文章目錄
- 一 排序的基本概念
- 二 常見的基本排序
- 1. 插入排序
- 2. 希爾排序
- 3. 選擇排序
- 4.堆排序
- 1)維護堆的性質
- 遞回維護堆的性質
- 非遞回維護堆的性質
- 2)建立堆
- 3)堆排序
- 5 歸并排序
- 6 快速排序
- 7 計數排序
- 8 冒泡排序
一 排序的基本概念
排序啊,一個很有趣的話題,排序就是使得資料能夠成為一種有序的操作,(并不嚴謹,可是這樣理解就夠了,)準確的定義,朋友們可以看看資料結構的書哈,我就不復制粘貼了哈,
- 為什么要有排序這個概念呢,它有啥用呢?
答:其實排序的主要目的就是為了提高查找效率,就比如說,二分查找演算法,前提必須有有序的資料才可以使用,極大提高了查找效率,,在我的理解,我的理解上啊,其實從廣義上講:把資料結構分為四大塊,線性表,非線性表,排序,查找,前面的三大板塊都是為了查找做準備的,都是為了提高查找效率,怎么說呢?假如你在某個瀏覽器,輸入你想要查找的東西,可是它半天都沒顯示出來,這就說明這個瀏覽器很菜,為什么菜,很大原因就是底層的代碼,如資料結構是按,線性的,非線性的,使用的排序演算法安排的不合理導致的唄,所以有必要學習以下排序,并且它非常有用哦,
- 排序的穩定與否判斷
穩定:如果a沒排序之前在b前面,且a = b,在排序之后a仍然在b的前面;
不穩定:如果a排序之前在b前面,且a=b,在排序之后a有可能會出現在b的后面;
- 內外排序是啥?
內排序:所有排序操作都在記憶體中完成;適合小資料的排序
外排序:由于資料太大,因此把資料放在磁盤中,而排序通過磁盤和記憶體的資料傳輸才能進行;
二 常見的基本排序
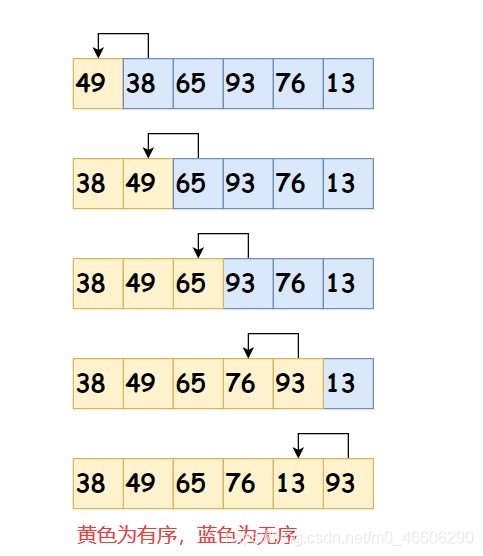
1. 插入排序
思想:插入排序,就是給你一組無序的資料,然后把資料分為 有序序列和無序序列 ,然后通過無序序列的資料和有序序列的資料進行比較,從而達到排序的目的,
代碼:
void InsertSort (int *a,int length)
{
for (int i = 1; i< length;i++) // 控制比較次數
{
if(a[i] < a[i-1]) //升序排序
{
swap(a[i],a[i-1]); //交換兩個數
//交換完兩個數還不夠,還要保證有序序列中也是有序的,
for (j = i-1;j > 0 && a[j] < a[j-1];j--)
{
swap(a[j],a[j-1]);
}
}
}
}
//交換函式
void swap(int &a,int &b)
{
int temp = a;
a = b;
b = temp;
}
另一種寫法:
void InsertSort(int* a,int length)
{
for (int i = 1;i < length;i++) //控制比較次數
{
key = a[i]; //保存要插入的值,為了下面執行a[j+1] = a[j]時候,a[i]的值還在
for (j = i-1;j >= 0 && key < a[j];j--) //開始比較插入
a[j+1] = a[j];
//退出回圈后
a[j+1] = key; //在執行a[j+1] = a[j]時候,
//a[i]也就是a[j+1]就被a[j]覆寫了,所以這句話的是把a[i]還會原來的位置
}
}
文字解釋:
假如有個 序列是 5 3;首先保存 3,3 和 5 比較,3比 5 小,把 5賦值給 3 的位置,最后,保存的 3 再賦值給 5 的位置;
此演算法在比較的程序就順便把數移動了,合適,資料量比較少時候使用,
2. 希爾排序
思想:
希爾排序又叫增量縮小排序,就是把一組資料按一定的增量來分成多個小組來插入排序,直到增量縮小到1,則排序結束;
# include<stdio.h>
# include<windows.h>
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void ShellSort(int* a, int length)
{
int j = 0;
for (int grap = length / 2; grap > 0; grap /= 2) //控制增量
{ //每一趟增量的插入排序
//每一趟都是排了一小組的一部分;
for (int i = grap; i < length; i++)
{
int key = a[i];//保存要插入的值
for ( j = i - grap; j >= 0 && key < a[j]; j -= grap)
a[j + grap] = a[j]; // 若后面的數 小于 前面, 把 前面的給后面的
//退出回圈后,把前面的數插入要插入的值,
a[j + grap] = key;
}
}
}
int main()
{
int a[] = { 10, 8, 4, 6, 9, 11, 123, 6, 2, 14, 3, 8, 5 };
int n = sizeof(a) / sizeof(a[0]);
print(a, n);
ShellSort(a, n);
print(a, n);
system("pause");
return 0;
}
對于 這個回圈的解釋 for (int i = grap;i > length;i++)

在我的理解:希爾排序也是插入排序的一種小變形方式;在插入排序中,增量就是為1的希爾排序;
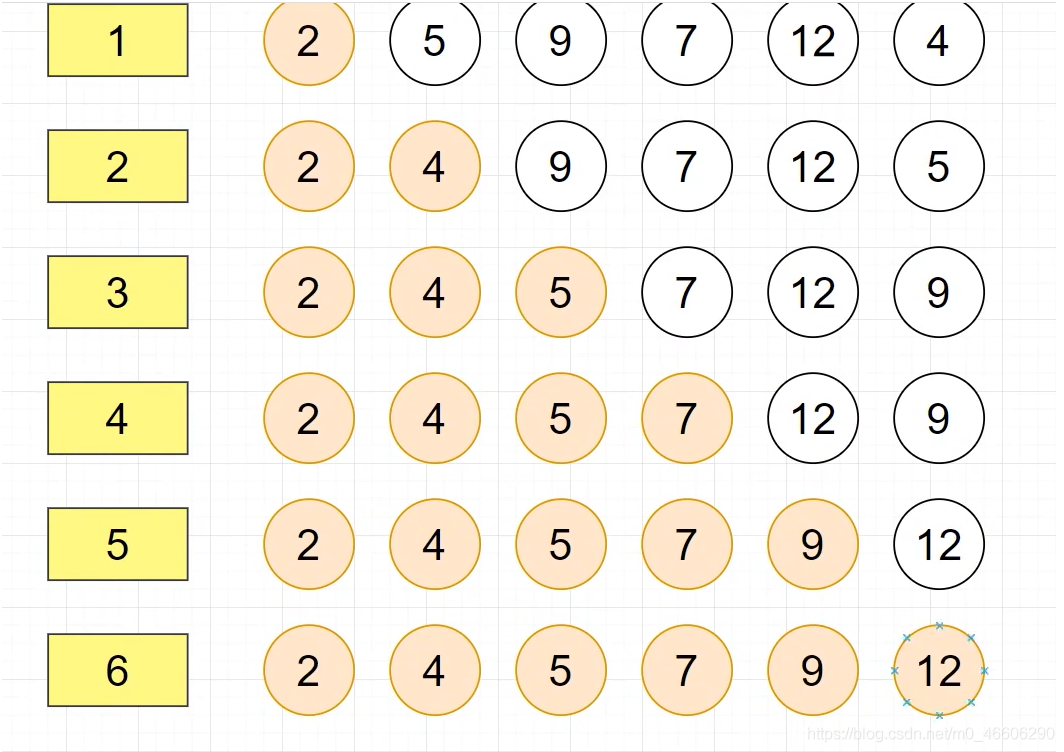
3. 選擇排序
思想: 選擇排序就是,給定一組無序資料,讓第一個資料作為最小(最大)的,然后剩下的資料與其比較,找到新的最小(最大)的數,把新的替換舊的數,依次回圈認為第二個資料最小…直到排完,

在這里插入圖片描述
void SelectSort(int* a, int length)
{
for (int i = 0;i < length;i++)
{
int min = i; //先假設第一個為最小的
for(int j = i+1;j < length;j++) //第一個后面開始找新的最小的
{
if(a[j] < a[min])
min = j;
}
swap(a[min],a[i]);
}
}
//交換函式
void swap(int &a,int &b)
{
int temp = a;
a = b;
b = temp;
}
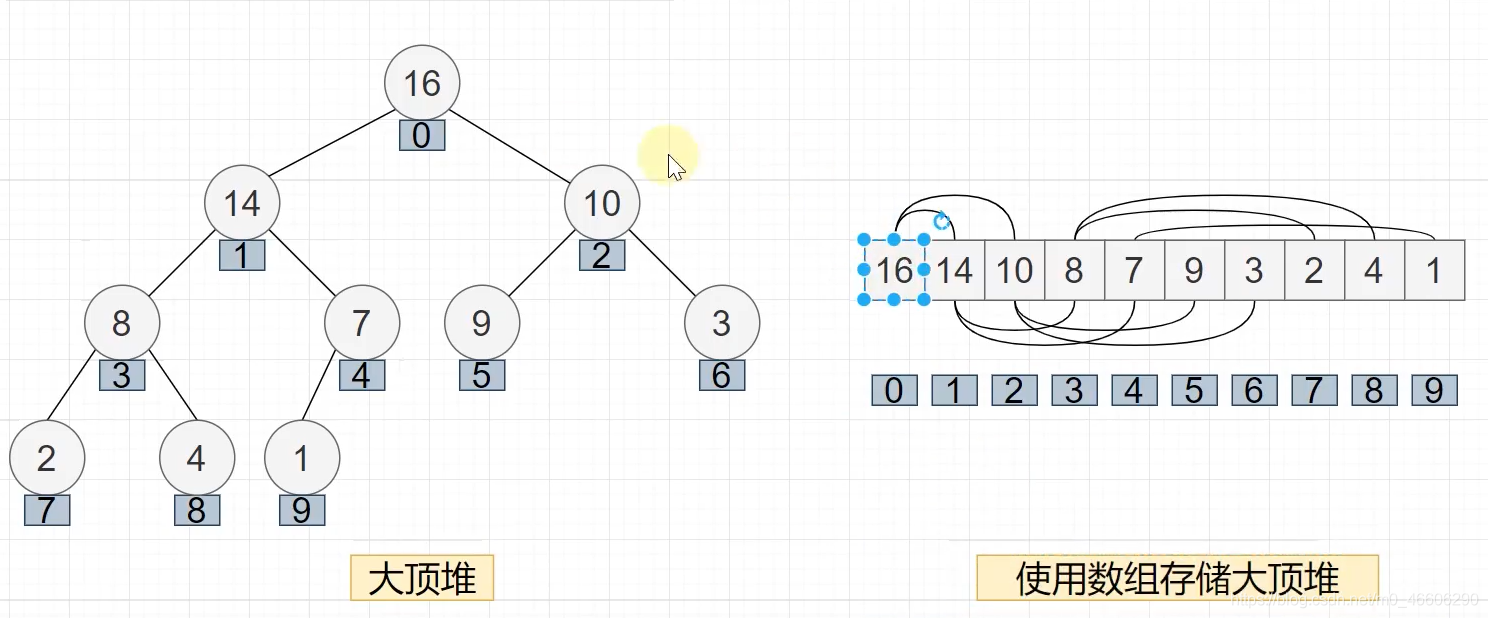
4.堆排序
思想:堆排序,也是叫做優先佇列,使用一種“完全二叉樹”的模式去存盤資料,然而完全二叉樹又可以用陣列的形式的方式存盤,而且,每一個父結點的值大于(小于)左右孩子的節點值,叫做大堆(小堆),
完全二叉樹的性質:
- 結點 下標 i 父結點的下標:i/2 -1;
- 結點下標 i 的左孩子的下標:i *2 +1;
- 結點下標 i 的有孩子的下標:i *2 +2;
推薦視頻:堆排序(heapsort) 或者這個 排序演算法:堆排序【圖解+代碼】,兩個都講得很清楚;
1)維護堆的性質
遞回維護堆的性質
維護堆的性質是把不滿足堆的排序方式的結點,維護成為堆的排序方式的結點,
// a為堆的陣列,n為陣列大小,i為要維護堆的下標,
//維護大堆的例子
void Heapify (int* a, int n,int i)
{
if (i >=n) //遞回的結束條件
return;
// 先把維護的下標默認認為是最大值的下標
int maxIndex = i;
int left = 2*i+1;
int right = 2*i+2;
//開始找真實最大值的下標
if (left < n && a[left] > a[maxIndex]) //左大于父的話,就換新的maxIndex
maxIndex = left;
if (right < n && a[right] > a[maxIndex])
//右大于父(在左大于父不成立下)或者右大于左,
//在(左大于父的前提下),把新的maxIndex找出來
maxIndex= right ;
if (maxIndex != i) //說明左右結點其中一個大于父結點
{
swap(a[maxIndex],a[i]);
Heapify(a,n,maxIndex);
}
}
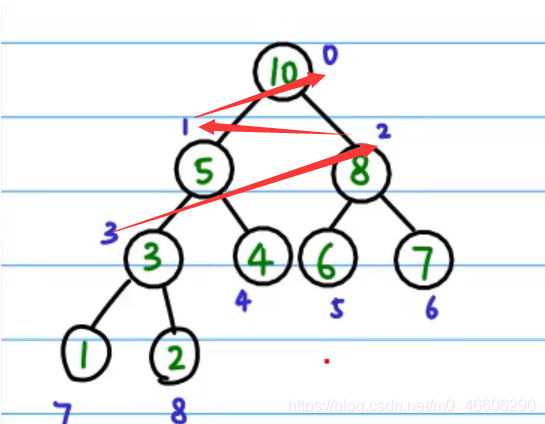
這段代碼的意思就是,假如要從某個已知不成堆的結點 i 開始 heapify; 假如我要從任意結點開始呢?那可以從最后一個結點的父結點開始逐漸遞減就可以 heapify 全部的節點了,這就是建立堆的程序,
這圖就是從最后一個結點的父節點開始堆化:
非遞回維護堆的性質
void heapify(int *a,int n,int parent)
{
int left = 2*parent + 1;
while (left < n)
{ //先找出根左右最大值的下標
if (left + 1 < n && a[left+1] > a[left]) //交換前看看右結點的值是否大于根節點;
left++;
if (a[left] > a[parent]) //右結點的值不大于根節點;左結點和根結點交換
{ //右結點得值大于根節點,
swap(a[left],a[parent]);
//繼續對下面的結點堆化
parent = left;
left = 2*parent + 1;
}
else //假如沒有 左右結點比parent大的話就結束堆化;
break;
}
}
2)建立堆
建立堆:就是維護堆的性質,把任意結點 i 的位置定為 最后一個結點;對最后一個結點的父節點進行維護堆;
void BulidHeap(int *a,int n)
{
int lastNode = n - 1; //先找出最后一個結點
for (int i = lastNode/2 -1; i >= 0;i--) // 從最后一個結點的父節點開始向上堆化構建,
//到根節點時候結束堆化
{
heapify(a,n,i);
}
}
3)堆排序
建立起的對我們結構我們還沒開始排序呢,現在開始排序,
因為剛剛建立了大堆,所以我們可以知道根結點一定是堆樹中最大的值,我們而要做就是
- 把根節點和最后一個結點做一次交換,然后取出交換后的最后一個結點,這樣就可以把最大的值取出來了,取出來的目的也是為了排序,然后由于交換了就會破壞堆的結構,
- 然后對交換后的根結點再進行一次堆化就可以了,繼續完成上訴操作,依次把堆樹中最大的值取出來,這樣就可以排序啦,

void HeapSort(int* a,int n)
{
int lastNode= n -1;
for (int i = lastNode; i >= 0; i--) //從最后一個結點開始和根交換
{
swap(a[0],a[i]);
//交換后,根又不滿足堆的性質了,所以重新堆化
heapify(a,i,0); //對根堆化,根的下標為 0;陣列大小每次會減一
}
}
5 歸并排序
思想:歸并排序就是將一個無序得序列,先分開,直到分到只有一個元素,然后再合并排序;
推薦一個視頻:排序演算法:歸并排序【圖解+代碼】,這個視頻講得很清楚,
# include<stdio.h>
# include<stdlib.h>
void merge_sort(int a[], int temp[], int left, int right)
{
if (left >= right) // left > right 不用分了, left = right 就是分到一個元素了,也不用分了
return;
//先把陣列分開 ,在 left < right 的前提下
int mid = (left + right) / 2;
//分為左邊的陣列
merge_sort(a, temp, left, mid );
// 分為右邊的陣列
merge_sort(a, temp, mid + 1, right);
//開始歸并
// 定義一個 左邊陣列的第一個元素的下標
int l_pos = left;
//定義一個 右邊陣列的第一個元素的下標
int r_pos = mid + 1;
// 定義一個存放歸并結果的陣列下標,用來后面歸并時候的操作
int t_pos = left;
//開始歸并,到臨時陣列
//在滿足左邊陣列的第一個元素下標<=最后一個元素的下標
//和右邊陣列第一個元素小于等于最后一個元素的下標前提下
while (l_pos <= mid && r_pos <= right)
{
if (a[l_pos]<a[r_pos])
temp[t_pos++] = a[l_pos++];
else
temp[t_pos++] = a[r_pos++];
}
//退出回圈后
//假如左邊陣列還有元素,直接將左邊陣列的元素丟進去臨時陣列
while(l_pos <= mid)
{
temp[t_pos++] = a[l_pos++];
}
//假如右邊陣列還有元素,直接將右邊陣列的元素丟進去臨時陣列
while(r_pos <= right)
{
temp[t_pos++] = a[r_pos++];
}
// 將臨時陣列拷貝到 原陣列
while (left <= right)
{
a[left] = temp[left];
left++;
}
}
void MergeSort(int a[], int n)
{ //給 歸并的結果存放的陣列開辟一個空間
int *temp = (int*)malloc(n*sizeof(int));
if (temp)
{ //開辟成功;
//開始歸并排序,先分開再歸并
merge_sort(a, temp, 0, n - 1);
free(temp);
}
}
void print(int a[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d\t", a[i]);
}
printf("\n");
}
int main()
{
int a[] = { 9, 5, 2, 7, 12, 4, 3, 1, 11 };
int n = 9;
print(a, n);
MergeSort(a, n);
print(a, n);
system("pause");
return 0;
}
6 快速排序
思想:就是任意選定一個數為 pivotKey(中心軸關鍵字),為了方便,通常這個pivotKet 為第一個元素,把剩余的元素和 pivotKey 比較,比它大放到右邊,比它小放到左邊;然后重復操作,直到分到左右的序列只有一個就排好序了,
推薦視頻:快速排序演算法;
我們排序要的效果是 左邊比 pivot 小,右邊比 pivot 大;
# include<stdio.h>
# include<windows.h>
void QuickSort(int arr[], int begin, int end)
{
int left = begin;
int right = end;
//把第一個元素作為 pivotKey 值;
int pivotKey = arr[left];
if (left >= right) //如果 left > right 就不用排了,
return; //或者 left = right;說明就分到左右兩邊就一個元素了
while (left < right)
{
while (left < right && arr[right] >= pivotKey)//若右邊的元素比 key 值大或等于,
right--; //說明不用賦值到左邊,直接下標往前移動
//退出回圈后,說明, arr[right] < pivotKey,就要放去左邊
if (left < right)
arr[left++] = arr[right];
while (left < right && arr[left] <= pivotKey)
left++;
if (left < right)
arr[right--] = arr[left];
}
// 當 left >= right 時候,說明這就是 pivotKey 的位置
arr[left] = pivotKey;
//繼續遞回呼叫 左邊快速排序
QuickSort(arr, begin, right - 1);
//繼續遞回調動 右邊快速排序
QuickSort(arr, right + 1, end);
}
//排序入口
void quick_sort(int arr[], int n)
{
QuickSort(arr, 0, n - 1);
}
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int a[] = { 10, 8, 4, 6, 9, 10, 123, 6, 2, 14, 3, 8, 5 };
int n = sizeof(a) / sizeof(a[0]);
print(a, n);
quick_sort(a, n);
print(a, n);
system("pause");
return 0;
}
7 計數排序
思想:計數排序就是統計一個無序序列的范圍大小,把里面相同的元素個數統計出來,把每組相同元素的個數存放到一個陣列中,用陣列下標對應元素的值,然后再取出其中的值,
類似一種哈希表的映射:用元素的值映射到陣列下標,
# include <stdio.h>
# include <windows.h>
# include <stdlib.h>
# include <assert.h>
void counting_sort(int a[], int n)
{
//統計元素的范圍大小,先找出元素的最大和最小值
int min = a[0]; //假定最小值為第一個元素
int max = a[0];//假定最大值為第一個元素
for (int i = 0; i< n; i++)
{
if (a[i] < min)
min = a[i];
if (a[i] > max)
max = a[i];
}
//開辟一個陣列,大小為元素的范圍大小即可
int range = max - min + 1;
int *temp = (int*)malloc(range*sizeof(int));
assert(temp);
//初始化陣列
memset(temp, 0, range*sizeof(int));
//往陣列temp添加相同元素的個數,于此同時,下標對應著元素的映射值
for (int j = 0; j < n; j++)
temp[a[j] - min]++;
//開始把值賦給 a 陣列
int i = 0; //存放陣列 a 的下標
for (int j = 0; j < range; j++)
{
while (temp[j]--)
{
a[i++] = j + min;
}
}
free(temp);
}
void print(int a[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
int main()
{
int a[] = { 6, 3, 4, 5, 2, 8, 6, 9, 2, 1 };
int n = sizeof(a) / sizeof(a[0]);
print(a, n);
counting_sort(a, n);
print(a, n);
system("pause");
return 0;
}
注意:記得開辟記憶體時候大小別賦值錯了,要不然改bug,改到你頭疼;
8 冒泡排序
思想:冒泡排序就是相鄰的兩個元素比較,前面大于后面的就交換,重復這個步驟;
普通的冒泡排序相信大家都會,這里我提供一種優化版的;我們都知道假如你給的序列就是有序的,就不需要排序了,可是,在普通冒泡排序中,并不是這樣,及時給你是有序的還是會一直找很多遍,優化版的只需要找一遍就可以;
# include<stdio.h>
# include<windows.h>
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void bubble_sort(int arr[], int n)
{
bool flag = false;
for (int i = 0; i < n; i++)
{ //沒交換保持flag = false;
flag = false;
for (int j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
flag = true;
swap(&arr[j], &arr[j + 1]);
}
//若一趟下來,都沒有交換,說明 已經是有順序的了,直接退出外回圈
if (flag == false)
break;
}
}
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[] = { 8, 9, 1, 4, 2, 3, 6, 7, 5, 5 };
int n = sizeof(arr) / sizeof(arr[0]);
print(arr, n);
bubble_sort(arr, n);
print(arr, n);
system("pause");
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289283.html
標籤:其他