全網最詳細的Hive文章系列,強烈建議收藏加關注!
后面更新文章都會列出歷史文章目錄,幫助大家回顧知識重點,
目錄
系列歷史文章
前言
Hive資料庫和表操作
一、資料庫操作
1、創建資料庫
2、創建資料庫并指定hdfs存盤位置
3、查看資料庫詳細資訊
4、洗掉資料庫
二、資料庫表操作
1、創建資料庫表語法
2、Hive建表時候的欄位型別
3、內部表操作
4、外部表操作
5、復雜型別操作
6、磁區表
7、分桶表
8、修改表
9、hive表中加載資料
10、hive表中的資料匯出
系列歷史文章
2021年大資料Hive(二):Hive的三種安裝模式和MySQL搭配使用
2021年大資料Hive(一):???????Hive基本概念
前言
2021年全網最詳細的大資料筆記,輕松帶你從入門到精通,該欄目每天更新,匯總知識分享

Hive資料庫和表操作
一、資料庫操作
1、創建資料庫
create database if not exists myhive;
use myhive;說明:hive的表存放位置模式是由hive-site.xml當中的一個屬性指定的
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
2、創建資料庫并指定hdfs存盤位置
create database myhive2 location '/myhive2';
3、查看資料庫詳細資訊
查看資料庫基本資訊
desc database myhive;
4、洗掉資料庫
洗掉一個空資料庫,如果資料庫下面有資料表,那么就會報錯
drop database myhive;強制洗掉資料庫,包含資料庫下面的表一起洗掉
drop database myhive2 cascade;
二、資料庫表操作
1、創建資料庫表語法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]說明:
1、CREATE TABLE 創建一個指定名字的表,如果相同名字的表已經存在,則拋出例外;用戶可以用 IF NOT EXISTS 選項來忽略這個例外,
2、EXTERNAL 關鍵字可以讓用戶創建一個外部表,在建表的同時指定一個指向實際資料的路徑(LOCATION),Hive 創建內部表時,會將資料移動到資料倉庫指向的路徑;若創建外部表,僅記錄資料所在的路徑,不對資料的位置做任何改變,在洗掉表的時候,內部表的元資料和資料會被一起洗掉,而外部表只洗掉元資料,不洗掉資料,
3、LIKE 允許用戶復制現有的表結構,但是不復制資料,
4、ROW FORMAT DELIMITED 可用來指定行分隔符
5、STORED AS SEQUENCEFILE|TEXTFILE|RCFILE 來指定該表資料的存盤格式,hive中,表的默認存盤格式為TextFile,
6、CLUSTERED BY 對于每一個表(table)進行分桶(MapReuce中的磁區),桶是更為細粒度的資料范圍劃分,Hive也是 針對某一列進行桶的組織,Hive采用對列值哈希,然后除以桶的個數求余的方式決定該條記錄存放在哪個桶當中,
7、LOCATION 指定表在HDFS上的存盤位置,
2、Hive建表時候的欄位型別
| 分類 | 型別 | 描述 | 字面量示例 |
| 原始型別 | BOOLEAN | true/false | TRUE |
|
| TINYINT | 1位元組的有符號整數 -128~127 | 1Y |
|
| SMALLINT | 2個位元組的有符號整數,-32768~32767 | 1S |
|
| INT | 4個位元組的帶符號整數(-2147483648~2147483647) | 1 |
|
| BIGINT | 8位元組帶符號整數 | 1L |
|
| FLOAT | 4位元組單精度浮點數1.0 |
|
|
| DOUBLE | 8位元組雙精度浮點數 | 1.0 |
|
| DEICIMAL | 任意精度的帶符號小數 | 1.0 |
|
| STRING | 字串,變長 | “a”,’b’ |
|
| VARCHAR | 變長字串 | “a”,’b’ |
|
| CHAR | 固定長度字串 | “a”,’b’ |
|
| BINARY | 位元組陣列 | 無法表示 |
|
| TIMESTAMP | 時間戳,毫秒值精度 | 122327493795 |
|
| DATE | 日期 | ‘2016-03-29’ |
|
| Time | 時分秒 | ‘12:35:46’ |
|
| DateTime | 年月日 時分秒 |
|
| 復雜型別 | ARRAY | 有序的的同型別的集合 | ["beijing","shanghai","tianjin","hangzhou"] |
| MAP | key-value,key必須為原始型別,value可以任意型別 | {"數學":80,"語文":89,"英語":95} | |
| STRUCT | 欄位集合,型別可以不同 | struct(‘1’,1,1.0) |
3、內部表操作
未被external修飾的是內部表(managed table),內部表又稱管理表,內部表資料存盤的位置由hive.metastore.warehouse.dir引數決定(默認:/user/hive/warehouse),洗掉內部表會直接洗掉元資料(metadata)及存盤資料,因此內部表不適合和其他工具共享資料,
1、hive建表初體驗
create database myhive;
use myhive;
create table stu(id int,name string);
insert into stu values (1,"zhangsan");
select * from stu;
???????2、創建表并指定欄位之間的分隔符
create table if not exists stu3(id int ,name string) row format delimited fields terminated by '\t';
???????3、根據查詢結果創建表
create table stu3 as select * from stu2;
???????4、根據已經存在的表結構創建表
create table stu4 like stu2;
???????5、查詢表的型別
desc formatted stu2;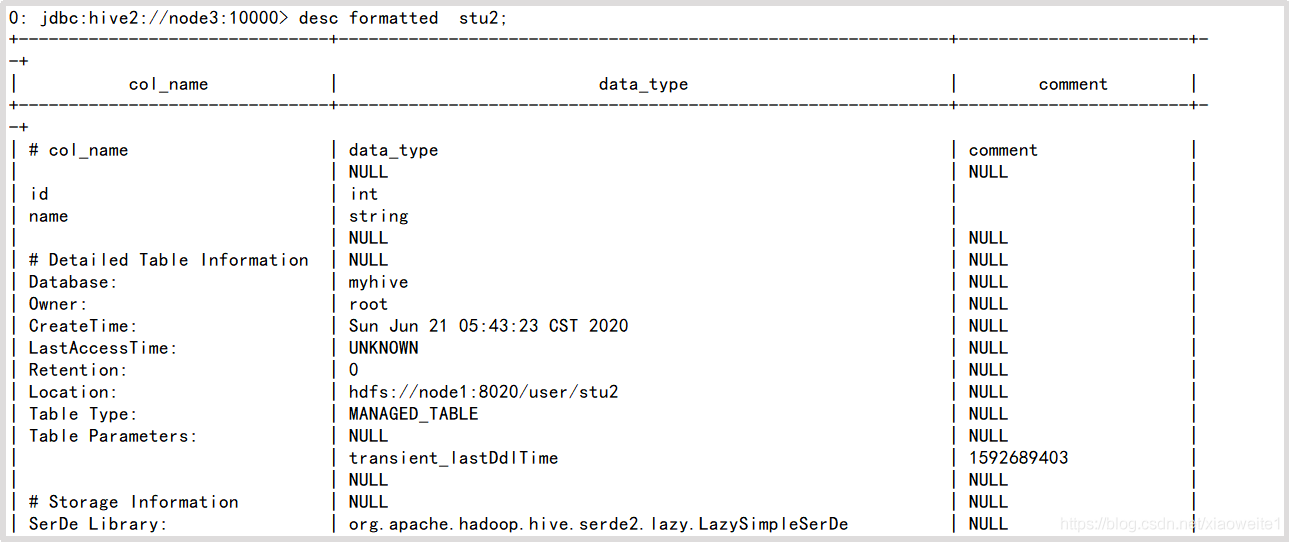
??????????????6、洗掉表
drop table stu2;查看資料庫和HDFS,發現洗掉內部表之后,所有的內容全部洗掉
4、外部表操作
在創建表的時候可以指定external關鍵字創建外部表,外部表對應的檔案存盤在location指定的hdfs目錄下,向該目錄添加新檔案的同時,該表也會讀取到該檔案(當然檔案格式必須跟表定義的一致),
外部表因為是指定其他的hdfs路徑的資料加載到表當中來,所以hive表會認為自己不完全獨占這份資料,所以洗掉hive外部表的時候,資料仍然存放在hdfs當中,不會刪掉,
1、資料裝載載命令Load
Load命令用于將外部資料加載到Hive表中
語法:
load data [local] inpath '/export/data/datas/student.txt' [overwrite] | into table student [partition (partcol1=val1,…)];引數:
- load data:表示加載資料
- local:表示從本地加載資料到hive表;否則從HDFS加載資料到hive表
- inpath:表示加載資料的路徑
- overwrite:表示覆寫表中已有資料,否則表示追加
- into table:表示加載到哪張表
- student:表示具體的表
- partition:表示上傳到指定磁區
???????2、操作案例
分別創建老師與學生表外部表,并向表中加載資料
源資料如下:
student.txt
01 趙雷 1990-01-01 男
02 錢電 1990-12-21 男
03 孫風 1990-05-20 男
04 李云 1990-08-06 男
05 周梅 1991-12-01 女
06 吳蘭 1992-03-01 女
07 鄭竹 1989-07-01 女
08 王菊 1990-01-20 女
teacher.txt???????
01 張三
02 李四
03 王五
- 創建老師表:
create external table teacher (tid string,tname string) row format delimited fields terminated by '\t';- 創建學生表:
create external table student (sid string,sname string,sbirth string , ssex string ) row format delimited fields terminated by '\t';- 從本地檔案系統向表中加載資料
load data local inpath '/export/data/hivedatas/student.txt' into table student;- 加載資料并覆寫已有資料
load data local inpath '/export/data/hivedatas/student.txt' overwrite into table student;- 從hdfs檔案系統向表中加載資料
其實就是一個移動檔案的操作
需要提前將資料上傳到hdfs檔案系統,
hadoop fs -mkdir -p /hivedatas
cd /export/data/hivedatas
hadoop fs -put teacher.csv /hivedatas/
load data inpath '/hivedatas/teacher.csv' into table teacher;注意,如果刪掉teacher表,hdfs的資料仍然存在,并且重新創建表之后,表中就直接存在資料了,因為我們的student表使用的是外部表,drop table之后,表當中的資料依然保留在hdfs上面了
5、復雜型別操作
1、Array型別
Array是陣列型別,Array中存放相同型別的資料
源資料:
說明:name與locations之間制表符分隔,locations中元素之間逗號分隔
zhangsan beijing,shanghai,tianjin,hangzhou
wangwu changchun,chengdu,wuhan,beijin
建表陳述句
create external table hive_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
collection items terminated by ',';匯入資料(從本地匯入,同樣支持從HDFS匯入)
load data local inpath '/export/data/hivedatas/work_locations.txt' overwrite into table hive_array;常用查詢:
-- 查詢所有資料
select * from hive_array;
-- 查詢loction陣列中第一個元素
select name, work_locations[0] location from hive_array;
-- 查詢location陣列中元素的個數
select name, size(work_locations) location from hive_array;
-- 查詢location陣列中包含tianjin的資訊
select * from hive_array where array_contains(work_locations,'tianjin');
???????6、磁區表
磁區不是獨立的表模型,要和內部表或者外部表結合:
內部磁區表
外部磁區表
??????????????1、基本操作
在大資料中,最常用的一種思想就是分治,磁區表實際就是對應hdfs檔案系統上的的獨立的檔案夾,該檔案夾下是該磁區所有資料檔案,
磁區可以理解為分類,通過分類把不同型別的資料放到不同的目錄下,
分類的標準就是磁區欄位,可以一個,也可以多個,
磁區表的意義在于優化查詢,查詢時盡量利用磁區欄位,如果不使用磁區欄位,就會全部掃描,
在查詢是通過where子句查詢來指定所需的磁區,
在hive中,磁區就是分檔案夾
創建磁區表語法
create table score(sid string,cid string, sscore int) partitioned by (month string) row format delimited fields terminated by '\t';創建一個表帶多個磁區
create table score2 (sid string,cid string, sscore int) partitioned by (year string,month string,day string) row format delimited fields terminated by '\t';加載資料到磁區表中
load data local inpath '/export/data/hivedatas/score.csv' into table score partition (month='202006');加載資料到一個多磁區的表中去
load data local inpath '/export/data/hivedatas/score.csv' into table score2 partition(year='2020',month='06',day='01');多磁區聯合查詢使用union all來實作
select * from score where month = '202006' union all select * from score where month = '202007';查看磁區
show partitions score;添加一個磁區
alter table score add partition(month='202008');同時添加多個磁區
alter table score add partition(month='202009') partition(month = '202010');注意:添加磁區之后就可以在hdfs檔案系統當中看到表下面多了一個檔案夾
洗掉磁區
alter table score drop partition(month = '202010');
???????7、分桶表
分桶就是將資料劃分到不同的檔案,其實就是MapReduce的磁區
??????????????1、基本操作
將資料按照指定的欄位進行分成多個桶中去,說白了就是將資料按照欄位進行劃分,可以將資料按照欄位劃分到多個檔案當中去
開啟hive的桶表功能(如果執行該命令報錯,表示這個版本的Hive已經自動開啟了分桶功能,則直接進行下一步)
set hive.enforce.bucketing=true;設定reduce的個數
set mapreduce.job.reduces=3; 創建分桶表
create table course (cid string,c_name string,tid string) clustered by(cid) into 3 buckets row format delimited fields terminated by '\t';桶表的資料加載,由于桶表的資料加載通過hdfs dfs -put檔案或者通過load data均不好使,只能通過insert overwrite
創建普通表,并通過insert overwrite的方式將普通表的資料通過查詢的方式加載到桶表當中去
創建普通表:
create table course_common (cid string,c_name string,tid string) row format delimited fields terminated by '\t';普通表中加載資料
load data local inpath '/export/data/hivedatas/course.csv' into table course_common;通過insert overwrite給桶表中加載資料
insert overwrite table course select * from course_common cluster by(cid);
8、修改表
1、表重命名
基本語法:
alter table old_table_name rename to new_table_name;-- 把表score3修改成score4
alter table score3 rename to score4;
???????2、增加/修改列資訊
-- 1:查詢表結構
desc score4;
-- 2:添加列
alter table score4 add columns (mycol string, mysco string);
-- 3:查詢表結構
desc score4;
-- 4:更新列
alter table score4 change column mysco mysconew int;
-- 5:查詢表結構
desc score4;
??????????????3、洗掉表
drop table score4;
???????4、清空表資料
只能清空管理表,也就是內部表
truncate table score4;
9、hive表中加載資料
1、直接向磁區表中插入資料
通過insert into方式加載資料
create table score3 like score;
insert into table score3 partition(month ='202007') values ('001','002',100);通過查詢方式加載資料
create table score4 like score;
insert overwrite table score4 partition(month = '202006') select sid,cid,sscore from score;
???????2、通過查詢插入資料
通過load方式加載資料
create table score5 like score;
load data local inpath '/export/data/hivedatas/score.csv' overwrite into table score5 partition(month='202006');- ???????多插入模式
常用于實際生產環境當中,將一張表拆開成兩部分或者多部分
給score表加載資料
load data local inpath '/export/data/hivedatas/score.csv' overwrite into table score partition(month='202006');創建第一部分表:
create table score_first( sid string,cid string) partitioned by (month string) row format delimited fields terminated by '\t' ;創建第二部分表:
create table score_second(cid string,sscore int) partitioned by (month string) row format delimited fields terminated by '\t';分別給第一部分與第二部分表加載資料
from score insert overwrite table score_first partition(month='202006') select sid,cid insert overwrite table score_second partition(month = '202006') select cid,sscore;- ???????查詢陳述句中創建表并加載資料(as select)
將查詢的結果保存到一張表當中去
create table score5 as select * from score;- ???????創建表時通過location指定加載資料路徑
1、創建表,并指定在hdfs上的位置
create external table score6 (sid string,cid string,sscore int) row format delimited fields terminated by '\t' location '/myscore6';2、上傳資料到hdfs上
hadoop fs -mkdir -p /myscore6
hadoop fs -put score.csv/myscore6;3、查詢資料
select * from score6;
???????10、hive表中的資料匯出
將hive表中的資料匯出到其他任意目錄,例如linux本地磁盤,例如hdfs,例如mysql等等
??????????????1、insert匯出
1)將查詢的結果匯出到本地
insert overwrite local directory '/export/data/exporthive' select * from score;2)將查詢的結果格式化匯出到本地
insert overwrite local directory '/export/data/exporthive' row format delimited fields terminated by '\t' collection items terminated by '#' select * from student;3)將查詢的結果匯出到HDFS上(沒有local)
insert overwrite directory '/exporthive' row format delimited fields terminated by '\t' select * from score;
??????????????2、hive shell 命令匯出
基本語法:(hive -f/-e 執行陳述句或者腳本 > file)
bin/hive -e "select * from myhive.score;" > /export/data/exporthive/score.txt
??????????????3、export匯出到HDFS上
export table score to '/export/exporthive/score';
???????4、sqoop匯出
由于篇幅有限,在專案實戰的系列文章詳細介紹
本博客大資料系列文章會一直每天更新,記得收藏加關注喔~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287132.html
標籤:其他
上一篇:Linux網路管理,NAT網路配置,修改主機名稱,主機映射,防火墻,系統啟動級別,用戶和用戶組,為用戶配置sudoer權限,檔案權限管理,打包和壓縮