詞嵌入的特性
現在你有了一堆嵌入向量,我們可以開始學習他們之間的特性了
前情提要:https://www.cnblogs.com/DAYceng/p/14962528.html
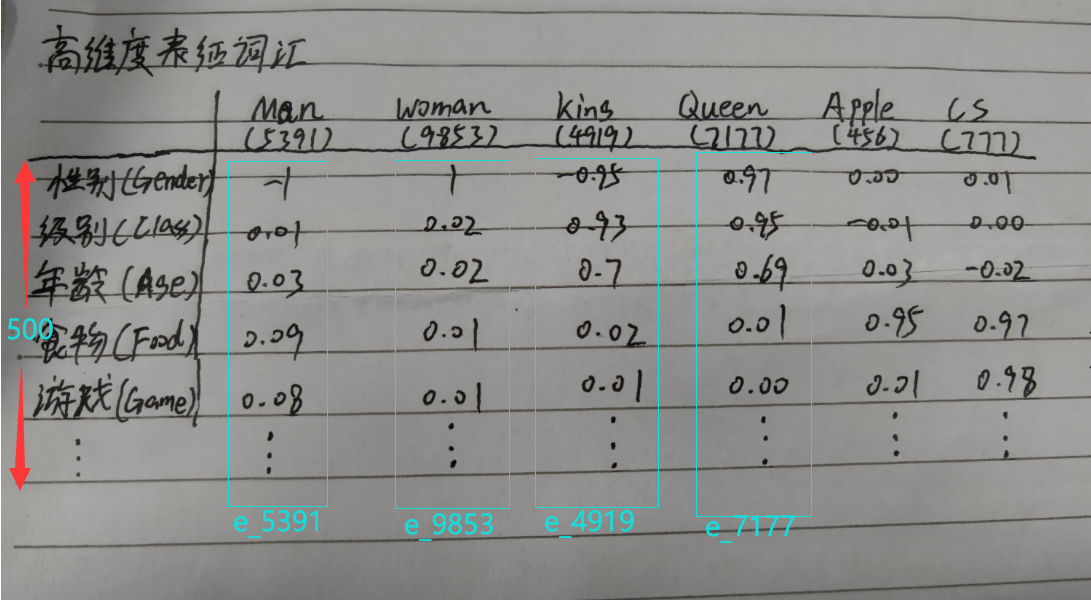
先把各向量重新命名便于區分
Man對應e_man①
Woman對應e_woman②
King對應e_king③
Queen對應e_queen④
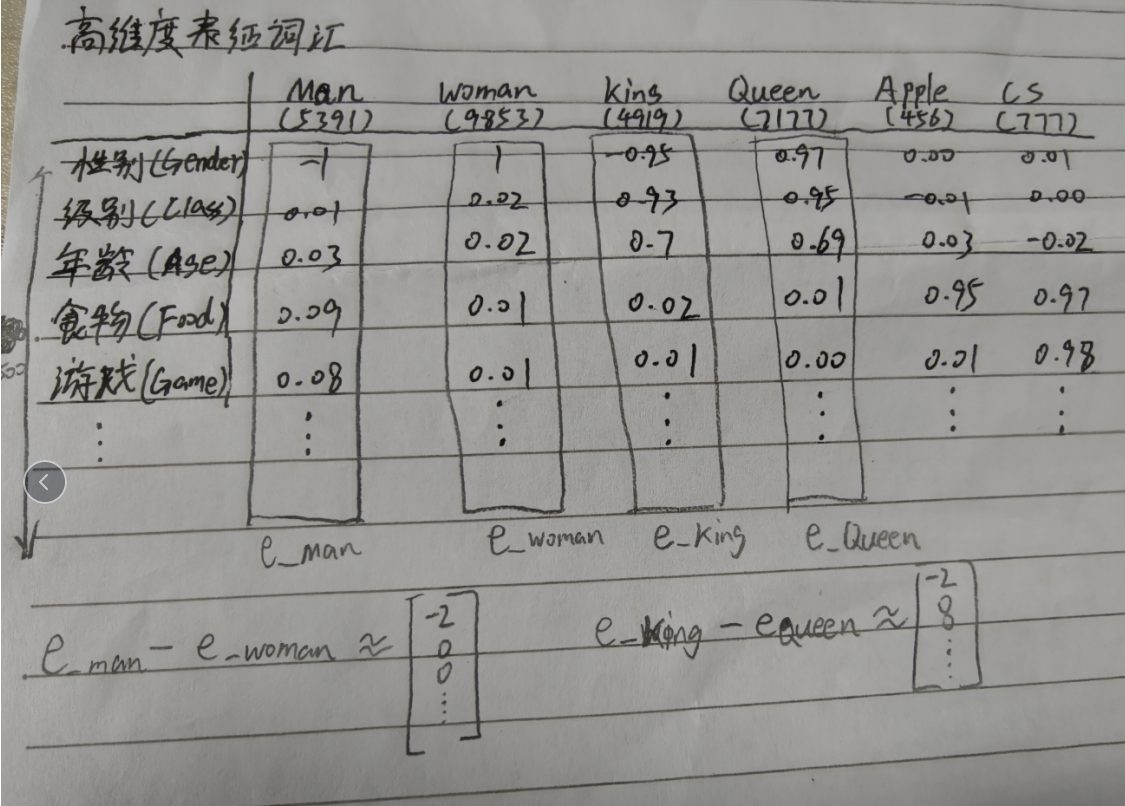
現在用e_man減e_woman
①-②≈[-2,0,0,...]
用e_king減e_queen
③-④≈[-2,0,0,...]
由此可見,Man和Woman的差異主要體現在性別(gender)上,King和Queen也是如此
那么,當系統被問及“Man之于Woman等價于King之于什么?”時,它自然的會用嵌入向量相減,從而推斷出問題的答案,即:Man之于Woman等價于King之于Queen
如何在演算法上實作上述特性?答案是”計算距離“

如圖所示,所求的e_?可以表示為:e_king-e_man+e_woman
那我現在只需要找出一個單詞的嵌入向量,假設為e_w,使得這個e_w與e_king-e_man+e_woman最相似即可
用函式表示也就是Sim(e_w,e_king-e_man+e_woman)取最大值就滿足條件
那么,這個Sim()是什么函式呢?
這個Sim()一般會是余弦相似度、歐氏距離等相似演算法(在代碼中以函式方式提供使用),具體不再展開
嵌入矩陣(Embedding Matrix)
有了詞嵌入這么強大的東西,那我們怎么去用它呢?
一般來說我們會以嵌入矩陣(Embedding Matrix)的形式來利用詞嵌入,就像下面這個
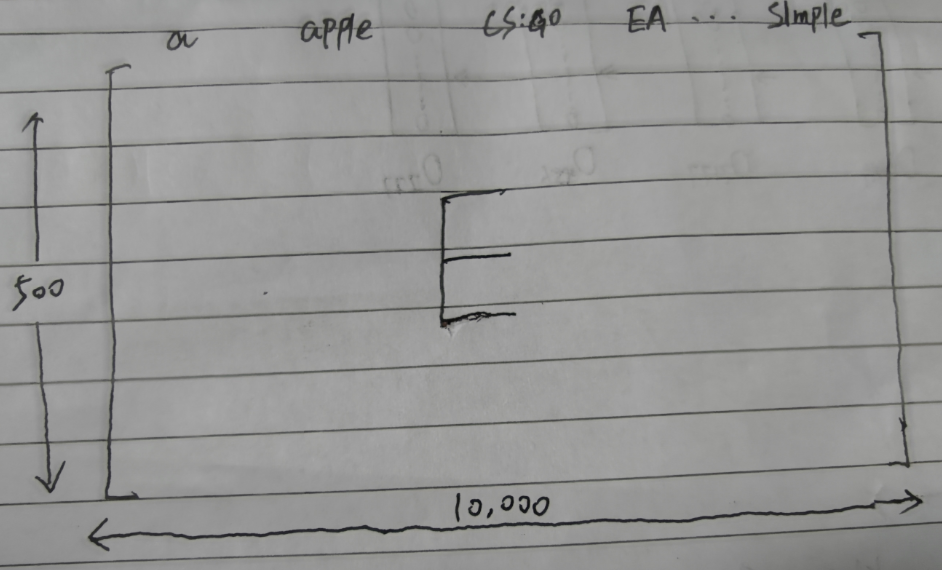
這是一個500 X 10000大小的嵌入矩陣,里面存的全是一些嵌入值,命名為E矩陣
可以看到,每列我標出了對應的單詞,說白了這個矩陣其實就是由一萬個嵌入向量拼接成的
現在我們需要使用One-Hot 了
假設我們有一個One-Hot編碼的向量O_7426,它是一個10000行1列的矩陣
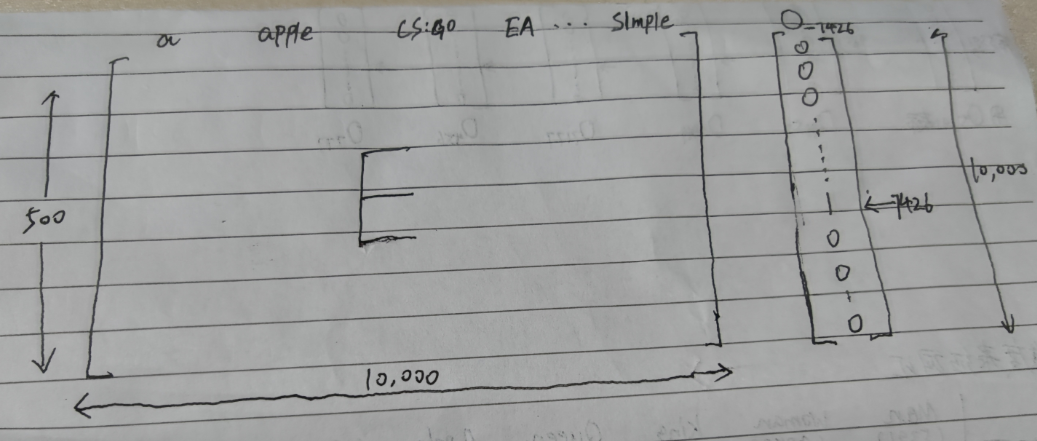
我們用O_7426與E相乘,即E * O_7426
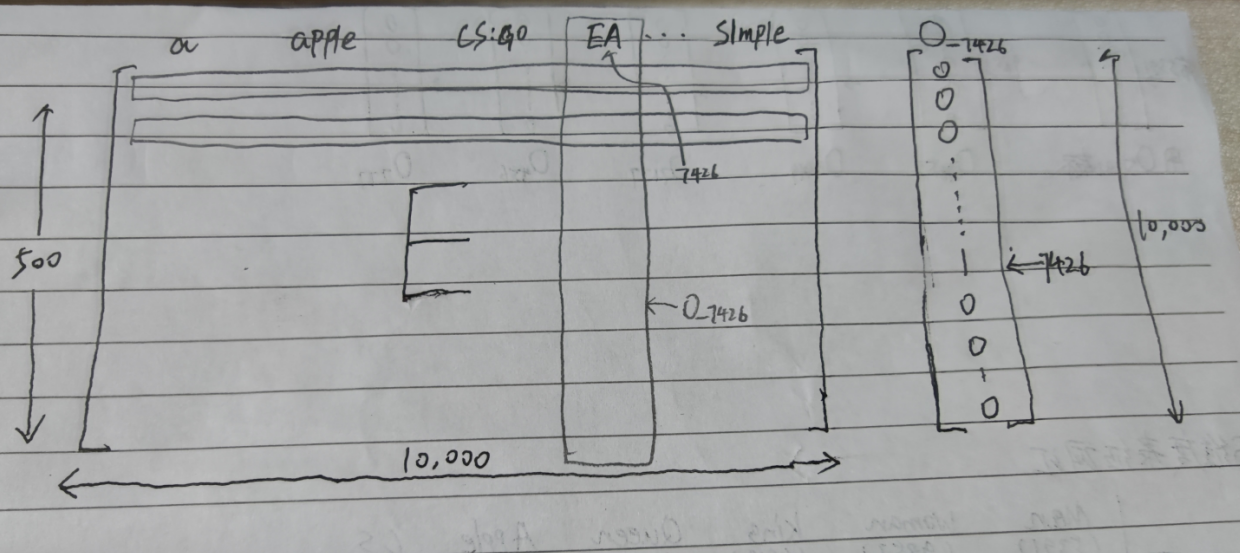
由線性代數的知識我們可以知道,E(500 X 10000) * O_7426(10000 X 1)的結果是一個大小為500 X 1的矩陣,用e_w表示
嗯?500 X 1
這不就是E矩陣中的一個列嗎?換句話說這個結果就是對應著某個詞的嵌入向量
假設E*O_7426的結果是上圖中框起來的部分,那么我們可以得出以下結論:
因為E * O_7426 = e_w
而e_w與"EA"所在列的值相等
所以
O_7426是對“EA”的獨熱編碼 #EA是第7426個詞
e_w = e_ea
因此原式可寫成:E * O_7426 = e_7426或者E * O_ea = e_ea
由上述我們還可以進一步推廣,任何與E矩陣,也就是嵌入矩陣相乘的One-Hot編碼向量,最后會定位到編碼對應的詞的詞嵌入,或者說嵌入向量,進而得出某個詞,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/288878.html
標籤:其他