JPEG原理分析及JPEG解碼器的除錯
一、實驗簡介
JPEG( Joint Photographic Experts Group)是用于連續色調靜態影像壓縮的一種標準,檔案后綴名為.jpg或.jpeg,是最常用的影像檔案格式,
主要采用預測編碼(DPCM)、離散余弦變換(DCT)以及熵編碼的聯合編碼方式,以去除冗余的影像和彩色資料,屬于有損壓縮格式,
所謂有損壓縮,就是把原始資料中不重要的部分去掉,以便可以用更小的體積保存,
1、JPEG格式分析
具體對照分析方法參見PNG格式分析
(1)SOI
SOI ,Start of Image,影像開始,標記代碼2位元組,固定值0xFFD8

(2)APP0
APP0,Application,應用程式保留標記0

標記代碼 2位元組 FF E0
資料長度 2位元組 00 10
識別符號 5位元組 4A 46 49 46 00 ,即字串JFIF0
版本號 2位元組 01 01
X和Y的密度單位 1位元組 00-無單位
X方向像素密度 2位元組 00
Y方向像素密度 2位元組 01
縮略圖水平像素數目 1位元組 00
縮略圖垂直像素數目 1位元組 01
(3)DQT
DQT,Define Quantization Table,定義量化表

標記代碼 2位元組 FF DB
資料長度 2位元組 00 43

(4)SOF0
SOF0,Start of Frame,幀影像開始


(5)DHT
DHT,Define Huffman Table,定義哈夫曼表


(6)SOS
SOS,Start of Scan,掃描開始 12位元組


(7)EOI
EOI,End of Image,影像結束 ,標記代碼2位元組 固定值0xFFD9
2、JPEG編碼原理
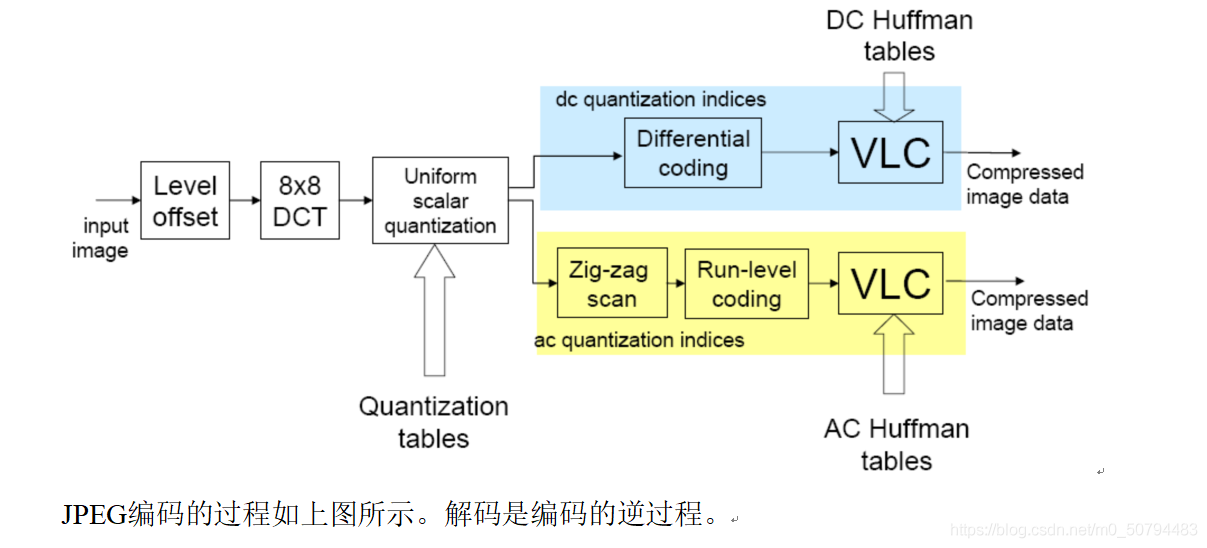
JPEG壓縮編碼演算法的主要計算步驟如下:
(1) level offset
- 將輸入圖片做一個零偏置電平下移,將原數值從無符號數轉換為有符號數,將值域往下做搬移,從而提高編碼效率,
- 對于n=8,即將0~255的值域,通過減去128轉換為值域在-128~127之間的值
(2) 8*8 DCT
- 將原始影像分為8*8的小塊, 對于圖片寬高不為8的倍數的圖片,進行邊緣填充處理,
- 對每個8x8塊的每行進行變換,然后每列進行變換,得到的是一個8x8的變換系數矩陣,其中(0,0)位置的元素就是直流分量,矩陣中的其他元素根據其位置表示不同頻率的交流分量,
DCT(離散余弦變換)具有很強的"能量集中"特性,大多數的自然信號(包括聲音和影像)的能量都集中在DCT變換后的低頻部分,當信號具有接近馬爾科夫程序(Markov
processes)的統計特性時,離散余弦變換的去相關性接近于K-L變換(Karhunen-Loève
變換–它具有最優的去相關性)的性能,從而提高編碼效率
(3) 量化(quantization),
- 量化就是用像素值÷量化表對應值所得的結果,
- 量化表左上角的值較小,右上角的值較大,這樣就起到了保持低頻分量,抑制高頻分量的目的,由于人眼對低頻分量的敏感程度遠高于高頻分量,因此我們需要對低頻分量細量化,對高頻部分粗量化,通過量化可以達到通低頻減高頻的效果
左邊那個量化表,最右下角的高頻÷16,這樣原先DCT后[-127,127]的范圍就變成了[-7,7],固然減少了碼字(從8位減至4位),
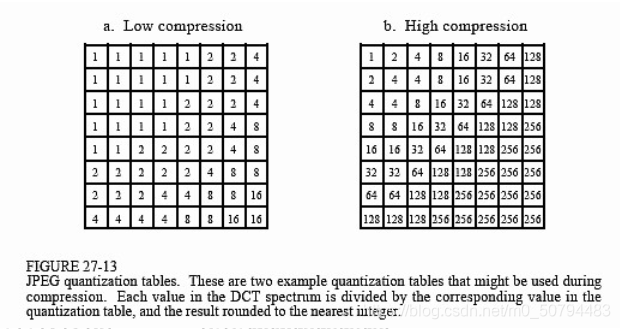
- JPEG使用的顏色是YUV格式,我們提到過,Y分量代表了亮度資訊,UV分量代表了色差資訊,由于人對亮度的敏感程度遠高于色度,我們可以對Y采用細量化,對UV采用粗量化,從而進一步提高壓縮比,所以量化表通常有兩張,一張是針對Y的;一張是針對UV的,
(4) 編碼
編碼資訊分兩類,一類是使用差分脈沖編碼調制(DPCM)對直流系數(DC)進行編碼,一類是使用行程長度編碼(RLE)對交流系數(AC)進行編碼,
- 使用差分脈沖編碼調制(DPCM)對直流系數(DC)進行編碼:
每個8 * 8格子F中的[0,0]位置上元素,代表8 * 8個子塊的平均值,JPEG中對F[0,0]單獨編碼,由于兩個相鄰的8×8子塊的DC系數相差很小,具有冗余,所以對它們采用差分編碼DPCM,可以提高壓縮比,也就是說對相鄰的子塊DC系數的差值進行編碼, - 使用行程長度編碼(RLE)對交流系數(AC)進行編碼:
另一類是8×8塊的其它63個子塊,即交流(AC)系數,采用行程編碼(游程編碼Run-length encode,RLE),為了保證低頻分量先出現,高頻分量后出現,以增加行程中連續“0”的個數,這63個元素采用了“之”字型(zigzag scan),的排列方法,如下圖所示,

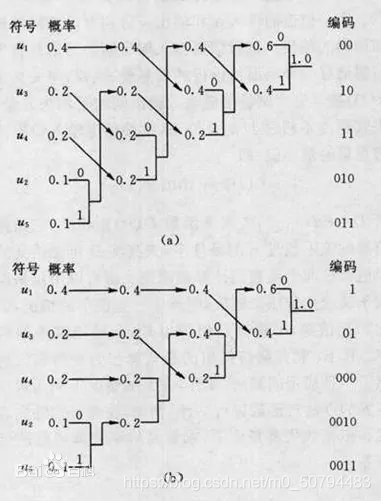
(5) 熵編碼(Huffman編碼)
為了進一步提高壓縮比,需要對RLE編碼結果再進行熵編碼,我們選用Huffman編碼根據使用頻率來最大化節省字符(編碼)的存盤空間,
操作步驟大致如下圖:
將符號按照概率由大到小排隊,編碼時從最小概率的兩個符號開始,可選其中一個支路為0,另一支路為1,然后將已編碼的兩支路的概率合并,并重新按照概率從大到小的順序排隊,多次重復使用上述方法直至合并概率歸一時為止,一般若將新合并后的支路排到等概率的最上支路,將有利于縮短碼長方差,且編出的碼更接近于等長碼
3、JPEG解碼原理
JPEG解碼為編碼的逆程序,解碼大致流程如下:
(1)讀入檔案的相關資訊
(2)初步了解影像資料流的結構
(3)顏色分量單元的內部解碼
(4)直流系數的差分編碼
(5)反量化 & 反Zig-zag編碼
(6)反離散余弦變換
二、實驗步驟
1、定義結構體、引數等
(1)struct huffman_table:
存盤Huffman碼表
struct huffman_table
{
/* Fast look up table, using HUFFMAN_HASH_NBITS bits we can have directly the symbol,
* if the symbol is <0, then we need to look into the tree table */
short int lookup[HUFFMAN_HASH_SIZE];
/* code size: give the number of bits of a symbol is encoded */
unsigned char code_size[HUFFMAN_HASH_SIZE];
/* some place to store value that is not encoded in the lookup table
* FIXME: Calculate if 256 value is enough to store all values
*/
uint16_t slowtable[16-HUFFMAN_HASH_NBITS][256];
};
(2)struct component:
儲存當前8×8像塊中有關解碼的資訊
struct component
{
unsigned int Hfactor; // 水平采樣因子
unsigned int Vfactor; // 垂直采樣因子
float* Q_table; // 指向該8×8塊使用的量化表
struct huffman_table *AC_table; // 指向該塊使用的AC Huffman表
struct huffman_table *DC_table; // 指向該塊使用的DC Huffman表
short int previous_DC; // 前一個塊的直流DCT系數
short int DCT[64]; // DCT系數陣列
#if SANITY_CHECK
unsigned int cid;
#endif
};
(3)struct jdec_private:
JPEG資料流的結構體,包含圖片寬高、Huffman碼表等資訊
/* tinyjpeg-internal.h */
struct jdec_private
{
/* Public variables */
uint8_t *components[COMPONENTS]; /* 分別指向YUV三個分量的三個指標 */
unsigned int width, height; /* 影像寬高 */
unsigned int flags;
/* Private variables */
const unsigned char *stream_begin, *stream_end;
unsigned int stream_length;
const unsigned char *stream; /* 指向當前資料流的指標 */
unsigned int reservoir, nbits_in_reservoir;
struct component component_infos[COMPONENTS];
float Q_tables[COMPONENTS][64]; /* quantization tables */
struct huffman_table HTDC[HUFFMAN_TABLES]; /* DC huffman tables */
struct huffman_table HTAC[HUFFMAN_TABLES]; /* AC huffman tables */
int default_huffman_table_initialized;
int restart_interval;
int restarts_to_go; /* MCUs left in this restart interval */
int last_rst_marker_seen; /* Rst marker is incremented each time */
/* Temp space used after the IDCT to store each components */
uint8_t Y[64*4], Cr[64], Cb[64];
jmp_buf jump_state;
/* Internal Pointer use for colorspace conversion, do not modify it !!! */
uint8_t *plane[COMPONENTS];
};
2、逐步除錯JPEG解碼器程式,將輸入的JPEG檔案進行解碼
具體程式如下:
/* 讀取JPEG檔案,進行解碼,并存盤結果 */
int convert_one_image(const char *infilename, const char *outfilename, int output_format)
{
FILE *fp;
unsigned int length_of_file;
unsigned int width, height;
unsigned char *buf;
struct jdec_private *jdec;
unsigned char *components[3];
/* 把jpeg讀入緩沖區 */
fp = fopen(infilename, "rb");
if (fp == NULL)
exitmessage("Cannot open filename\n");
length_of_file = filesize(fp);
buf = (unsigned char *)malloc(length_of_file + 4);
if (buf == NULL)
exitmessage("Not enough memory for loading file\n");
fread(buf, length_of_file, 1, fp);
fclose(fp);
/* 解壓縮 */
jdec = tinyjpeg_init();
if (jdec == NULL)
exitmessage("Not enough memory to alloc the structure need for decompressing\n");
/* 決議檔案頭 */
if (tinyjpeg_parse_header(jdec, buf, length_of_file)<0)
exitmessage(tinyjpeg_get_errorstring(jdec));
/* 計算影像寬高 */
tinyjpeg_get_size(jdec, &width, &height);
snprintf(error_string, sizeof(error_string),"Decoding JPEG image...\n");
if (tinyjpeg_decode(jdec, output_format) < 0)
exitmessage(tinyjpeg_get_errorstring(jdec));
/*
* Get address for each plane (not only max 3 planes is supported), and
* depending of the output mode, only some components will be filled
* RGB: 1 plane, YUV420P: 3 planes, GREY: 1 plane
*/
//提取YUV分量
tinyjpeg_get_components(jdec, components);
/* 按照指定的輸出格式保存輸出檔案 */
switch (output_format)
{
case TINYJPEG_FMT_RGB24:
case TINYJPEG_FMT_BGR24:
write_tga(outfilename, output_format, width, height, components);
break;
case TINYJPEG_FMT_YUV420P:
write_yuv(outfilename, width, height, components);
break;
case TINYJPEG_FMT_GREY:
write_pgm(outfilename, width, height, components);
break;
}
/* Only called this if the buffers were allocated by tinyjpeg_decode() */
tinyjpeg_free(jdec);
/* else called just free(jdec); */
free(buf);
return 0;
}
3、將輸出檔案保存為可供YUVViewer觀看的YUV檔案
//輸出yuv檔案
snprintf(temp, 1024, "%s.yuv", filename);
F = fopen(temp, "wb");
fwrite(components[0], width, height, F);
fwrite(components[1], width * height / 4, 1, F);
fwrite(components[2], width * height / 4, 1, F);
fclose(F);
4、視音頻編解碼除錯中TRACE的目的和含義
頭檔案tinyjpeg.h中
TRACE設為1,表示程式正常除錯運行;
TRACE設為0,關閉程式
#define snprintf _snprintf
#define TRACE 1
#define TRACEFILE "trace_jpeg.txt"
5、以txt檔案輸出所有的量化矩陣及Huffman碼表
(1)宣告量化矩陣和Huffman碼表的txt檔案
tinyjpeg.h
FILE* quanfile;//宣告量化矩陣txt檔案
FILE* hufffile;//宣告Huffman碼表txt檔案
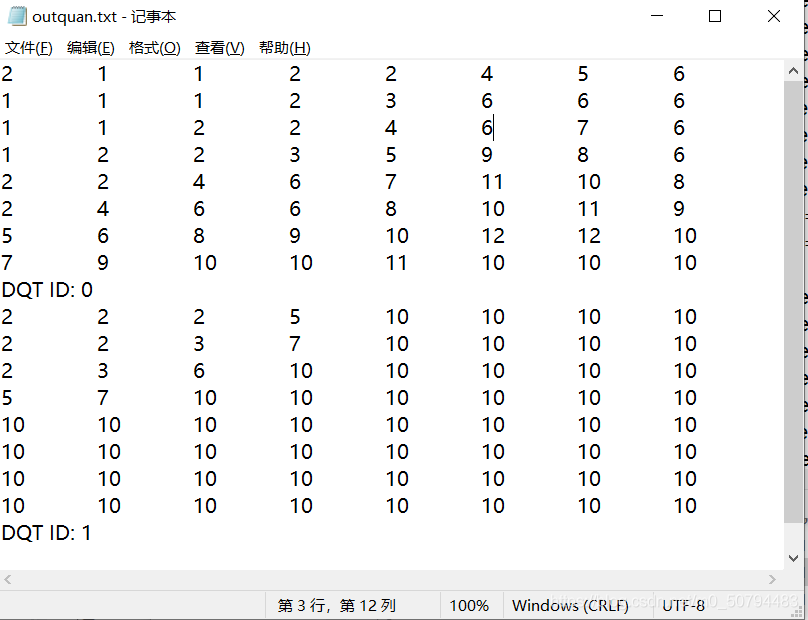
(2)建立并輸出量化矩陣
tinyjpeg.c中build_quantization_table()的修改:
static void build_quantization_table(float* qtable, const unsigned char* ref_table)
{
int i, j;
static const double aanscalefactor[8] = {
1.0, 1.387039845, 1.306562965, 1.175875602,
1.0, 0.785694958, 0.541196100, 0.275899379
};
const unsigned char* zz = zigzag;
//輸出所有量化矩陣
quanfile = fopen("outquan.txt", "a");//打開量化矩陣檔案
for (i = 0; i < 8; i++) {
for (j = 0; j < 8; j++) {
fprintf(quanfile, "%d\t", ref_table[*zz]);//把量化矩陣輸入到txt檔案
*qtable++ = ref_table[*zz++] * aanscalefactor[i] * aanscalefactor[j];
}
fprintf(quanfile, "\n");
}
}
(3)量化矩陣檔案的更新寫入
parse_DQT( )
static int parse_DQT(struct jdec_private* priv, const unsigned char* stream)
{
int qi;//量化表ID
float* table;// 指向量化表
const unsigned char* dqt_block_end;// 指向量化表結束位置
#if TRACE
fprintf(p_trace, "> DQT marker\n");
fflush(p_trace);
#endif
dqt_block_end = stream + be16_to_cpu(stream);
stream += 2; // 跳過長度欄位
while (stream < dqt_block_end)// 檢查是否還有量化表
{
qi = *stream++; // 將量化表中系數逐個賦給qi
#if SANITY_CHECK
if (qi >> 4)
snprintf(error_string, sizeof(error_string), "16 bits quantization table is not supported\n");
if (qi > 4)
snprintf(error_string, sizeof(error_string), "No more 4 quantization table is supported (got %d)\n", qi);
#endif
table = priv->Q_tables[qi];
build_quantization_table(table, stream);
stream += 64;
}
#if TRACE
fprintf(p_trace, "< DQT marker\n");
fflush(p_trace); //更新列印的trace檔案
fprintf(quanfile, "DQT ID: %d\n", qi);
fflush(quanfile); //更新列印量化矩陣
#endif
return 0;
}
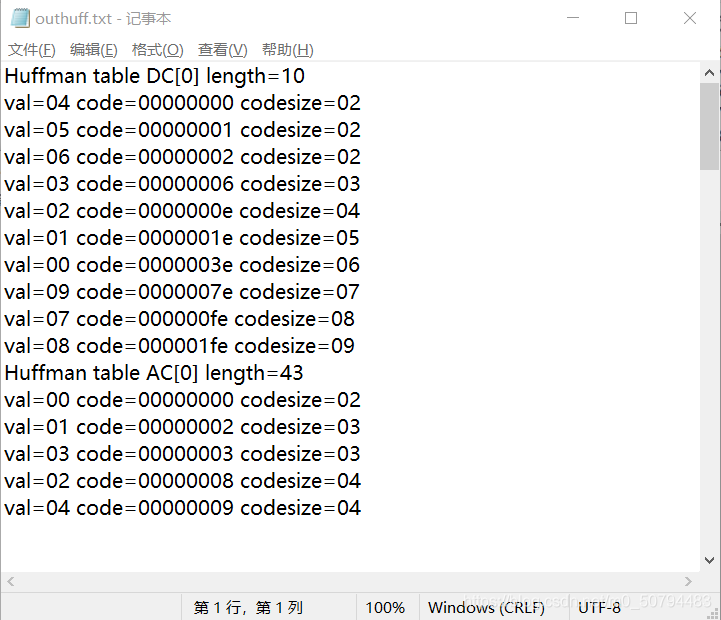
(4)建立并輸出HUFFMAN碼表
static void build_huffman_table(const unsigned char* bits, const unsigned char* vals, struct huffman_table* table)
{
unsigned int i, j, code, code_size, val, nbits;
unsigned char huffsize[HUFFMAN_BITS_SIZE + 1], * hz;
unsigned int huffcode[HUFFMAN_BITS_SIZE + 1], * hc;
int next_free_entry;
/*
* Build a temp array
* huffsize[X] => numbers of bits to write vals[X]
*/
hz = huffsize;
for (i = 1; i <= 16; i++)
{
for (j = 1; j <= bits[i]; j++)
*hz++ = i;
}
*hz = 0;
memset(table->lookup, 0xff, sizeof(table->lookup));
for (i = 0; i < (16 - HUFFMAN_HASH_NBITS); i++)
table->slowtable[i][0] = 0;
/* Build a temp array
* huffcode[X] => code used to write vals[X]
*/
code = 0;
hc = huffcode;
hz = huffsize;
nbits = *hz;
while (*hz)
{
while (*hz == nbits)
{
*hc++ = code++;
hz++;
}
code <<= 1;
nbits++;
}
/*
* Build the lookup table, and the slowtable if needed.
*/
next_free_entry = -1;
for (i = 0; huffsize[i]; i++)
{
val = vals[i];
code = huffcode[i];
code_size = huffsize[i];
/*列印輸出Huffman碼表*/
#if TRACE
fprintf(p_trace, "val=%2.2x code=%8.8x codesize=%2.2d\n", val, code, code_size);
fflush(p_trace);
fprintf(hufffile, "val=%2.2x code=%8.8x codesize=%2.2d\n", val, code, code_size);
fflush(hufffile);
#endif
table->code_size[val] = code_size;
if (code_size <= HUFFMAN_HASH_NBITS)
{
/*
* Good: val can be put in the lookup table, so fill all value of this
* column with value val
*/
int repeat = 1UL << (HUFFMAN_HASH_NBITS - code_size);
code <<= HUFFMAN_HASH_NBITS - code_size;
while (repeat--)
table->lookup[code++] = val;
}
else
{
/* Perhaps sorting the array will be an optimization */
uint16_t* slowtable = table->slowtable[code_size - HUFFMAN_HASH_NBITS - 1];
while (slowtable[0])
slowtable += 2;
slowtable[0] = code;
slowtable[1] = val;
slowtable[2] = 0;
/* TODO: NEED TO CHECK FOR AN OVERFLOW OF THE TABLE */
}
}
}
(5)Huffman碼表的更新寫入
parse_DHT()
/*列印輸出Huffman碼表*/
static int parse_DHT(struct jdec_private* priv, const unsigned char* stream)
{
unsigned int count, i;
unsigned char huff_bits[17];
int length, index;
length = be16_to_cpu(stream) - 2;
stream += 2; /* Skip length */
#if TRACE
fprintf(p_trace, "> DHT marker (length=%d)\n", length);
fflush(p_trace);
#endif
hufffile = fopen("outhuff.txt", "a");
while (length > 0) {
index = *stream++;
/* We need to calculate the number of bytes 'vals' will takes */
huff_bits[0] = 0;
count = 0;
for (i = 1; i < 17; i++) {
huff_bits[i] = *stream++;
count += huff_bits[i];
}
#if SANITY_CHECK
if (count >= HUFFMAN_BITS_SIZE)
snprintf(error_string, sizeof(error_string), "No more than %d bytes is allowed to describe a huffman table", HUFFMAN_BITS_SIZE);
if ((index & 0xf) >= HUFFMAN_TABLES)
snprintf(error_string, sizeof(error_string), "No more than %d Huffman tables is supported (got %d)\n", HUFFMAN_TABLES, index & 0xf);
#if TRACE
fprintf(p_trace, "Huffman table %s[%d] length=%d\n", (index & 0xf0) ? "AC" : "DC", index & 0xf, count);
fflush(p_trace);
fprintf(hufffile, "Huffman table %s[%d] length=%d\n", (index & 0xf0) ? "AC" : "DC", index & 0xf, count);
fflush(hufffile);
#endif
#endif
if (index & 0xf0)
build_huffman_table(huff_bits, stream, &priv->HTAC[index & 0xf]);
else
build_huffman_table(huff_bits, stream, &priv->HTDC[index & 0xf]);
length -= 1;
length -= 16;
length -= count;
stream += count;
}
#if TRACE
fprintf(p_trace, "< DHT marker\n");
fflush(p_trace);
#endif
return 0;
}
四、實驗代碼分析
1、決議JPEG檔案頭函式
JPEG檔案頭函式定位了檔案頭識別符號后的開始位置、長度、以及結束位置:
int tinyjpeg_parse_header(struct jdec_private *priv, const unsigned char *buf, unsigned int size)
{
int ret;
/* Identify the file */
if ((buf[0] != 0xFF) || (buf[1] != SOI)) // JPEG檔案必須以SOI marker為起始,否則不是合法的JPEG檔案
snprintf(error_string, sizeof(error_string),"Not a JPG file ?\n");
priv->stream_begin = buf+2; // 跳過識別符號
priv->stream_length = size-2;
priv->stream_end = priv->stream_begin + priv->stream_length;
ret = parse_JFIF(priv, priv->stream_begin); // 開始決議JPEG
return ret;
}
2、決議SOF
static int parse_SOF(struct jdec_private *priv, const unsigned char *stream)
{
int i, width, height, nr_components, cid, sampling_factor;
int Q_table;
struct component *c;
#if TRACE
fprintf(p_trace,"> SOF marker\n");
fflush(p_trace);
#endif
print_SOF(stream);
height = be16_to_cpu(stream+3);
width = be16_to_cpu(stream+5);
nr_components = stream[7];
#if SANITY_CHECK
if (stream[2] != 8)
snprintf(error_string, sizeof(error_string),"Precision other than 8 is not supported\n");
if (width>JPEG_MAX_WIDTH || height>JPEG_MAX_HEIGHT)
snprintf(error_string, sizeof(error_string),"Width and Height (%dx%d) seems suspicious\n", width, height);
if (nr_components != 3)
snprintf(error_string, sizeof(error_string),"We only support YUV images\n");
if (height%16)
snprintf(error_string, sizeof(error_string),"Height need to be a multiple of 16 (current height is %d)\n", height);
if (width%16)
snprintf(error_string, sizeof(error_string),"Width need to be a multiple of 16 (current Width is %d)\n", width);
#endif
stream += 8;
for (i=0; i<nr_components; i++) {
cid = *stream++;
sampling_factor = *stream++;
Q_table = *stream++;
c = &priv->component_infos[i];
#if SANITY_CHECK
c->cid = cid;
if (Q_table >= COMPONENTS)
snprintf(error_string, sizeof(error_string),"Bad Quantization table index (got %d, max allowed %d)\n", Q_table, COMPONENTS-1);
#endif
c->Vfactor = sampling_factor&0xf;
c->Hfactor = sampling_factor>>4;
c->Q_table = priv->Q_tables[Q_table];
#if TRACE
fprintf(p_trace,"Component:%d factor:%dx%d Quantization table:%d\n",
cid, c->Hfactor, c->Hfactor, Q_table );
fflush(p_trace);
#endif
}
priv->width = width;
priv->height = height;
#if TRACE
fprintf(p_trace,"< SOF marker\n");
fflush(p_trace);
#endif
return 0;
}
3、決議SOS
static int parse_SOS(struct jdec_private *priv, const unsigned char *stream)
{
unsigned int i, cid, table;
unsigned int nr_components = stream[2]; // 顏色分量數
stream += 3;
for (i=0;i<nr_components;i++) {
/* 得到使用的Huffmann表號 */
cid = *stream++;
table = *stream++;
priv->component_infos[i].AC_table = &priv->HTAC[table&0xf];
priv->component_infos[i].DC_table = &priv->HTDC[table>>4];
}
priv->stream = stream+3;
return 0;
}
4、之字形掃描
static const unsigned char zigzag[64] =
{
0, 1, 5, 6, 14, 15, 27, 28,
2, 4, 7, 13, 16, 26, 29, 42,
3, 8, 12, 17, 25, 30, 41, 43,
9, 11, 18, 24, 31, 40, 44, 53,
10, 19, 23, 32, 39, 45, 52, 54,
20, 22, 33, 38, 46, 51, 55, 60,
21, 34, 37, 47, 50, 56, 59, 61,
35, 36, 48, 49, 57, 58, 62, 63
};
五、除錯與結果分析
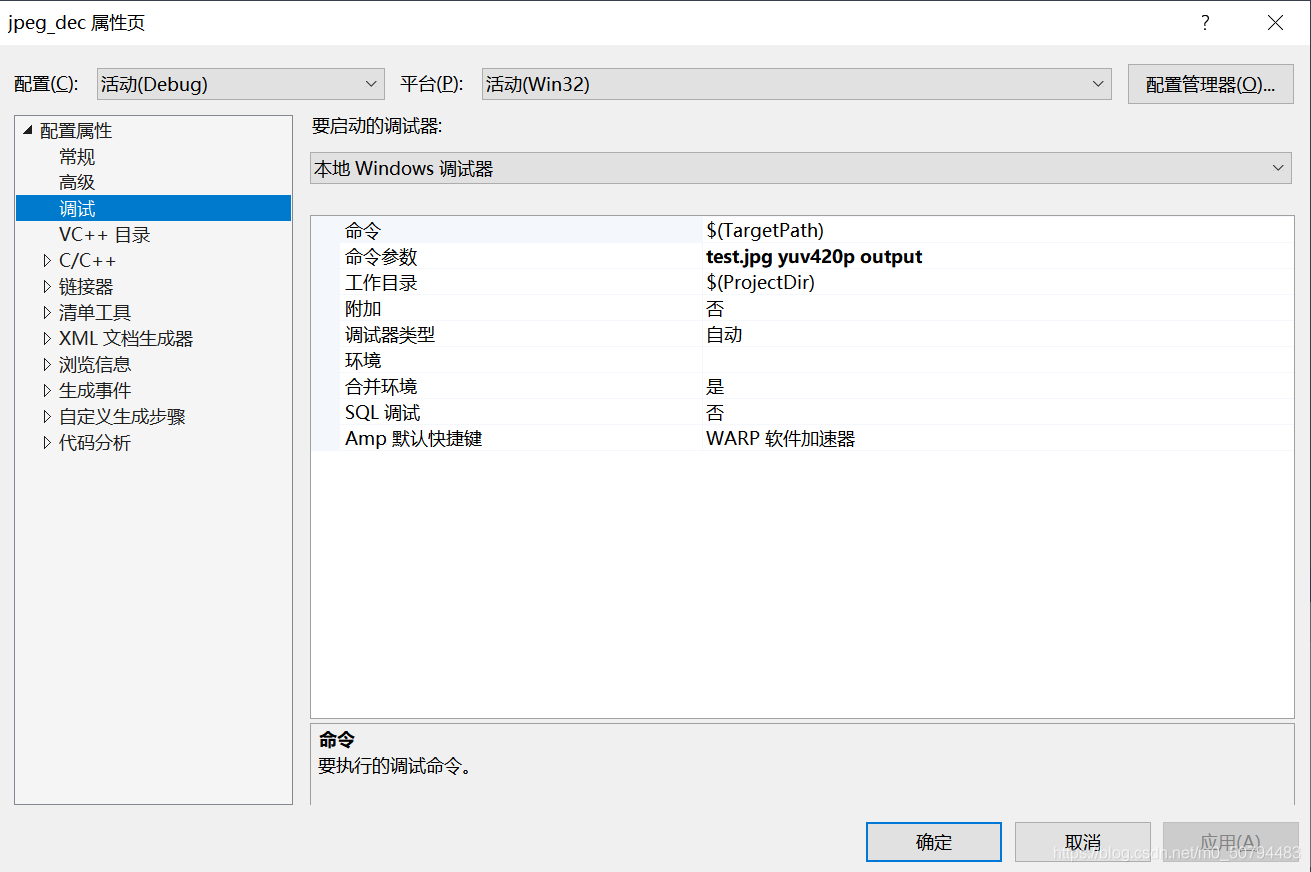
0、設定命令引數
解碼的jpg檔案 /yuv420p / 輸出檔案前綴(中間空格隔開)
這一行命令引數表示將test.jpg檔案轉換為yuv420格式的前綴為output檔案
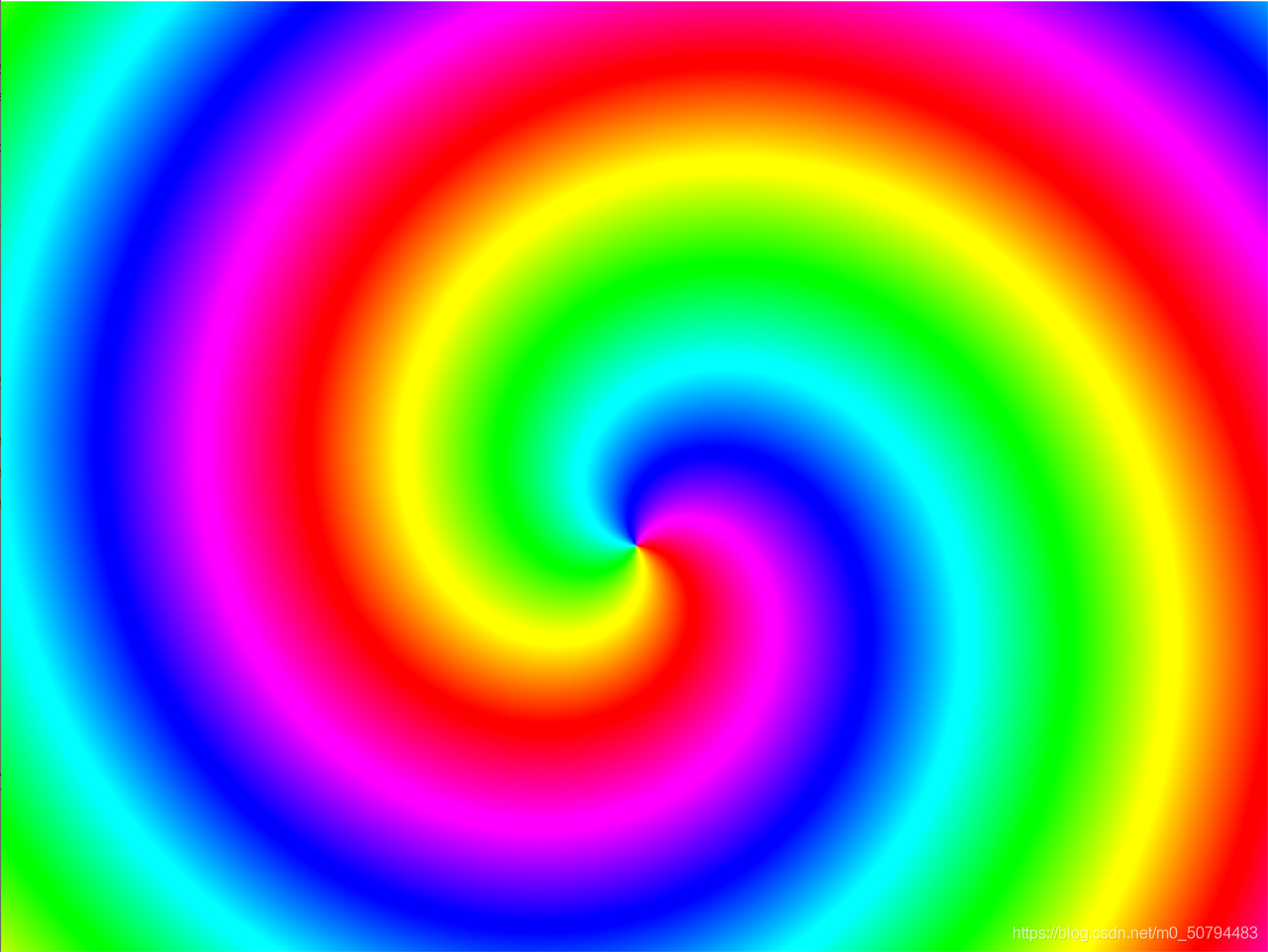
1、解碼JPEG生成的YUV檔案

2、生成量化矩陣檔案outquan.txt

3、生成Huffman碼表
六、實驗總結
1、本實驗通過Visual Studio實作,
2、通過本實驗掌握了JPEG編解碼系統的基本原理以及JPEG的格式分析,
3、在程式除錯中理解程式設計的整體框架以及三個結構體的設計目的,同時理解了TRACE在視音頻編解碼除錯中的目的和含義,
4、初步掌握了復雜的資料壓縮演算法實作,并能根據理論分析需要實作所對應資料的輸出,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286501.html
標籤:其他