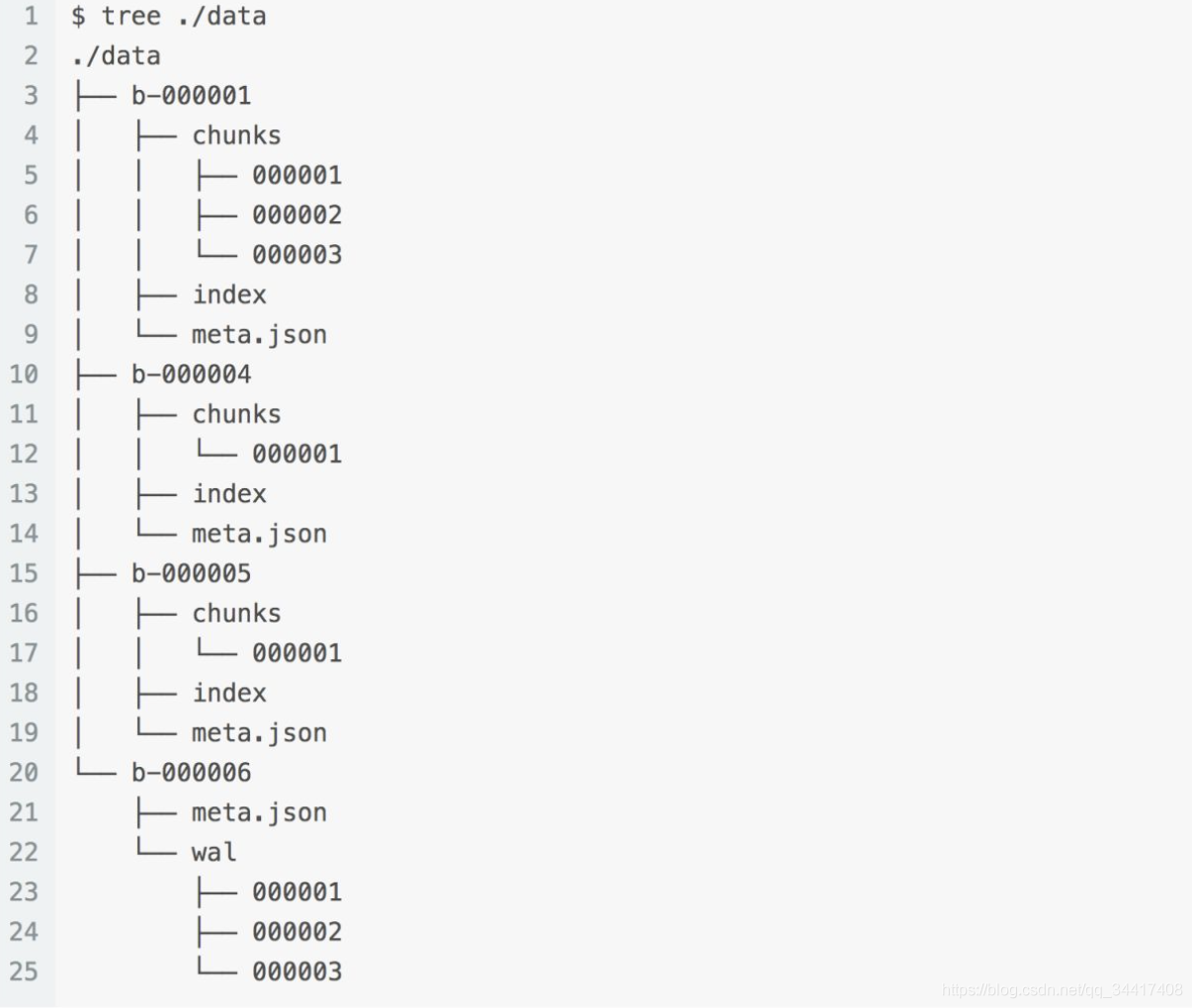 ??為了防止資料丟失,所有新采集的資料都會被寫入到 WAL 日志中,在系統恢復時能快速地將其中的資料恢復到記憶體中,
??為了防止資料丟失,所有新采集的資料都會被寫入到 WAL 日志中,在系統恢復時能快速地將其中的資料恢復到記憶體中,
block
??每個 block 內部存盤著該時間視窗內的所有時序資料,它同時擁有自己的 index 和 chunks ,除了最新的、正在接收新鮮資料的 block 之外,其它 blocks 都是不可變的,
??block 結構形式如下圖:
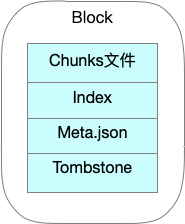
??block 的實質就是將一段時間里的記憶體資料組織成檔案形式保存下來,
meta.json
??meta.json 存盤當前 block 的一些元資訊,
{
"ulid":"01EPVA7WJ5DXTV6FR06VJ0CT40",
"minTime":1605081600,
"maxTime":1605085200,
"stats":{
"numSamples":1359295562,
"numSeries":441979,
"numChunks":11207472
},
"compaction":{
"level":1,
"sources":[
"01EPVA7WJ5DXTV6FR06VJ0CT40"
]
},
"version":2,
"numChunkFile":3
}
從中我們可以看出:
??該 Block 是由1個含有3個 chunk 的原始 Block 「01EPVA7WJ5DXTV6FR06VJ0CT40壓縮生成」;
??時序資料指標的范圍是<1605081600,1605085200>;
??總共擁有samples個數為:1359295562;
??資料指標個數:441979;
??chunks個數:11207472;
??…
chunks
?? chunk 結構圖如下:

??series ref 是用于訪問記憶體中資料列的 ID , mint 和 maxt 是在 chunk sample 中看到的最小和最大時間戳,encoding 是用于壓縮塊的編碼, len 是此后的位元組數,data 是壓縮塊的實際位元組數,CRC32 是上述chunk內容的校驗和,用于檢查資料的完整性,
Cut切分策略
??當寫入磁盤單個檔案超過512M的時候,就會自動切分一個新的檔案,
Index
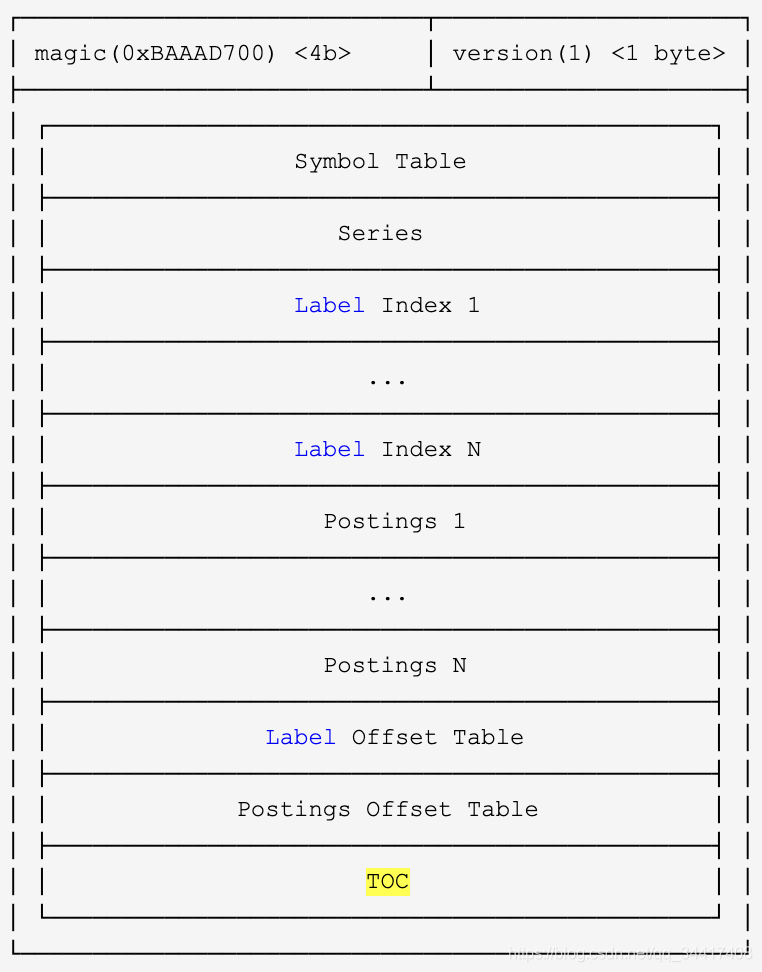
??這個檔案就是 Prometheus 最復雜的索引結構,索引就是為了讓我們快速的找到想要的內容,為了便于理解,就通過一次資料的尋址來探究一下Prometheus的磁盤索引結構,
索引生效程序
??假設我們要檢索擁有系列三個標簽的所有序列資料,
({__name__:http_request}{api:api-server})且時間為 start\end
1、根據檢索時間范圍定位 block 位置
從選擇 block開始,遍歷所有 block的 meta.json ,找到具體的 block ,
2、Label 過濾
找到目標 block 之后,需要通過 label 過濾檢索,那么問題來了!
- 前文說了,通過 Labels 找資料是通過倒排索引,我們的倒排索引是保存在 index 檔案里面的,那么怎么在這個單一檔案里找到倒排索引的位置呢?這就引入了 TOC(Table Of Content) ,
?? - TOC結構,如下圖:
?? - 首先我們訪問的是 Posting offset table ,如下所示:
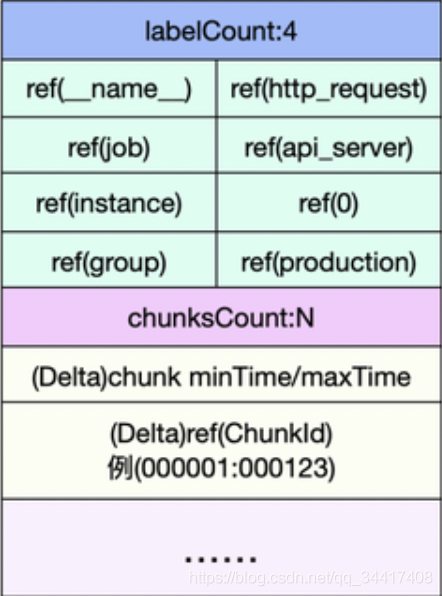
?? - 由于倒排索引按照不同的 LabelPair(key/value) 會有非常多的條目,所以 Posing offset table 就是決定到底訪問哪一條 Posting 索引,offset 就是指的這一 Posting 條目在檔案中的偏移,Postings 如下所示:
?? - 假設我們通過三條 Postings 倒排索引索引取交集得出
{series1,Series2,Series3}∩{series1,Series2}∩{Series1}={Series1} 中的資料,而 Posting 中的 Ref(Series1) 即為這 Series 在 index 檔案中的偏移,Series結構如下所示:
?? - Series 以 Delta 的形式記錄了 chunkId 以及該 chunk 包含的時間范圍,這樣就可以很容易過濾出我們需要的 chunk ,然后再按照 chunk 檔案的訪問,即可找到最終的原始資料,


tombstones
?? 由于 Prometheus block 的資料一般在寫完后就不會變動,如果要洗掉部分資料,就只能記錄一下洗掉資料的范圍,由下一次 compactor 組成新 block 的時候洗掉,而記錄這些資訊的檔案即是 tomstones,
Prometheus核心的索引結構及生效程序聊完了,除了索引結構,其提供的資料超級壓縮策略也是其在海量資料中,依舊堅挺的原因之一,下面來聊聊壓縮策略…
資料壓縮「Data Compress」
?? 假設我們以平均每秒采集 20w+ 個資料指標寫入資料,chunk 平均1KB,block 平均4KB ,每秒對磁盤的 IO 壓力還是挺大…
?? 假如我們需要查詢一周的資料,那么這個查詢將涉及到 80 多個 blocks ,資料也需要進行大量的磁盤 IO 到記憶體中聚合最終結果……
?? 為了減輕磁盤 IO 壓力,就需要充分利用記憶體,而記憶體的資源十分寶貴,為了達到在有限都記憶體資源中存盤更多的資料指標的目標, Prometheus 提出了資料壓縮「Data Compress」,
Chunk Compress
?? 目前, prometheus.v3 具備將每個指標壓縮至 1.28 bytes/sample 的壓縮能力,
?? 假設指標只含有 float64 型別的 Sample\TimeStamp ,不做壓縮已經占用16byte ,加上變長的指標維度變數、名稱后壓縮至 1.28bytes ,可以說壓縮比是 8% ,非常驚人,那么下面聊聊這樣的壓縮比下,隱藏了哪些不為人知的壓縮策略…
雙增量策略「delta-of-delta」
?? 由于監控業務特性,使 timestamp、value/sample 天生具有連貫性、遞增性,且連續 sample 相差幅度極小,故在統計存盤時,無須完整記一值,只需記錄其相對增量就可以達到壓縮的目的,
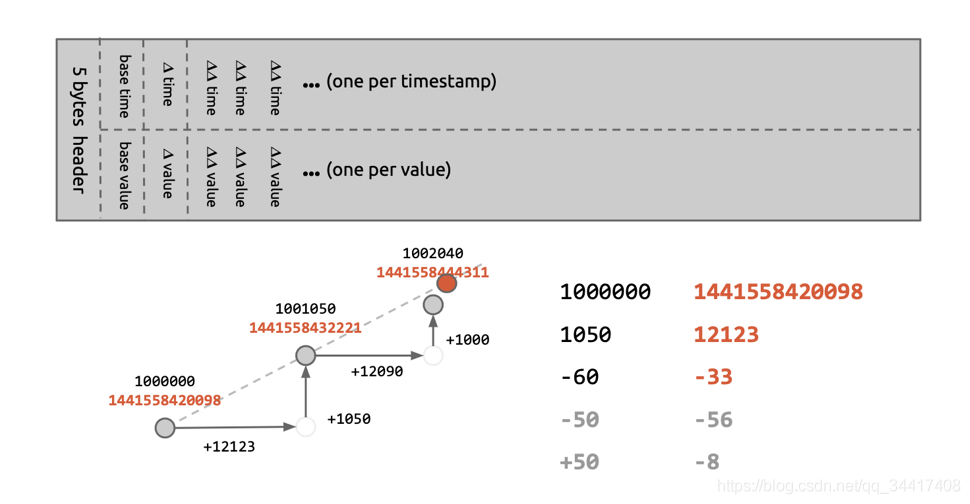
??如圖,在每個 chunk 中,只存盤一個完整的 value + Timestamp 作為基準,后續資料指標基于資料增長趨勢「斜率」值的差額即可,有效的縮短了數值長度,
??此策略也是 Prometheus 默認壓縮編碼策略,
XOR策略
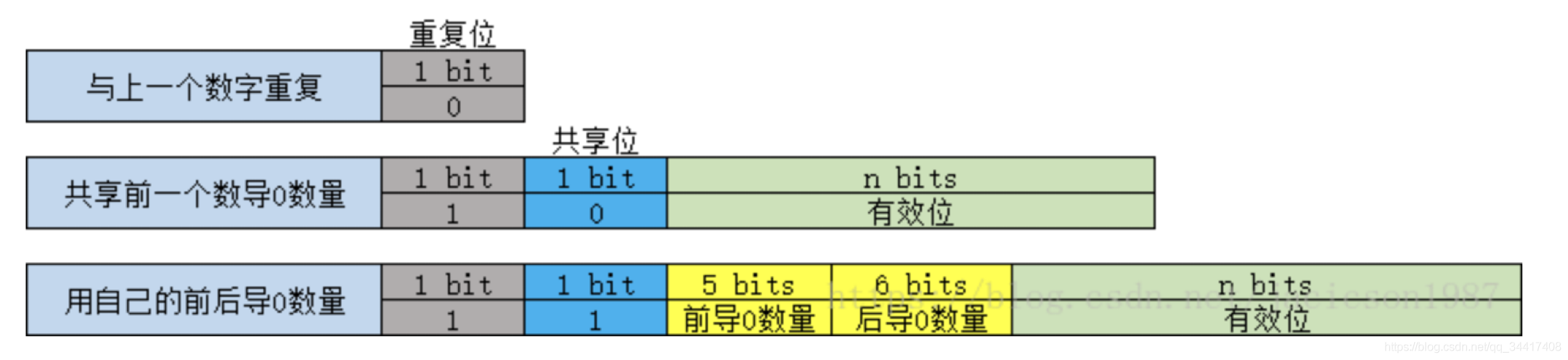
??大家都知道浮點數在計算機中存盤結構是這樣的:

??由于相鄰的 sample 點的資料值差異很小,也可以采用 XOR 策略,
通過連續兩個值做異或操作,不同的 bits 只有2位,頭部( leading )和尾部( trailing )都有大量連續的位是 ’ 0 ‘ , 根據這種情況,對 leading 和 trailing 的’ 0 ’進行壓縮存盤就能節約大量空間,
??XOR結構圖如下:
上面跟大家嘮了那么多存盤,都是基于本地存盤,當我們線上生產環境需要集群部署的時候,可咋辦呢?不慌,繼續嘮…
<有點喝了,歡迎關注收藏,歇歇下次繼續看…>
五、Prometheus集群部署
??云設施的完善和發展,使服務上云的節奏不斷加快,推動著主流的產品技術走向未來,
??在基于云的部署中,常見物理機、虛擬機逐漸將會被容器化技術代替,基于容器的 k8s ,慢慢的走向大眾視野….
??那么 Prometheus 在生產環境中部署該如何做呢?
注:下面的集群部署方案部分基于 Kubernetes ,
單小集群解決方案
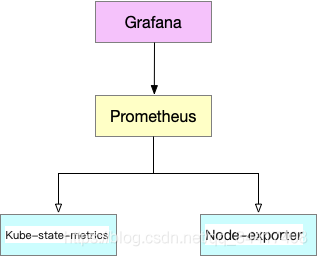
??單個集群中,利用 Kubernetes 提供的 kube-state-metrics、node-exporter、apiserver,controller-manager,scheduler,kubelet 等組件,提供每個組件核心功能相關的資料,比如 QPS、容器 CPU 使用率、記憶體使用率、Pod 的基本資訊等…
??通過 Prometheus 提供的 Explore 機制將相關指標轉化為 Prometheus 格式即可,
名詞小課堂:
- Kube-state-metrics:這個組件用于監控Kubernetes資源的狀態,比如Pod的狀態,原理是將Kubernetes中的資源,轉換成Prometheus的指標,讓Prometheus來采集,比如Pod的基本資訊,Serivce的基本資訊,
- Node-exporter:用于監控Kubernetes節點的基本狀態,這個組件以DeamonSet的方式部署,每個節點一個,用于提供節點相關的指標,比如節點的cpu使用率,記憶體使用率等等,
……
部署架構
??使用這種方式,就可以將集群的節點,組件,資源狀態,容器運行時狀態都給監控起來,
多集群部署解決方案
??當我們擁有多個集群需要監控,需要將他們的監控資料存盤在一起進行聚合處理,利用單機群的架構就存在兩個問題:
1、網路問題
多個集群之間網路可能是不通的,也就意味著通過API無法拉取資料,
2、服務發現問題
Prometheus無法對集群外的集群做服務發現,無法跨集群操作,
??針對這種情況,Prometheus 提供了聯邦策略,
聯邦策略
??Prometheus 支持拉取其他 Prometheus 的資料到本地,稱為聯邦機制,
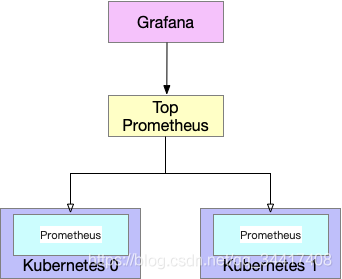
??通過對每個集群單獨部署 Prometheus 服務,在他們上層部署一個 Top Prometheus ,用于拉取各個集群內部的 Prometheus 資料進行匯總,
??在集群規模普遍較小,整體資料量不大的情況下,聯邦的方案部署簡單,理解成本低,沒有其他組件的引入,是一個很不錯的選擇,
??1、當資料規模龐大的時候,資料存盤壓力全在 Top Prometheus ,會出現無法承載的問題,
??2、另外一點是,如果最底層 Prometheus 沒有關閉本地存盤的話,還會存在資料冗余的問題(Prometheus2.x 版本一下不支持關閉本地存盤),
Thanos 高可用解決方案
??Thanos 是一款開源的 Prometheus 高可用解決方案,其支持從多個Prometheus 中查詢資料并進行匯總和去重,并支持將 Prometheus 本地資料傳送到云上物件存盤進行長期存盤,
部署架構
??Thanos 頂層替換掉 Top Prometheus ,底層集群添加 Sidecar 組件進行資料采集上傳到物件存盤,資料通過 Query 組件去重匯總處理進行外顯,
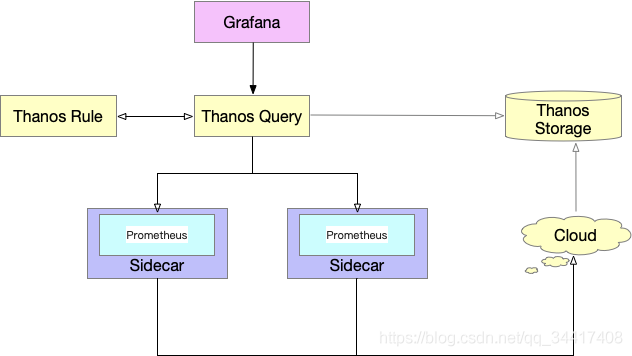
??如上圖所示,包含以下幾個基本組件,
- Query:Query代理Prometheus作為查詢入口,它會去所有Prometheus,Store以及Ruler查詢資料,匯總并去重,
- Sidecar:將資料上傳到物件存盤,也負責接收Thanos Query的查詢請求,
- Ruler:進行資料的預聚合及告警,
- Store: 負責從物件存盤中查詢資料,
??Thanos 相對聯邦機制有以下幾個優勢:
????1、資料不再存盤在單個 Prometheus 中,所以整體能承載的資料規模比聯邦大,
????2、Thanos Query 組件有去重能力,每個集群中可以部署2+個Prometheus來做資料多副本,
????3、監控資料可傳送到云上物件存盤,能支持更長久的存盤,
大集群場景解決方案
??大集群場景的特點是資料規模大,無論是節點的規模,還是資料量,都是一個 Prometheus 無法采集的,
分片策略
??Prometheus 支持在組態檔中加入 hashmod ,通過某個 label 的值來進行 hash ,讓每個 Prometheus 只采集部分節點,
??例如按節點的地址進行 hashmod ,讓節點采集任務分散到3個 Prometheus 中,這樣每個 Prometheus 就只會采集部分節點,從而達到分片效果,由于每個分片的 hashmod 取值不一樣,所以每個分片需要使用單獨的組態檔,
??雖然使用 hashmod 的方式在一定程度上可以將負載分散到多個 Prometheus 中,但是其至少存在以下問題:
1、配置管理復雜:由于每個分片都要有單獨的組態檔,需要維護多份組態檔,
2、配置項有侵入:需要為每個 Job 考慮 hashmod 的方式,而且需要清楚所采集資料根據那個 label 來 hash 才可能平均,對使用者相當不友好,
3、可能出現熱點:hashmod 是不保證負載一定均衡的,因為如果多個資料規模較大的節點被 hashmod 到一個分片,這個分片就有可能 OOM ,
??Thanos 支持 Prometheus 的分片策略解決大集群部署問題,但針對上述存在的問題,暫時沒有較好的解決方案,
Q&A
1、文中開始的效果圖是 Prometheus + Grafana ,Prometheus 生產資料源之后怎么和Grafana 互動可以講解下嗎?
具體詳情請關注后續博文
2、文中提出云原生,云原生架構具體是指什么呢?
具體詳情請關注后續博文
3、Prometheus 誕生于云時代的到來,這里云是指哪些?
文中的云基礎設施包含公有云、私有云、混合云,
4、Prometheus 和其他監控組件有什么區別?面對監控場景該如何選型呢?
細品 Prometheus 特點,擁抱云原生! 具體詳情請關注后續博文
5、Prometheus 自身節點資料如何監控呢?
需要根據實際情況去搭建一個,最好依托手邊現有的基礎設施監控,將Prometheus部署在上面即可,
具體詳情請關注后續博文
6、倒排索引具體策略是什么呢?
請關注后續博文,或移步Es「https://blog.csdn.net/qq_34417408/article/details/117196166?spm=1001.2014.3001.5502」
8、云時代中,容器化、云原生化是每個系統都會逐步發展的目標或是終點嗎/?
首先,微服務、容器和云原生架構并不是適合每個專案;
隨著VR\loT等技術的發展,系統或架構的演進或許沒有終點…
具體詳情請關注后續博文
附錄
通過刨析 Prometheus 內部策略及各種結構「細品」,希望對以后架構設計有所幫助!
一天一個小技巧,偷偷超越隔壁老大哥!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286251.html
標籤:其他