作業筆記
Spark SQL 淺學筆記1
前面提到:Hive是將SQL轉為MapReduce,而SparkSQL可以理解成是將SQL決議成RDD + 優化再執行
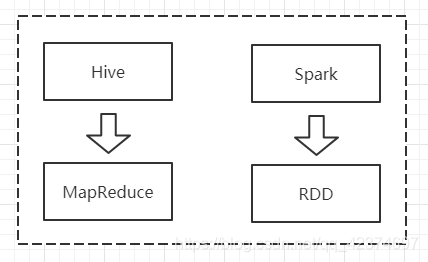
對于開發人員來講,SparkSQL 可以簡化 RDD 的開發,提高開發效率,且執行效率非常快,所以實際作業中,基本上采用的就是> SparkSQL,Spark SQL 為了簡化 RDD 的開發,提高開發效率,提供了 2 個編程抽象,類似 Spark Core 中的RDD
? DataFrame
? DataSet
Spark 中的模塊
參考圖片:https://zhuanlan.zhihu.com/p/61631248
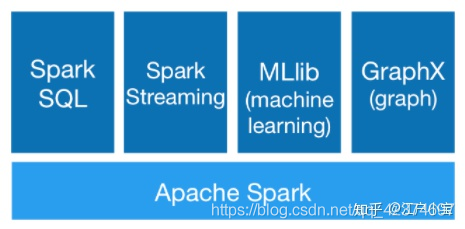
底層是Spark-core核心模塊,Spark-core的核心抽象是RDD,Spark SQL等都基于RDD封裝了自己的抽象,例如在Spark SQL中是DataFrame/DataSet,
相對來說RDD是更偏底層的抽象,DataFrame/DataSet是在其上做了一層封裝,做了優化,使用起來更加方便,從功能上來說,DataFrame/DataSet能做的事情RDD都能做,RDD能做的事情DataFrame/DataSet不一定能做,
SparkSQL 特點
-
易整合:無縫的整合了 SQL 查詢和 Spark 編程
-
統一的資料訪問:使用相同的方式連接不同的資料源
-
兼容 Hive:在已有的倉庫上直接運行 SQL 或者 HiveQL
-
標準資料連接:通過 JDBC 或者 ODBC 來連接
DataFrame
在 Spark 中,DataFrame 是一種以 RDD 為基礎的分布式資料集,類似于傳統資料庫中的二維表格,(除了資料以外,還記錄資料的結構資訊,即schema)
DataFrame 與 RDD 的主要區別在于,
DataFrame 帶有 schema 元資訊,即 DataFrame所表示的二維表資料集的每一列都帶有名稱和型別,這使得 Spark SQL 得以洞察更多的結構資訊,從而對藏于 DataFrame 背后的資料源以及作用于 DataFrame 之上的變換進行了針對性的優化,最終達到大幅提升運行時效率的目標,
反觀 RDD,由于無從得知所存資料元素的具體內部結構,Spark Core 只能在 stage 層面進行簡單、通用的流水線優化,
簡言之:
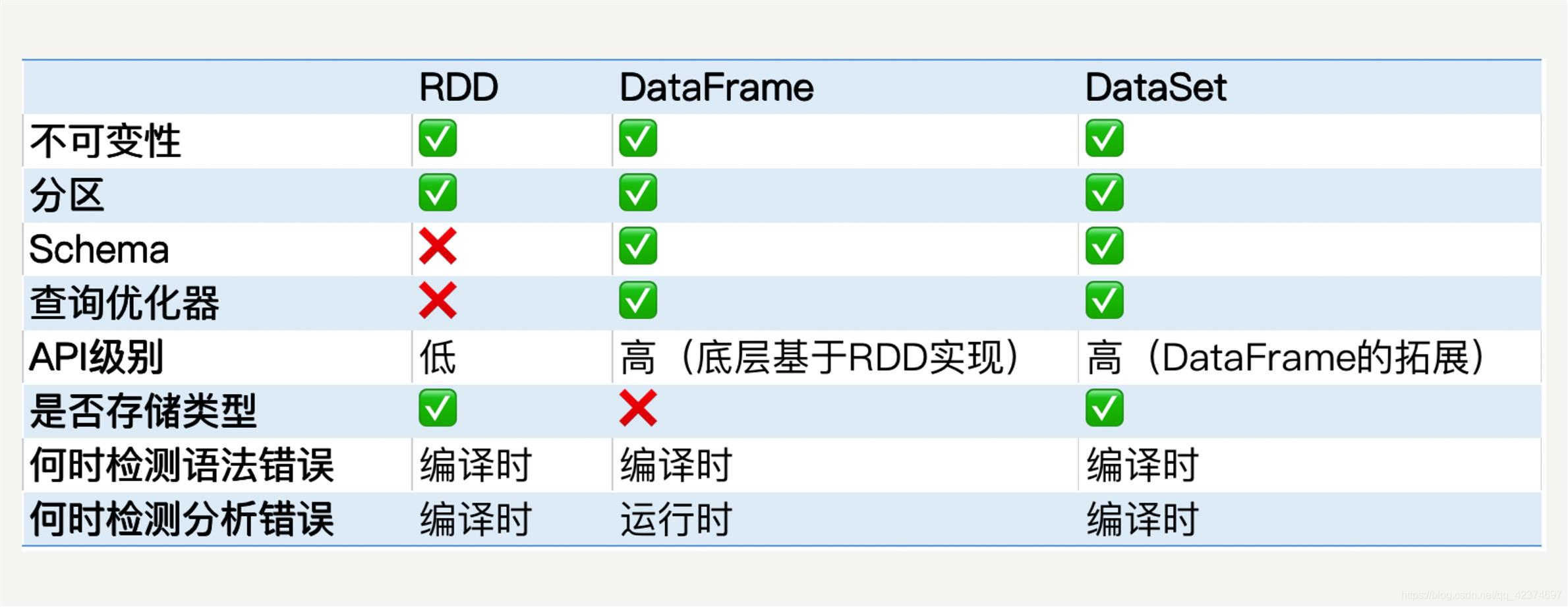
RDD中沒有schema資訊,而DataFrame中資料每一行都包含schema
DataFrame = RDD[Row] + shcema
同時,與 Hive 類似,DataFrame 也支持嵌套資料型別(struct、array 和 map),從 API易用性的角度上看,DataFrame API 提供的是一套高層的關系操作,比函式式的 RDD API 要更加友好,門檻更低,
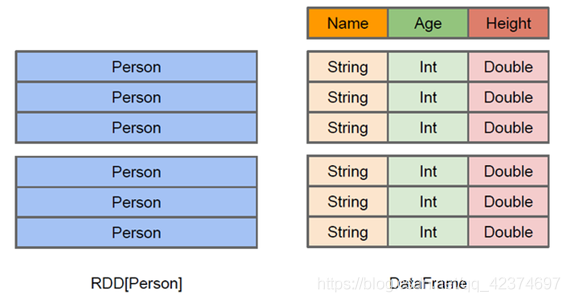
左側的 RDD[Person]雖然以 Person 為型別引數,但 Spark 框架本身不了解 Person 類的內部結構,
而右側的 DataFrame 卻提供了詳細的結構資訊,使得 Spark SQL 可以清楚地知道該資料集中包含哪些列,每列的名稱和型別各是什么,
DataFrame 是為資料提供了 Schema 的視圖,可以把它當做資料庫中的一張表來對待
DataFrame 也是懶執行的,但性能上比 RDD 要高,主要原因:優化的執行計劃,即查詢計劃通過 Spark catalyst optimiser 進行優化,
DataSet
DataSet 是分布式資料集合,DataSet 是 Spark 1.6 中添加的一個新抽象,是 DataFrame的一個擴展,
它提供了 RDD 的優勢(強型別,使用強大的 lambda 函式的能力)以及 SparkSQL 優化執行引擎的優點,DataSet 也可以使用功能性的轉換(操作 map,flatMap,filter等等),
? DataSet 是 DataFrame API 的一個擴展,是 SparkSQL 最新的資料抽象
?與RDD相比,保存了更多的描述資訊,概念上等同于關系型資料庫中的二維表,
? 用戶友好的 API 風格,既具有型別安全檢查也具有 DataFrame 的查詢優化特性;
? 用樣例類來對 DataSet 中定義資料的結構資訊,樣例類中每個屬性的名稱直接映射到DataSet 中的欄位名稱;
?與DataFrame相比,DataSet 保存了型別資訊, 是強型別的,比如可以有 DataSet[Car],DataSet[Person],提供了編譯時型別檢查,
? DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通過 as 方法將DataFrame 轉換為 DataSet,Row 是一個型別,跟 Car、Person 這些的型別一樣,所有的表結構資訊都用 Row 來表示,獲取資料時需要指定順序
參考:Spark中DataSet的基本使用
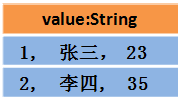
1.假設RDD中的兩行資料長這樣:

2.那么DataFrame中的資料長這樣

RDD中沒有schema資訊,而DataFrame中資料每一行都包含schema
DataFrame = RDD[Row] + shcema
RDD 轉 DataFrame 實際就是加上結構資訊
DataFrame 轉換為普通RDD 就比較簡單了,直接去掉結構資訊就行了,但是轉換不回原來結構,直接轉為RDD[row]型別了
3.那么Dataset中的資料長這樣(每行資料是個Object):
或者長這樣(每行資料是個Object):

DataSet包含了DataFrame的功能,Spark2.0中兩者統一,DataFrame表示為DataSet[Row],即DataSet的子集,
RDD、DataFrame、DataSet的區別
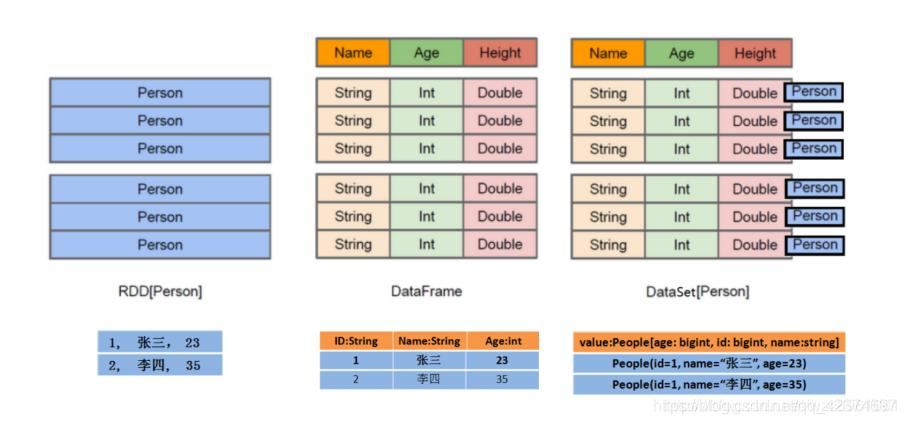
(1)RDD[Person]以Person為型別引數,但不了解其內部結構,
(2)DataFrame提供了詳細的結構資訊schema列的名稱和型別,這樣看起來就像一張表了
(3)DataSet[Person]中不光有schema資訊,還有型別資訊
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287345.html
標籤:其他