文章目錄
- 1 問題引入:為什么需要自注意力機制
- 1.1 更加復雜的輸入
- 1.2 更多可能的輸出
- 1.2.1 每一個向量都有一個對應的Label
- 1.2.2 輸入多個向量,只需要輸出一個Label
- 1.2.3 機器要自己決定應該輸出多少個Label
- 1.3 處理詞性標注問題的困境
- 2 自注意力機制(Self-Attention)
- 3 Self-Attention的具體運作程序
1 問題引入:為什么需要自注意力機制
在探討了CNN的架構以后,我們要探討的另一個常見的Network架構,叫做Self-Attention,至于Self-Attention 是什么我們先按下不表,我們先來看看Self-Attention出現的背景,
1.1 更加復雜的輸入
到目前為止,我們的Network的輸入都是一個向量,而且這個向量的大小往往是固定的,就像我們在CNN中要求輸入的圖片大小需要統一,那現在假設我們的輸入是多個向量,并且輸入向量的個數是不確定的,那我們又該如何處理呢?
假設我們今天要Network處理的輸入是一個句子,每一個句子的長度都不一樣,并且每個句子里面詞匯的數目也不一樣,
如果我們把一個句子里面的每一個詞匯,都描述成一個向量,那我們的輸入就會是一個Vector Set,而且每次輸入時句子的長度不一樣,Vector Set的大小就不一樣,至于怎么把一個詞匯表示成一個向量,最簡單的做法是One-Hot的Encoding

但是One-Hot的Encoding的表示方法有一個非常嚴重的問題,它假設所有的詞匯彼此之間都是沒有關系的,但事實上Cat跟Dog都是動物所以他們的表示應該比較接近,而Cat跟Apple一個動物一個植物,他們的表示應該比較疏遠,能夠實作這種表示的一個方法叫做Word Embedding,
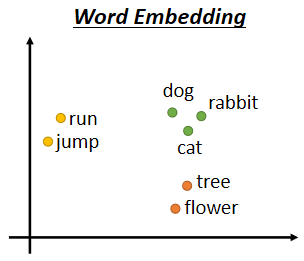
Word Embedding 給每個單詞分配一個固定長度的向量表示,這個長度可以自行設定,比如300,實際上會遠遠小于字典長度(比如10000),而且兩個單詞向量之間的夾角值可以作為他們之間關系的一個衡量
如果你把Word Embedding畫出來的話,你會發現所有的動物可能聚集成一團,所有的植物可能聚集成一團,所有的動詞可能聚集成一團等等,
1.2 更多可能的輸出
我們的輸入是一堆向量,它可以是文字,可以是語音,可以是Graph,那這個時候,我們有可能有什么樣的輸出呢,有如下的三種可能性:
1.2.1 每一個向量都有一個對應的Label
當你的模型看到輸入是四個向量的時候,它就要輸出四個Label,而每一個Label如果是一個數值,那就是Regression的問題;如果是一個Class,那就是一個Classification的問題
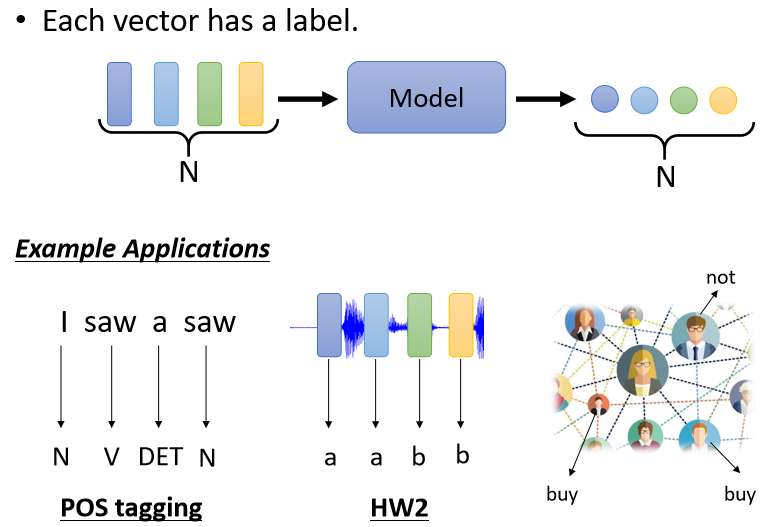
舉例來說,在文字處理的問題上,假設你今天要做的是POS Tagging,POS Tagging就是詞性標注,你要讓機器自動識別句子中的每一個詞匯是什么詞性,它是名詞、動詞還是形容詞等等,
這個任務其實并沒有很容易,舉例來說,你現在看到一個句子,“I saw a saw.” 這句話的意思是“我看到一個鋸子”,第一個saw是動詞,而第二個saw是名詞,對于這種一詞多義的情況,處理起來還是比較困難的,總之這個任務的輸入跟輸出的長度是一樣的,這就屬于我們所說的每一個向量都有一個對應的Label這種情況,
1.2.2 輸入多個向量,只需要輸出一個Label
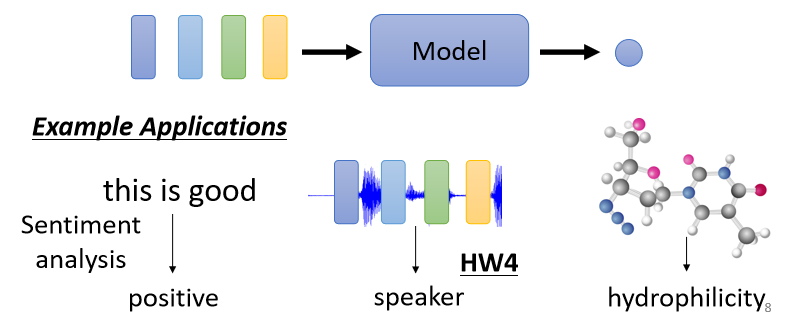
舉例來說,如果輸入是句子的話,我們需要做Sentiment Analysis,就是給機器看一段話,它要決定說這段話是正面的還是負面的,這樣一整個句子的輸入只需要產生一個輸出的Label,表示Positive或者Negative,
1.2.3 機器要自己決定應該輸出多少個Label
有時候我們不知道應該最終需要輸出多少個Label,機器要自己決定,這種任務又叫做sequence to sequence的任務,
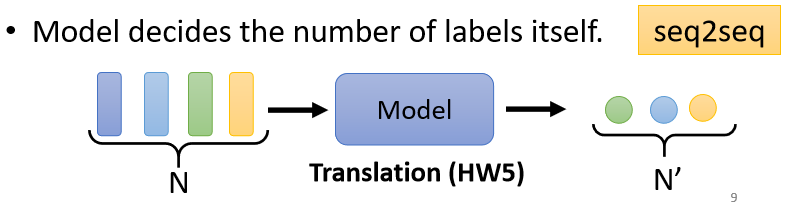
翻譯就是sequence to sequence的任務,因為輸入輸出是不同的語言,它們的詞匯的數目本來就不會一樣多,此外語音辨識也是sequence to sequence的任務,輸入一句話的語音信號,輸出一段文字,
1.3 處理詞性標注問題的困境
對于之前提到的三種可能的輸出,第一種可能,也就是輸入跟輸出數目一樣多的狀況又叫做Sequence Labeling,我們需要給Sequence里的每一個向量一個對應的Label,那要怎么解決這個問題呢?
由于我們以前的Fully Connected的Network都是一個輸入一個輸出,那既然要多個輸入多個輸出,最直觀的想法就是我們用多個Fully Connected的Network來分別接收輸入Sequence中的每一個向量,再對應輸出就好,
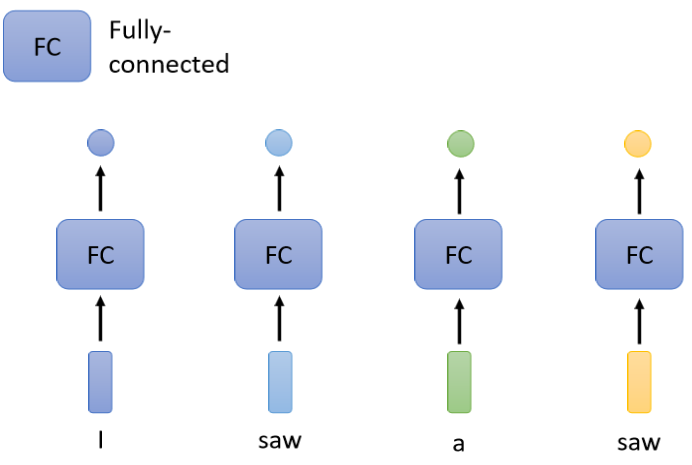
那這么做有一個很明顯的問題,假設我們的Network是做詞性標記的任務,你給機器一個句子 “I saw a saw”,對Fully Connected Network來說,后面這一個saw跟前面這個saw完全一模一樣,因為它們是同一個詞匯,所有分別處理這兩個saw的Network輸入同一個詞匯,它沒有理由輸出不同的東西,
但實際上我們卻期待機器在輸入第一個saw后要輸出動詞,輸入第二個saw后要輸出名詞,但現在看來用Fully Connected Network的方法是不可能做到的,那有沒有可能讓Fully Connected的Network在看到一個輸入的同時,還可以去考慮這個輸入的背景關系的資訊呢?
這當然是有可能的,我們可以簡單地把前后幾個向量都串起來,一起丟到Fully-Connected的Network就結束了,假如我們把當前要處理的向量和它的前一個以及后一個向量一起丟進Network,這三個向量就組成了我們的一個Window,這時這個Network的輸出就可以同時考慮這個Window內所有向量的資訊,
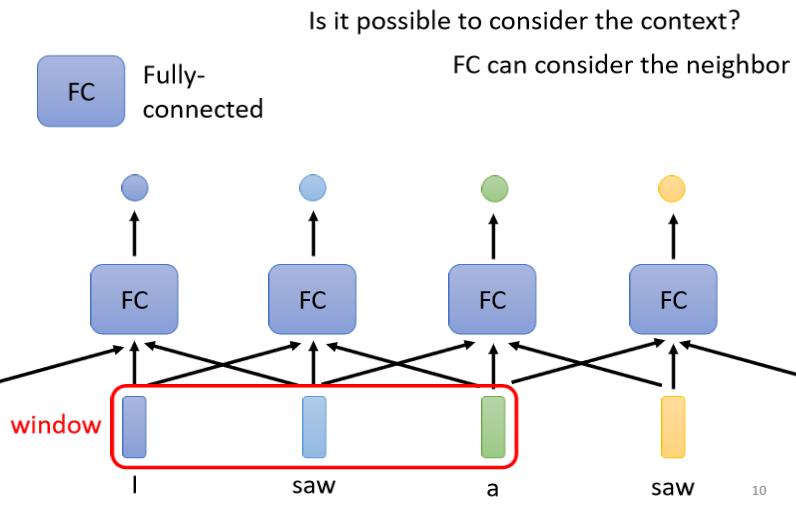
但如果今天我們有某一個任務,不是考慮一個Window就可以解決的,而是要考慮整個Sequence才能夠解決的話,又要怎么辦呢?
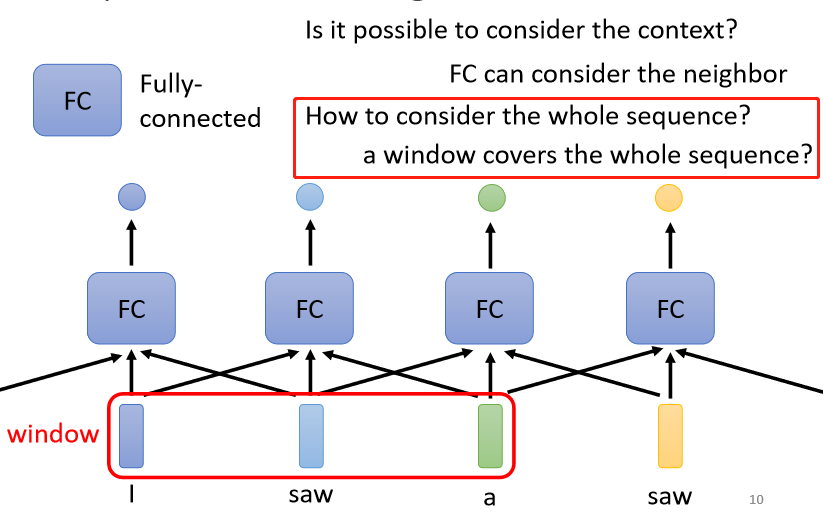
那我們可能會說這個很容易呀,把Window開大一點,大到可以把整個Sequence蓋住就可以了嘛,但實際上我們的Sequence的長度是有長有短的,如果真的要用一個Window把全部Sequence蓋住,那可能要統計一下訓練資料里面最長的Sequence有多長,但是如果開一個這么大的Window,意味著Fully Connected Network需要非常多的引數,那可能不只運算量很大,還容易Overfitting,
所以有沒有更好的方法來考慮整個Sequence的資訊呢,這就引出了接下來要介紹的Self-Attention這個技術,
2 自注意力機制(Self-Attention)
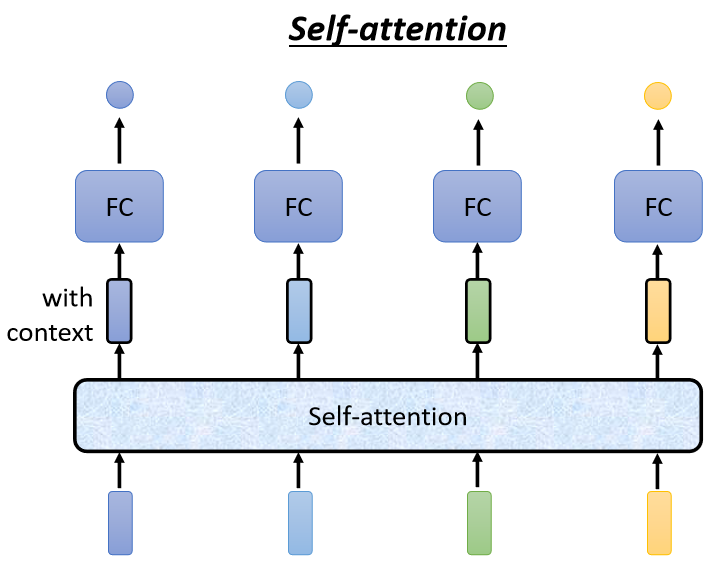
Self-Attention會考慮一整個Sequence的資訊,輸入幾個Vector它就輸出幾個Vector,輸出的這4個Vector,他們都是考慮一整個Sequence以后才得到的,至于它是如何做到考慮一整個Sequence的資訊的,等一會兒再解釋,
而且Self-Attention不是只能用一次,你可以疊加很多次,可以Self-Attention的輸出,通過Fully Connected Network以后,再做一次Self-Attention,Fully-Connected的Network,如下圖所示,最后再得到最終的結果,所以可以把Fully Connected的Network跟Self-Attention交替使用,
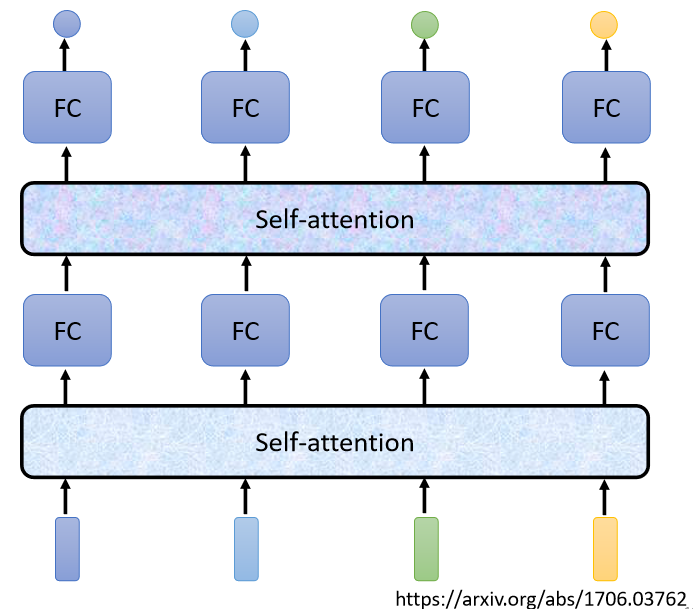
有關Self-Attention,最知名的一篇文章就是 Attention Is All You Need (arxiv.org),在這篇Paper里面,Google提出了Transformer這樣的Network架構,Transformer的架構之后會講到,這里我們只需要知道Transformer里面一個最重要的Module就是Self-Attention,它就是變形金剛的火種源,

接下來我們來看一看Self-Attention具體是怎么運作的,它是如何做到考慮一整個Sequence的資訊的,
3 Self-Attention的具體運作程序
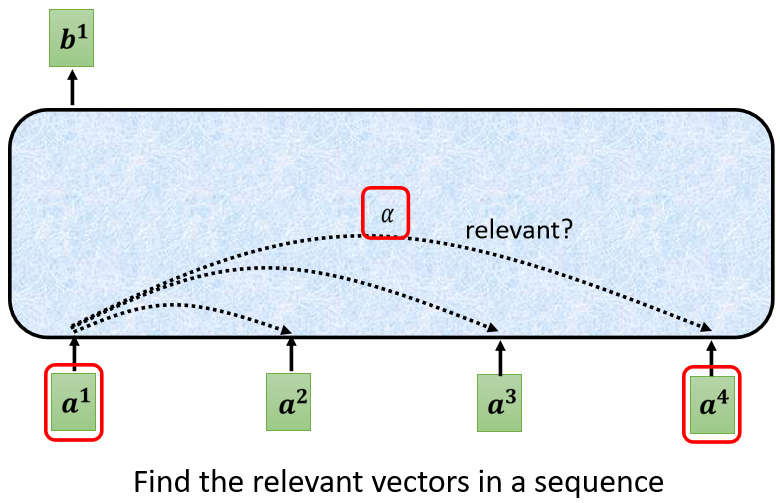
我們假設Self-Attention的Input就是一串的Vector,那這個Vector可能是你整個Network的Input,也可能是某個Hidden Layer的Output,所以我們這邊不是用 x x x來表示它,而是用 a a a來表示它,代表它有可能是前面已經做過一些處理,
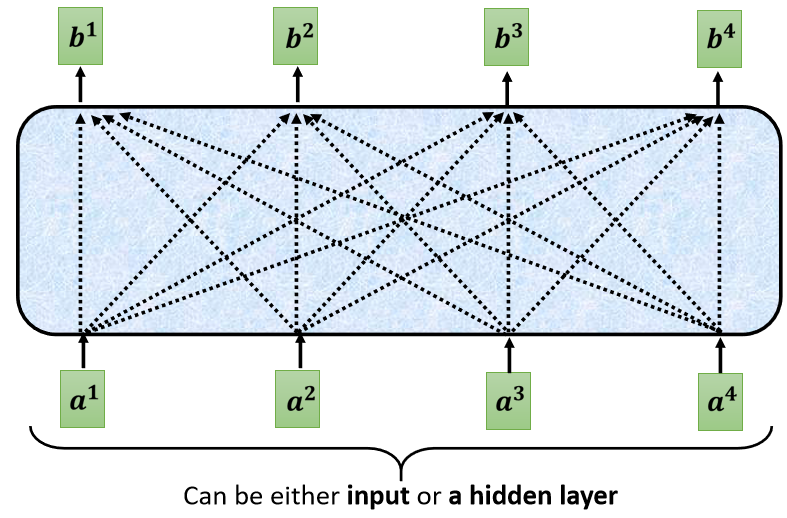
所以從上圖可以看到我們的Self-Attention會輸入一排向量 a a a,最后輸出另外一排向量 b b b,
那這每一個b都是考慮了所有的a以后才生成出來的,所以這邊刻意畫了非常非常多的箭頭,告訴你$b^1 考 慮 了 考慮了 考慮了a1$到$a4 產 生 的 , 產生的, 產生的,b2$考慮$a1 到 到 到a4$產生的,$b3 b^4$也是一樣,考慮整個input的sequence,才產生出來的
接下來我們來說明一些怎么產生 b 1 b^1 b1這個向量,剩下的 b 2 b 3 b 4 b^2 b^3 b^4 b2b3b4的產生程序和 b 1 b^1 b1是完全類似的,
產生 b 1 b^1 b1這個向量的程序中有一個特別的機制,這個機制是根據 a 1 a^1 a1這個向量,找出整個很長的sequence里面哪些部分跟判斷 a 1 a^1 a1是哪一個label是有關系的,哪些部分是我們要決定 a 1 a^1 a1的class,決定 a 1 a^1 a1的regression數值的時候,所需要用到的資訊,每一個向量跟 a 1 a^1 a1的關聯的程度,用一個數值叫α來表示
那這個Self-Attention的模塊怎么表達兩個向量之間的關聯性呢,就比如兩個向量 a 1 a^1 a1跟 a 4 a^4 a4,它怎么決定 a 1 a^1 a1跟 a 4 a^4 a4有多相關,然后給它一個數值α呢,這就需要在這個Self-Attention的模塊的里面有一個計算attention的模組:
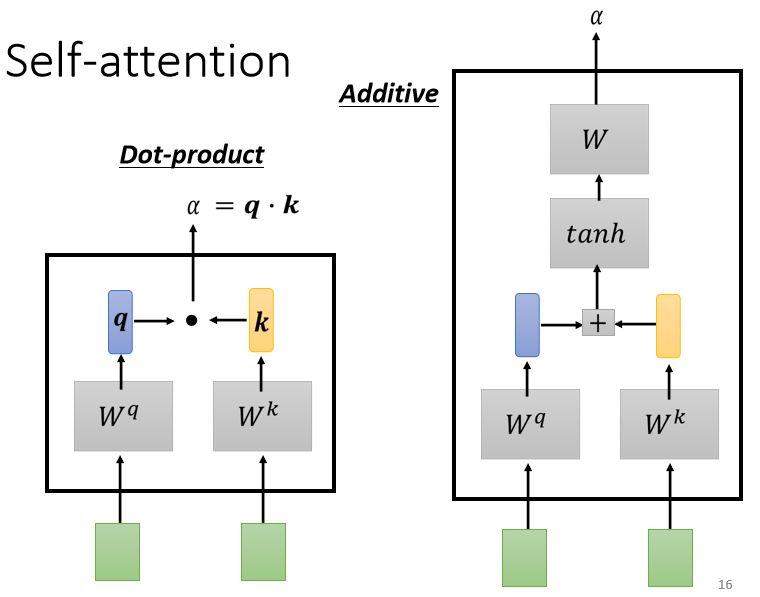
這個計算attention的模組用兩個向量作為輸入,然后直接輸出表示兩者相關性的α這個數值,而計算這個α的數值有兩種比較常見的做法:
-
第一個做法呢叫做dot product,輸入的這兩個向量分別乘上兩個不同的矩陣,左邊的向量乘上 W q W^q Wq這個矩陣得到矩陣 q q q,右邊的向量乘上 W k W^k Wk這個矩陣得到矩陣 k k k,再把 q q q跟 k k k做element-wise 的相乘(對應位置的元素逐個相乘),再全部加起來以后就得到一個數值α,
-
另外一種做法叫做Additive,它同樣把輸入的兩個向量通過 W q W^q Wq W k W^k Wk得到 q q q跟 k k k,但之后不是把它們逐元素相乘,而是直接把 q q q跟 k k k串起來,然后通過一個Activation Function,最后再通過一個變換得到α,
但是在接下來的討論里,我們都只用左邊這個方法,這也是今日最常用的方法,也是用在Transformer里面的方法,回到剛剛的問題上來,我們就需要把 a 1 a^1 a1去跟另外的 a 2 a 3 a 4 a^2 a^3 a^4 a2a3a4,分別去計算他們之間的關聯性,也就是計算他們之間的α
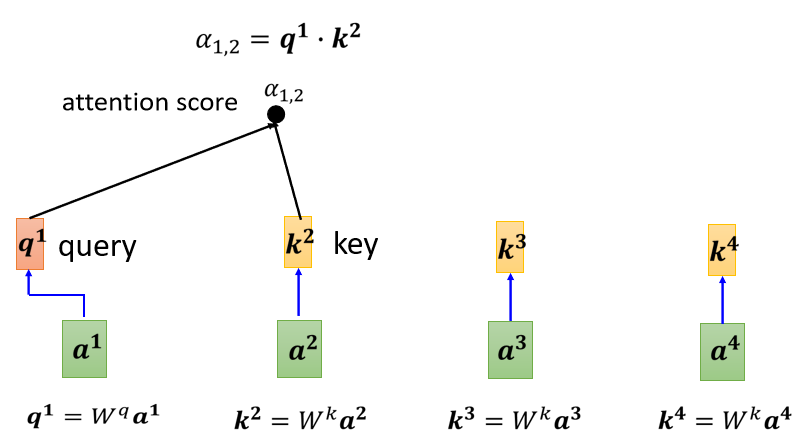
把 a 1 a^1 a1乘上$W^q 得 到 得到 得到q^1 , 那 這 個 ,那這個 ,那這個q$有一個名字,我們叫做Query,它就像是你在操作搜索引擎時候搜索的關鍵字,所叫做Query,
接下來呢, a 2 a 3 a 4 a^2 a^3 a^4 a2a3a4都要分別乘上 W k W^k Wk,得到 k k k這個Vector,這個 k k k呢我們叫做Key,然后你**把Query q 1 q^1 q1跟這個Key k 2 k_2 k2?逐元素相乘,最后相加就得到α,**我們這里得到的 α 1 , 2 α_{1,2} α1,2?,下標的1表示Query是 a 1 a^1 a1提供的,下標中的2表示Key是 a 2 a^2 a2提供的時候,這個 α 1 , 2 α_{1,2} α1,2?也叫做Attention的Score,表示了 a 1 a 2 a^1 a^2 a1a2之間的相關性,
計算完 α 1 , 2 α_{1,2} α1,2?后, a 1 a^1 a1接下來也要跟 a 3 a 4 a^3 a^4 a3a4來分別計算Attention Score,分別是 α 1 , 3 α_{1,3} α1,3?, α 1 , 4 α_{1,4} α1,4?,
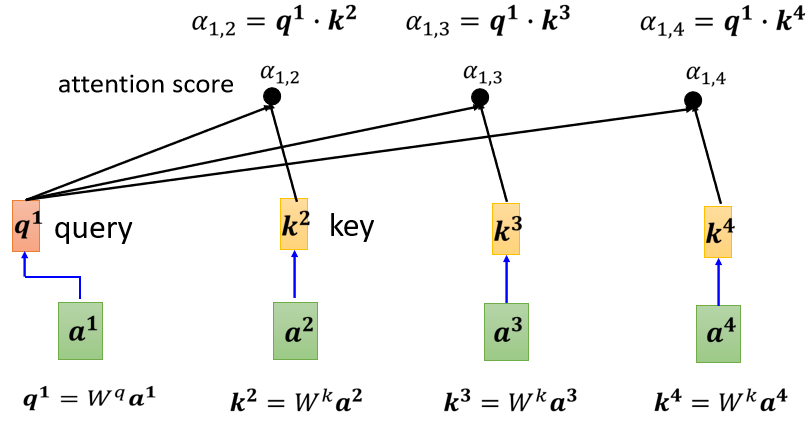
一般在實踐中, a 1 a^1 a1也會自己跟自己算關聯性,這件事情其實是很重要的,不計算的話可能會導致最終的結果有很大的偏差,在計算完 a 1 a^1 a1跟每一個向量的關聯性以后,最后這些輸出會通過一個SoftMax層,
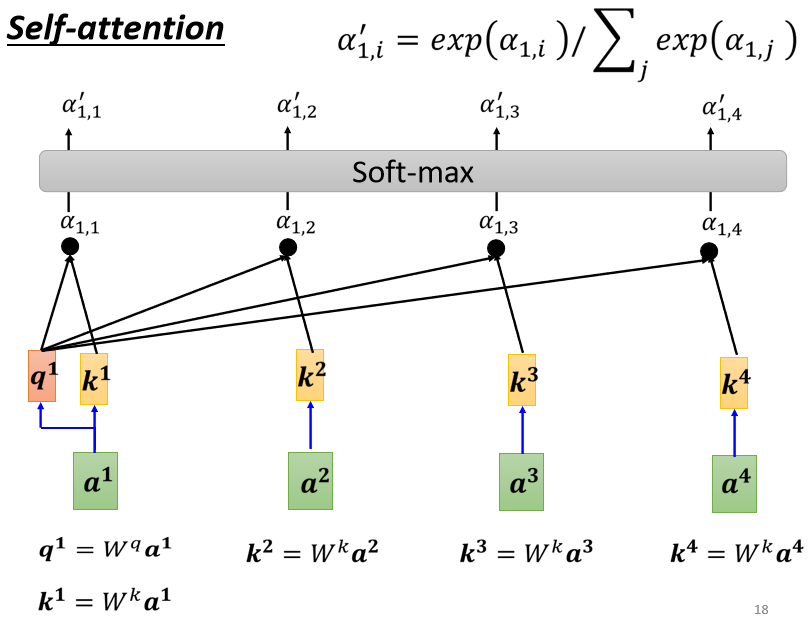
這個SoftMax跟分類的時候那個SoftMax是一模一樣的,當然這里用ReLU作為激活函式也可以,α通過Soft-Max后就得到了 α ′ α' α′,接下來得到這個 α ′ α' α′以后,我們就要根據這個 α ′ α' α′去抽取出這個Sequence里面重要的資訊,具體要怎么做呢?
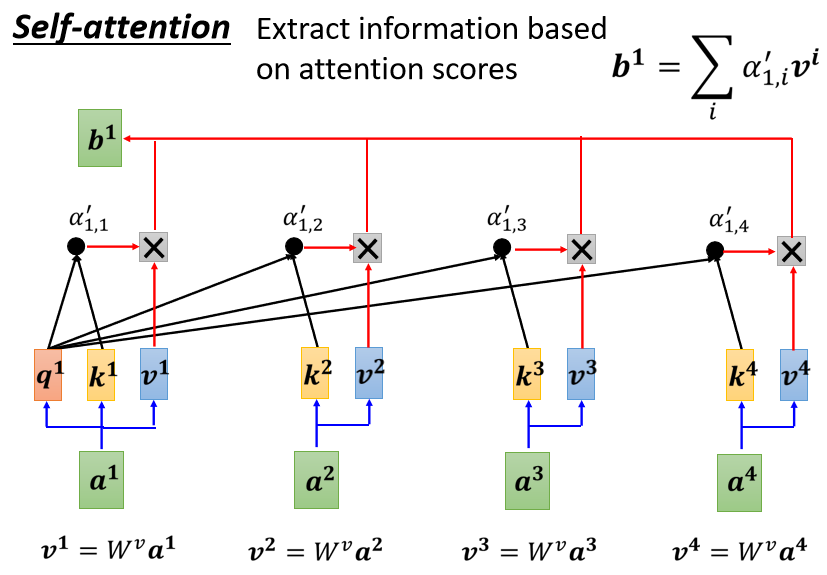
-
首先把 a 1 a^1 a1到 a 4 a^4 a4的每一個向量都乘上$W^v 得 到 新 的 向 量 , 分 別 就 是 用 得到新的向量,分別就是用 得到新的向量,分別就是用v^1 v^2 v^3 v^4$來表示,
-
接下來把 v 1 v^1 v1到 v 4 v^4 v4的每一個向量都去乘上對應Attention的分數,也就是乘上對應的 α ′ α' α′,
-
最后再這些乘出來的結果加起來,就得到 b 1 b^1 b1
b 1 = ∑ i α 1 , i ′ v i b^1=\sum_i\alpha'_{1,i}v^i b1=i∑?α1,i′?vi
事實上誰的Attention的分數最大,誰的 v v v就會主導最終生成的 b 1 b^1 b1這個結果,因為我們生成的 b 1 b^1 b1最主要的還是要看 a 1 a^1 a1,這就是為什么之前提到 a 1 a^1 a1要和自己算一個Attention的分數,自己跟自己的關聯度肯定是最大的,這就保證了 a 1 a^1 a1的主導地位,再接著考慮其他變數Attention的分數,實質上就是考慮了 a 1 a^1 a1的背景關系,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289430.html
標籤:AI
上一篇:深度學習 端對端的車牌檢測與識別 LPDR演算法 License Plate Detection and Recognition