近些年,隨著實時通信技術的發展,在線會議逐漸成為人們作業中不可或缺的重要辦公工具,據不完全統計,線上會議中約有 75% 為純語音會議,即無需開啟攝像頭和螢屏共享功能,此時會議中的語音質量和清晰度對線上會議的體驗便至關重要,
作者|七琦
審校|泰一
前言
在現實生活中,會議所處的環境是極具多樣性的,包括開闊的嘈雜環境、瞬時非平穩的鍵盤敲擊聲音等,這些對傳統的基于信號處理的語音前端增強演算法提出了很大的挑戰,與此同時伴隨著資料驅動類演算法的快速發展,學界 [1] 和工業界 [2,3,4] 逐漸涌現出了深度學習類的智能語音增強演算法,并取得了較好的效果,AliCloudDenoise 演算法在這樣的背景下應運而生,借助神經網路卓越的非線性擬合能力,與傳統語音增強演算法相結合,在不斷的迭代優化中,針對實時會議場景下的降噪效果、性能消耗等方面進行了一系列的優化與改進,最終可以在充分保證降噪能力的同時保有極高的語音保真度,為阿里云視頻云實時會議系統提供了卓越的語音會議體驗,
語音增強演算法的發展現狀
語音增強是指干凈語音在現實生活場景中受到來自各種噪聲干擾時,需要通過一定的方法將噪聲濾除,以提升該段語音的質量和可懂度的技術,過去的幾十年間,傳統單通道語音增強演算法得到了快速的發展,主要分為時域方法和頻域方法,其中時域方法又可以大致分為引數濾波法 [5,6] 和信號子空間法 [7],頻域方法則包括譜減法、維納濾波法和基于最小均方誤差的語音幅度譜估計方法 [8,9] 等,
傳統單通道語音增強方法具有計算量小,可實時在線語音增強的優點,但對非平穩突發性噪聲的抑制能力較差,比如馬路上突然出現的汽車鳴笛聲等,同時傳統演算法增強后會有很多殘留噪聲,這些噪聲會導致主觀聽感差,甚至影響語音資訊傳達的可懂度,從演算法的數學理論推導角度來說,傳統演算法還存在決議解求解程序中假設過多的問題,這使得演算法的效果存在明顯上限,難以適應復雜多變的實際場景,自 2016 年起,深度學習類方法顯著提升了許多監督學習任務的性能,如影像分類 [10],手寫識別 [11],自動語音識別 [12],語言建模 [13] 和機器翻譯 [14] 等,在語音增強任務中,也出現了很多深度學習類的方法,
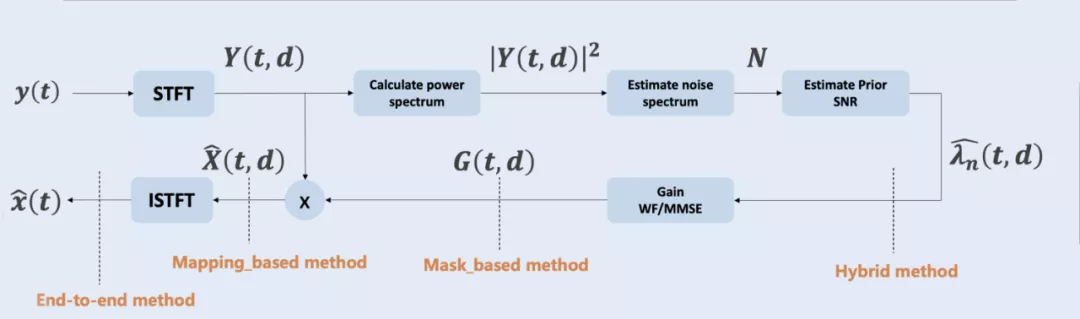
圖一 傳統單通道語音增強系統的經典演算法流程圖
基于深度學習類的語音增強演算法根據訓練目標的不同大致可分為以下四類:
? 基于傳統信號處理的混合類語音增強演算法(Hybrid method)
這類演算法多將傳統基于信號處理的語音增強演算法中的一個或多個子模塊由神經網路替代,一般情況下不會改變演算法的整體處理流程,典型代表如 Rnnoise[15],
? 基于時頻掩模近似的語音增強演算法(Mask_based method)
這類演算法通過訓練神經網路來預測時頻掩模,并將預測的時頻掩模應用于輸入噪聲的頻譜來重構純凈語音信號,
常用的時頻掩模包括 IRM[16],PSM[17], cIRM[18] 等,訓練程序中的誤差函式如下式所示:
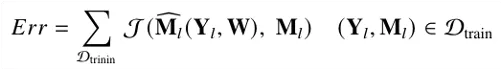
? 基于特征映射的語音增強演算法(Mapping_based method)
這類演算法通過訓練神經網路來實作特征的直接映射,常用的特征包括幅度頻譜、對數功率頻譜和復數頻譜等,訓練程序中的誤差函式如下式所示:
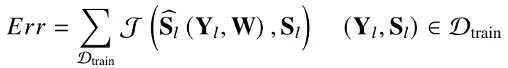
? 基于端到端的語音增強演算法(End-to-end method)
這類演算法將資料驅動的思想發揮到了極致,在資料集分布合理的前提下,拋卻頻域變換,直接從時域語音信號進行端到端的數值映射,是近兩年廣泛活躍在學術界的熱門研究方向之一,
AliCloudDenoise 語音增強演算法
一、演算法原理
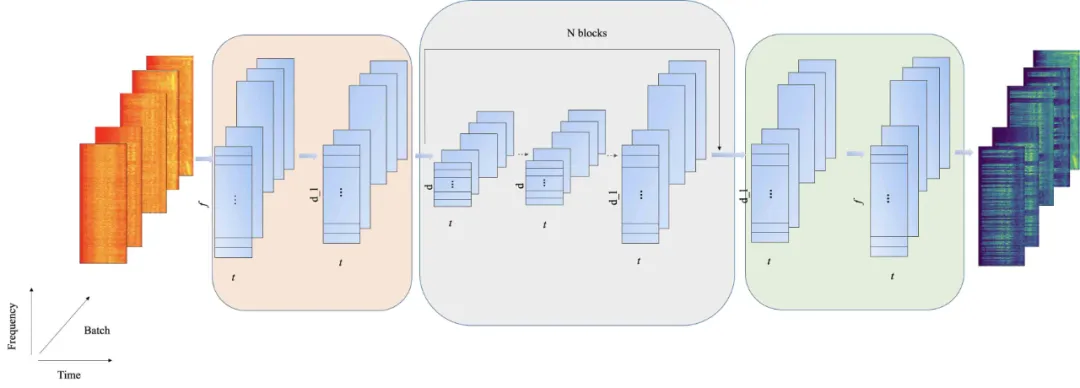
在綜合考慮業務使用場景,對降噪效果、性能開銷、實時性等諸多因素權衡后,AliCloudDenoise 語音增強演算法采用了 Hybrid 的方法,將帶噪語音中噪聲能量和目標人聲能量的比值作為擬合目標,進而利用傳統信號處理中的增益估計器如最小均方誤差短時頻譜幅度 (MMSE-STSA) 估計器,求得頻域上的去噪增益,最后經逆變換得到增強后的時域語音信號,在網路結構的選擇上,兼顧實時性和功耗,舍棄了 RNN 類結構而選擇了 TCN 網路,基本網路結構如下圖所示:
二、實時會議場景下的演算法優化
1、開會時旁邊人多很吵怎么辦?
問題背景
在實時會議場景中,有一類較為常見的背景噪聲是 Babble Noise,即多個說話者的交談聲組成的背景噪聲,此類噪聲不僅僅是非平穩的,而且和語音增強演算法的目標語音成分相似,導致在對這類噪聲的抑制程序中演算法處理的難度增大,以下列舉了一個具體的實體:
問題分析與改進方案
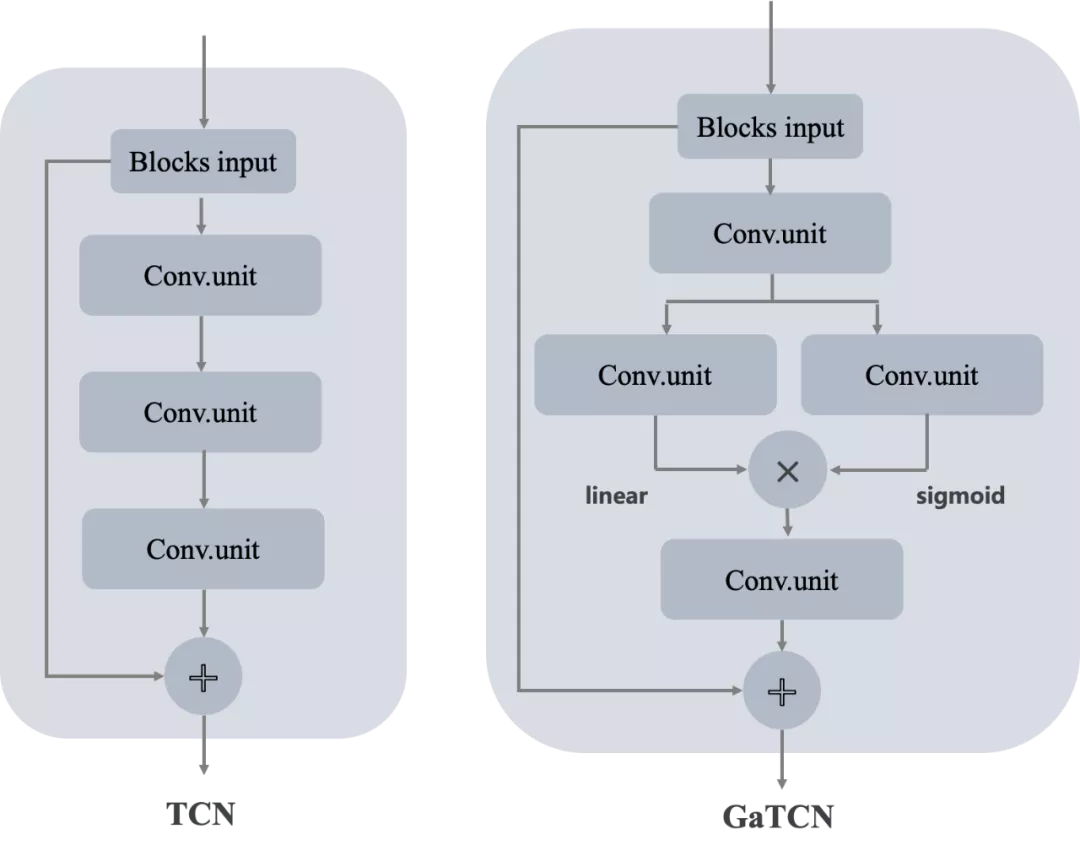
經過對數十小時含有 Babble Noise 的辦公室場景音頻進行分析,同時結合人類的語音發聲機制,發現這類噪聲具有類長時平穩存在特性,眾所周知,在語音增強演算法中,背景關系資訊(contextual information)對演算法效果有著非常重要的影響,所以針對 Babble Noise 這種對背景關系資訊更加敏感的噪聲型別,AliCloudDenoise 演算法通過空洞卷積(dilated convolutions)系統性地聚合模型中的關鍵階段性特征,顯式的增大感受野,同時額外的融合了門控機制(gating mechanisms),使得改進后的模型對 Babble Noise 的處理效果有了明顯的改善,下圖展示了改進前(TCN)與改進后(GaTCN)的關鍵模型部分的對比圖,
在語音測驗集上的結果表明,所提 GaTCN 模型在 IRM 目標下語音質量 PESQ[19] 較 TCN 模型提升了 9.7%,語音可懂度 STOI[20] 較 TCN 模型提升了 3.4%;在 Mapping a priori SNR[21] 目標下語音質量 PESQ 較 TCN 模型提升了 7.1%,語音可懂度 STOI 較 TCN 模型提升了 2.0%,且優于所有的 baseline 模型,指標詳情見表一和表二,

表一 客觀指標語音質量 PESQ 對比詳情

表二 客觀指標語音可懂度 STOI 對比詳情
改進效果展示:
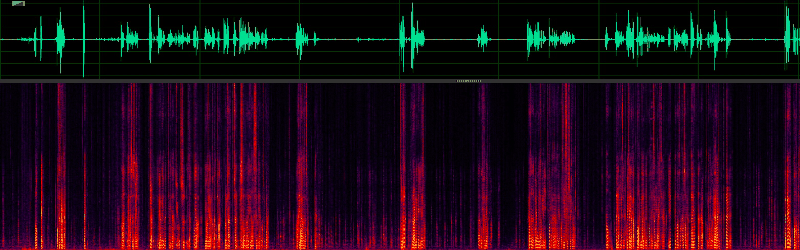
2、關鍵時刻怎能掉字?
問題背景
在語音增強演算法中,吞字或特定字詞消失如陳述句尾音消失的現象是影響增強后語音主觀聽感的一個重要因素,在實時會議場景中,因涉及到的語種多樣,語者說話內容多樣,這種現象更為常見,以下列舉了一個具體的實體:
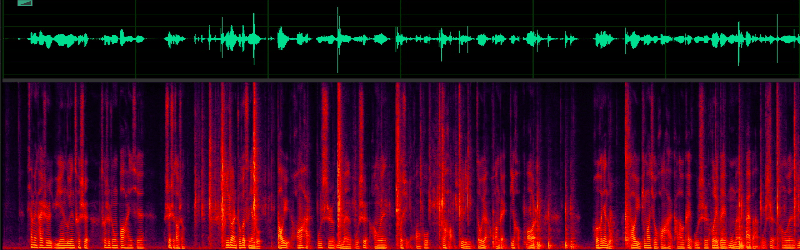
問題分析與改進方案
在分類構建的 1w+ 條語音測驗資料集上,通過對增強后吞字、掉字現象發生的時機進行統計,并可視化其對應的頻域特征,發現該現象主要發生在清音、疊音及長音等幾類特定的音素或字詞上;同時,在以信噪比為維度的分類統計中發現低信噪比情況下的吞字、掉字現象顯著增多,據此,進行了以下三方面的改進:
? 資料層面:首先進行了訓練資料集中特定音素的分布統計,在得出占比較少的結論后,針對性的豐富了訓練資料集中的語音成分,
? 降噪策略層面:降低低信噪比情況,在特定情況下使用組合降噪的策略,即先進行傳統降噪,再進行 AliCloudDenoise 降噪,此方法的缺點體現在以下兩方面,首先組合降噪會增加演算法開銷,其次傳統降噪不可避免的會出現頻譜級音質損傷,降低整體的音質質量,此方法經實測確實會改善吞字、掉字現象,但因其缺點明顯,并未在線上使用,
? 訓練策略層面:在針對性的豐富了訓練資料集中的語音成分后,確實會改善增強后吞字、掉字的現象,但仍存在該現象,進一步分析后,發現其頻譜特征與某些噪聲的頻譜特征高度相似,導致網路訓練區域收斂困難,基于此,AliCloudDenoise 演算法采用了訓練中輔助輸出語音存在概率,而推演程序中不采納的訓練策略,SPP 的計算公式如下:
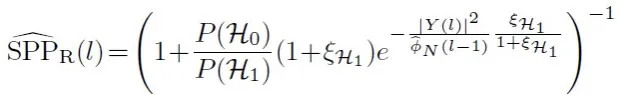
在語音測驗集上的結果表明,所提雙輸出的輔助訓練策略在 IRM 目標下語音質量 PESQ 較原模型提升了 3.1%,語音可懂度 STOI 較原模型提升了 1.2%;在 Mapping a priori SNR 目標下語音質量 PESQ 較原模型提升了 4.0%,語音可懂度 STOI 較原模型提升了 0.7%,且優于所有的 baseline 模型,指標詳情見表三和表四,

表三 客觀指標語音質量 PESQ 對比詳情

表四 客觀指標語音可懂度 STOI 對比詳情
改進效果展示:
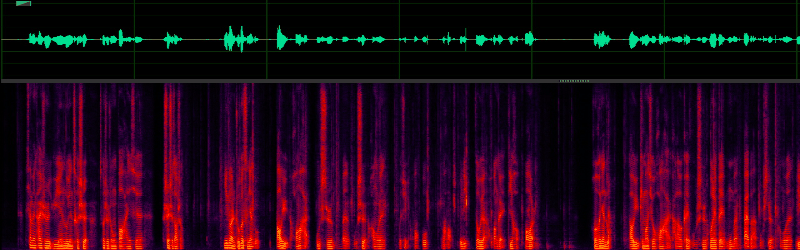
三、如何讓演算法的適用設備范圍更廣
對于實時會議場景來說,AliCloudDenoise 演算法的運行環境一般包括 PC 端、移動端以及 IOT 設備等,盡管在不同運行環境中關于能耗的要求不同,但 CPU 占用、記憶體容量及帶寬、電量消耗等都是我們關注的關鍵性能指標,為了使 AliCloudDenoise 演算法能夠廣泛地為各個業務方提供服務,我們采用了一系列能耗優化手段,主要包括模型的結構化裁剪、資源自適應策略、權值量化與訓練量化等,并通過一些輔助收斂策略在精度降低 0.1% 量級的情況下最終得到了約 500KB 的智能語音增強模型,極大地拓寬了 AliCloudDenoise 演算法的應用范圍,
接下來我們首先對優化程序中涉及到的模型輕量化技術做簡單的回顧,然后對資源自適應策略和模型量化展開介紹,最后給出 AliCloudDenoise 演算法的關鍵能耗指標,
1、采用的模型輕量化技術
針對深度學習模型的輕量化技術,一般指對模型的引數量及尺寸、運算量、能耗、速度等 “運行成本” 進行優化的一系列技術手段,其目的是便于模型在各類硬體設備的部署,同時,輕量化技術在計算密集型的云端服務上也有廣泛的用途,可以幫助降低服務成本、提升相應速度,
輕量化技術的主要難點在于:在優化運行成本的同時,演算法的效果與泛化性、穩定性不應受到明顯的影響,這對于常見的 “黑箱式” 神經網路模型來說,在各方面都具有一定的難度,此外,輕量化的一部分難點也體現在優化目標的差異性上,
比如模型尺寸的降低,并不一定會使得運算量降低;模型運算量的降低,也未必能提高運行速度;運行速度的提升也不一定會降低能耗,這種差異性使得輕量化難以 “一攬子” 地解決所有性能問題,需要從多種角度、利用多種技術配合,才能達成運行成本的綜合降低,
目前學術界與工業界常見的輕量化技術包括:引數 / 運算量子化、剪枝、小型模塊、結構超參優化、蒸餾、低秩、共享等,其中各類技術都對應不同的目的與需求,比如引數量化可以壓縮模型占用的存盤空間,但運算時依然恢復成浮點數;引數 + 運算全域量子化可以同時降低引數體積,減少芯片運算量,但需要芯片有相應的運算器支持,才能發揮提速效果;知識蒸餾利用小型的學生網路,學習大型模型的高層特征,來獲得性能匹配的輕量模型,但優化存在一些難度且主要適合簡化表達的任務(比如分類),
非結構化的精細剪裁可以將最多的冗余引數剔除,達成優良的精簡,但需要專用硬體支持才可以減少運算量;權重共享可顯著降低模型尺寸,缺點是難以加速或節能;AutoML 結構超參搜索能自動確定小型測驗結果最優的模型堆疊結構,但搜索空間復雜度與迭代估計的優良度限制了其應用面,下圖展示了 AliCloudDenoise 演算法在能耗優化程序中主要采用的輕量化技術,

2、資源自適應策略
資源自適應策略的核心思想是模型可以在資源不充足的情況下自適應的輸出滿足限定條件的較低精度的結果,在資源充足時就做到最好,輸出最優精度的增強結果,實作此功能最直接的想法是訓練不同規模的模型存放在設備中,按需使用,但會額外增加存盤成本,AliCloudDenoise 演算法采用了分級訓練的方案,如下圖所示:
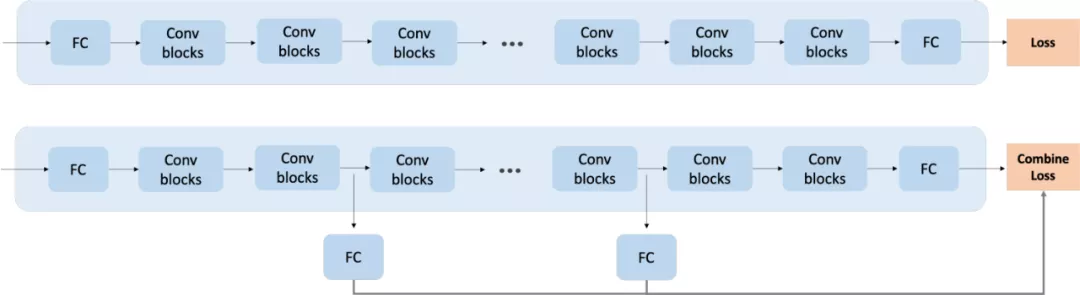
將中間層的結果也進行輸出,經聯合 loss 最終進行統一約束訓練,但實際驗證中發現存在以下兩個問題:
? 比較淺層的網路抽取的特征比較基礎,淺層網路的增強效果較差,
? 增加了中間層網路輸出的結構后,最后一層網路的增強結果會受到影響,原因是聯合訓練程序中會希望淺層網路也可以輸出較為不錯的增強結果,破壞了原有網路結構抽取特征的分布布局,
針對以上兩個問題,我們采用了多尺度 Dense 連接 + 離線超參預剪枝的優化策略,保證了模型可動態按需輸出精度范圍不超過 3.2% 的語音增強結果,
3、模型量化
在模型所需的記憶體容量及帶寬的優化上,主要采用了 MNN 團隊的權值量化工具 [22] 和 python 離線量化工具 [23] 實作了 FP32 與 INT8 之間的轉換,方案示意圖如下:

4、AliCloudDenoise 演算法的關鍵能耗指標
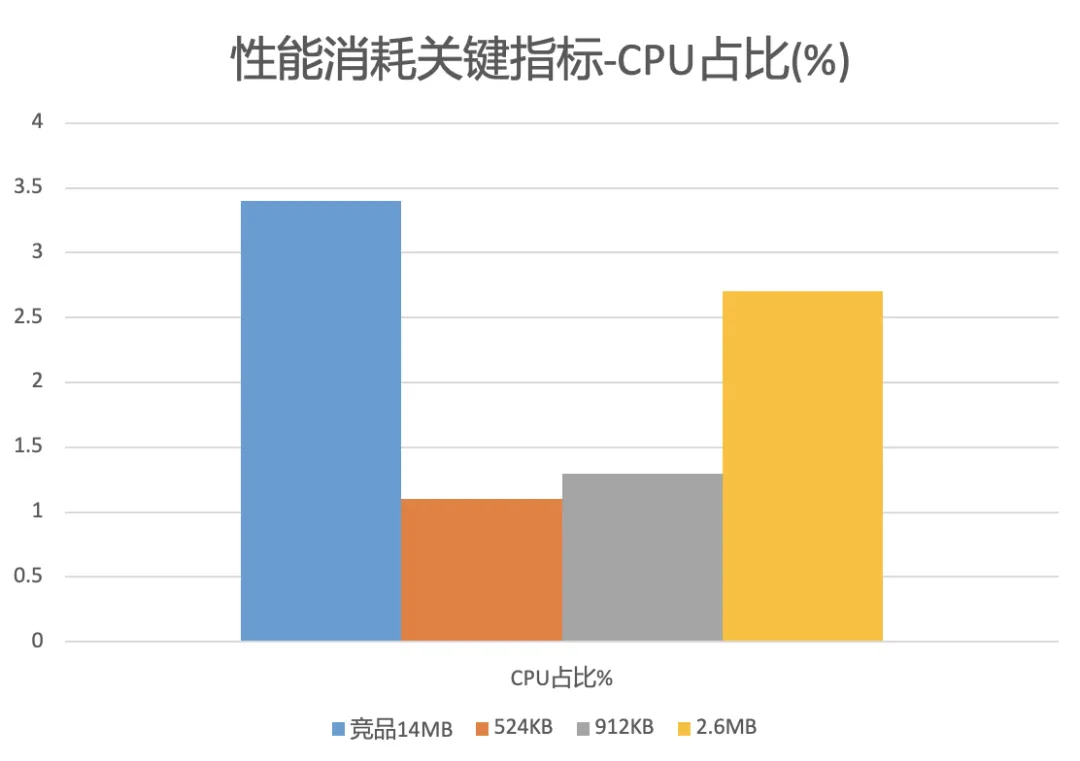
如上圖所示,在 Mac 平臺的演算法庫大小上,競品為 14MB,AliCloudDenoise 演算法目前主流輸出的演算法庫為 524KB、912KB 和 2.6MB,具有顯著優勢;在運行消耗上,Mac 平臺的測驗結果表明,競品的 cpu 占用為 3.4%,AliCloudDenoise 演算法庫 524KB 的 cpu 占用為 1.1%,912KB 的 cpu 占用為 1.3%,2.6MB 的 cpu 占用為 2.7%,尤其在長時運行條件下,AliCloudDenoise 演算法有明顯優勢,
四、演算法的效果技術指標評測結果
針對 AliCloudDenoise 演算法的語音增強效果的評估目前主要集中在兩個場景上,通用型場景和辦公室會議場景,
1、通用場景下的評測結果
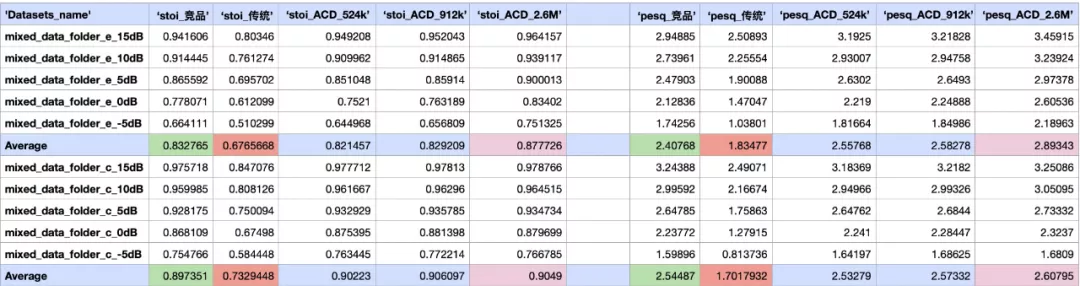
通用型場景的測驗集中,語音資料集由中文和英文兩部分組成(共計約 5000 條),噪聲資料集則包含了常見的四類典型噪聲,平穩噪聲(Stationary noise)、非平穩噪聲(Non-stationary noise)、辦公室噪聲(Babble noise)和室外噪聲(Outdoor noise),環境噪聲強度設定在 - 5 到 15db 之間,客觀指標主要通過 PESQ 語音質量與 STOI 語音可懂度來衡量,兩項指標都是值越大表示增強后的語音效果越好,
如下表所示,在通用型場景的語音測驗集上的評測結果表明,AliCloudDenoise 524KB 演算法庫較傳統演算法在 PESQ 上分別有 39.4%(英文語音)和 48.4%(中文語音)的提升,在 STOI 上分別有 21.4%(英文語音)和 23.1%(中文語音)的提升,同時和競品演算法基本持平,而 AliCloudDenoise 2.6MB 演算法庫較競品演算法在 PESQ 上分別有 9.2%(英文語音)和 3.9%(中文語音)的提升,在 STOI 上分別有 0.4%(英文語音)和 1.6%(中文語音)的提升,展現出了顯著的效果優勢,
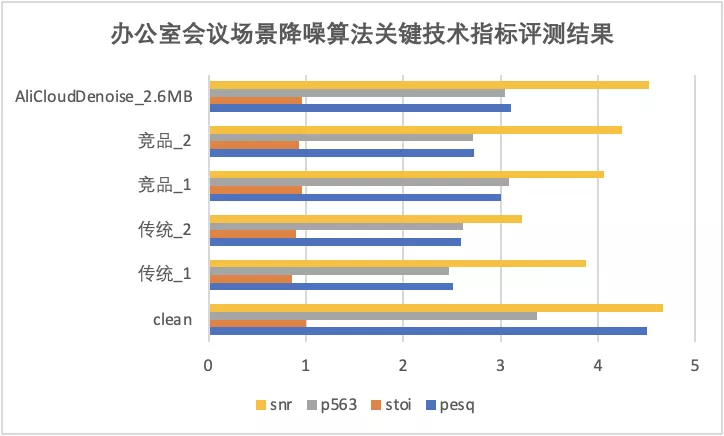
2、辦公室場景下的評測結果
結合實時會議的業務聲學場景,我們針對辦公室場景做了單獨的評測,噪聲為實際錄制的真實辦公場景下的嘈雜噪聲,共構建了約 5.3h 的評測帶噪語音,下圖展示了 AliCloudDenoise 2.6MB 演算法庫和競品 1、競品 2、傳統 1 及傳統 2 ,這四種演算法在 SNR、P563、PESQ 和 STOI 指標上的對比結果,可以看到 AliCloudDenoise 2.6MB 演算法庫具有明顯優勢,
未來展望
在實時通信場景下,AI + Audio Processing 還有很多待探索和落地的研究方向,通過資料驅動思想與經典信號處理演算法的融合,可以給音頻的前端演算法(ANS、AEC、AGC)、音頻的后端演算法(帶寬擴展、實時美聲、變聲、音效)、音頻編解碼及弱網下的音頻處理演算法(PLC、NetEQ)帶來效果上的升級,為阿里云視頻云的用戶提供極致的音頻體驗,
參考文獻
[1] Wang D L, Chen J. Supervised speech separation based on deep learning: An overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1702-1726.
[2] https://venturebeat.com/2020/04/09/microsoft-teams-ai-machine-learning-real-time-noise-suppression-typing/
[3] https://venturebeat.com/2020/06/08/google-meet-noise-cancellation-ai-cloud-denoiser-g-suite/
[4] https://medialab.qq.com/#/projectTea
[5] Gannot S, Burshtein D, Weinstein E. Iterative and sequential Kalman filter-based speech enhancement algorithms[J]. IEEE Transactions on speech and audio processing, 1998, 6(4): 373-385.
[6] Kim J B, Lee K Y, Lee C W. On the applications of the interacting multiple model algorithm for enhancing noisy speech[J]. IEEE transactions on speech and audio processing, 2000, 8(3): 349-352.
[7] Ephraim Y, Van Trees H L. A signal subspace approach for speech enhancement[J]. IEEE Transactions on speech and audio processing, 1995, 3(4): 251-266.
[8] Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on acoustics, speech, and signal processing, 1984, 32(6): 1109-1121.
[9] Cohen I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging[J]. IEEE Transactions on speech and audio processing, 2003, 11(5): 466-475.
[10]Ciregan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification[C]//2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012: 3642-3649.
[11]Graves A, Liwicki M, Fernández S, et al. A novel connectionist system for unconstrained handwriting recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2008, 31(5): 855-868.
[12]Senior A, Vanhoucke V, Nguyen P, et al. Deep neural networks for acoustic modeling in speech recognition[J]. IEEE Signal processing magazine, 2012.
[13]Sundermeyer M, Ney H, Schlüter R. From feedforward to recurrent LSTM neural networks for language modeling[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(3): 517-529.
[14]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[15] Valin J M. A hybrid DSP/deep learning approach to real-time full-band speech enhancement[C]//2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018: 1-5.
[16] Wang Y, Narayanan A, Wang D L. On training targets for supervised speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2014, 22(12): 1849-1858.
[17] Erdogan H, Hershey J R, Watanabe S, et al. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks[C]//2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015: 708-712.
[18] Williamson D S, Wang Y, Wang D L. Complex ratio masking for monaural speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2015, 24(3): 483-492.
[19] Recommendation I T U T. Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs[J]. Rec. ITU-T P. 862, 2001.
[20] Taal C H, Hendriks R C, Heusdens R, et al. A short-time objective intelligibility measure for time-frequency weighted noisy speech[C]//2010 IEEE international conference on acoustics, speech and signal processing. IEEE, 2010: 4214-4217.
[21] Nicolson A, Paliwal K K. Deep learning for minimum mean-square error approaches to speech enhancement[J]. Speech Communication, 2019, 111: 44-55.
[22] https://www.yuque.com/mnn/cn/model_convert
[23] https://github.com/alibaba/MNN/tree/master/tools/MNNPythonOfflineQuant
「視頻云技術」你最值得關注的音視頻技術公眾號,每周推送來自阿里云一線的實踐技術文章,在這里與音視頻領域一流工程師交流切磋,公眾號后臺回復【技術】可加入阿里云視頻云技術交流群,和作者一起探討音視頻技術,獲取更多行業最新資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/288386.html
標籤:其他
下一篇:回溯法解決全排列問題總結