Flink原理學習之 視窗和時間
文章目錄
- Flink原理學習之 視窗和時間
- 一、Flink的時間型別
- 二、Watermark
- 三、Flink視窗機制
Java、大資料開發學習要點(持續更新中…)
一、Flink的時間型別
Flink的時間語意分為三種:
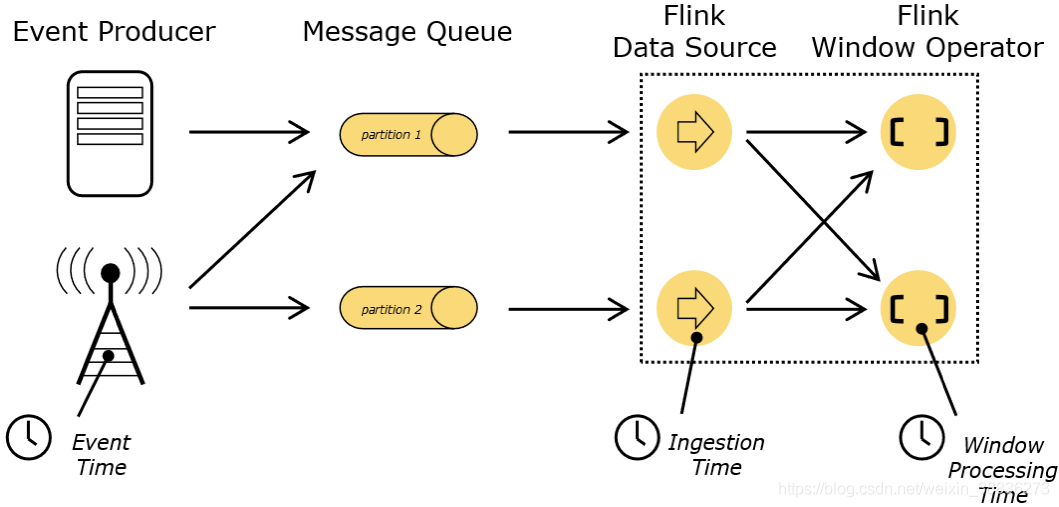
- Event Time:即事件時間,是事件真正發生的時間,一旦確定就不會發生變化,它通常由事件中的時間戳描述,例如采集的日志資料中,每一條日志都會記錄自己的生成時間,Flink通過時間戳分配器訪問事件時間戳,
- Processing Time:即處理時間,是每一個執行基于時間操作的算子的本地系統時間,與機器相關,因此多次執行結果會不同,默認的時間屬性就是Processing Time,
- Ingestion Time:即攝取時間,是資料進入Flink的時間,攝取時間也無法避免Flink例外重啟后資料處理的不準確問題,
一般來說Event Time才是事件真正的時間,也是Flink最大的特點之一,一般業務都是使用事件時間,像Processing Time,會產生多次計算結果不同的問題,也會因為資料延遲到達服務端而產生統計不準確的問題(Spark Streaming就是使用Processing Time),
二、Watermark
??Watermark用于在EventTime下處理亂序事件,而正確處理亂序事件,通常通過Watermark和視窗來實作,亂序是由于網路、分布式等原因產生的,而亂序不經處理則會影響視窗資料統計的準確性,
??Watermark也可以理解成一個延遲觸發機制,我們可以設定Watermark的延時時長t,每次系統會校驗已經到達的資料中最大的maxEventTime,然后認定eventTime小于maxEventTime - t的所有資料都已經到達(實際是否真到了并不知道),如果有視窗的停止時間等于maxEventTime – t,那么這個視窗被觸發執行,
??Watermark是Source通過一定策略(一般選擇周期性)插入資料流并向下傳遞的,Watermark = maxEventTime - 最大延遲時間,一旦Watermark大于視窗結束時間,觸發視窗計算的執行,由此可見,Watermark在資料流中是非減的,而如果出現Group By、Union等多個資料流匯集的算子,產生了多個Watermark匯集的情況,為了保證Watermark的遞增和資料的完整性,那么該算子會保留最小的Watermark,并發送給下游,
三、Flink視窗機制
??流式計算是一種被設計用于處理無限資料集的資料處理引擎,而無限資料集是指一種不斷增長的本質上無限的資料集,而Window是一種切割無限資料為有限塊進行處理的手段,Window將一個無限的流拆分成有限大小的buckets,我們可以在這些桶上做計算操作,
Window可以分成兩類:
- CountWindow:按照指定的資料條數生成一個Window,與時間無關,
- TimeWindow:按照時間生成Window【可以根據視窗實作原理的不同分成三類:滾動視窗(Tumbling Window)、滑動視窗(Sliding Window)和會話視窗(Session Window)】
- 滾動視窗:時間對齊,視窗長度固定,沒有重疊,
- 滑動視窗:時間對齊,視窗長度固定,可以有重疊,在這種情況下同一個元素可能會被分配到多個視窗中,
- 會話視窗:時間無對齊,一個視窗在一段時間未接受到資料后將會關閉,下次資料到來則開啟一個新的視窗,(類似會話機制)
Window Function 定義了要對視窗中收集的資料做的計算操作,主要可以分為兩類:
-
增量聚合函式:
每條資料到來就進行計算,保存一個簡單的狀態,典型的增量聚合函式有ReduceFunction, AggregateFunction, -
全視窗函式:
先把視窗所有資料收集起來,等到計算的時候會遍歷所有資料,ProcessWindowFunction就是一個全視窗函式,由上可知,視窗的資料都是保存在狀態中的,并且視窗的容錯機制靠狀態的checkpoint機制實作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287346.html
標籤:其他
上一篇:Spark SQL 淺學筆記2
下一篇:Git的基本命令(學習筆記)