1 單變數線性回歸模型
1.1 模型例子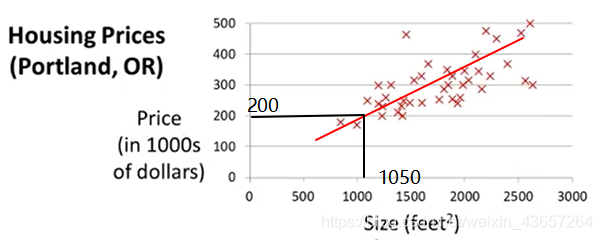
這是一個預測房屋價格的模型,根據不同的房屋面積可以推測出對應的價格,如圖所示,如果有一個1050平方尺大小的房子,則預計可以以200k左右的價格賣出
這是監督學習演算法的一個例子,它的監督學習方式是回歸(Regression),回歸的意思是,我們根據之前的資料預測出一個準確的輸出值,對于這個例子來說輸出值就是價格
還有一種學習方式叫做分類(Classification),就是0/1離散輸出的問題,給一個輸入值,預測是還是否
符號標記:
m m m:訓練樣本數量
x x x:輸入變數/特征, y y y:輸出變數/目標變數
( x , y ) (x,y) (x,y):一個訓練樣本, ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)):第i個訓練樣本
h ( h y p o t h e s i s ) h(hypothesis) h(hypothesis):學習演算法的解決方案(假設)
1.2 監督學習演算法作業方式
首先有一個訓練集,遞給學習演算法,學習演算法輸出一個函式h,輸入房屋尺寸大小,根據輸入的x值來得出y值,y值對應房子的價格,因此h是一個從x到y的函式映射,
h的運算式可能為:
?
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_{θ(x)} = θ_0+θ_1x
hθ(x)?=θ0?+θ1?x
因為只含有一個特征/輸入變數,因此這樣的問題叫作單變數線性回歸問題,
2 代價函式
第1節提到了h運算式
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_{θ(x)} = θ_0+θ_1x
hθ(x)?=θ0?+θ1?x
其中
θ
i
\theta_i
θi?是模型引數
然后為模型選擇合適的引數(parameters) θ 0 \theta _0 θ0?和 θ 1 \theta _1 θ1?,選擇的引數決定了我們得到的直線相對于我們的訓練集的準確程度
線性回歸的整體目標函式:
J
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
2
J(\theta_0,\theta_1) = \frac{1}{2m}\sum^{m}_{i=1}{(h_{θ(x^{(i)})}-y^{{(i)}})^2}
J(θ0?,θ1?)=2m1?i=1∑m?(hθ(x(i))??y(i))2
即,我們要找到能使資料集中預測值 h θ ( x ( i ) ) h_{θ(x^{(i)})} hθ(x(i))?和真實值 y ( i ) y^{{(i)}} y(i)的差的平方的和的 1 2 m \frac{1}{2m} 2m1?的最小的 θ 0 \theta_0 θ0?和 θ 1 \theta_1 θ1?
也叫做代價函式/平方誤差函式
3 梯度下降演算法
用于最小化任意函式J
思路:
- 開始先給 θ 0 \theta_0 θ0?和 θ 1 \theta_1 θ1?設定初始值(一般都先設為0)
- 不斷地改變 θ 0 \theta_0 θ0?和 θ 1 \theta_1 θ1?使 J ( θ 0 , θ 1 ) J(\theta_0,\theta_1) J(θ0?,θ1?)變小,直到找到最小值,或區域最小值
選擇不同的初始引陣列合,可能會找到不同的區域最小值(最小值不唯一)
演算法:
重復直至收斂{
θ
j
:
=
θ
j
?
α
?
?
θ
j
J
(
θ
0
,
θ
1
)
\theta_j := \theta_j - \alpha\frac{\partial}{\partial \theta_j}J(\theta_0,\theta_1)
θj?:=θj??α?θj???J(θ0?,θ1?)
} ( for j = 0 j=0 j=0 and j = 1 j=1 j=1 )
接下來對其中一些符號做解釋
: = := :=是賦值運算子,它和 = = =是不一樣的,不要混淆了
α \alpha α是學習率, α \alpha α越大代表梯度下降得越快,反之則下降得越慢(即以多大幅度更新 θ j \theta_j θj?),那么如何確定 α \alpha α后面會講
有一個細節要注意,
θ
0
\theta_0
θ0?和
θ
1
\theta_1
θ1?要同步更新,如下圖所示,左邊是正確的更新,右邊是錯誤的

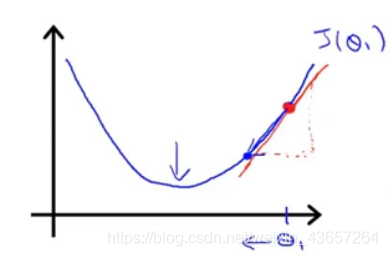
對于這個問題,求導的目的,基本上可以說取這個紅點的切線斜率,就是這條剛好與函式曲線相切的這條直線,這條直線的斜率正好是這個三角形的高度除以這個水平長度,現在,這條線有一個正斜率,也就是說它有正導數,因此,我得到的新的 θ 1 \theta _{1} θ1?,更新后 θ 1 \theta _{1} θ1?等于減去一個正數乘以學習率 a a a,反之,在左邊的話得到的斜率是負數,
現在再回過頭來看學習率 a a a,如果 a a a太小,則更新速度太慢,如果 a a a太大,則可能無法達到最低點,會導致無法收斂甚至發散,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286500.html
標籤:其他
上一篇:matlab撰寫信號的基本運算