大資料
- 第一章
- 大資料問題的定義和來源 P3-5
- 大資料問題的特點 P7-9
- 大資料應用四大層面的關鍵技術 P15
- 大資料四大計算模式:除圖計算外詳細了解 P16
- 云計算的概念,物聯網的概念,云計算與物聯網之間的關系 P18-19,21-22,26
- 第三章
- HDFS的本質:分布式檔案系統
- 塊的概念和優勢P46
- 名稱節點和資料節點的定義P46-47
- 第二名稱節點的意義和作業原理P47
- 冗余存盤的具體實作方法和優勢P50-51
- 資料存放策略和原因P51,資料讀取與復制P52
- HDFS中三種可能的錯誤和恢復方法 P52
- 第四章 HBASE
- HBASE與傳統資料庫的對比 P64-65
- HBASE的資料模型概念、資料坐標P66-68
- HBASE列式存盤的基本模型 P70 圖4-4
- HBASE的三層結構 P73
- HBASE的系統結構與客戶端、Zookeeper服務器、Master服務器、Region服務器功能P74-75
- 第五章 NoSQL資料庫
- NoSQL資料庫三大特點 P94-95
- 關系型資料庫不滿足Web2.0應用的三大原因 P96
- 四大型別NOSQL資料庫名稱與特點P99-101
- NoSQL三大基石:CAP的定義,CAP三種選擇兩種的實作方法P102-103
- NoSQL四大特性:BASE定義 P104
- 第七章 MapReduce
- Map與Reduce的基本定義P133表7-1
- MapReduce基本作業流程 P134
- 使用combiner與不使用combiner時的MapReduce執行Wordcount的基本流圖 P141-142 圖7-7、8、9
- 使用MapReduce進行自然連接運算流程 P143
- 第九章 Spark
- Spark相比Hadoop的核心優勢,核心優勢的實作方法P174
- RDD轉換操作、行動操作、惰性呼叫與DAG構建 P180
- 常用RDD API P188表9-2 9-3
- Spark面向不同功能的組件 P176
- 第十章 流計算
- 流資料的特點P195
- 靜態資料分析與流資料處理的不同(批處理與流計算)P199
- 流計算的概念,MapReduce為什么不適用于流計算
- 流計算的資料處理流程 P198
- Storm的基本設計思想 (Spouts Bolts Topology)P202
- Spark Streaming的基本設計思想 P207
第一章
大資料問題的定義和來源 P3-5
1.存盤設備容量不斷增加,
2.CPU處理能力大幅度提升,
3.網路帶寬不斷增加,
大資料問題的特點 P7-9
1.資料量大,
2.資料型別繁多,包括結構化資料和非結構化資料,
3.處理速度快,大資料時代的很多應用都需要基于快速生產的資料給出實時分析結果,用于指導生產和生活實踐,
4.價值密度低,
大資料應用四大層面的關鍵技術 P15
1.資料采集與預處理,
2.資料的存盤和管理
3.資料處理和分析
4.資料安全和隱私保護
大資料四大計算模式:除圖計算外詳細了解 P16
1.批處理計算 :批處理計算主要解決針對大規模資料的批量處理,也是我們日常資料分許作業中非常常見的一類資料處理需求,
2.流計算 :流資料(或資料流)是指在時間分布和數量上無限的一系列動態資料的集合體,資料的價值隨著時間的流逝而降低,因此必須采用實時計算的方式給出秒級回應,
3.圖計算
4.查詢分析計算 :針對超大規模資料的存盤管理和查詢分析,需要提供實時或準實時的回應,才能很好地滿足企業經營管理需求,
云計算的概念,物聯網的概念,云計算與物聯網之間的關系 P18-19,21-22,26
1.云計算的概念
云計算實作了通過網路提供可伸縮的、廉價的分布式計算能力,用戶只需要在具備網路接入條件的地方,就可以隨時隨地獲得所需的各種IT資源,云計算代表了以虛擬化為核心、以低成本為目標的、動態可擴展的網路應用基礎設施,是近年最有代表性的網路計算計算與模式,
2.物聯網的概念
物聯網是物物相連的互聯網,是互聯網的延申,它利用區域網路或互聯網等通信技術把傳感器、控制器、機器、人員和物等通過新的方式連在一起,形成人與物、物與物相連,實作資訊化和遠程管理控制,
3.聯系
P26 第二段
第三章
HDFS的本質:分布式檔案系統
塊的概念和優勢P46
在傳統的檔案系統中,為了提高磁盤讀寫效率,一般以資料塊為單位,而不是以位元組為單位,
因此,以塊為單位讀寫資料,可以把磁盤尋道時間分攤到大量資料中,
HDFS也同樣采用了塊的概念,默認一個塊的大小是64MB,這么做的原因,是為了最小化尋址開銷,
好處:
1.支持大規模檔案存盤
2.簡化系統設計
3.適合資料備份
名稱節點和資料節點的定義P46-47
1.名稱節點(NameNode)負責管理分布式檔案系統的命名空間,保存了兩個核心的資料結構,即FsImage和EditLog,FsImage用于維護檔案系統樹以及檔案樹中所有的檔案和檔案夾的元資料,操作日志檔案EditLog記錄了所有針對檔案的創建、重命名等操作,名稱節點記錄了每個檔案中各個塊所在的資料節點為位置資訊(相當于一個資料目錄),但是并不持久化存盤這些資訊,而是在系統每次啟動時掃描所有資料節點重構得到這些資訊,
2.資料節點(DataNode)是分布式檔案系統HDFS的作業節點,負責資料的存盤和讀取,會根據客戶端或者名稱節點的調度來進行資料的存盤和檢索,并且向名稱節點定期發送自己所存盤的塊的串列,
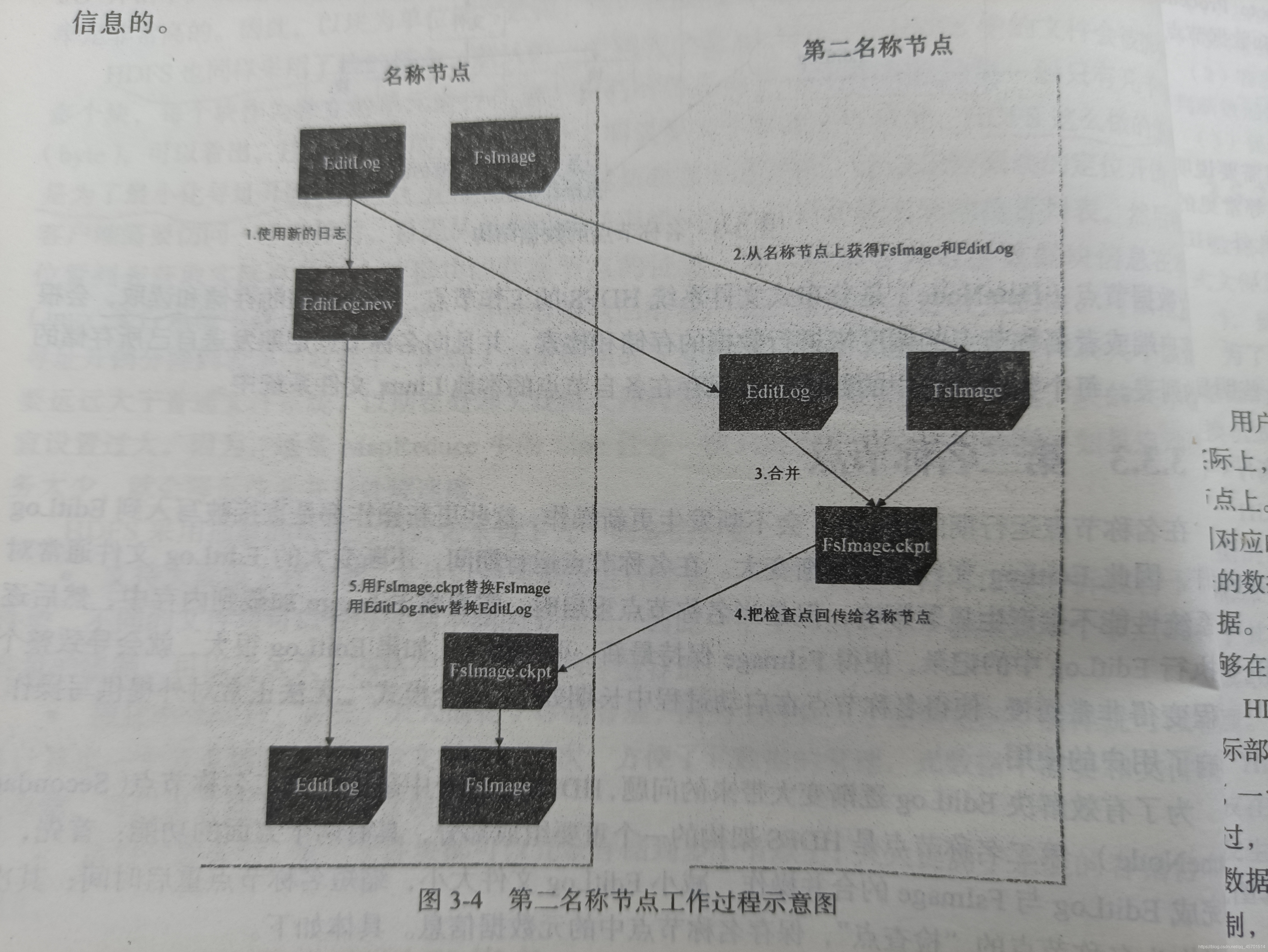
第二名稱節點的意義和作業原理P47
冗余存盤的具體實作方法和優勢P50-51
具體實作方法: 作為一個分布式檔案系統,為了保證系統的容錯性和可用性,HDFS采用了多副本方式對資料進行冗余存盤,通常一個資料塊的多個副本會被分布到不同的資料節點上,
優勢:
1.加快資料傳輸速度,當多個客戶端需要同時訪問一個檔案時,可以讓多個客戶端分別從不同的資料塊副本中讀取資料,這就大大加快了資料的傳輸速度,
2.容易檢查資料錯誤,HDFS的資料節點之間通過網路傳輸資料,采用多個副本可以容易判斷資料傳輸是否出錯,
3.保證資料的可靠性,即使某個資料節點出現故障失效,也不會造成資料的丟失,
資料存放策略和原因P51,資料讀取與復制P52
1.資料存放策略:為了提高資料的可靠性于系統的可用性,以及充分利用網路帶寬,HDFS采用了以機架為基礎的資料存放策略,
原因:首先,可以獲得很高的資料可靠性,即使一個機架發生故障,位于其他機架上的資料副本仍然可用的,其次,在讀取資料的時候,可以在多個機架上并行的處理資料,大大提高了資料讀取速度;最后,可以更容易地實作系統內部負載均衡和錯誤處理,
2.資料讀取
HDFS提供了一個API可以確定一個資料節點所屬地機架ID,客戶端也可以呼叫API獲取自己所屬地機架ID,當客戶端讀取資料時,從名稱節點獲得資料塊不同副本地存放位置串列,串列中包含了副本所在的資料節點,可以呼叫API來確定客戶端和這些資料節點所屬的機架ID,當發現某個資料塊副本對應的機架ID和客戶端對用的機架ID相同時,就優先選擇該副本讀取資料,如果沒有發現,就隨機選擇一個副本讀取資料,
3.資料復制
HDFS的資料復制采用了流水線復制的策略,大大提高了資料復制程序的效率,
HDFS中三種可能的錯誤和恢復方法 P52
1.名稱節點出錯
恢復:第一,把名稱節點上的元資料資訊同步存盤到其他檔案系統中;第二,運行一個第二名稱節點,當名稱節點宕機以后,可以把第二名稱節點作為一種彌補措施,利用第二名稱節點的元資料資訊進行系統恢復,但是從前面對第二名稱節點的介紹中可以看出,這樣做仍然會丟失部分資料,因此,一般會把上述兩種方法結合使用,當名稱節點發生宕機時,首先到遠程掛載的網路檔案系統中獲取備份的元資料資訊,放到第二名稱節點上進行恢復,并把第二名稱節點作為名稱節點來使用,
2.資料節點出錯
恢復:每個資料節點會定期向名稱節點發送“心跳”資訊,向名稱節點報告自己的狀態,發生宕機,一般使用冗余復制成為新副本,
3.資料出錯
第四章 HBASE
HBASE與傳統資料庫的對比 P64-65
1.資料型別, 關系資料庫采用關系模型,具有豐富的資料型別和存盤方式,HBase采用更簡單的資料模型,它把資料存盤為未經解釋的字串,
2.資料操作, 關系資料庫中包含了豐富的操作,如插入、洗掉、更新、查詢等,其中會涉及到多表連接,HBase操作則不存在復雜的表與表之間的關系,只有簡單的插入、查詢、洗掉、清空等(沒有更新是因為HDFS檔案系統只允許在檔案后追加內容,而不允許修改),
3.存盤模式, 關系資料庫基于行模式存盤,HBase基于列存盤,
4.資料索引, 關系資料庫通常可以針對不同列構建復雜的多個索引以提高資料訪問性能,HBase只有一個索引—行鍵,
5.資料維護, 關系資料庫更新操作會覆寫掉原來的值,HBase的更新操作并不會洗掉資料舊的版本,二是生產一個新的版本,舊的版本仍然保留,
6.可伸縮性,
HBASE的資料模型概念、資料坐標P66-68
1.表
2.行
3.列族
4.列限定符
5.單元格
6.時間戳

對于我們熟悉的關系資料塊而言,資料定位可以理解為采用”二維坐標“,即根據行和列就可以確定表中一個確定的值,HBase中需要根據行鍵、列族、列限定符和時間戳來確定一個單格,即四維坐標{行鍵,列族,列限定符,時間戳}
根據上面表格,我們確定一個坐標,{”201505003”,“Info”,“email",“1174184620720”},可以確定這個單元格存盤的值為”you@163.com"
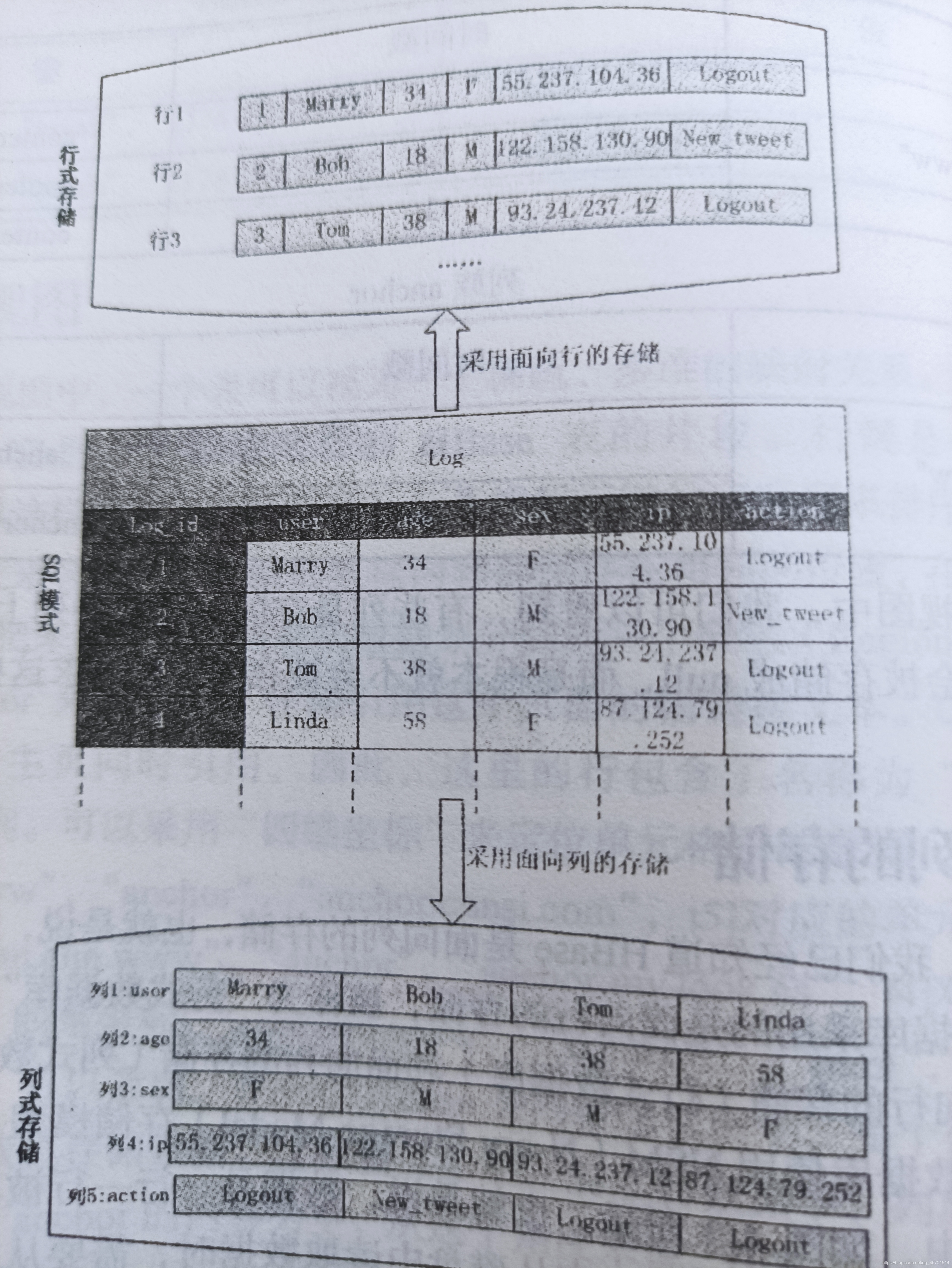
HBASE列式存盤的基本模型 P70 圖4-4
HBASE的三層結構 P73
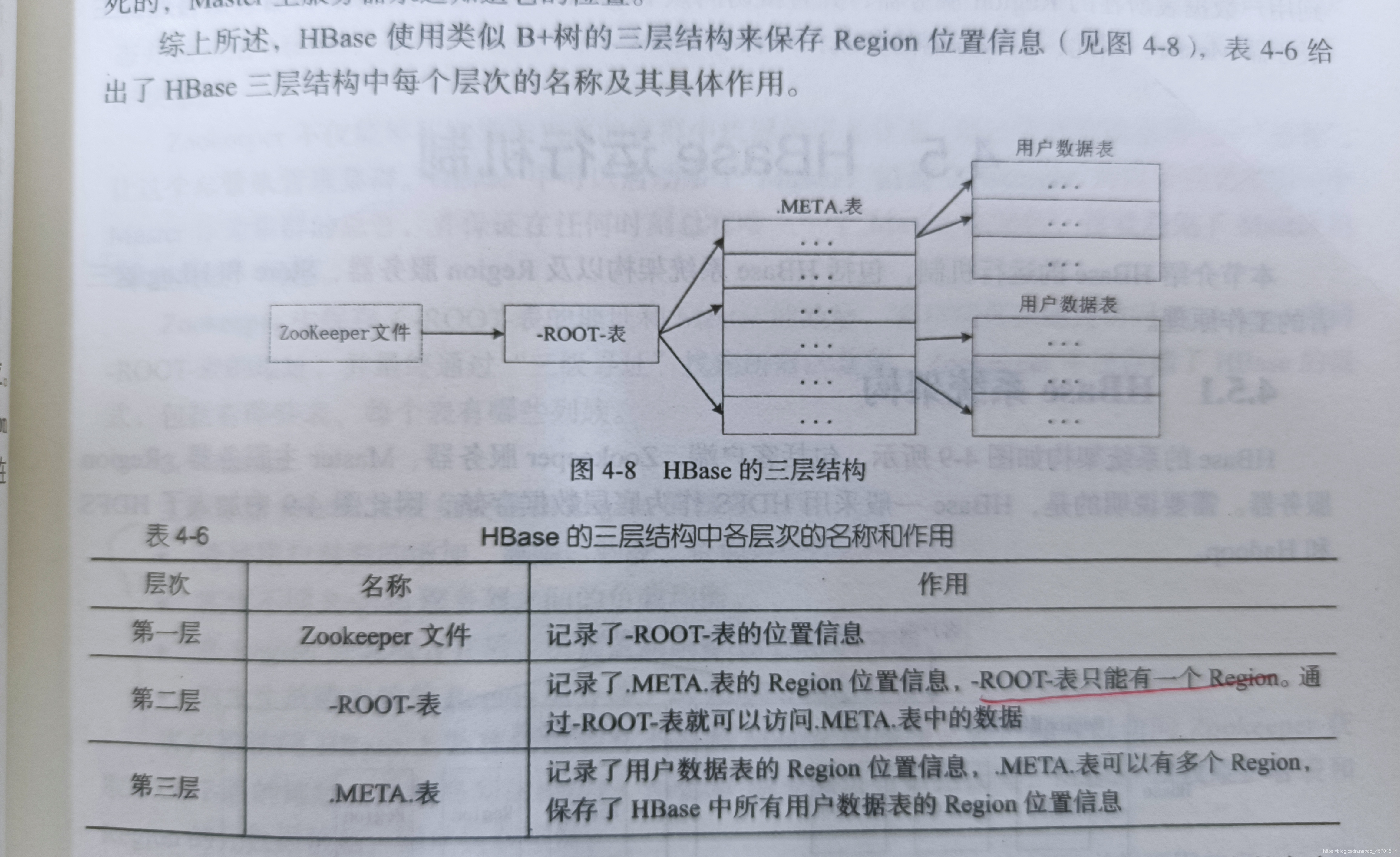
HBASE的系統結構與客戶端、Zookeeper服務器、Master服務器、Region服務器功能P74-75
第五章 NoSQL資料庫
NoSQL資料庫三大特點 P94-95
1.靈活的可擴展性
2.靈活的資料模型
3.與云計算緊密融合
關系型資料庫不滿足Web2.0應用的三大原因 P96
1.Web2.0網站系統通常不需要嚴格的資料庫事務,
2.Web2.0并不要求嚴格的讀寫實時性,
3.Web2.0通常不包括大量的復雜SQL查詢,
四大型別NOSQL資料庫名稱與特點P99-101
1.鍵值資料庫
鍵值資料庫會使用一個哈希表,這個表中有一個特定的Key和一個指標指向特定的Value.

2.列族資料庫
列族資料庫一般采用列族資料模型,資料庫由多個行構成,每個資料庫包含多個列族,不用的行可以具有不同數量的列族,屬于同一列族的資料會被存放在一起,
3.檔案資料庫
在檔案資料庫中,檔案是資料庫的最小單位,

4.圖資料庫
圖資料庫以圖論為基礎,一個圖是一個數學模型,用來表示一個物件集合,包括頂點以及連接頂點的邊,
NoSQL三大基石:CAP的定義,CAP三種選擇兩種的實作方法P102-103
- C(Consistenct):一致性,它是指任何一個讀操作總是能夠讀到之前完成的寫操作的結果,也就是分布式環境中,多點資料是一致的,
- A(Availability) :可用性,它是指快速獲取資料,可以在確定的時間內回傳結果,
- P(Tolerance of Network Partition):磁區容忍性,它是指當出現網路磁區的情況時,分離的系統也能夠正常運行,

NoSQL四大特性:BASE定義 P104
1.基本可用
基本可用是指一個分布式系統的一部分發生問題變得不可用時,其他部分仍然可以正常使用,也就是允許磁區失敗的情形出現,
2.軟狀態
“軟狀態”是與“硬狀態”相對應的一種提法,資料庫保存的資料是“硬狀態”時,可以保證資料的一致性,即保證資料一直是正確的,“軟狀態”是指狀態可以有一段時間不同步,具有一定的滯后性,
3.最終一致性
一致性的型別包括強一致性和弱一致性,二者的主要區別在于高并發的資料訪問操作下,后續操作是否能夠獲取最新資料,
第七章 MapReduce
Map與Reduce的基本定義P133表7-1

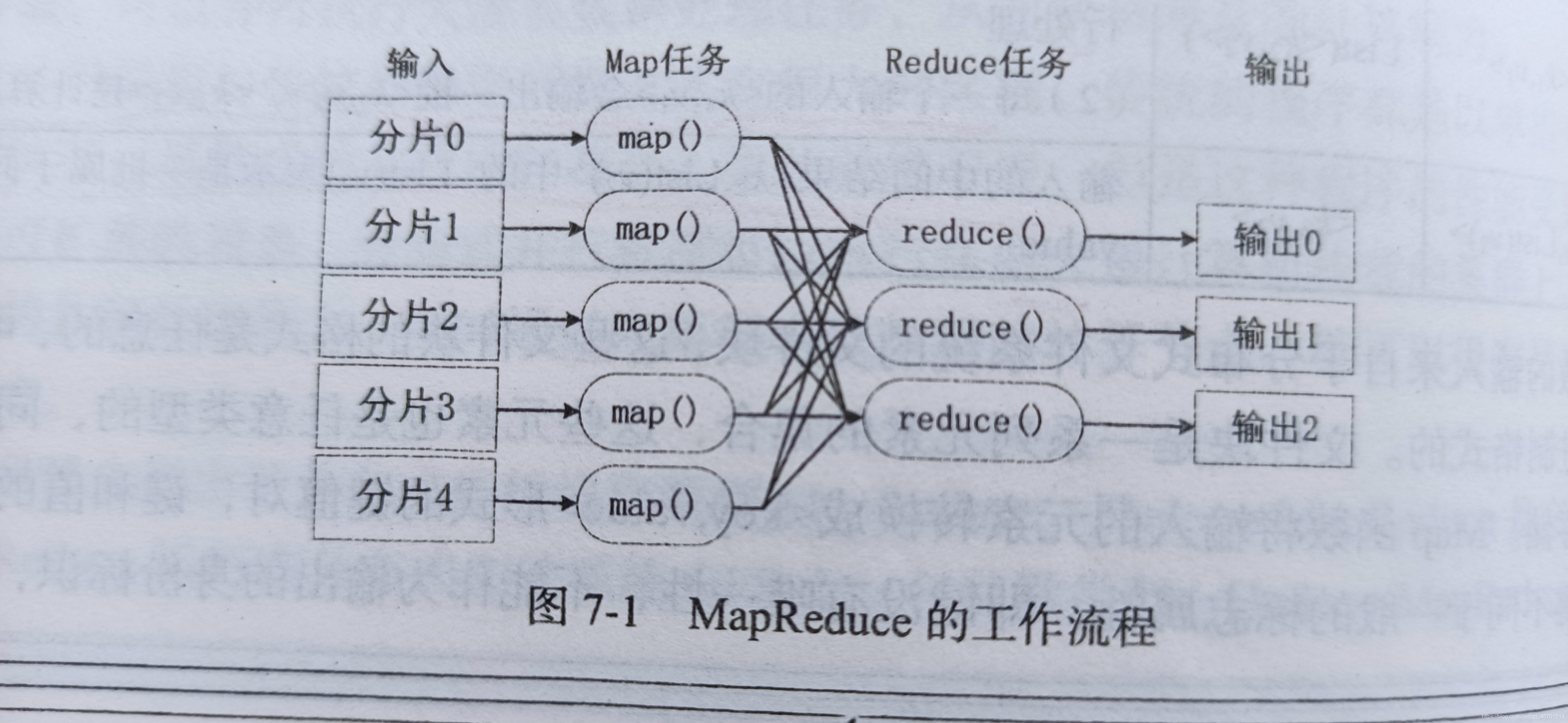
MapReduce基本作業流程 P134
MapReduce的核心思想是“分而治之”
1.就是把一個大的資料集拆分成多個小資料塊在多臺機器上并行處理,也就是說,一個大的MapReduce作業,首先拆分成多個小資料塊在多臺機器上并行執行,每個Map任務通常運行在資料存盤的節點上,這樣計算和資料就可以放在一起運行,不需要額外資料傳輸的開銷,
2.當Map任務結束后,會生成以<key,value>形式表示的許多中間結果,然后,這些中間結果會被分發到多個Reduce任務的多臺機器上并行執行,具有相同的key的<key,value>會被發送到一個Reduce任務哪里,Reduce任務會對中間結果進行匯總計算得到最后的結果,并輸出到分布式檔案系統中,
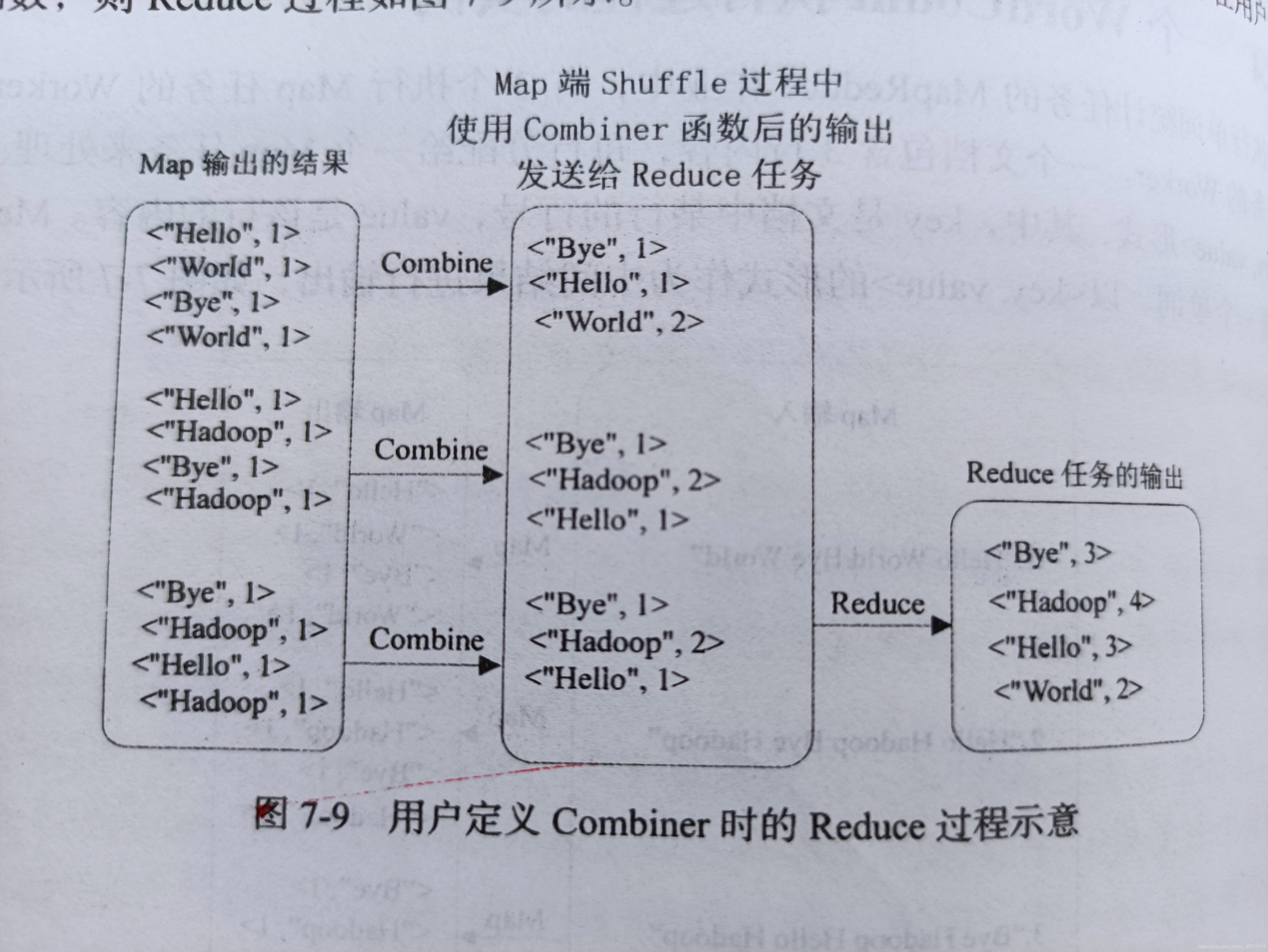
使用combiner與不使用combiner時的MapReduce執行Wordcount的基本流圖 P141-142 圖7-7、8、9
在這之前我們要理解一個概念:
合并是指combiner的程序,combiner是對重復的key合并在一起,減少冗余資訊,是對key的操作,
歸并是兩個有序檔案合并成一個有序檔案,是對檔案的操作,
1.map的程序,把每句話的單詞作為key,數量作為value

2.用戶沒有定義Combiner時的Reduce程序,就是進行了歸并,即具有相同key鍵值對會被歸并成一個新的鍵值對,鍵值對形式為<key,List(v)>(value變成一個集合了)
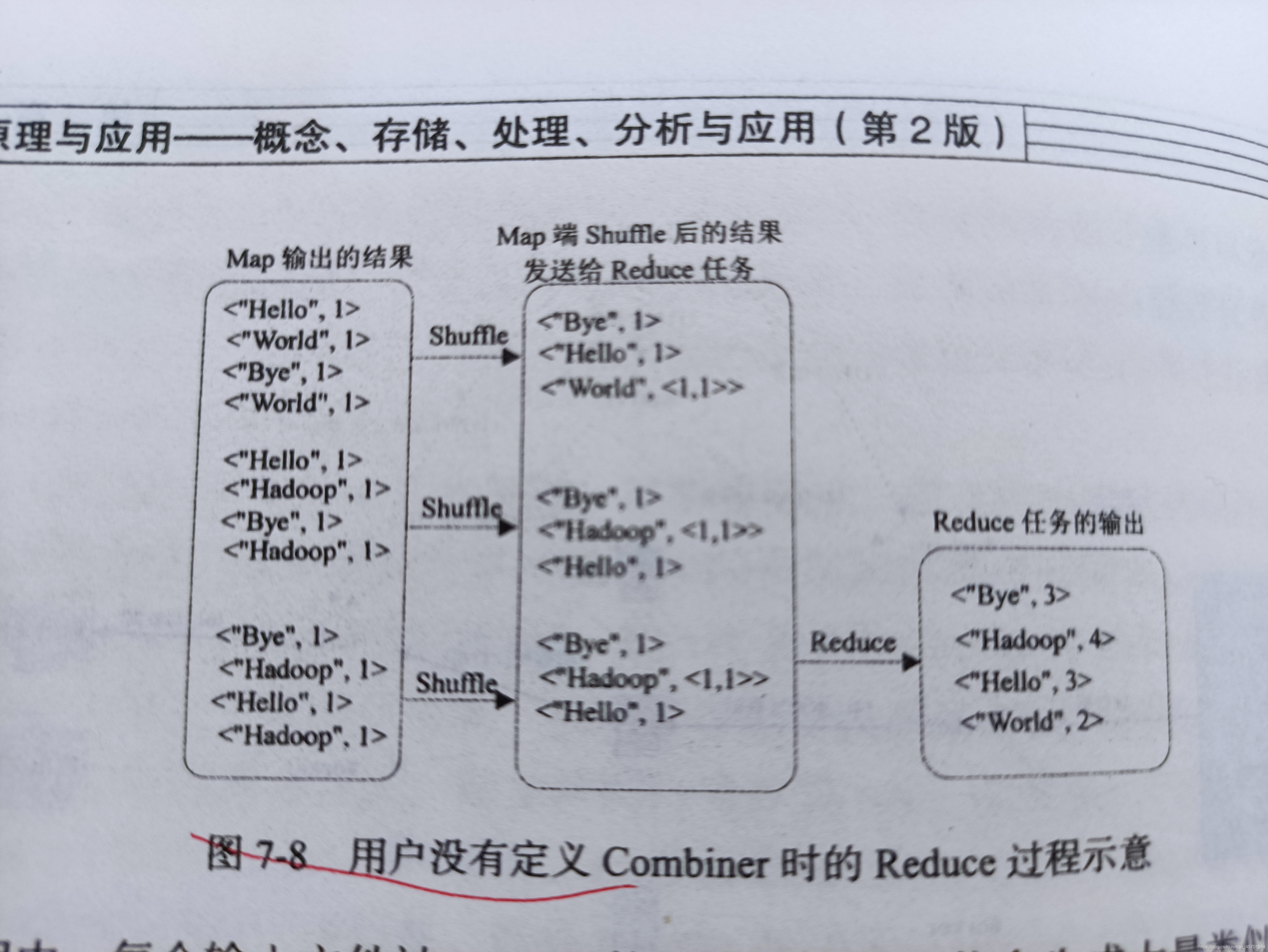
3.用戶進行了Combiner的操作,即合并
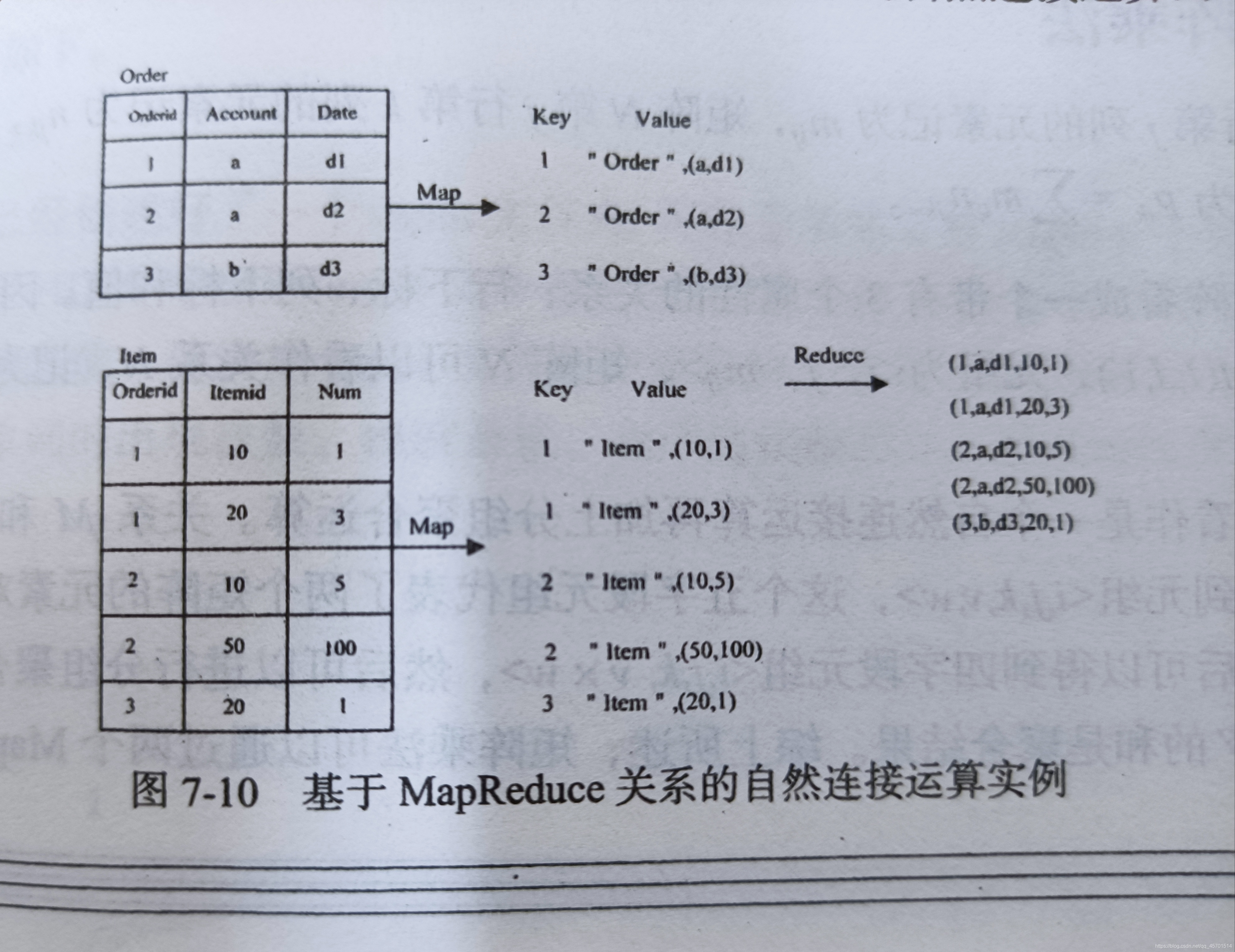
使用MapReduce進行自然連接運算流程 P143
1.首先將每個每張表轉換成<b,<S,c>>的形式,b就是兩張表需要連接的欄位的值,即圖中的Orderid欄位,S就是每張表的名字,如文中的一直張的名字 Order,c就是剩下欄位值的集合,如文中Order表的第一條記錄(a,d1)
如果把Order中的第一條記錄轉換成一個<key,value>,即 <1,<“Order”,(a,d1)>>
2.reduce,把表名為Order和Item具有共同屬性Orderid欄位進行合并,如圖所示,
第九章 Spark
Spark相比Hadoop的核心優勢,核心優勢的實作方法P174
1.Spark的計算模式也屬于MapReduce,但不局限與Map和Reduce操作,還提供了多種資料集操作型別,編程模型比MapReduce更靈活,
2.Spark提供了記憶體計算,中間結果直接放在記憶體中,帶來了更高的迭代運算效率,
3.Spark基礎DAG的任務調度機制,要優于MapReduce的迭代執行機制,
原因:使用Hadoop進行迭代計算非常耗資源,因為每次迭代都需要從磁盤中寫入、讀取中間資料,IO開銷大,而Spark將資料載入記憶體后,之后的迭代計算都可以直接使用記憶體中的中間結果作運算,避免了從磁盤中頻繁讀取資料,
RDD轉換操作、行動操作、惰性呼叫與DAG構建 P180
常用RDD API P188表9-2 9-3

Spark面向不同功能的組件 P176
1.Spark Core
Spark Core包含了Spark基本功能,如記憶體計算、任務調度、部署模式、故障恢復、存盤管理等,主要面對批資料處理場景,
2.Spark SQL
Spark SQL允許開發人員直接處理RDD,同時也可查詢Hive、HBase等外部資料源,Spark SQL的一個重要特點是其能夠統一處理關系表和RDD,使得開發人員不需要自己撰寫Spark應用程式,開發人員可以輕松使用你SQL命令進行查詢,并進行更復雜的資料分析,
3.Spark Streaming
Spark Streaming支持高吞吐量、可容錯處理的實時流資料處理,其核心思路是將流資料分解成一系列短小的批處理作業,每個短小的批處理作業都可以使用Spark Core進行快速處理,
4.MLlib(機器學習)
MLlib提供了常用機器學習演算法的實作,包括聚類、分類、回歸、協同過濾等,降低了機器學習的門檻,開發人員只需要具備一定的理論知識就能進行機器學習作業,
5.GraphX(圖計算)
GraphX是Spark中用于圖計算的API,可認為是Pregel在Spark上的重寫優化,GraphX性能良好,擁有豐富的功能和運算子,能在海量資料上自如地運行復雜地圖演算法,
第十章 流計算
流資料的特點P195
1.資料快速持續到達,潛在大小也許是無窮無盡地,
2.資料來源眾多,格式復雜,
3.資料量大,但是不十分關注存盤,一旦流資料中的某個元素經過處理,要么被丟棄,要么被歸檔存盤,
4.注重資料的整體價值,不過分關注個別資料,
5.資料順序顛倒,或者不完整,系統無法控制將要處理的新到達的資料元素順序,
靜態資料分析與流資料處理的不同(批處理與流計算)P199
1.流處理系統處理的是實時的資料,而傳統的資料處理系統處理的是預先存盤好的靜態資料,
2.用戶通過流處理系統獲取的是實時結果,而通過傳統的資料處理系統獲取的是過去某一時刻的結果,并且,流處理系統,無需用戶主動發出查詢,實時查詢服務可以主動將實時結果推送給用戶,
流計算的概念,MapReduce為什么不適用于流計算
MapReduce是用來離線處理大量批資料的,需要將中間結果存入磁盤,再將中間結果讀取,做不到實時回應結果,
流計算的資料處理流程 P198
1.資料實時采集
2.資料實時計算
3.實時查詢計算
Storm的基本設計思想 (Spouts Bolts Topology)P202
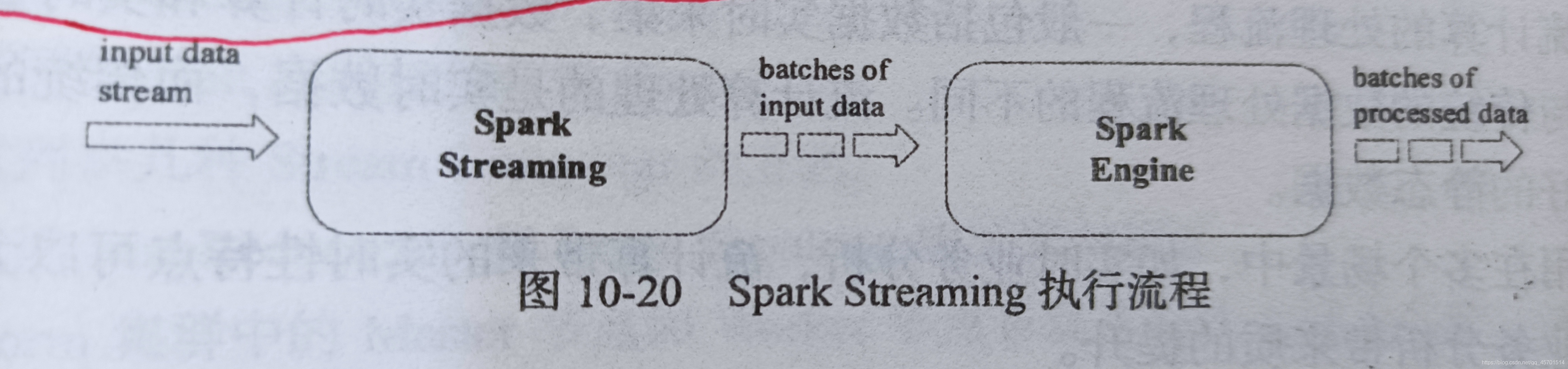
Spark Streaming的基本設計思想 P207
Spark Streaming的基本原理是將實時輸入資料流以時間片(秒級)為單位進行拆分,然后經Spark引擎以類似批處理的方式處理每個時間片資料
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287353.html
標籤:其他
下一篇:JMU軟體大資料技術復習提綱