背景:yarn的web界面是所有大資料開發都會或多或少查看的,比如任務運行失敗,任務運行緩慢,查看詳細任務運行進度,詳細報錯排查,debug等,但是實際從反饋來看,很多大資料開發對yarn界面的日志查看并不深入,對一些常見指標并不熟悉,下面以Hive/MapRedcue任務為例,
1.Task容錯機制原理與使用
1.1 map/reduce有failed和killed現象?
如下任務yarn界面很常見,比如reduce出現了2個failed,17killed,那么對我任務最終結果有沒有影響呢?如果沒有影響原因是啥呢?比如下面Task Type和 Attemp Type兩個欄目都有map/reduce的狀態和個數統計,兩者的區別是什么?要想深入了解這些問題,就先要弄明白mapredcue/hive任務的Tast容錯機制,
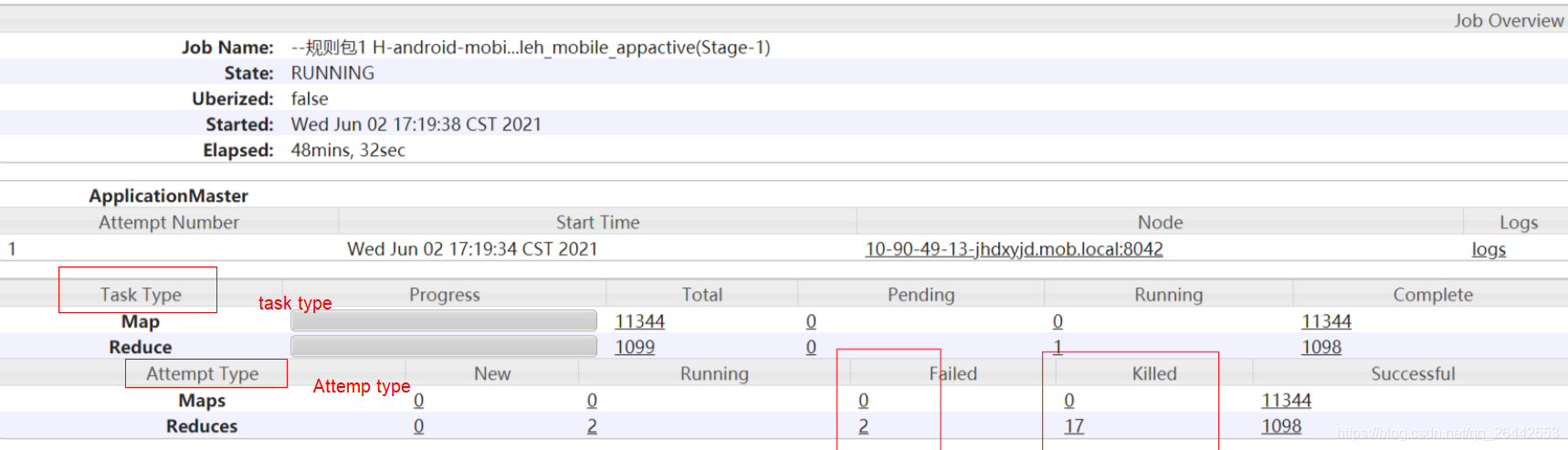
1.2 Task type與Attemp Type的區別
MapRecue/Hive 任務分成maptask和reducetask,每個型別的task的總數一般是根據資料量和引數配置決定,在任務起始階段已經確定,yarn界面的Task Type統計的就是提交yarn時需要執行的task任務數量,而實際一個task允許嘗試多次運行,每次運行嘗試的實體就被稱Task Attempt,也就是yarn任務日志界面Attempt Type里統計的資料,這也就是為啥map/reduce的實體都是以attmp_****開頭的原因,因為任務的運行實體是attemp,
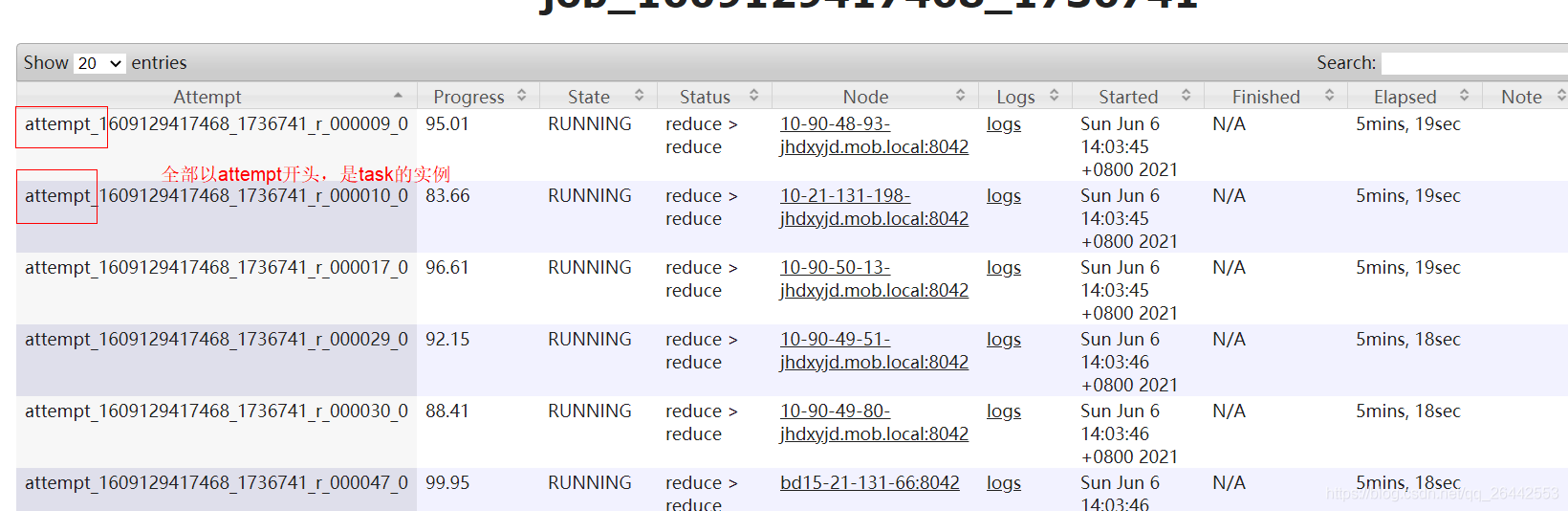
注意:任務還是task開頭的,兩個查看的入口是不同的,我們一般關注的是task的進度,一個task任務可以有多個attmpt實體在跑,具體牽扯到推測執行,
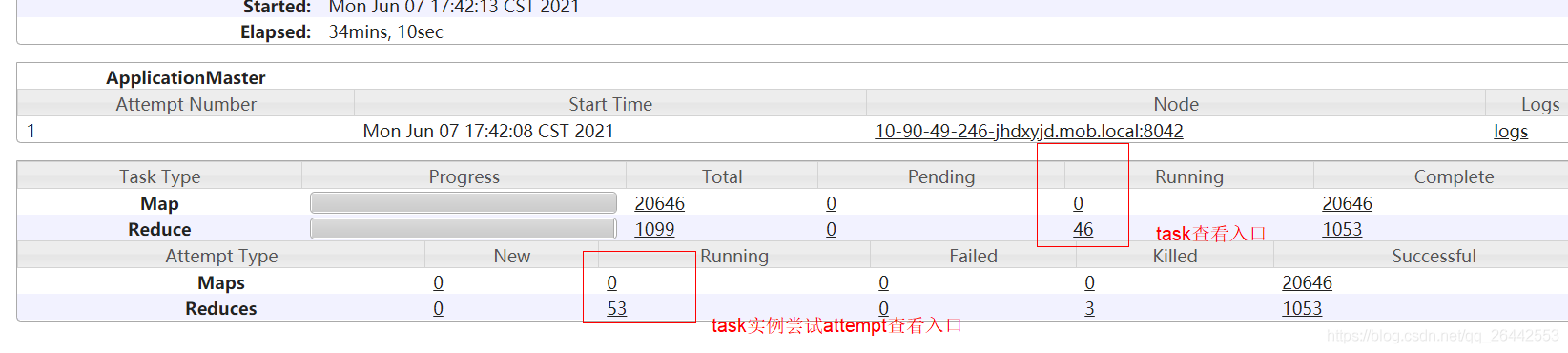
1.3Task的容錯機制的使用
實際生產中,map/reduce task會因為多方面原因如機器老化,資源不足,行程崩潰,帶寬限制等出現部分map/reduce task實體失敗的情況,這是極其正常且容易發生的事,如果這個時候整個任務就直接報錯了,那么代價就太大了,所以hadoop就引入了task容錯機制,map/reduce實體失敗后,在退出之前向APPMaster發送錯誤報告,錯誤報告會被記錄進用戶日志,APPMaster然后將這個任務實體標記為failed,將其containner資源釋放給其他任務使用,
通過如下兩個引數控制map/reduce的task一旦失敗了map/reduce實體可以重試的次數,一般直接使用默認值就可以,所以實際開發中,不要關注單個map的失敗,只要不失敗四次,對任務就沒有影響,每次失敗后APPMaster都會試圖避免在以前失敗過的節點上重新調度該任務,直到任務成功,或者超過4次,超過4次則不會在嘗試,默認作業容錯率是0,這時候整個任務失敗,
1.控制Map Task失敗最大嘗試次數,默認值4
mapred.map.max.attempts ---廢棄引數
mapreduce.map.maxattempts ---推薦新引數
2.1.控制Reduce Task失敗最大嘗試次數,默認值4
mapred.reduce.max.attempts ---廢棄引數
mapreduce.reduce.maxattempts---推薦新引數1.3.1任務任務實體出現failed/killed的場景
1.任務實體attempt長時間沒有向MRAPPMaster報告,后者一直沒收到其進度的更新,一般attempt實體與APPMaster3s通信一次,前者像后者報告任務進度和狀態;超出閾值,任務變會被認為僵死“”被標記失敗failed,然后MRAPPMaster會將其JVM殺死,釋放資源,然后重新嘗試在其他節點啟動一個新的任務實體,
mapreduce.task.timeout=600000 ms,10分鐘
The number of milliseconds before a task will be terminated if it neither reads an input, writes an output, nor updates its status string. A value of 0 disables the timeout.2.任務attempt失敗fialed的其他原因比較多,比如代碼有問題,outofmemory,GC.
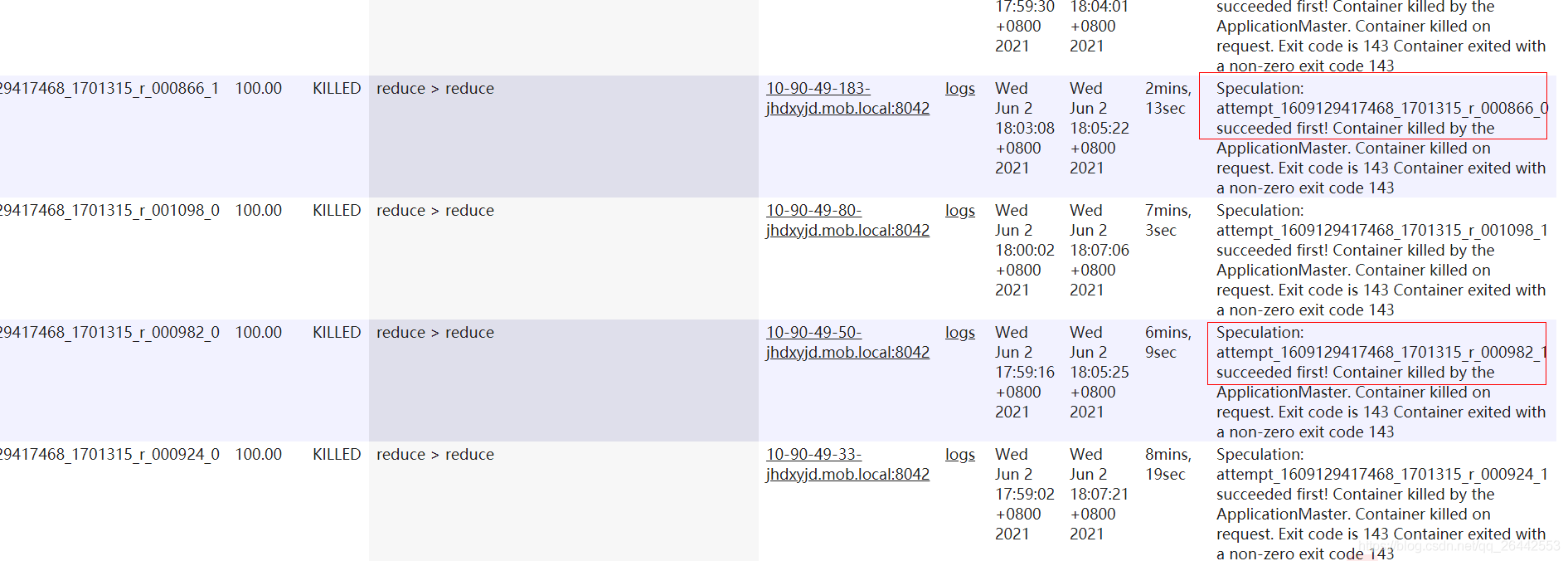
3.一個任務實體attempt被killed一般就兩種情況,一是客戶端主動請求殺死任務,二是框架主動殺死任務,對于后者,一般是由于作業被殺死或者該任務的備任任務(推測執行)已經執行完成,這個任務不需要繼續執行了,所以被Killed,比如nodemanager節點故障,比如停止等,這時候上面的所有任務實體都會被標記為killed,其他再比如任務執行超出某些閾值范圍,比如動態磁區超過最大檔案數,所有任務都會被殺死killed.
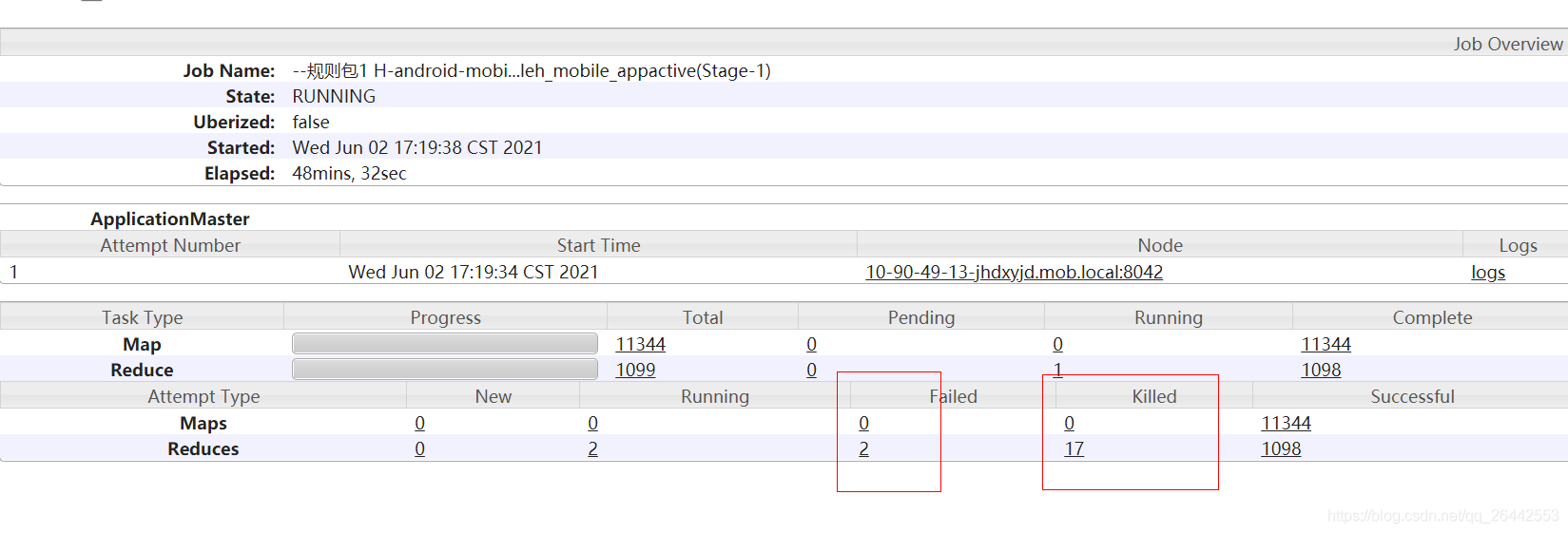
如下任務被殺死就是因為MRAPPMaster主動要求殺死的備份任務
2.任務的推測執行
實際開發中查看yarn日志可能會遇到,為啥顯示有257reduce沒跑完,下面attempt里卻有261redcues 處于running狀態呢?
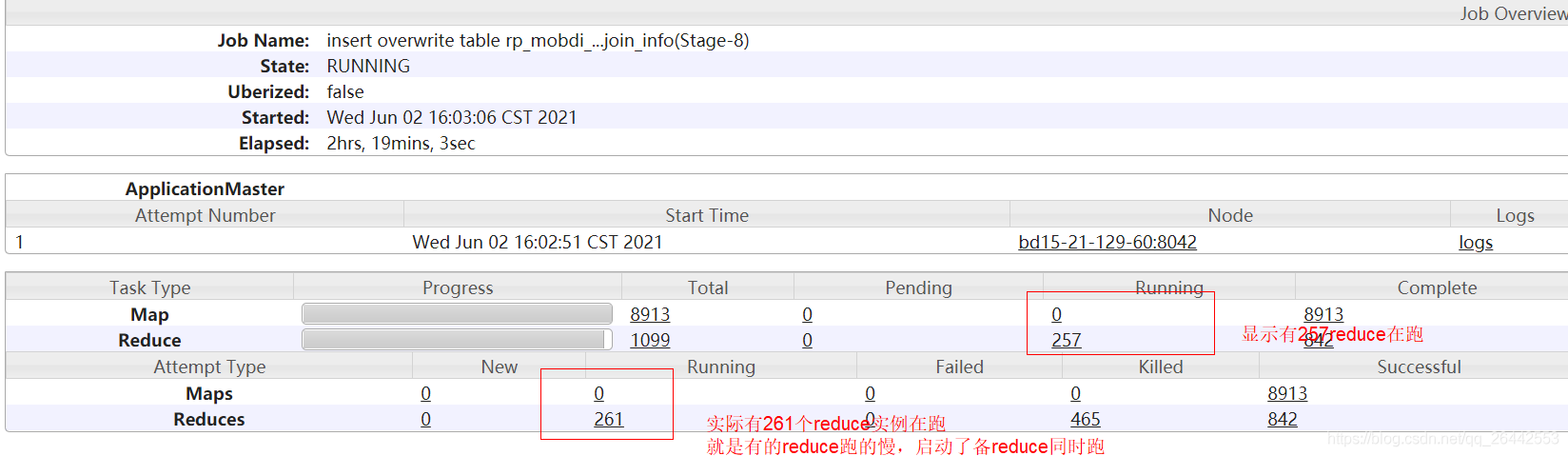
MRappMaster當監控到一個任務實體的運行速度慢于其他任務實體時,會為該任務啟動一個備份任務,讓這個兩個任務同時處理一份資料,如map/reduce,誰先處理完,成功提交給MRappMaster就采用誰的,另一個則會被killed,這種方式可以有效防止那些長尾任務拖后腿,是為任務推測speculative execution,
任務推測執行的好處就是空間換時間,防止長尾拖后腿的,比如某個實體所在的機器不行跑的賊慢,重啟一個很快執行完了,任務推測的壞處就是兩個重復任務,浪費資源,降低集群的效率,尤其redcue任務的推測執行,拉群map資料加大網路io,而且推測任務可能會相互競爭,
默認集群開啟推測執行,可以基于集群計算框架,也可以基于任務型別單獨開啟,map任務建議開啟,reduce可以結合實際謹慎開啟,
mapreduce.map.speculative=true
---默認,開啟map推測執行
mapreduce.reduce.speculative=true
---默認,開啟reduce推測執行,都可單獨開,
mapreduce.job.speculative.speculative-cap-running-tasks=0.1
--在任何時刻可以被推測執行的任務數百分比
--其他還有很多關于推測執行的引數,可以參考官網3.任務進度與計數器
經常參看某個整個任務進度或者task進度,你知道這個進度是怎么計算出來的?
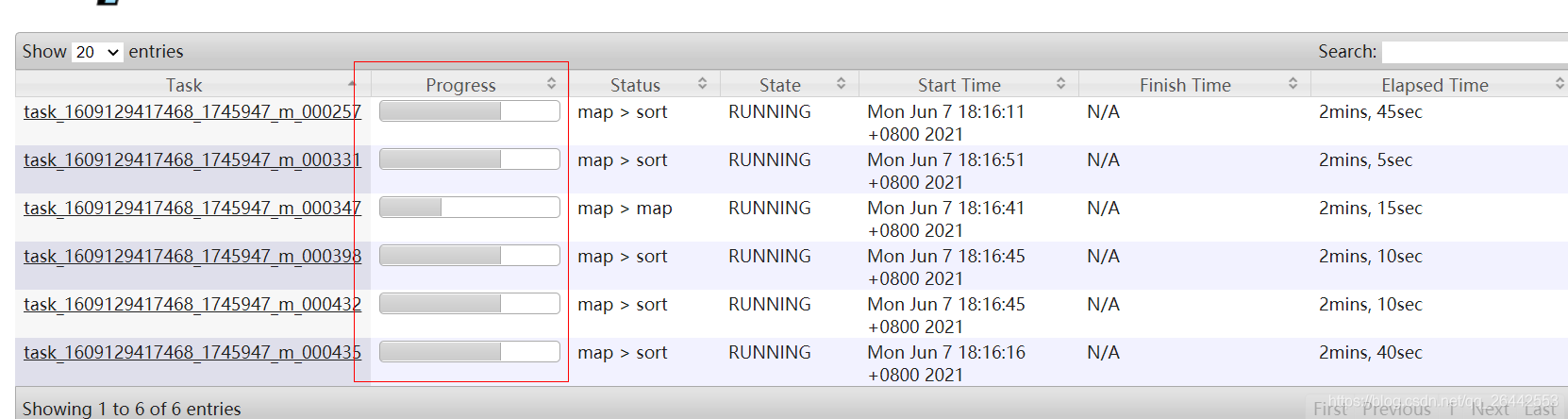
map/reduce任務task運行時,會和MRAPPMaster進行通信,間隔3s,通過UMbilical介面匯報自己的 任務進度以及任務狀態,最侄訓總展示如上圖所示,
map任務比較簡單,任務進度就是對切片輸入的資料總量已處理的占比,比如處理完了85%的資料了那么進度就是85%,主要通過計數器統計,
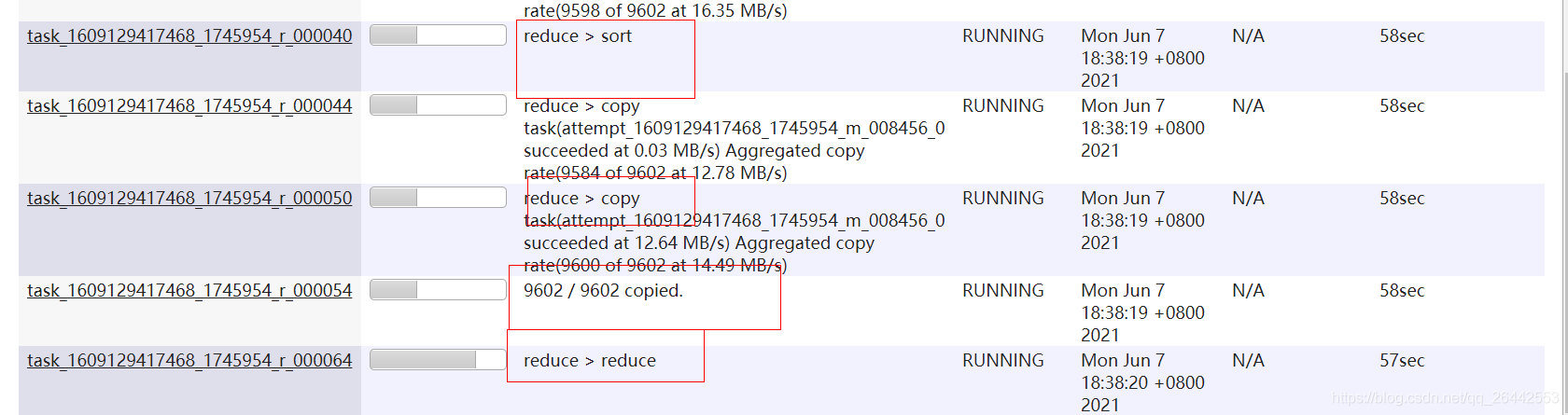
reduce任務根據redue階段的完成統計的,三個程序依次是;拉取復制map資料1/3,合并排序1/3,reduce函式聚合處理1/3;比如某個reduce處理了map輸出的資料一半,則該reduce的進度是1/3+1/3+1/3*1/2,
如下反應了一個reuce的三個階段
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286368.html
標籤:其他
上一篇:一文快速搞懂Kudu到底是什么