本文是杭州站 Meetup 講師喬雷根據其分享內容整理而成的文章,
圖資料庫是一種使用圖結構進行語意查詢的資料庫,它使用節點、邊和屬性來表示和存盤資料,圖資料庫的應用領域非常廣泛,在反應事物之間聯系的計算都可以使用圖資料庫來解決,常用的領域如社交領域里的好友推薦、金融領域里的風控管理、零售領域里的商品實時推薦等等,
Nebula Graph 簡介與架構
Nebula Graph 是一個高性能、可線性擴展、開源的分布式圖資料庫,它采用存盤、計算分離的架構,計算層和存盤層可以根據各自的情況彈性擴容、縮容,這就意味著 Nebula Graph 可以最大化利用云原生技術實作彈性擴展、成本控制,能夠容納千億個頂點和萬億條邊,并提供毫秒級查詢延時的圖資料庫解決方案,
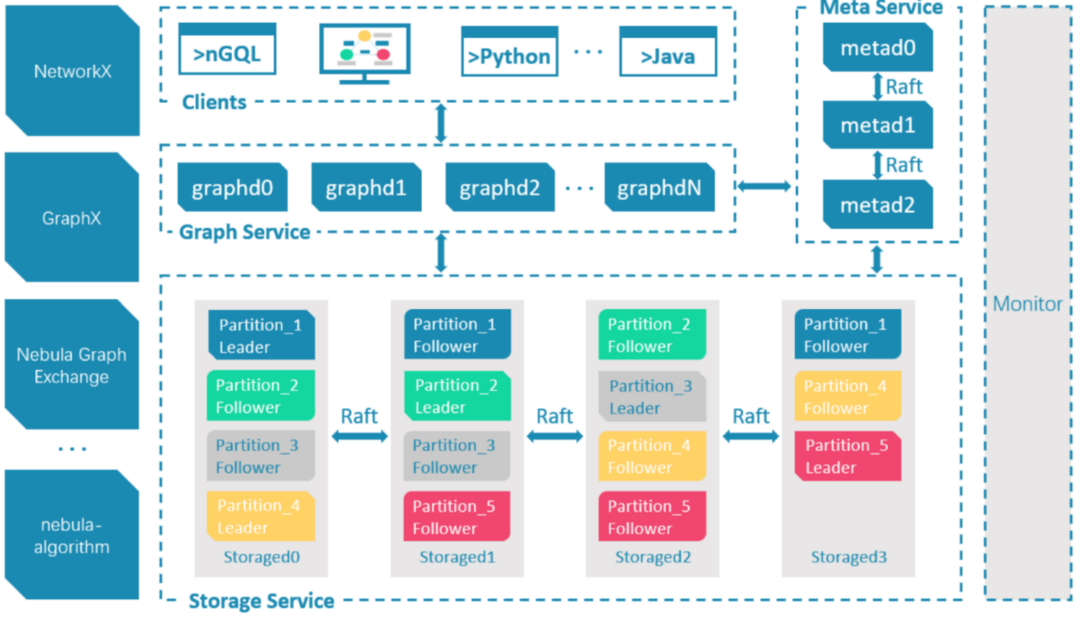
上圖所示為 Nebula Graph 的架構,一個 Nebula 集群包含三個核心服務,Graph Service、Meta Service 和 Storage Service,每個服務由若干個副本組成,這些副本會根據調度策略均勻地分布在部署節點上,
Graph Service 對應的行程是 nebula-graphd,它由無狀態無關聯的計算節點組成,計算節點之間互不通信,Graph Service 的主要功能,是決議客戶端發送 nGQL 文本,通過詞法決議Lexer 和語法決議 Parser 生成執行計劃,并通過優化后將執行計劃交由執行引擎,執行引擎通過 Meta Service 獲取圖點和邊的 schema,并通過存盤引擎層獲取點和邊的資料,
Meta Service 對應的行程是 nebula-metad ,它基于 Raft 協議實作分布式集群,leader 由集群中所有 Meta Service 節點選出,然后對外提供服務,followers 處于待命狀態并從 leader 復制更新的資料,一旦 leader 節點 down 掉,會再選舉其中一個 follower 成為新的 leader,Meta Service 不僅負責存盤和提供圖資料的 meta 資訊,如 Space、Schema、Partition、Tag 和 Edge 的屬性的各欄位的型別等,還同時負責指揮資料遷移及 leader 的變更等運維操作,
Storage Service 對應的行程是 nebula-storaged,采用 shared-nothing 的分布式架構設計,每個存盤節點都有多個本地 KV 存盤實體作為物理存盤其核心,Nebula 采用 Raft 來保證這些KV 存盤之間的一致性,目前支持的主要存盤引擎為 Rocksdb 和 HBase,
Nebula Graph 提供C++、Java、Golang、Python、Rust 等多種語言的客戶端,與服務器之間的通信方式為 RPC,采用的通信協議為 Facebook-Thrift,用戶也可通過 nebula-console、nebula-studio 實作對 Nebula Graph 操作,
多云架構挑戰
Nebula Graph 的云產品定位是 DBaaS (Database-as-a-Service)平臺,因此肯定要借助云原生技術來達成這一目標,到底該如何落地呢?首先要明確一點,任何技術都不是銀彈,只有合適的場景使用合適的技術,雖然我們擁有很多可供挑選的開源產品來搭建這個平臺,但是最終落實到交付給用戶的產品上,還有很多挑戰,
這里我列舉了三個方面的挑戰:
業務挑戰
多個云廠商的資源適配,這里需要實作統一的資源抽象模型,同時還要做好國際化,國際化需要考慮地域文化差異、當地法律法規差異、用戶消費習慣差異等多個要素,這些要素決定了需要在設計模式上去迎合當地用戶的使用習慣,從而提升用戶體驗,
性能挑戰
在大多數情況下,通過同一云廠商網路傳輸的資料移動速度比必須通過全球互聯網從一個云廠商傳輸到另一個云廠商的資料移動速度要快得多,這意味著跨云之間的網路連接可能成為多云體系結構的嚴重性能瓶頸,資料孤島很難打破,因為企業無法遷移格式不同且駐留在不同技術中的資料,缺乏可遷移性會帶給多云戰略帶來潛在的風險,在單個云廠商中,使用云廠商的原生自動擴展工具配置作業負載的自動擴展非常容易,當用戶的作業負載跨越多個云廠商時,自動擴展就會變得棘手,
運營挑戰
大規模的 Kubernetes 集群運營是非常有挑戰的事情,滿足業務的快速發展和用戶需求也是對團隊極大的考驗,首先是做到集群的管理標準化、可視化,其次全部的運維操作流程化,這需要有一個深入了解運維痛點的管理平臺,可以解決我們大部分的運維需求,資料安全上需要考慮在沒有適當的治理和安全控制的情況下,將資料從一個平臺遷移到另一個平臺(或從一個區域遷移到另一個區域)會帶來資料安全風險,
DBaaS(Database-as-a-Service)
云原生技術簡單概括就是為用戶提供一種簡易的、敏捷的、可彈性擴展的、可復制的方式,最大化使用云上資源的能力,云原生技術不斷演進也是為了用戶更好的專注于業務開發,大家可以看到這個金字塔,從 IaaS 到最上面的云原生應用層,產品形態越來越靈活,計算單元的粒度越來越細,模塊化程度、自動化運維程度、彈性效率、故障恢復能力都是越來越高,這說明每往上走一層,應用與底層物理基礎設施解耦就越徹底,用戶的關注點不再是從硬體服務器到業務實作整個鏈條,而是僅需要關注于當下業務本身,
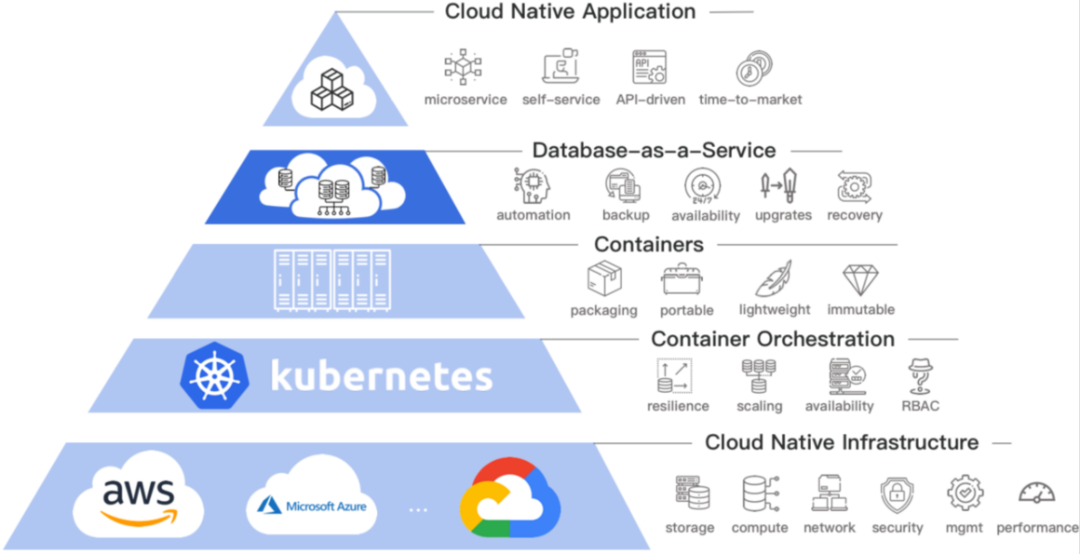
PaaS 平臺的容器編排系統是 Kubernetes,自然而然地就能想到基于 Kubernetes 構建這套平臺,Kubernetes 提供了容器運行時介面,你可以選擇任意一種實作這套介面的運行時來構建應用運行的基礎環境,因此,利用好 Kubernetes 提供的能力,就能達到事半功倍的效果,Kubernetes 提供了從命令列終端 kubectl 到容器運行依賴的存盤、網路、計算的多個擴展點,用戶可以根據業務場景實作一些自定義擴展插件對接到 kubernetes 平臺,而不用擔心侵入性,
用戶視圖
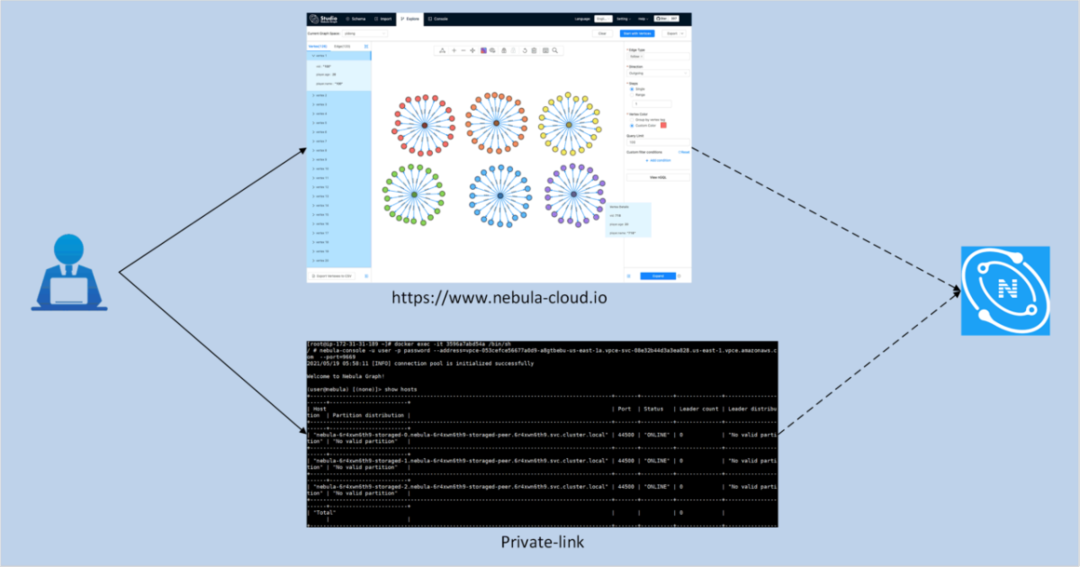
NebulaCloud 目前為用戶提供兩種訪問方式,一種是通過瀏覽器進入 Studio 操作視窗,在資料匯入后可以做圖探索,nGQL 陳述句執行等操作,另一種是通過廠商提供的 private-link 打通用戶到 NebulaCloud 之間的網路連接,用戶可以通過 nebula-console 或者 nebula client 直連到 Nebula 實體,
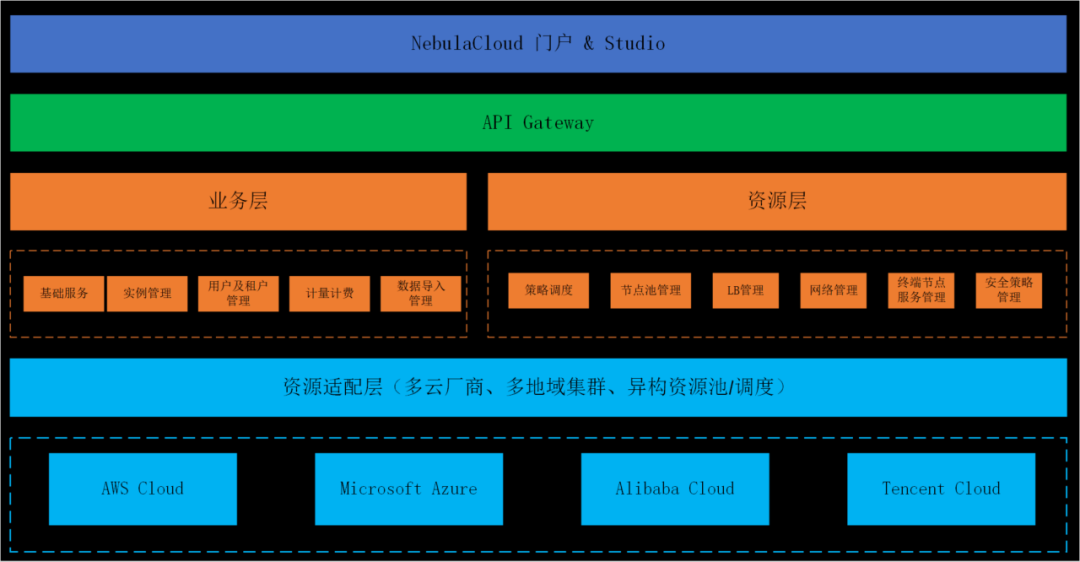
NebulaCloud 架構
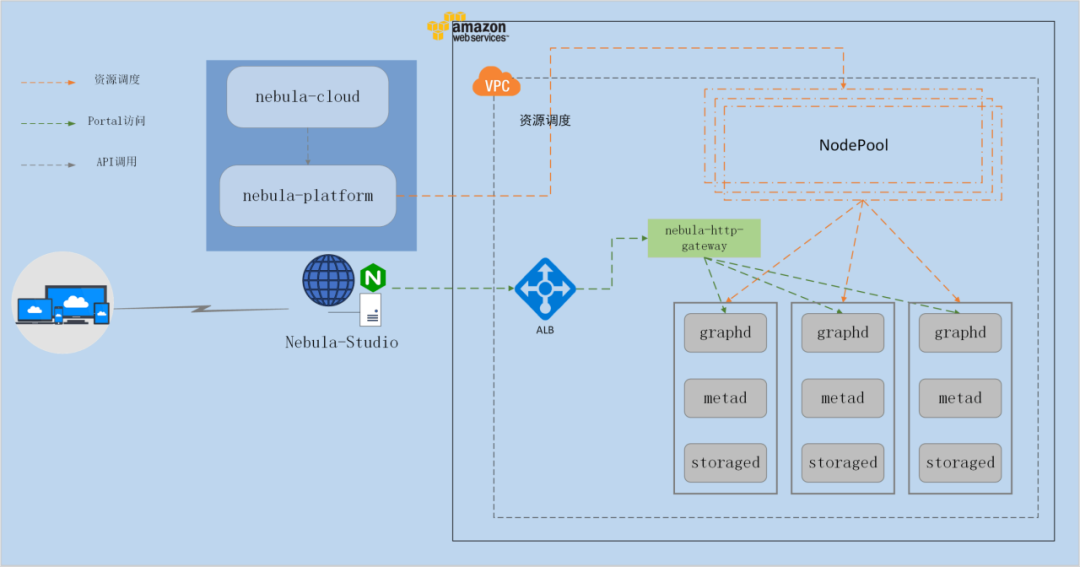
從業務架構上看,NebulaCloud 可以分為三層,最底層是資源適配層,主要負責提供資源層面上的適配,提供對多云廠商、多地域集群、同構或異構資源池的抽象描述,再往上是業務層與資源層,業務層涵蓋基礎服務、實體管理、租戶管理、計費管理、資料匯入管理等業務模塊;資源層負責提供 Nebula 集群的運行環境,在調度策略下提供最佳的資源配置,最上層是網關層,對外提供訪問服務,
NebulaCloud 內部流程
這里以 AWS 為例策略地描述一個 Nebula 集群的創建程序,用戶創建實體請求提交后,nebula-platform 服務根據輸入的廠商、地域、規格等引數資訊做資源調度,比如資源池、負載均衡、安全策略等配置,然后通過 nebula-operator 的 api 完成實體的創建,最后配置 ALB 規則,為用戶提供訪問實體的入口,
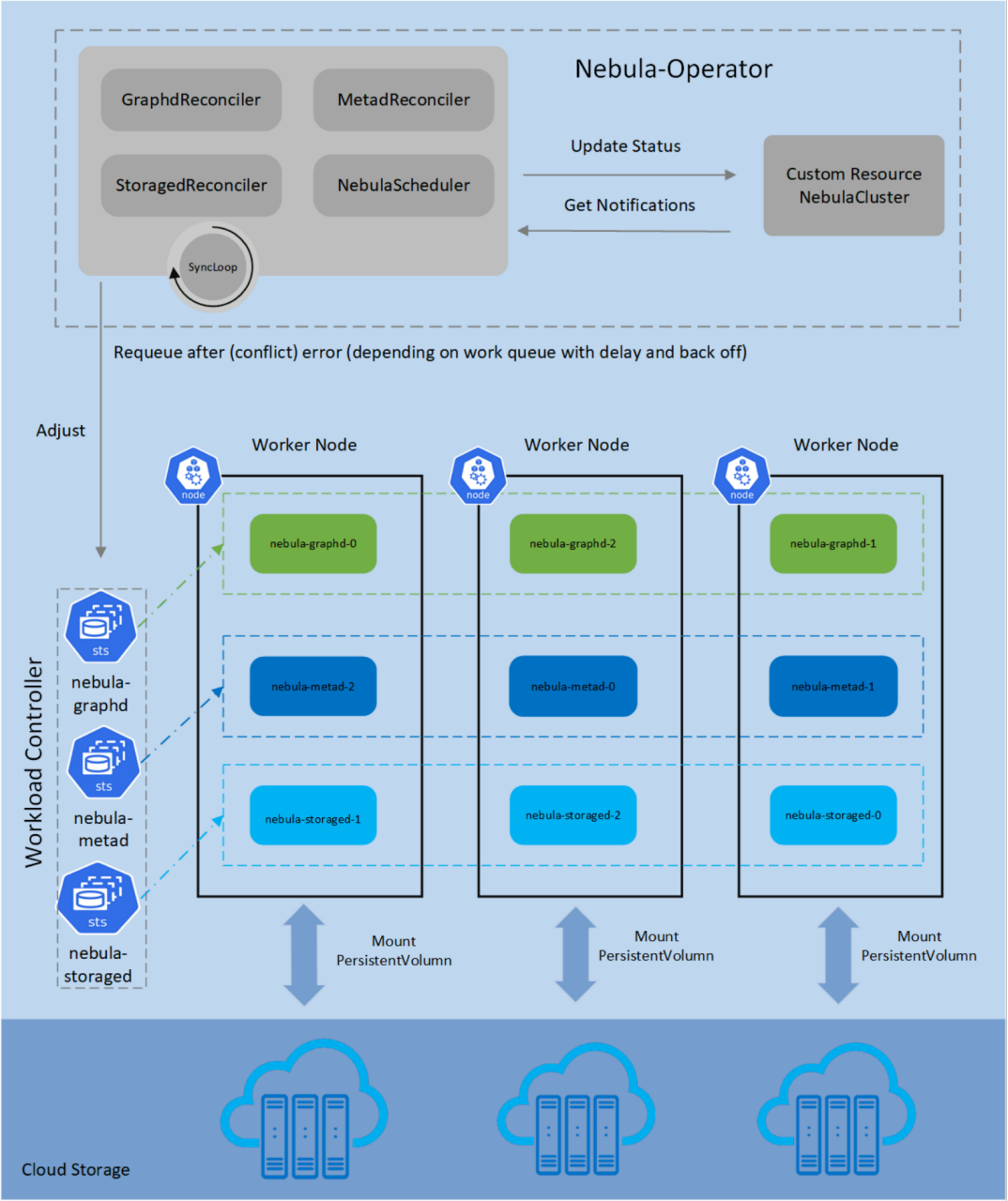
Nebula-Operator
在 Kubernetes 中,定義一個新物件可以有兩種方式,一個是 CustomResourceDefinition, 一個是 Aggregation ApiServer,其中 CRD 是目前主流的做法,nebula-operator 就是 CRD 來實作的,
CRD+Custom Controller 就是典型的 Operator 模式了,通過向 Kubernetes 系統注冊好的 CRD,我們可以使用 controller 來觀察 Nebula 集群以及與它相關聯的資源物件狀態,然后按照寫的協調邏輯來驅動 Nebula 集群向期望狀態轉移,這么實作可以把 Nebula 相關的管理作業都沉淀到 Operator 里,用戶使用 NebulaGraph 的復雜度降低,可以輕松完成彈性擴縮容、滾動升級等核心操作,我們基于 kubernetes 的 Restful API 生成了一套管理 Nebula 集群的 API,這樣用戶可以拿著 API 就能實作對接自己的 PaaS 平臺,搭建自己的圖計算平臺,
nebula-operator 目前的功能還在不斷完善中,實體的滾動升級需要 Nebula 提供底層支持,預計今年會支持上,
KubeSphere 多集群管理
平臺化管理
KubeSphere 衍生自青云公有云的操作面板,除了繼承顏值,同時在功能上也是相當完備,NebulaCloud 需要對接的主流云廠商都已經支持上,因此一套管理平臺就可以運維所有的 Kubernetes 集群,多集群管理是我們最為看重的功能點,
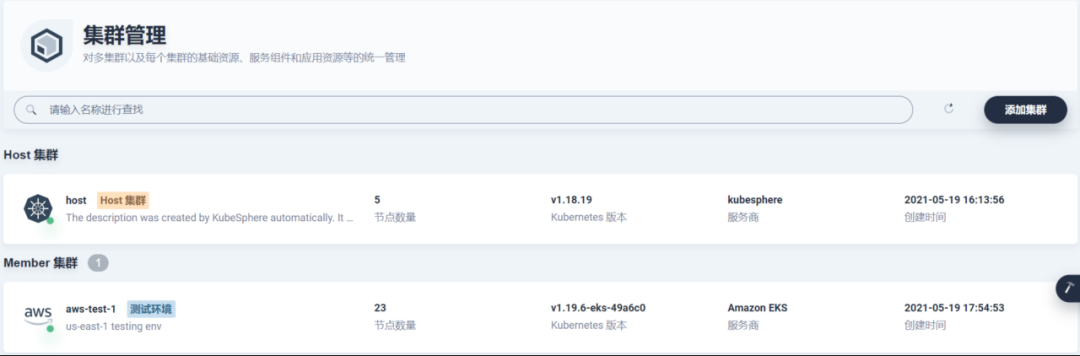
我們在本地環境部署了 Host 集群,其余的云上托管 Kubernetes 集群通過直連接入的方式作為 Member 集群,這里需要注意 ApiServer 訪問配置放通單個 IP,比如本地環境的出口公網 IP,
流程化操作
我們使用 IaC 工具 pulumi 部署新集群,再通過自動化腳本工具設定待管理集群 member 角色,全部程序無需人工操作,集群的創建由平臺的告警模塊來觸發,當單集群的資源配額達到告警水位后,會自動觸發彈性出一套新的集群,
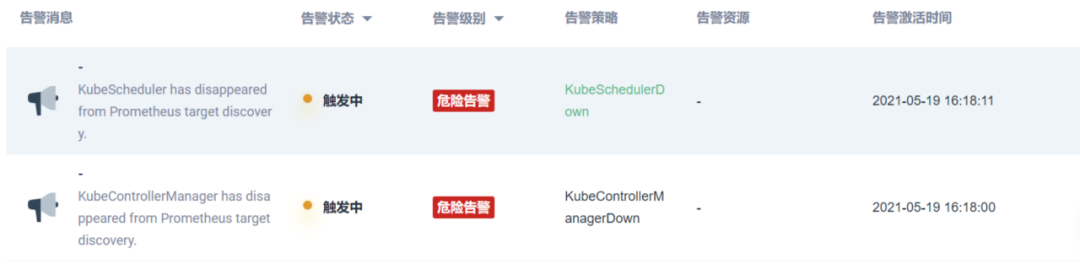
自動化監控
KubeSphere 提供了豐富的內置告警策略,同時還支持自定義告警策略,內置的告警策略基本可以覆寫日常所需的監控指標,在告警方式上也有多種選擇,我們采用了郵件與釘釘相結合的方式,重要緊急的可以通過釘釘直接釘到值班人員,普通級別的可以走郵件方式,

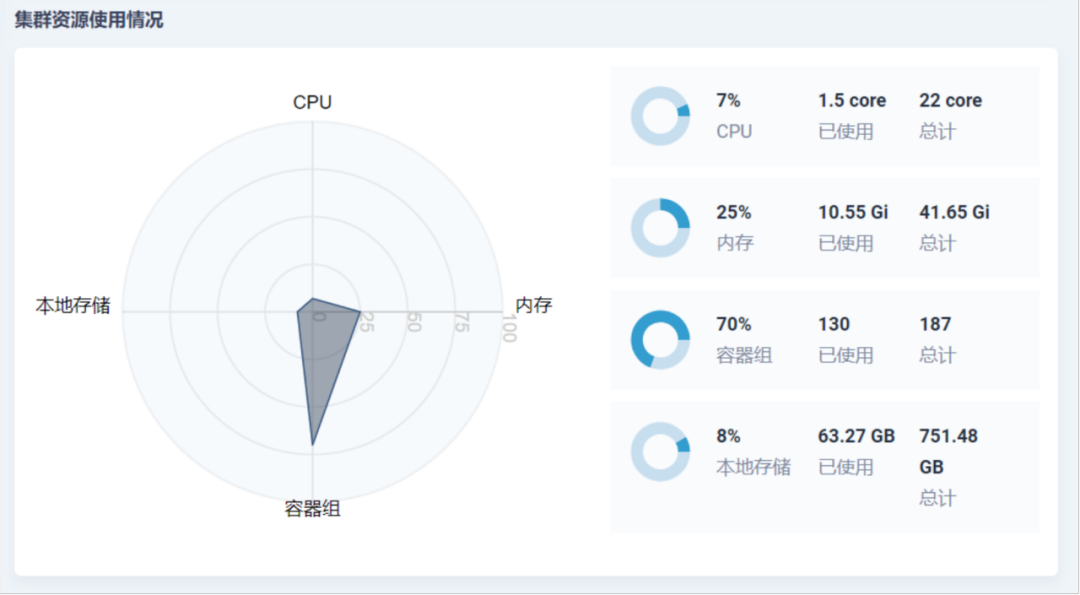
智能化運營
KubeSphere 提供了集群多個維度的全域展示視圖,目前管理的集群數量少足夠使用,未來隨著接入 member 集群數量的增加,可以通過運營資料的分析做資源的精細化調度和故障預測,進一步提前發現風險,提升運營的質量,
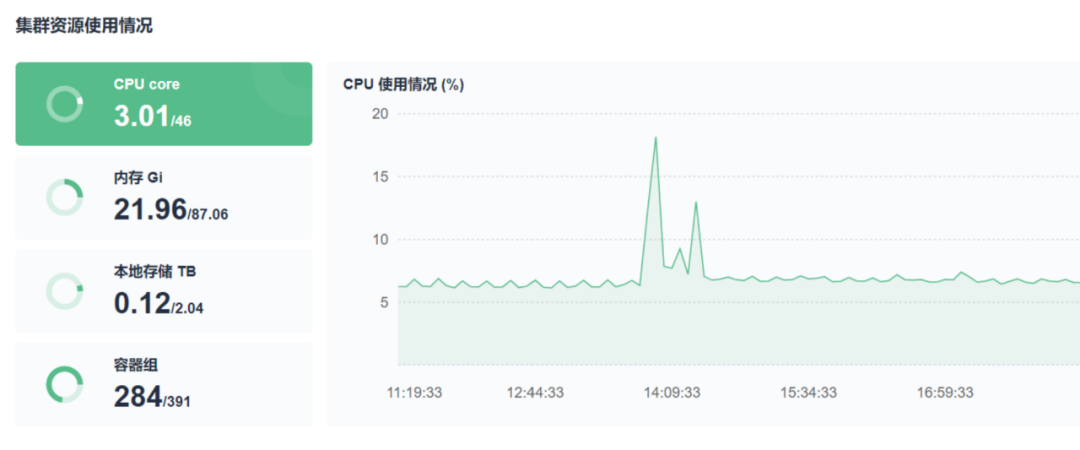
其他
KubeSphere 還有很多好用的配套工具,比如日志查詢、事件查詢、操作審計日志等,這些工具在精細化運營都是必不可少的, 我們目前已經接入了測驗環境集群,在深度使用掌握 KubeSphere 的全貌后會嘗試接入生產集群,
未來規劃
我們將充分挖掘自定義告警策略并加以利用,同時結合 Nebula 集群自身的監控指標打造監控全景圖;覆寫核心指標的多級、多維度的告警機制,將風險消滅在源頭;完善周邊配套工具,通過主動、被動以及流程化等減少誤操作風險;啟用 DevOps 作業流,打通開發、測驗、預發、生產環境,減少人力介入,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/288877.html
標籤:其他