目錄
- 🥑HTTP/1.x 的連接管理
- 🏳??🌈短連接
- 🏳??🌈長連接
- 🏳??🌈HTTP 流水線
- 🏳??🌈域名分片
- 💬總結

🥑HTTP/1.x 的連接管理
-
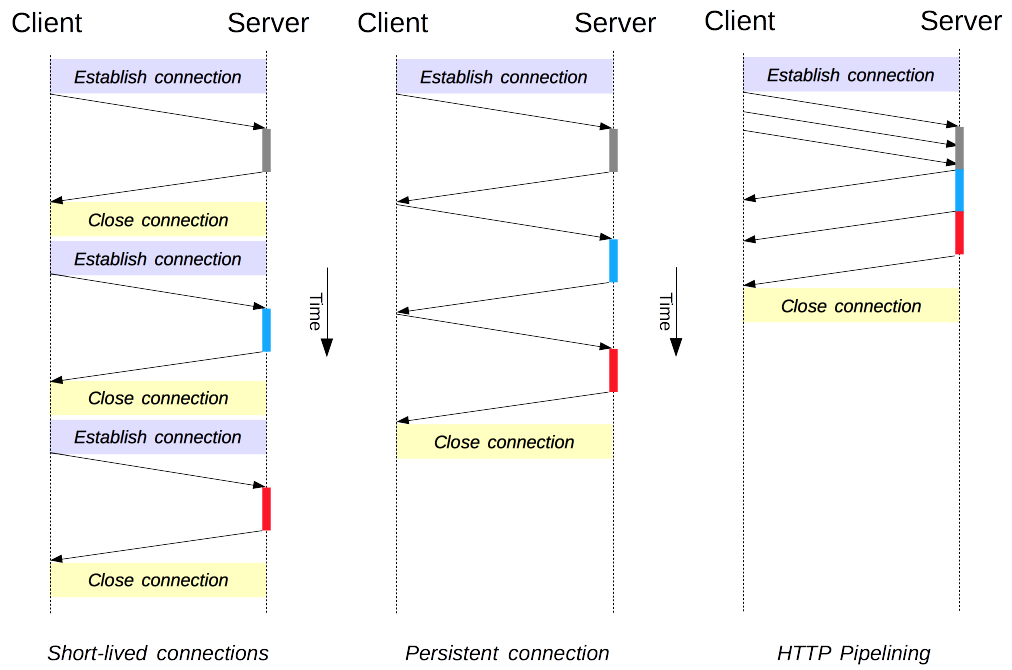
連接管理是一個 HTTP 的關鍵話題:打開和保持連接在很大程度上影響著網站和 Web 應用程式的性能,在 HTTP/1.x 里有多種模型:短連接, 長連接, 和 HTTP 流水線,
-
HTTP 的傳輸協議主要依賴于 TCP 來提供從客戶端到服務器端之間的連接,在早期,HTTP 使用一個簡單的模型來處理這樣的連接,這些連接的生命周期是短暫的:每發起一個請求時都會創建一個新的連接,并在收到應答時立即關閉,
-
這個簡單的模型對性能有先天的限制:打開每一個 TCP 連接都是相當耗費資源的操作,客戶端和服務器端之間需要交換好些個訊息,當請求發起時,網路延遲和帶寬都會對性能造成影響,現代瀏覽器往往要發起很多次請求(十幾個或者更多)才能拿到所需的完整資訊,證明了這個早期模型的效率低下,
-
有兩個新的模型在 HTTP/1.1 誕生了,首先是長連接模型,它會保持連接去完成多次連續的請求,減少了不斷重新打開連接的時間,然后是 HTTP 流水線模型,它還要更先進一些,多個連續的請求甚至都不用等待立即回傳就可以被發送,這樣就減少了耗費在網路延遲上的時間,
HTTP/2 新增了其它連接管理模型,
-
要注意的一個重點是 HTTP 的連接管理適用于兩個連續節點之間的連接,如 hop-by-hop,而不是 end-to-end,當模型用于從客戶端到第一個代理服務器的連接和從代理服務器到目標服務器之間的連接時(或者任意中間代理)效果可能是不一樣的,HTTP 協議頭受不同連接模型的影響,比如 Connection 和 Keep-Alive,就是 hop-by-hop 協議頭,它們的值是可以被中間節點修改的,
-
一個相關的話題是HTTP連接升級,在這里,一個HTTP/1.1 連接升級為一個不同的協議,比如TLS/1.0,Websocket,甚至明文形式的HTTP/2,
🏳??🌈短連接
-
HTTP 最早期的模型,也是 HTTP/1.0 的默認模型,是短連接,每一個 HTTP 請求都由它自己獨立的連接完成;這意味著發起每一個 HTTP 請求之前都會有一次 TCP 握手,而且是連續不斷的,
-
TCP 協議握手本身就是耗費時間的,所以 TCP 可以保持更多的熱連接來適應負載,短連接破壞了 TCP 具備的能力,新的冷連接降低了其性能,
-
這是 HTTP/1.0 的默認模型(如果沒有指定 Connection 協議頭,或者是值被設定為 close),而在 HTTP/1.1 中,只有當 Connection 被設定為 close 時才會用到這個模型,
除非是要兼容一個非常古老的,不支持長連接的系統,沒有一個令人信服的理由繼續使用這個模型,
🏳??🌈長連接
-
短連接有兩個比較大的問題:創建新連接耗費的時間尤為明顯,另外 TCP 連接的性能只有在該連接被使用一段時間后(熱連接)才能得到改善,為了緩解這些問題,長連接 的概念便被設計出來了,甚至在 HTTP/1.1 之前,或者這被稱之為一個 keep-alive 連接,
-
一個長連接會保持一段時間,重復用于發送一系列請求,節省了新建 TCP 連接握手的時間,還可以利用 TCP 的性能增強能力,當然這個連接也不會一直保留著:連接在空閑一段時間后會被關閉(服務器可以使用 Keep-Alive 協議頭來指定一個最小的連接保持時間),
-
長連接也還是有缺點的;就算是在空閑狀態,它還是會消耗服務器資源,而且在重負載時,還有可能遭受 DoS attacks 攻擊,這種場景下,可以使用非長連接,即盡快關閉那些空閑的連接,也能對性能有所提升
-
HTTP/1.0 里默認并不使用長連接,把 Connection 設定成 close 以外的其它引數都可以讓其保持長連接,通常會設定為 retry-after,
-
在 HTTP/1.1 里,默認就是長連接的,協議頭都不用再去宣告它(但我們還是會把它加上,萬一某個時候因為某種原因要退回到 HTTP/1.0 呢),
🏳??🌈HTTP 流水線
HTTP 流水線在現代瀏覽器中并不是默認被啟用的:
- Web 開發者并不能輕易的遇見和判斷那些搞怪的代理服務器的各種莫名其妙的行為,
- 正確的實作流水線是復雜的:傳輸中的資源大小,多少有效的 RTT 會被用到,還有有效帶寬,流水線帶來的改善有多大的影響范圍,不知道這些的話,重要的訊息可能被延遲到不重要的訊息后面,這個重要性的概念甚至會演變為影響到頁面布局!因此 HTTP 流水線在大多數情況下帶來的改善并不明顯,
- 流水線受制于 HOL 問題,
默認情況下,HTTP 請求是按順序發出的,下一個請求只有在當前請求收到應答過后才會被發出,由于會受到網路延遲和帶寬的限制,在下一個請求被發送到服務器之前,可能需要等待很長時間,
流水線是在同一條長連接上發出連續的請求,而不用等待應答回傳,這樣可以避免連接延遲,理論上講,性能還會因為兩個 HTTP 請求有可能被打包到一個 TCP 訊息包中而得到提升,就算 HTTP 請求不斷的繼續,尺寸會增加,但設定 TCP 的 MSS(Maximum Segment Size) 選項,仍然足夠包含一系列簡單的請求,
并不是所有型別的 HTTP 請求都能用到流水線:只有 idempotent 方式,比如 GET、HEAD、PUT 和 DELETE 能夠被安全的重試:如果有故障發生時,流水線的內容要能被輕易的重試,
今天,所有遵循 HTTP/1.1 的代理和服務器都應該支持流水線,雖然實際情況中還是有很多限制:一個很重要的原因是,目前沒有現代瀏覽器默認啟用這個特性,
🏳??🌈域名分片
除非你有緊急而迫切的需求,不要使用這一過時的技術,升級到 HTTP/2 就好了,在 HTTP/2 里,做域名分片就沒必要了:HTTP/2 的連接可以很好的處理并發的無優先級的請求,域名分片甚至會影響性能,大多數 HTTP/2 的實作還會使用一種稱作連接凝聚的技術去嘗試合并被分片的域名,
-
作為 HTTP/1.x 的連接,請求是序列化的,哪怕本來是無序的,在沒有足夠龐大可用的帶寬時,也無從優化,一個解決方案是,瀏覽器為每個域名建立多個連接,以實作并發請求,曾經默認的連接數量為 2 到 3 個,現在比較常用的并發連接數已經增加到 6 條,如果嘗試大于這個數字,就有觸發服務器 DoS 保護的風險,
-
如果服務器端想要更快速的回應網站或應用程式的應答,它可以迫使客戶端建立更多的連接,例如,不要在同一個域名下獲取所有資源,假設有個域名是 www.example.com,我們可以把它拆分成好幾個域名:www1.example.com、www2.example.com、www3.example.com,所有這些域名都指向同一臺服務器,瀏覽器會同時為每個域名建立 6 條連接(在我們這個例子中,連接數會達到 18 條),這一技術被稱作域名分片,

💬總結
- 改進后的連接管理極大的提升了 HTTP 的性能,不管是 HTTP/1.1 還是 HTTP/1.0,使用長連接 – 直到進入空閑狀態 – 都能達到最佳的性能,
- 然而,解決流水線故障需要設計更先進的連接管理模型,HTTP/2 已經在嘗試了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289284.html
標籤:其他
上一篇:資料結構 第八篇:八大排序【插入,希爾,選擇,堆,歸并,快排,冒泡,計數】
下一篇:資料鏈路層 ?一看就懂了!!!