文章目錄
- 前言
- 一、BF解法
- 二、KMP演算法
- 真前綴,真后綴
- KMP原理
- 三、next陣列
- next陣列計算方法
- 四、KMP演算法實作
- 總結
前言
給定一個主字串T以及一個模式字串P,判斷P是不是T的子串,如果是則回傳P在T中第一個元素的位置,如果不是回傳-1,
例如給定主字串:aaaaaabc,模式串aaabc,顯然,P是T的子串,回傳3
主串 aaaaaabc,模式串bcd,P不是T的子串回傳-1,
一、BF解法
對于這個問題,我們最容易想到的就是BF解法
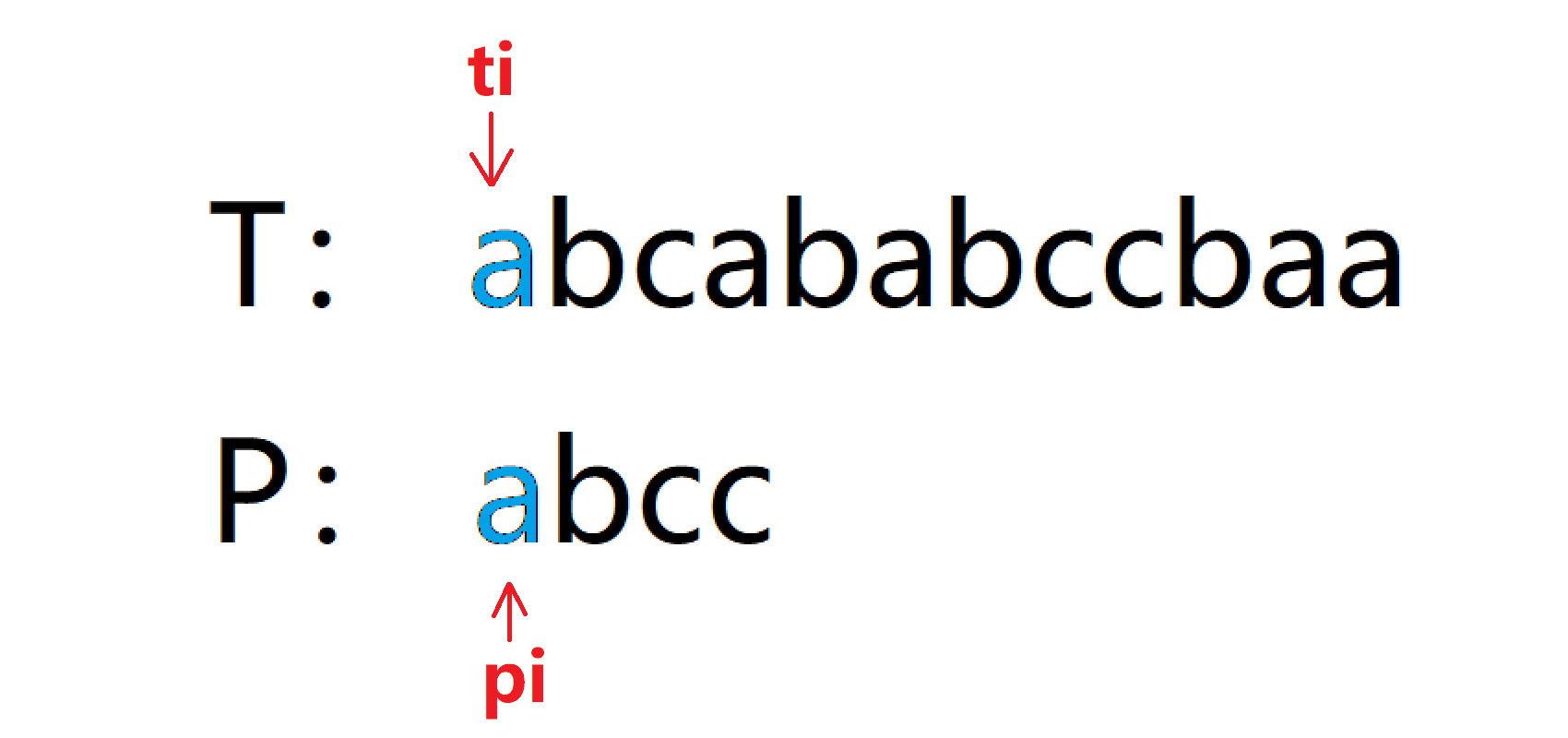
我們以T:abcababccbaa,P:abcc為例分析,
先看一個動圖:藍色表示比配成功,紅色表示匹配失敗
#include<stdio.h>
#include<string.h>
int BF(const char* text, const char* pattern) //text為文本串,pattern為模式串
{
if (text == NULL || pattern == NULL)return -1;
int Tlen = strlen(text);
int Plen = strlen(pattern); //Tlen為文本串長度, Plen為模式串長度
if (Plen == 0)return -1; //規定模式串長度為0,認為pattern不是text子串,回傳-1
if (Plen > Tlen)return -1; //如果Plen > Tlen,pattern肯定不是text子串,回傳-1
//Plen不為0且Plen < Tlen
int ti = 0; //text指標
int pi = 0; //pattern指標
while(ti < Tlen && pi < Plen)
{
if (text[ti] == pattern[pi]) //匹配成功,pi和ti后移
ti++, pi++;
else
{
//匹配失敗,pi和ti回溯
ti = ti - pi + 1; //ti后移一位
//pi的大小就是已經匹配成功的字符數,ti - pi 回到開始比較的字符位置,再加1完成向后移動1位
pi = 0; //pi重頭開始
}
}
//回圈結束ti == Tlen 或者pi == Plen
if (pi == Plen)
return ti - pi; //pi ==Plen,表示完全匹配成功,回傳ti - pi 即開始比較的字符位置
else
return -1; //匹配失敗,回傳-1
}
while回圈:while(ti < Tlen && pi < Plen)可以進行優化

如圖所示,當起始位置大于Tlen - Plen時,就不用繼續比較接下面的字符,可以直接return,比較的起始位置等于ti - pi,所有我們可以對while回圈進行優化:
while(ti - pi <= Tlen - Plen && pi < Plen)
不能用ti <= Tlen -Plen,因為我們要保證的是每次比較的起始位置不大于Tlen - Plen而不是ti不大于Tlen - Plen
二、KMP演算法
BF演算法雖然容易想到,但是運行速度較慢,時間復雜度為O(m * n),m是主字串長度,n是模式串長度,(時間復雜度指的是未優化前的BF演算法)
為了提高運算效率D.E.Knuth,J.H.Morris和V.R.Pratt三位大神提出了一種更為快速的方法,也稱KMP演算法,
BF演算法之所以慢,是因為只要匹配失敗,ti和pi指標都會回溯,ti回溯到原來的起始位置加1出,pi回溯到0,這樣就會造成很多重復的比較,KMP演算法正是改進了這一點,當匹配失敗的時候,ti不回溯,只對pi進行回溯,
真前綴,真后綴
舉個例子,對于字串ababab
所有的真前綴有a,ab,aba,abab,ababa(不包含自身)
所有的真后綴有b,ab,bab,abab,babab(不包含自身)
在真前綴和真后綴中有兩個是相等的,ab和ab,abab和abab,最大相等前后綴長度為4
KMP原理
我們以T:abaaababc,P:abab為例分析相等前后綴的作用:
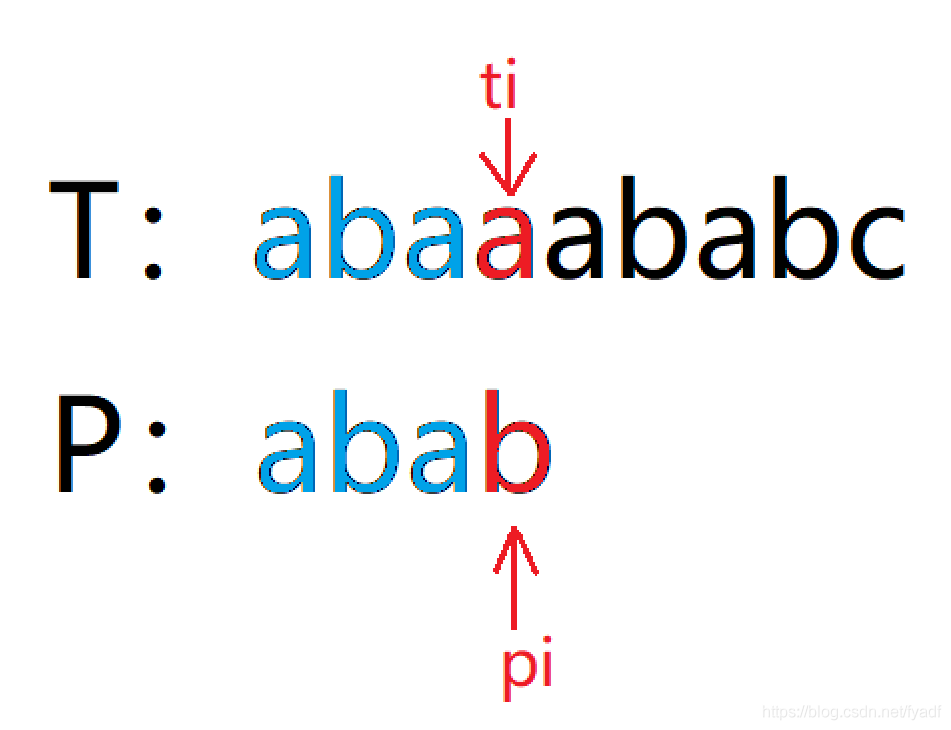
當第四個字符發生不匹配時,前三個字符必然是匹配的,又因為模式串中P[0] == P[2],P[2]和T[2]匹配,因此P[0]也必然和T[2]匹配,因此可以不移動ti,只將pi移動到P[1]位置處即可
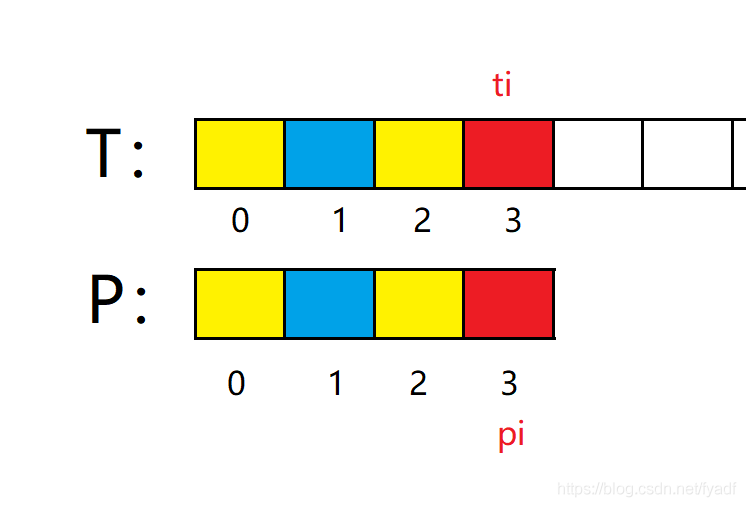
前三個位置匹配,并且黃色部分位置相同,因此對P進行如下移動: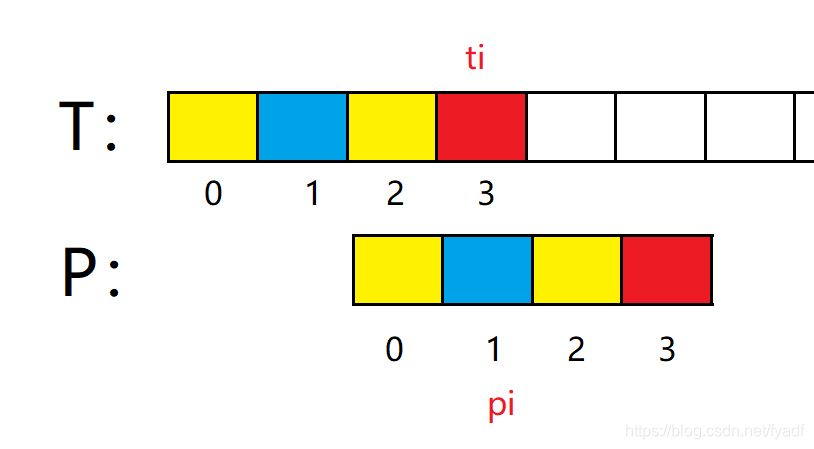
一般情況:pi位置的最大相等前后綴長度為k,當pi處匹配失敗時:
(因為pi才匹配失敗,代表前面部分已經匹配成功)
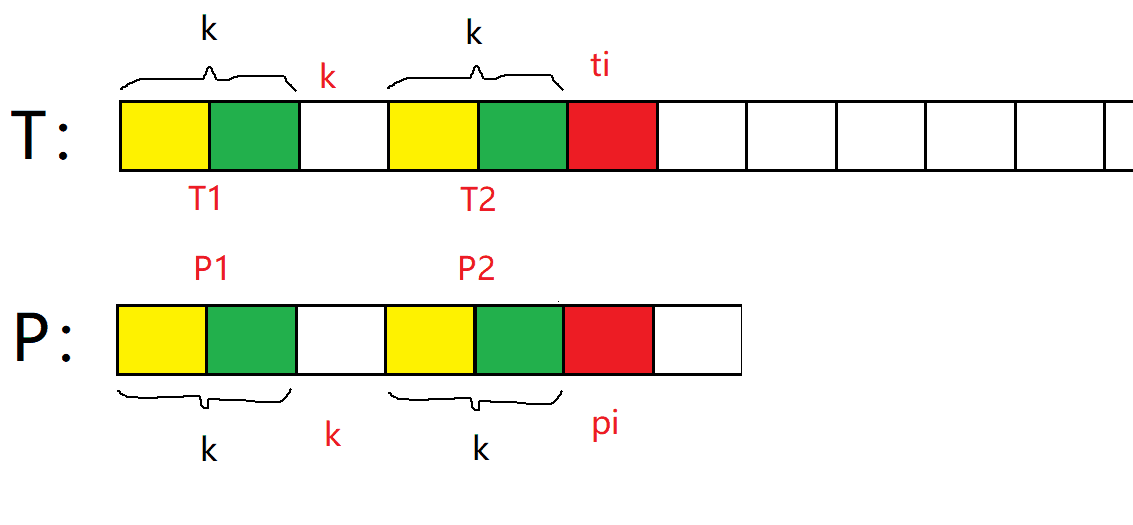
因為T和P的陣列下標是從0開始的,最大前后綴長度為k,因此中間空白處的下標就是k,當pi不匹配時,因為T1 == T2 == P1 == P2,所以只需要將pi移動到下標為k處,這也就是代碼中pi = next[pi]的理解
這就是KMP演算法的原理,當匹配失敗時,ti不動,只對pi進行回溯,這樣就大大減少了算比較的次數,從而提高了演算法的效率,
三、next陣列
在KMP演算法中,引入了一個next[]陣列,next[i]的值表示當第i個字符不匹配時,pi回溯的位置,(這句話非常重要!!!)next陣列中的每個元素就是當前字母前面的字串的最大相等前后綴長度,其中規定next[0] = -1,
例如模式串:ababa,next[1],看a的最大相同前后綴長度,為0;next[2]看ab的最大相同前后綴長度,為0;next[3]看aba的最大相同前后綴長度,為1;,next[4]看abab的最大相同前后綴長度,為2,因此ababa的next[] = {-1, 0, 0, 1, 2 }
next陣列計算方法
這一部分很抽象,也是KMP演算法中最難理解的部分,我也花了很久的時間,看了網上很多的文章,最后才弄明白,我將詳細地給大家解釋這一部分及其代碼,
首先我們要知道一點,next陣列中next[i + 1] <= next[i] + 1;
用反證法證明:假設存在一個i使得,next[i] = k,next[i + 1] = k + n,n > 1
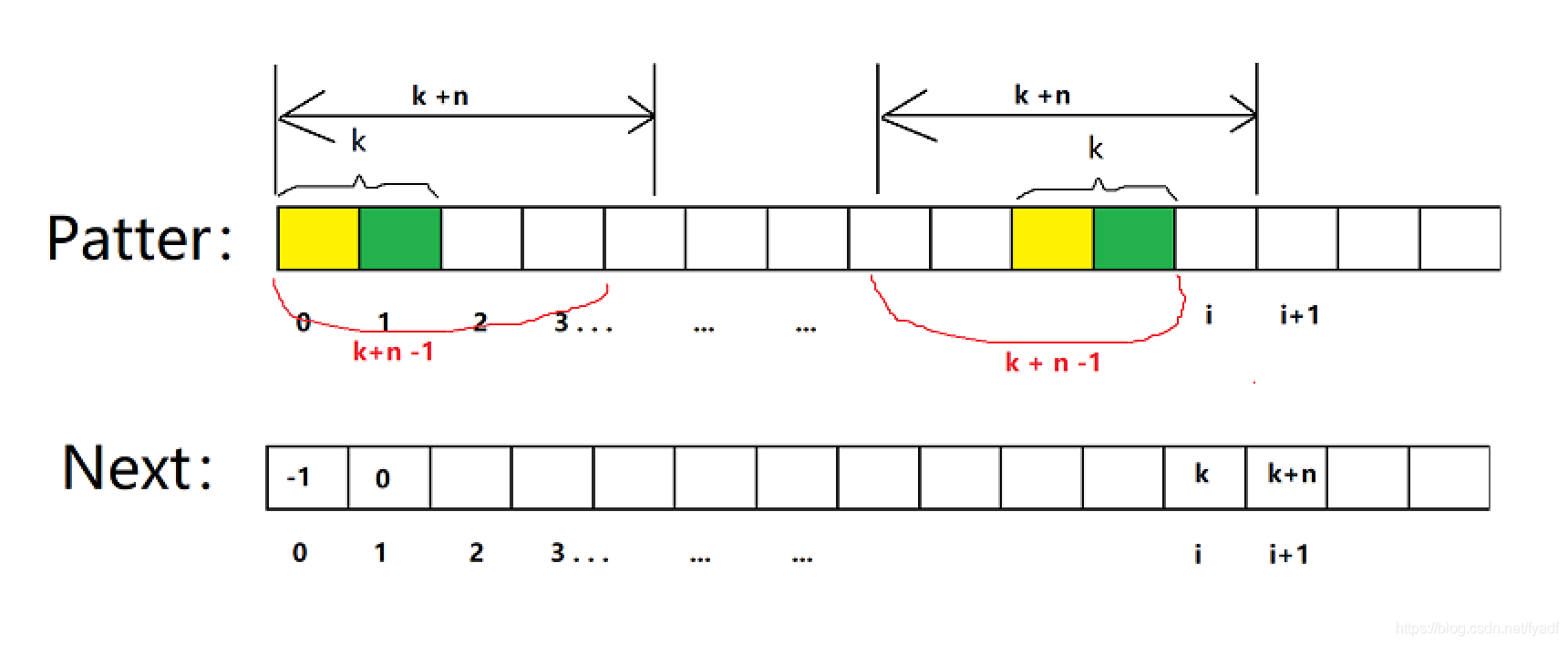
因為next[i + 1] = k + n,所以前后k+n段相等,所以k+n-1段也相等,因為n>1且n為整數,所以k+n-1 > k,所以next[i] > k與next[i]=k矛盾,所以next[i+1] <= next[i]+1,證明完畢, 所以next陣列的值最多只能以加1的速度增長,
如果已知next[i]=k,怎么計算next[i+1]呢:
因為next[i]=k,所以前綴k個字符和后綴k個字符相等,所以第k+1個字符的下標正好是k,這點也很重要,有助于理解代碼
情況1:P[k] == P[i],因為next[i]=k,所以前后k個區域相等,又因為P[k] == P[i],所以next[i]=k+1,
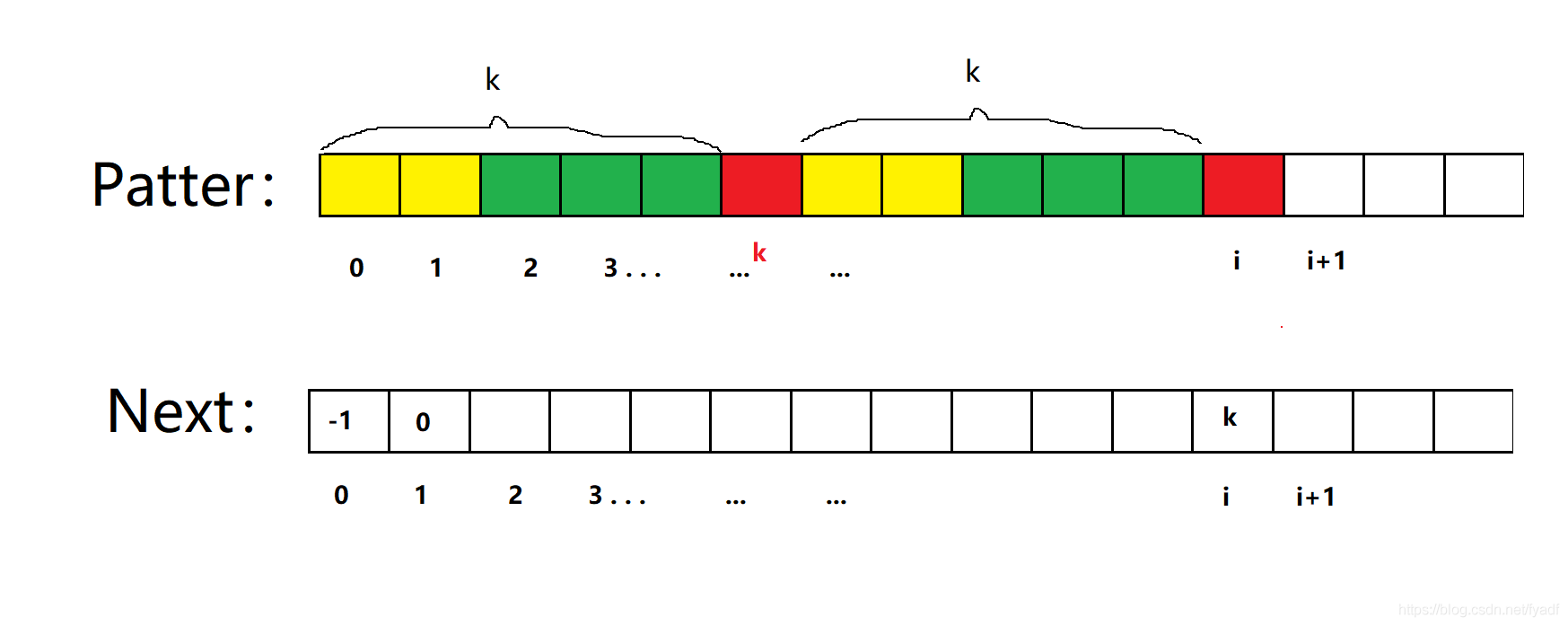
情況2:P[k] !=P[i](最難理解的部分)
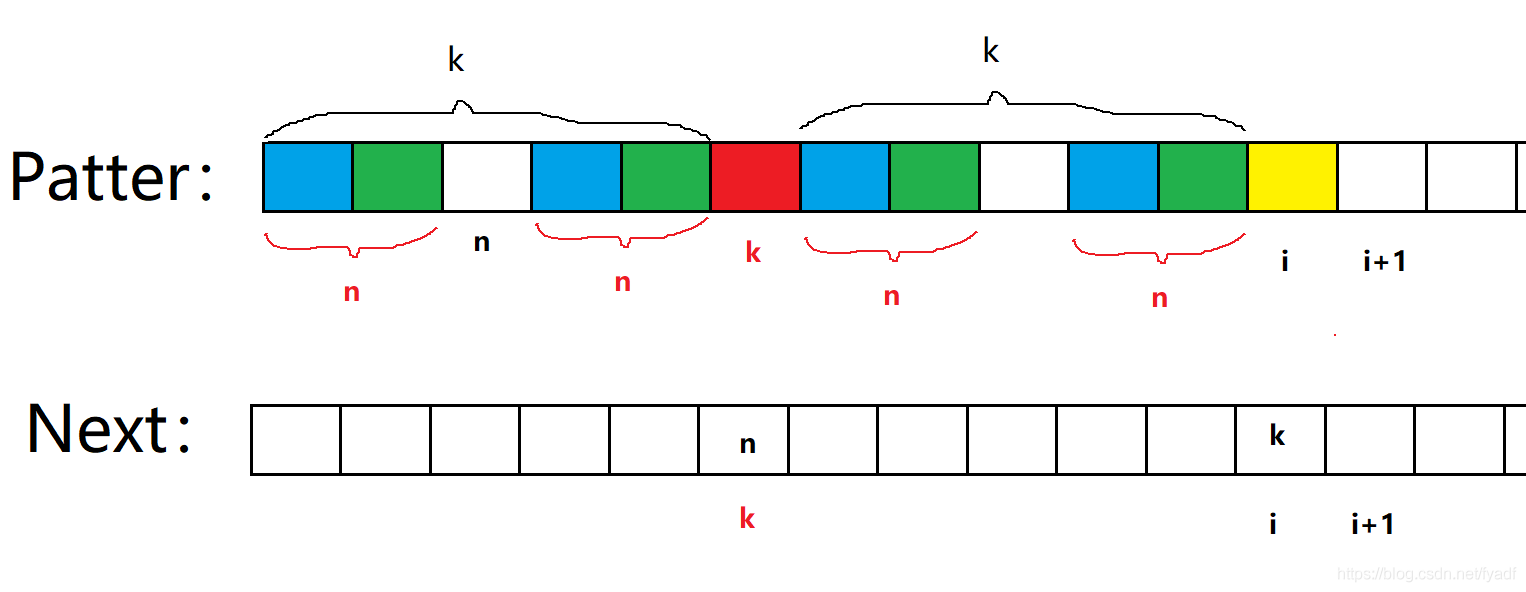
假設next[k] = n,因為next[i]=k,所以前后k個區域已經相等,如圖所示,同時因為next[k]=n,所以這4個n區域也相等,所以先判斷P[i]和P[n]是否相等,如果相等,next[i+1]就等于n+1,如果不相等,那我們按照這個思路繼續往前回溯,找到next[n]的位置,如果一直找不到,最侄訓回到next[0]的位置,此時我們令next[i+1]=0,這也就是代碼中k = next[k]的解釋,
void GetNext(const char* pattern, int* next)
{
//因為GetNext函式是在KMP函式中呼叫,在KMP中已經判斷過空指標的情況,
//因此這里就不再判斷
int len = strlen(pattern); //模式串長度
next[0] = -1; //next[0]設為-1
int i = 0;
int k = -1; //因為next[0]為-1,k的初始值設為-1
while (i < len- 1)
{
if (k < 0 || pattern[i] == pattern[k]) //如果k回溯到了-1,或者pattern[i] == pattern[k],則將k和i向后移動
{
//k++, i++;
next[++i] = ++k; //因為下標k也是next[i]的值,當滿足if條件時,next[i+1] == next[i]+1
}
else k = next[k]; //當不滿足條件時,對k進行回溯,解釋見博客正文部分
}
}
四、KMP演算法實作
理解了next陣列,KMP演算法就已經完成了一大半了,下面直接上代碼
int KMP(const char* text, const char* pattern)
{
if (text == NULL || pattern == NULL) return -1; //判斷空指標情況
int Tlen = strlen(text); //text字串長度
int Plen = strlen(pattern); //模式串長度
if (Tlen == 0 || Plen == 0)return -1; //規定如果模式串長度為0,則回傳-1
if (Tlen < Plen) return -1; //如果文本字符長度小于模式串字符長度,一定不能匹配成功回傳-1
int* next = malloc(sizeof(int) * Plen); //創建next陣列
if (next == NULL) //列印錯誤資訊
perror("next創建失敗");
GetNext(pattern, next); //求next陣列
int ti = 0, pi = 0; //ti,pi分別為文本串和模式串的指標
while (ti < Tlen && pi < Plen)
{
if (pi < 0 || text[ti] == pattern[pi]) //如果pi<0,表示回溯到了模式串首端,只能從頭進行匹配(只回溯pi)
{ //如果當前位置匹配成功,將ti和pi都后移
ti++;
pi++;
}
else
{
pi = next[pi]; //匹配失敗,對pi回溯
}
}
free(next);
//回圈結束時,ti == tlen || pi == plen ,如果pi == plen表示匹配完成,回傳起始匹配位置下標,否則回傳-1
return pi == Plen ? ti - Plen : -1;
}
總結
KMP演算法真的很難理解,如果文中有不足之處還請之處,同時也希望我的文章能給你帶來幫助,創作不易,花了很長時間總結的博客,給個三連吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287133.html
標籤:其他