文章目錄
- 前言
- 一、建立高斯差分金字塔
- 1、建立高斯金字塔
- 2、建立高斯差分金字塔
- 3、建塔程序中引數的設定及相關細節問題
- 二、關鍵點(key points)位置確定
- 1、閾值化
- 2、在高斯差分金字塔中找極值點
- 3、調整極值點位置
- 4、舍去低對比度的點
- 5、邊緣效應的去除(難點)
- 三、為關鍵點賦予方向
- 1、亞像素點尺度去對應離散點尺度
- 2、統計
- 3、找到主方向
- 四、構建關鍵點的描述符
- 1、旋轉至主方向所在方向
- 2、確定關鍵點附近區域的大小,
- 3、在確定的區域上做128維描述符統計
- 總結
前言
SIFT(Scale Invariant Feature Transform)即尺度不變特征變換演算法,該特征向量集具有對影像縮放,平移,旋轉不變的特征,在對圖片進行特征提取及匹配時,對于光照、仿射和投影變換也有一定的不變性,是一個魯棒性較強的特征提取與匹配演算法,以下是SIFT特征提取與匹配演算法的處理流程,
一、建立高斯差分金字塔
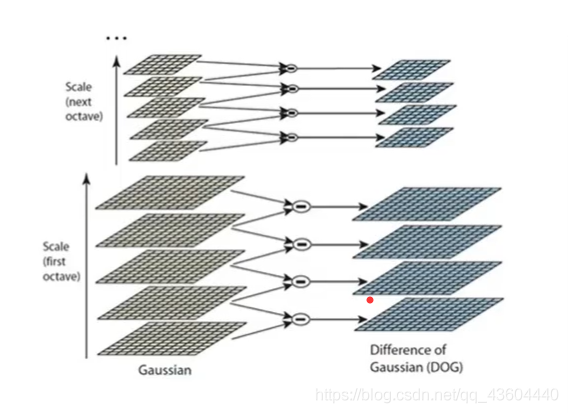
1、建立高斯金字塔
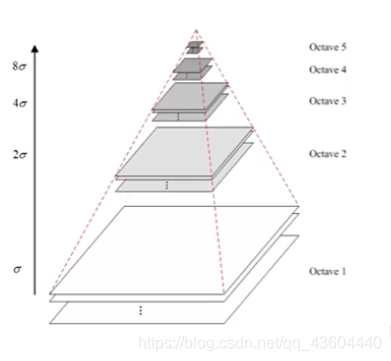
我們知道對于高斯核來說,可以用不同的方差σ計算得到不同的高斯核,通過不同尺度的高斯核對原始影像進行卷積(此處方差σ我們稱為尺度),卷積過后得到最下方的Octave1圖組,而高斯金字塔上方的Octave2圖組是由Ovtave1圖組進行隔點取點對Octave1圖組進行下采樣后,再用不同尺度的高斯核進行卷積得到的,也就是:
- 對Octave1圖組中的圖片進行隔點取點下采樣
- 對下采樣后的圖組進行不同尺度的高斯核卷積
通過以上兩個步驟,得到Octave2圖組,那依次類推,Octave3是由Octave2下采樣后再卷積得到的…這樣,我們得到了高斯金字塔,如下圖所示,
2、建立高斯差分金字塔
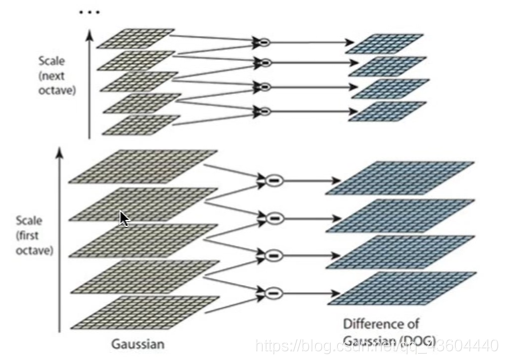
我們現在已經得到了影像的高斯金字塔,還不能結束,我們最終的目的是得到高斯差分金字塔,
由于相同圖組中的影像大小是一樣的,我們將相鄰兩層的影像像素點相減(此處的相減就是傳統意義上的減號),得到差分層,這樣我們對不同Octave層都進行此操作,得到高斯差分金字塔,如下圖所示,
3、建塔程序中引數的設定及相關細節問題
此處的引數主要是指兩個:
- O:高斯金字塔中,要有多少個Octave圖組
- S:高斯金字塔中,每個Octave組要有多少層
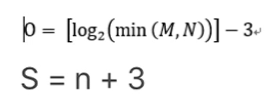
如上圖第一個公式,我們要選擇多少組其實可以自己設定,但原SIFT論文中給出了建議值,
- 對于O的選擇:M、N指原影像的長和寬,求最小值后開log再減3
- 對于S的選擇:n指我們希望提取多少個圖片中的特征,一般2個的話n也就是取2,加上3后S取5
現在萌生了第一個問題,3是怎么來的呢?為什么兩個公式中都有3?
答:對于這個問題,我們從結果來分析原因,我們可以看到上圖2中的高斯差分金字塔,對于原高斯金字塔中的5張圖,進行像素點相減操作后只能得到4張圖,對于4張圖片我們要找特征點,我們是在尺度空間(在前文中提到方差也就是尺度)中尋找極值點,那除了x、y兩個平面方向,還有一個尺度方向,我們可以理解為z軸,那對于最上面的差分層來說,由于它上面已經沒有圖片了,我們無法在z方向對它進行求導,也就是說我們無法在最上層的差分層找極值點了,同理,最下層的差分層也無法找極值點,
那最上層和最下層都無法找極值點,減去2,此時要注意,我們從高斯金字塔到高斯差分金字塔的變換程序中也損失了1層,再加上損失的這層,2+1,也就是3的由來了,
第二個疑問,SIFT為什么要建立高斯金字塔這樣的一種結構?
答:由于高斯金字塔是逐步下采樣得到的一個金字塔狀,我們希望演算法在對影像進行處理的時候,對于不同拍攝距離得到的圖片具有遠近特征的不變性,無論攝像機拿的遠近,對于同一個物體都可以識別,那高斯金字塔這種下大上小的結構也就模擬了這種構想,同樣,用高斯核去卷積實際上是模擬了近處清晰、遠處模糊,并且數學上有相關證明:高斯核是唯一一個可以模擬近處清晰、遠處模糊的線性核,這也就是為什么我們只能用高斯核的原因,
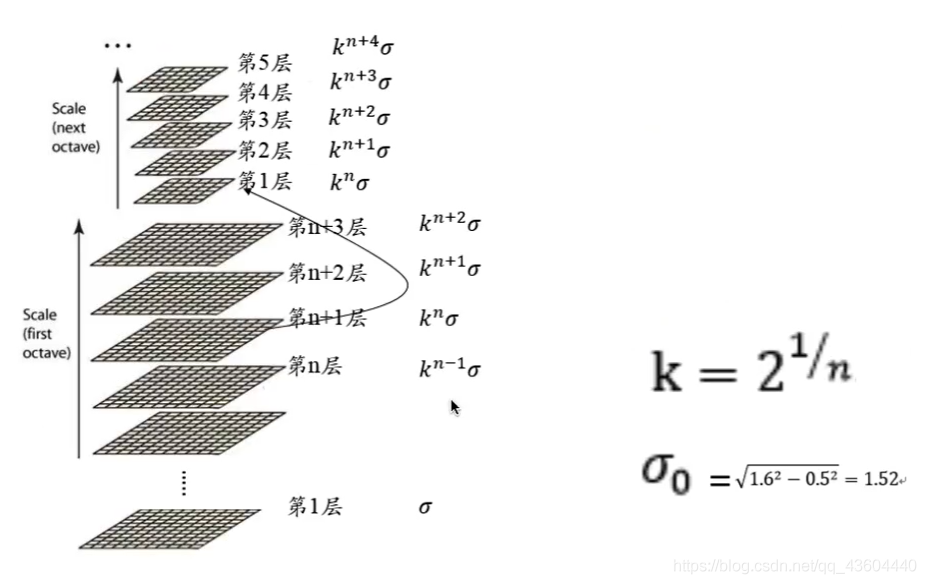
第三個疑問,建塔程序中的σ如何配置的呢?
答:如下圖所示,我們令k=2開n次方,對于Octave1中的第一層,我們直接用σ,第二層就乘上一個σ,即kσ,以此類推,對于Octave2中的第一層,我們取Octave1中的倒數第三層,因為倒數第三層的σ為k^nσ,也就是為了湊2σ,達到一個隔點取點的降采樣效果,
第四個疑問,σ0又是如何設定的呢?
由于我們相繼本身拍出的相片也不是完全清晰的,也具有一個模糊尺度,在論文中我們認為模糊尺度為0.5,我們希望第一次高斯核卷積后尺度可以達到1.6,那我們用1.52的方差σ0去卷積,就可以得到1.6的尺度,實際上這個程序是利用了高斯核的類勾股數性質,如圖右下方公式,
注:用0.5尺度的高斯核去卷積,將得到的結果再用1.52尺度的高斯核去卷積,以上操作跟直接用1.6尺度的高斯核去卷積得到的圖片,效果是一樣的,
二、關鍵點(key points)位置確定
1、閾值化
abs(val) > 0.5*T/n T=0.04
以上公式,通過閾值化去掉噪聲點,
2、在高斯差分金字塔中找極值點
由于我們是在尺度空間中進行極值點的查找的,除了平面x、y軸外還有個尺度的σ軸,所以我們要在26個點(三層)中找到極大值點或極小值點,如下圖所示,
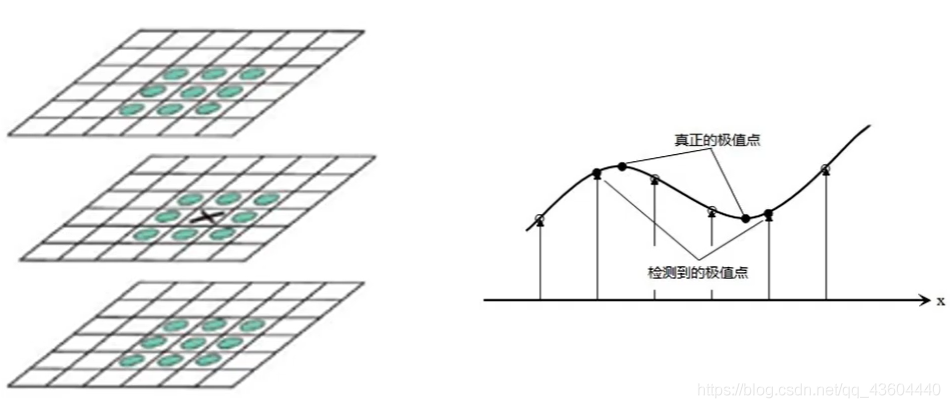
我們通過這種方式,實際上是在離散空間中找到極值點的,實際上,真實極值點存在的位置可能并不是在這些個離散點上的,而是在離散空間中我們找到的極值點附近的點,所以我們通過一些方式找到一個精確的亞像素位置的真正極值點,
那么,用什么方式來進行這個真實極值點尋找呢?泰勒展開,
3、調整極值點位置
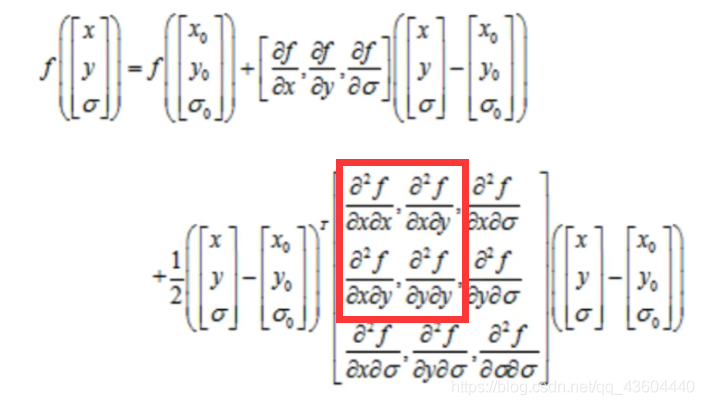
在檢測到的極值點X0附近做三元二階泰勒展開,也就是做一個X0處函式的近似,如下圖,
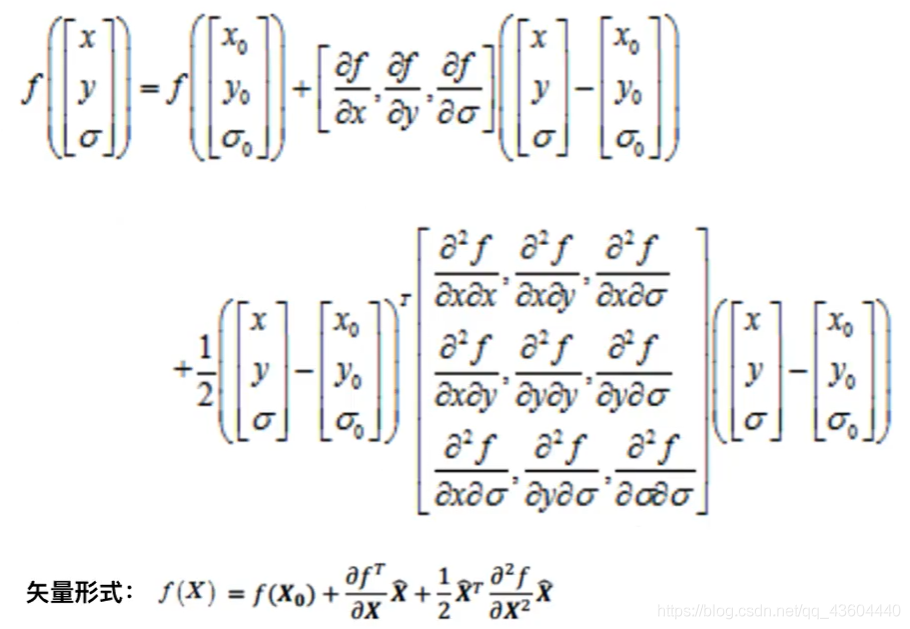
得到f(X)后,我們對f(X)求導,如下:
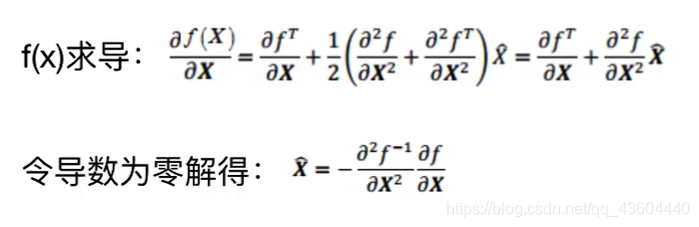
此處,我們得到的X一帽,相當于是我們得到的X0相對于真實極值點的位移量,我們將這個值反代入f(X)中,就得到了真實極值點的值,如下,
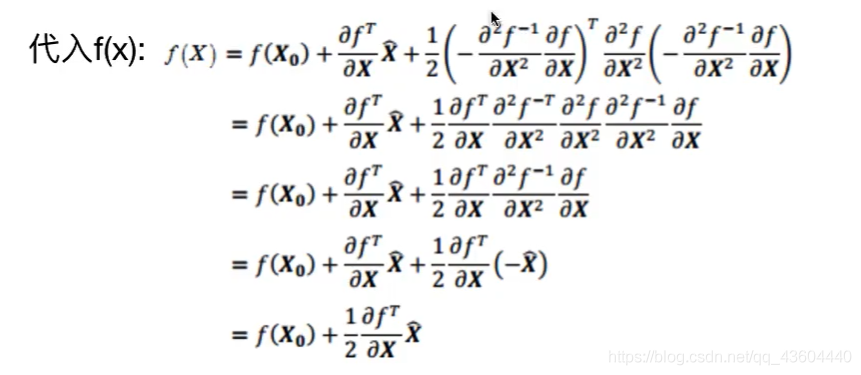
當然,在演算法實作時,我們求得真實極值點是一個迭代的程序,有三種情況:
- 設定的迭代條件:X一帽的三個分量x、y、σ均小于0.5時,方可成立,此時位移量已經足夠小了,我們就認為已經收斂了,
- 出現函式不收斂的情況,那我們將這么點直接舍去,
- 函式已經收斂,但解超出了一定范圍,舍去,
4、舍去低對比度的點
若|f(X)| < T/n,則舍去X
通過以上公式,舍去對比度較低的點,很可能是個噪聲點,
5、邊緣效應的去除(難點)
首先,我們引入一個海參矩陣,如下:
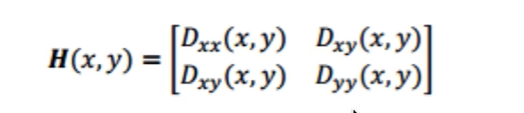
矩陣中的值,實際上就是上文求真實極值點程序中,框選的四個值,
海參矩陣可以描述函式的區域的曲率,我們希望某個點在x、y兩個方向的曲率差不多,否則的話它很可能是一個邊緣點,根據數學上的概念,海參矩陣的特征值和曲率是呈正比的,
此處我們不去算它的特征值,太麻煩了,通過引入跡和行列式來代替特征值α和β的關系,如下:

-
若Det(H)<0,說明兩個特征值已經異號了,也就是曲率肯定是不接近的,存在邊緣效應,直接舍去X點,
-
若Det(H)>0且α>β,說明γ>1,如下:
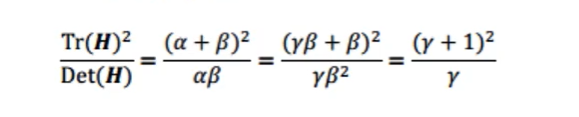
由于(γ+1)^2/γ化簡后是一個對勾函式,γ>1,也就變成了一個單增函式,那么在γ=1時就是他的最小值,由于γ=α/β,γ的值越小則曲率越低,我們為γ設定一個閾值,建議取10,也就是:

三、為關鍵點賦予方向
此時我們已經確定了關鍵點,下面要做的就是為關鍵點賦予方向,假設我們找到的關鍵點如下圖,紅點是關鍵點,
1、亞像素點尺度去對應離散點尺度
首先,我們在高斯金字塔上找到和關鍵點的σ值最接近的某個高斯圖層所對應的尺度σx,(也就是從亞像素點尺度去對應離散點的尺度)
2、統計
統計 以該特征點為圓心,以1.5倍的σx為半徑的圓內的所有梯度方向及其梯度幅值,并做1.5σ的高斯濾波,(此處做高斯濾波的意義就是為了加權,使得離中心越近的點權值越高)
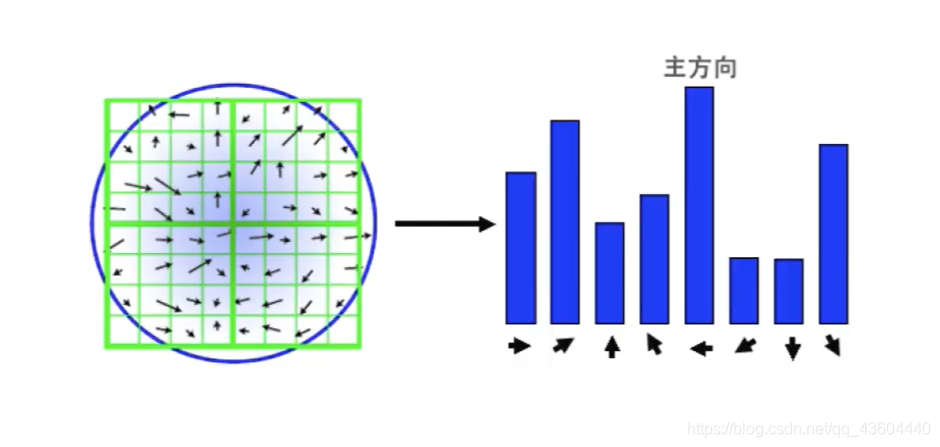
3、找到主方向
通過統計結果找到該特征點的主方向,也可能存在輔方向(>80%則有),對于有兩個方向的特征點,實際上我們是以兩個特征點去處理的,

四、構建關鍵點的描述符
通過上文操作,我們已經確定了關鍵點的xy位置資訊、尺度σ以及方向,為了方便后續關鍵點匹配,我們最后一步要做的就是構建關鍵點的描述符,在SIFT演算法中,描述符其實是一個128維的向量,在特征點匹配程序中,通過k近鄰等方式對特征點進行匹配,
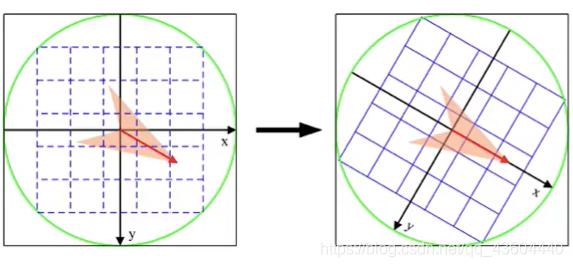
1、旋轉至主方向所在方向
將特征點周圍的區域旋轉至主方向所對應的方向,這也是SIFT演算法具有旋轉不變性的原因所在,
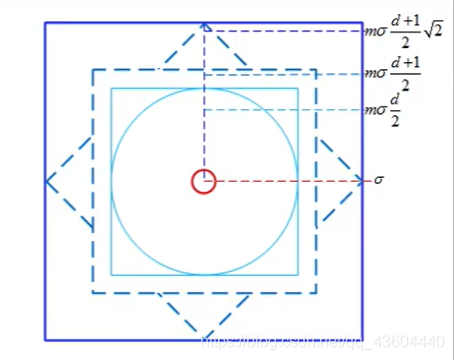
2、確定關鍵點附近區域的大小,
如下圖所示,論文中的區域大小是這樣設定的,m取3,mσ是指每個小區域的邊長大小,d是指所確定的區域中在x、y方向上有多少個小區域,論文中取4,
3、在確定的區域上做128維描述符統計
在4×4個子區域中,包含了很多梯度方向,經過高斯加權后,在每個子區域中統計8個方向的梯度長度,128維向量是怎么來的呢?16*8,16是指16個子區域,8是指8個方向,那么我們按照順序將128個梯度長度標記即可得到關鍵點的描述符,
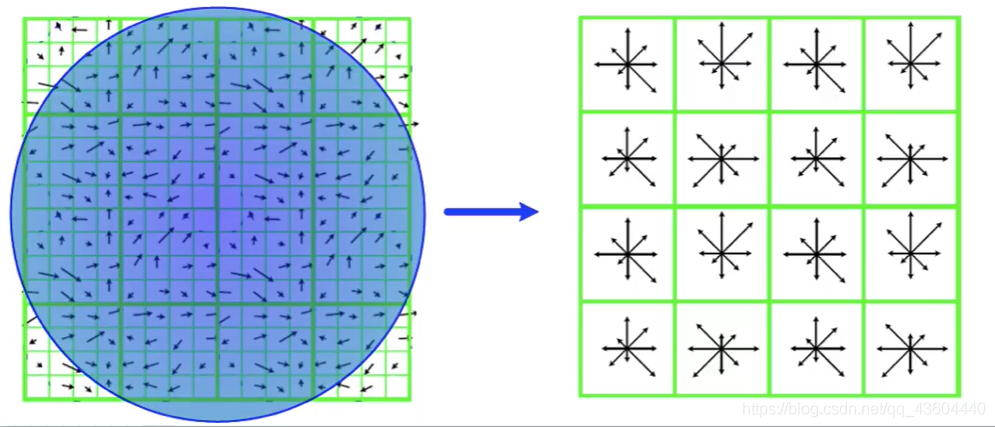
完成關鍵點進行描述后,我們就可以用K近鄰等方式對最接近的兩個關鍵點進行匹配,這樣也就完成了特征點的匹配作業啦!
總結
本文具體介紹了SIFT演算法的原理及流程,之前用SIFT、SURF、ORB等演算法做過相關專案,但僅僅是跑了代碼,演算法原理也沒有很理解,這次終于把SIFT部分梳理通透啦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289413.html
標籤:其他