文章目錄
- 基本優化思想和最小二乘法
- 1. 簡單線性回歸的機器學習建模思路
- 回顧簡單線性回歸建模問題
- 最優化問題的求解方法
- 圖形展示目標函式
- SSE最小值
- 2. 機器學習一般流程
- 3. 第一個優化演算法:最小二乘法
- 最小二乘法的表示方法
- 代數表示法
- 最小二乘法的矩陣表示形式
- 最小二乘法的簡單實作
- 4. 反向驗證導數為0
- torch.autograd.grad 函式
基本優化思想和最小二乘法
1. 簡單線性回歸的機器學習建模思路
回顧簡單線性回歸建模問題
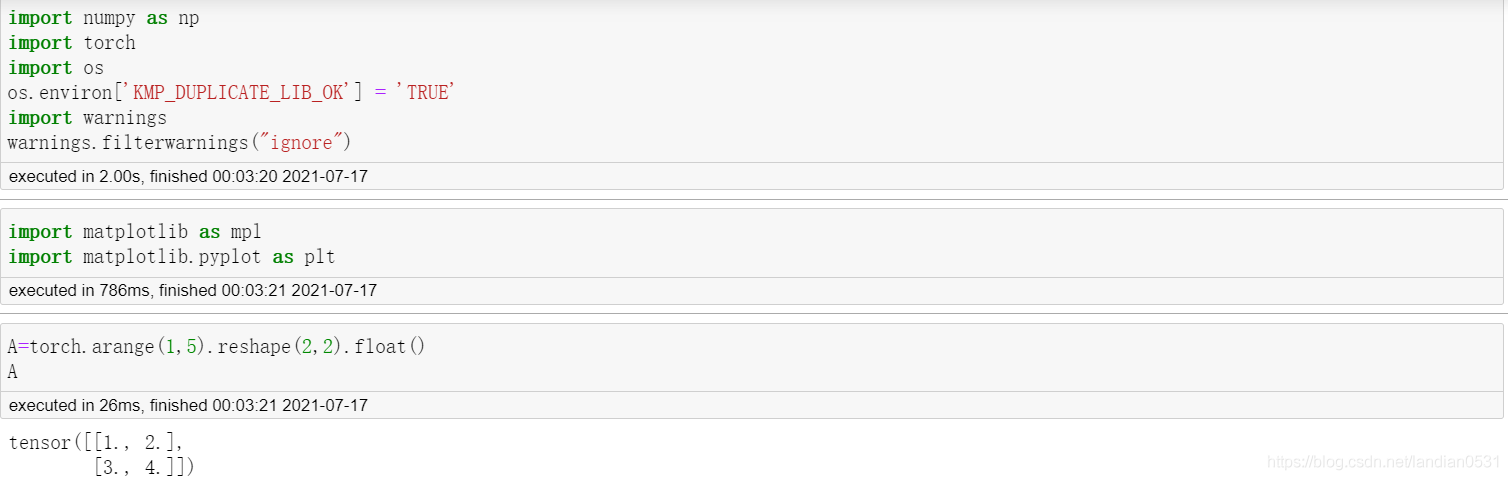
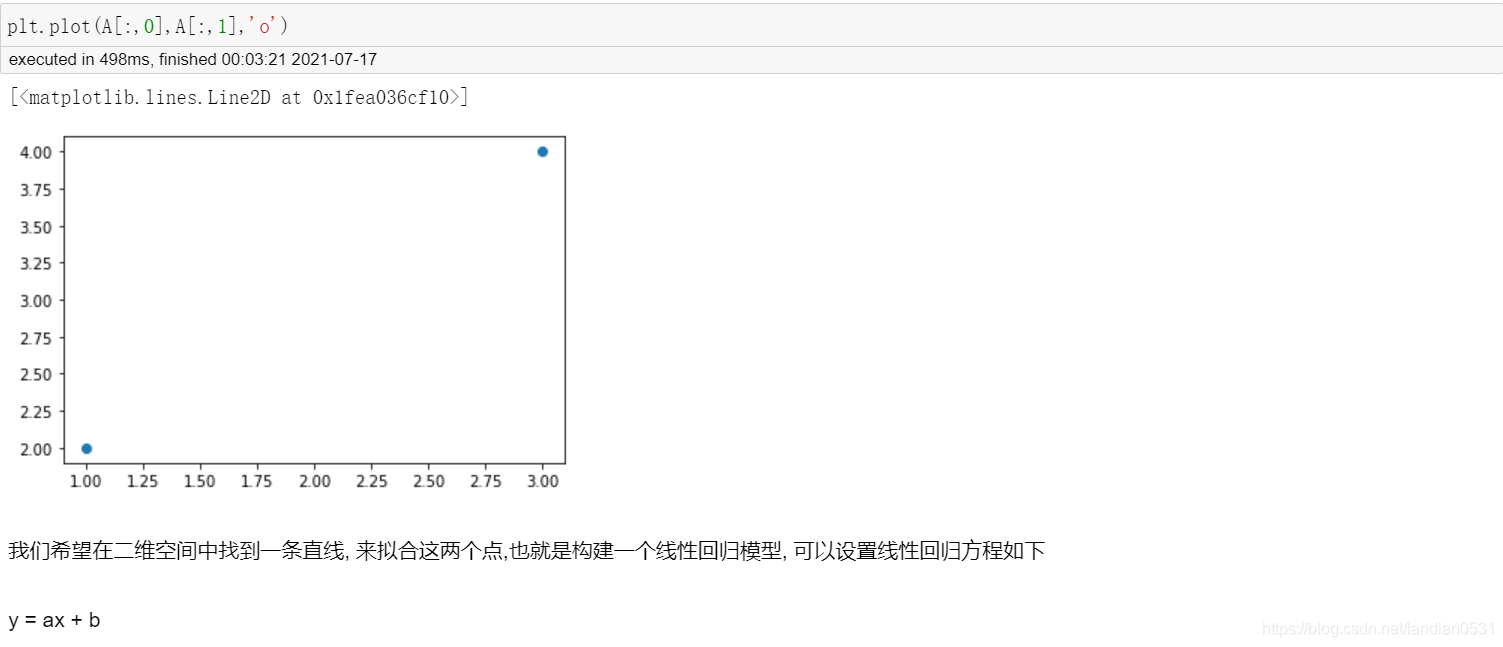
上述問題除了可以用矩陣方程求解以外, 可以轉化成最優化問題,通過求解最優化問題的方法對其進行求解.
總的來說, 最優化問題的轉發分為兩步, 其一是確定最優化數值指標, 其二則是確定優化目標函式.
如果我們希望通過一條直線擬合二維平面上分布的點, 最核心的目標,毫無以為就是希望方程的預測值和真實值相差較小. 假設真實的y值用
y
y
y表示, 預測值用
y
^
\hat{y}
y^? 表示,帶入a, b引數, 則有數值表示如下:

而這兩個預測值和真實值相差:
y 1 y_1 y1? = 2, y ^ 1 \hat{y}_1 y^?1? = a + b, y 1 y_1 y1? - y ^ 1 \hat{y}_1 y^?1? = 2 - a - b
y 2 y_2 y2? = 4, y ^ 2 \hat{y}_2 y^?2? = 3a + b, y 2 y_2 y2? - y ^ 2 \hat{y}_2 y^?2? = 4 - 3a - b
我們希望 y ^ \hat{y} y^? 和 y y y 盡可能接近, 所以我們可以考慮計算上述誤差總和. 但為了避免正負相消(一部分為正, 另一部分為負), 在衡量上述兩個點的誤差總和時, 我們使用平方和進行衡量, 而不是簡單的求和:
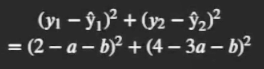
上式就是兩個點的預測值和真實值的差值的平方和, 也就是誤差平方和 - SSE (Sum of the Squared Errors)
至此, 我們已經把原問題轉化為一個最優化問題,接下來我們的問題就是, 當a, b取何值時, SSE取值最小? SSE是我們優化的目標方程(求最小值), 因此上述方程為目標函式. 同時 SSE代表真實值和預測值之間的差值(誤差平方和), 因此也被稱為損失函式(預測值距離真實值的損失)
目標函式和損失函式并不完全等價, 但大多數目標函式都有損失函式構成
最優化問題的求解方法
在機器學習領域, 大多數優化問題都是圍繞目標函式(或者損失函式)進行求解. 在上述問題中, 我們需要圍繞SSE求最小值. SSE是一個關于a和b的二元函式, 要求其最小值,需要借助數學工具,也就是最優化方法.
圖形展示目標函式
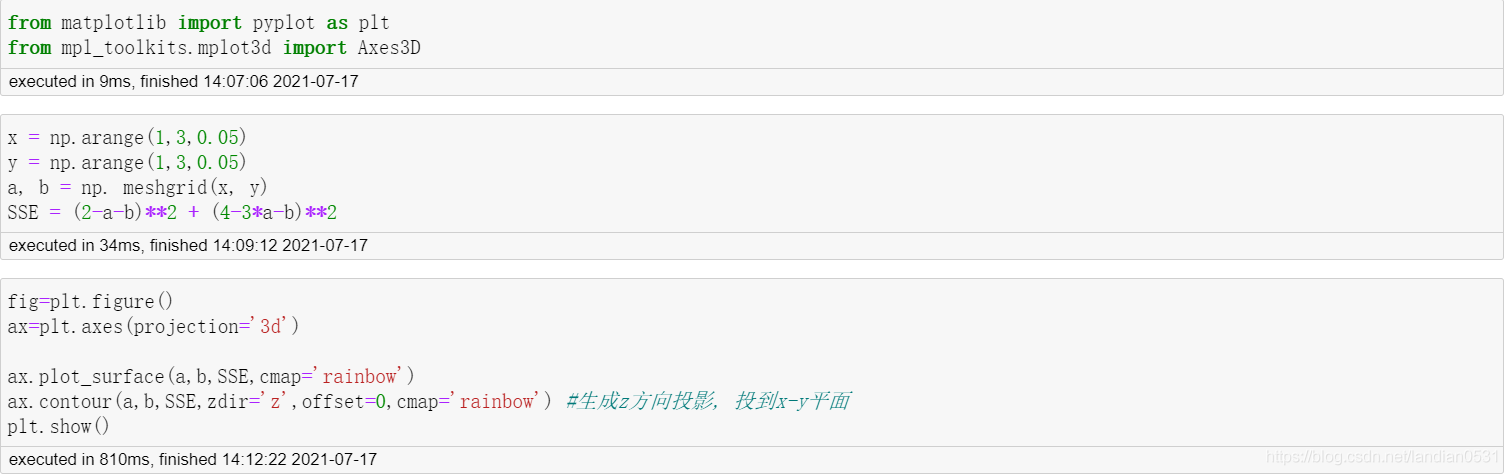


對于一個凸函式來說, 全域最小值明顯存在, 基于凸函式的數學定義, 我們可以進一步給出求解上述SSE凸函式最小值的一般方法, 也就是著名的最小二乘法.
駐點可以使說是臨界點, 但不是拐點, 拐點特指左右兩邊函式凹凸性發生變化的點,不可和駐點混淆.
SSE最小值
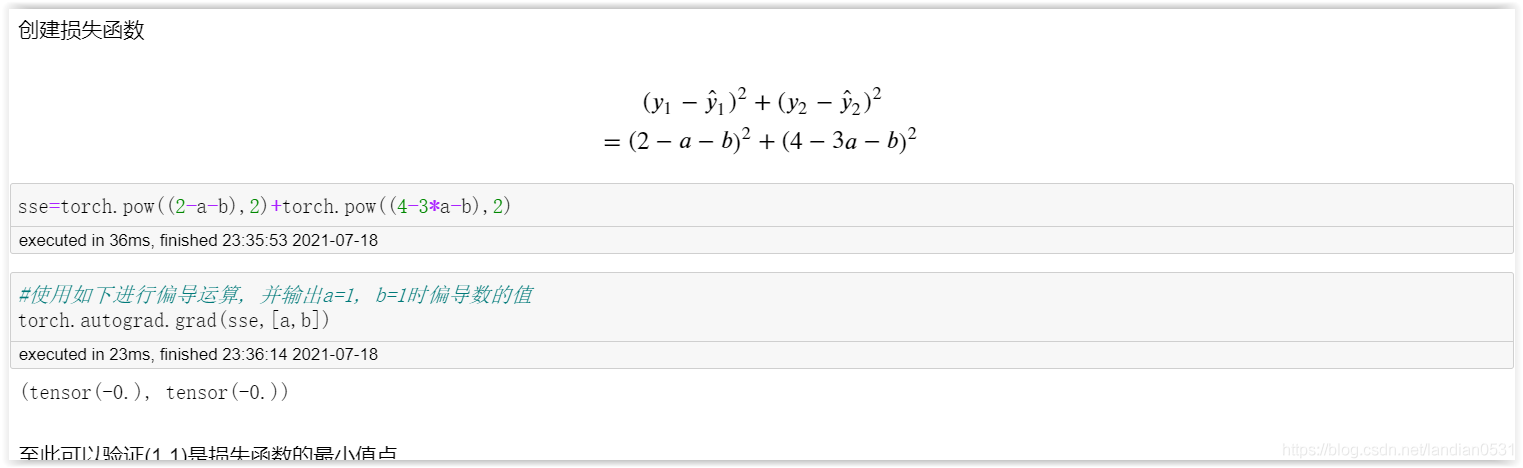
對于SSE來說, 對于簡單線性回歸的損失函式, SSE是凸函式,因此, 對于SSE(a,b) = ( 2 ? a ? b ) 2 (2-a-b)^2 (2?a?b)2 + ( 4 ? 3 a ? b ) 2 (4-3a-b)^2 (4?3a?b)2, 最小值點就是a, b兩個引數求偏導等于0的點
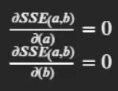

利用偏導等于得出的方程組求解線性回歸方程引數, 就是最小二乘法求解程序. 此處我們求得a = 1, b =1時, SSE(a,b)取得最小值, 也就是(1,1)時目標函式的最小值.
2. 機器學習一般流程
1). 提出基本模型
2). 確定損失函式和目標函式
3). 根據目標函式特性,選擇優化方法, 求解目標函式
3. 第一個優化演算法:最小二乘法
利用優化方法求解目標函式其實是機器學習建模程序中最為核心的環節. 因此圍繞上述簡單線性回歸問題, 進一步討論最小二乘法背后的數學邏輯和優化思想, 同事簡單探討資料的矩陣表示方法和基本矩陣運算.
同時,線性方程也是構建神經網路模型的基礎, 我們需要深入探討線性模型建模細節以及最基本的優化演算法: 最小二乘法.
最小二乘法的表示方法
兩種表示方式, 代數表示法和矩陣表示法
代數表示法
假設多元線性方程有如下形式:
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x) = {w_1}{x_1} + {w_2}{x_2}+...+ {w_d}{x_d} + b
f(x)=w1?x1?+w2?x2?+...+wd?xd?+b
令
w
w
w = (
w
1
w_1
w1?,
w
2
w_2
w2?,…
w
d
w_d
wd?),
x
x
x = (
x
1
x_1
x1?,
x
2
x_2
x2?,…
x
d
x_d
xd?), 則上式可寫為
f
(
x
)
=
w
T
x
+
b
f(x) = {w^T}x + b
f(x)=wTx+b
在機器學習領域, 線性回歸自變數系數命名為w, (weight)的簡寫, 意為自變數的權重
優化目標可寫為:
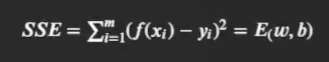
通過偏導為0求得最終結果的最小二乘求解程序為:
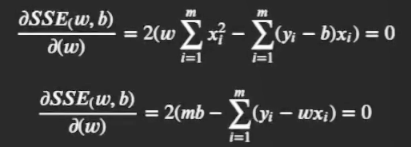
進而可得
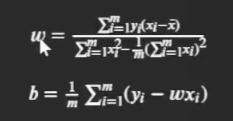
其中 x  ̄ \overline{x} x = 1 m ∑ i = 1 m x i \frac{1}{m}\sum_{i=1}^mx_i m1?∑i=1m?xi? , x 1 x_1 x1?為 x x x的均值, 并且( x i x_i xi?, y i y_i yi?)代表二維空間中的點,.
最小二乘法的矩陣表示形式
對于線性方程組來說, 矩陣表示是一種更加簡潔的表示方式, 并且對于支持陣列運算的torch來說,線性方程組的矩陣表示也更貼近代碼的實際書寫形式. 線性方程如下:
1 ? a + b = 2 3 ? a + b = 4 1*a+b=2 \\ 3*a+b=4 1?a+b=23?a+b=4
在轉化為矩陣表格的程序中, 令
A A A = [ 1 2 3 1 ] \begin{bmatrix} {1}&{2}\\ {3}&{1}\\ \end{bmatrix} [13?21?]
B B B = [ 2 4 ] \begin{bmatrix} {2}\\ {4} \end{bmatrix} [24?]
X T X^T XT = [ a b ] \begin{bmatrix} {a}\\ {b} \end{bmatrix} [ab?]
則原方程組可以表示為
A
?
X
T
=
B
A * X^T = B
A?XT=B
更一般的情況下, 多元線性回歸方程為
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x)={w_1}{x_1} +{w_2}{x_2}+ ... +{w_d}{x_d} + b
f(x)=w1?x1?+w2?x2?+...+wd?xd?+b
令
w ^ = ( w 1 x 1 + w 2 x 2 + . . . + w d x d + b ) \hat{w} = ({w_1}{x_1}+{w_2}{x_2}+...+{w_d}{x_d}+b) w^=(w1?x1?+w2?x2?+...+wd?xd?+b)
x ^ = ( x 1 , x 2 , . . . , x d , 1 ) \hat{x} = ({x_1},{x_2},...,{x_d},1) x^=(x1?,x2?,...,xd?,1)
1) w ^ \hat{w} w^ : 方程系數所組成的向量, 并且我們將自變數系數和截距放到了一個向量中, 此處\hat{w}就相當于前例中的a, b組成的向量(a,b)
2) x ^ \hat{x} x^ : 方程自變數和1共同組成的向量
因此, 方程可表示為
f ( x ) = w ^ ? x ^ T f(x) = \hat{w}* \hat{x} ^T f(x)=w^?x^T
我們將所有自變數的值放在一個矩陣中, 并且和此前A矩陣類似, 為了捕捉截距, 添加一列全為1 的列在矩陣的末尾, 設總共有m組取值, 則

對應到前例中的A矩陣, A矩陣就是擁有一個自變數, 兩個取值的x矩陣. 令 y y y為自變數的取值, 則有
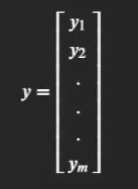
此時, SSE可表示為:
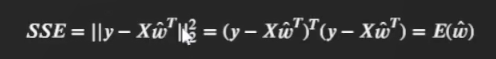
根據最小二乘法的求解程序, 令
E
(
w
^
)
E(\hat w)
E(w^) 對
w
^
\hat w
w^ 求導方程取值為0, 有

進一步可得
X
T
X
w
^
T
=
X
T
y
X^T X {\hat w}^T = X^T y
XTXw^T=XTy
要使得此式有解, 等價于
X
T
X
X^T X
XTX (也被稱為矩陣的交叉乘積crossprod)存在逆矩陣, 若存在,則可以解出
w
^
T
=
(
X
T
X
)
?
1
X
T
y
{\hat w}^T = (X^T X)^{-1} X^T y
w^T=(XTX)?1XTy
最小二乘法的簡單實作
回到最初的例子,有如下關系:
X X X = A A A = [ 1 2 3 1 ] \begin{bmatrix} {1}&{2}\\ {3}&{1}\\ \end{bmatrix} [13?21?]
y y y = B B B = [ 2 4 ] \begin{bmatrix} {2}\\ {4} \end{bmatrix} [24?]
w ^ T \hat w^T w^T = X T X^T XT = [ a b ] \begin{bmatrix} {a}\\ {b} \end{bmatrix} [ab?]
代碼實作最小二乘法:
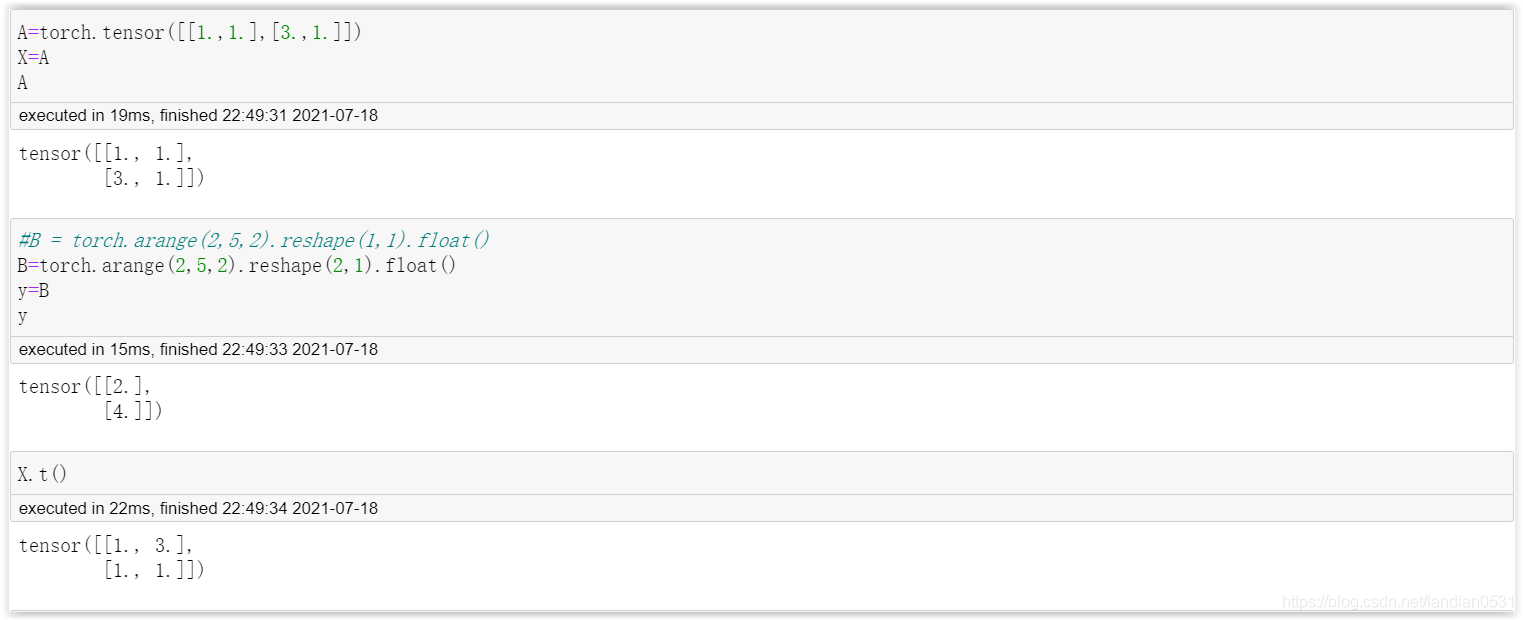

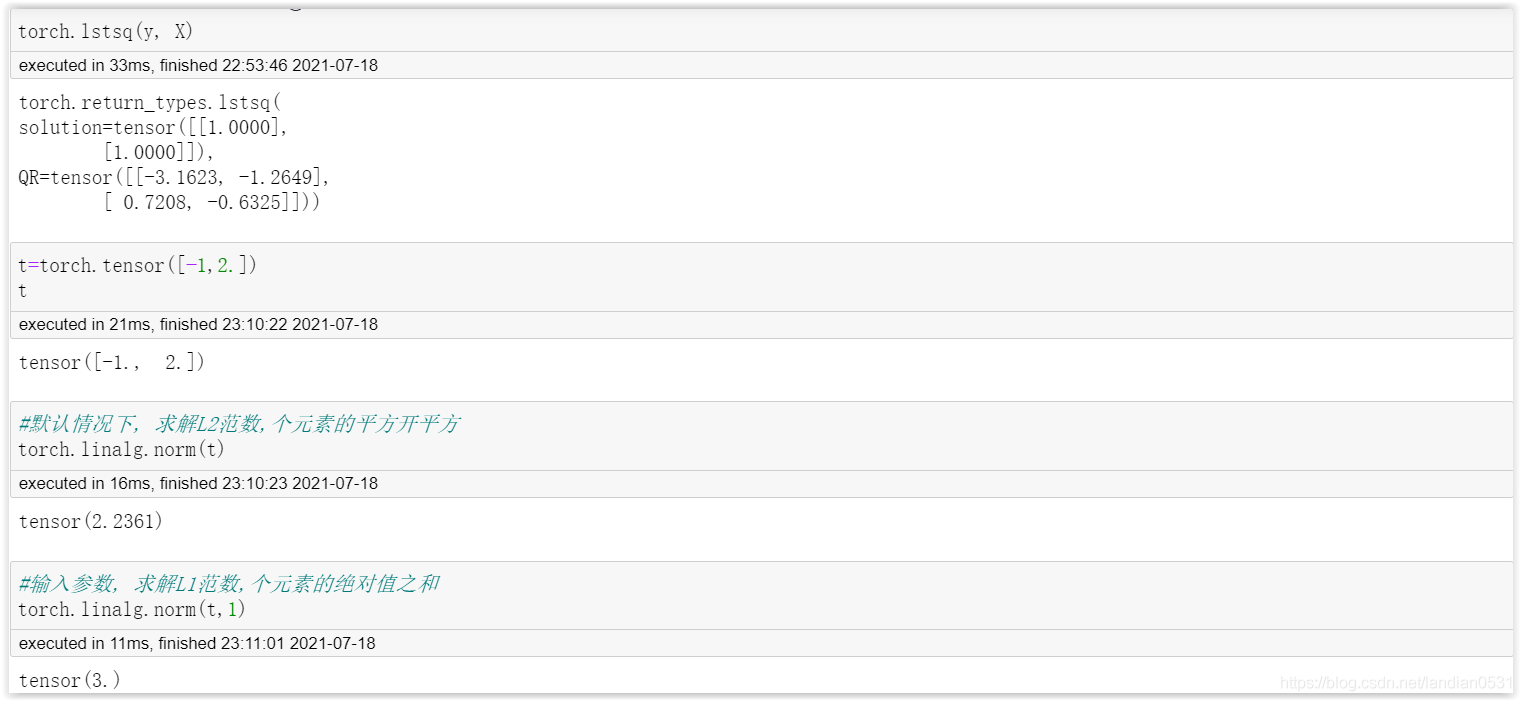
我們也可以直接呼叫最小二乘函式 torch.lstsq(B, A)進行求解.

對于lstsq函式來說, 第一個引數是因變數張量, 第二個引數是自變數張量, 并且同時回傳結果還包括QR矩陣分解的結果. QR分解也是矩陣分解的一種方法.
另外, 在最小二乘法數學推導程序中, 涉及到矩陣范數的運算, 在Pytorch中, 我們利用linalg.nom函式求向量或者矩陣的范數.
4. 反向驗證導數為0
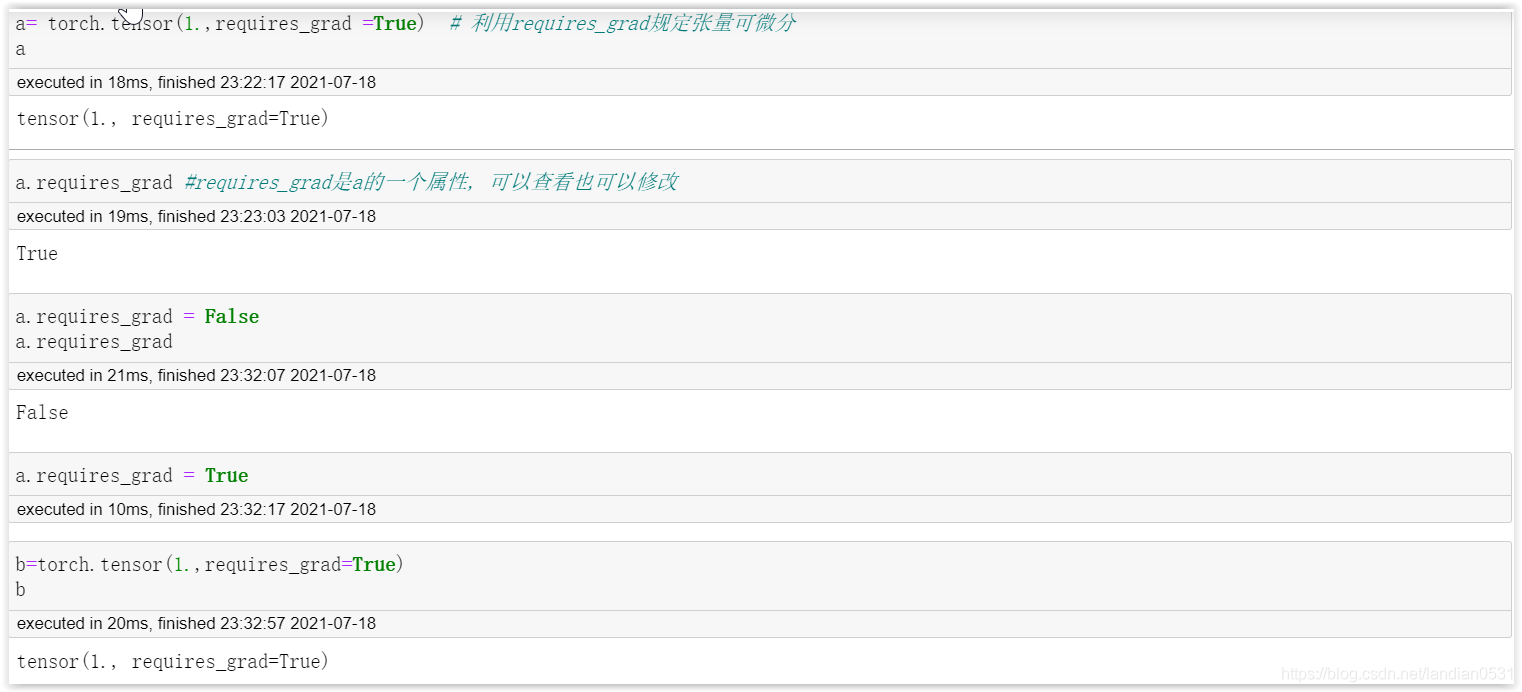
借助Pytorch中的autograd模塊來進行反向驗證, 看下損失函式SSE在a=1, b=1時偏導數是否都為0.
嚴格意義上, autograd模塊是Pytorch中的自動微分模塊, 我們可以通過autograd模塊中的函式進行微分運算,在神經網路模型中, 通過自動微分運算求解梯度是模型優化的核心.
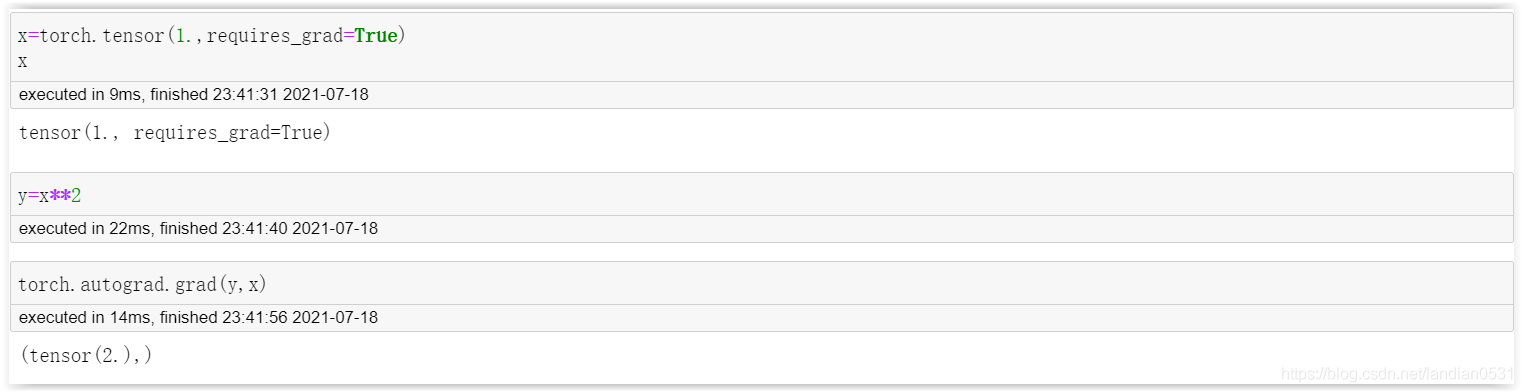
torch.autograd.grad 函式
是通用微分函式, 當只輸入一個自變數是計算結果為導數, 輸入多個自變數時則會計算偏導數.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289432.html
標籤:AI
上一篇:PTA團體程式設計天梯賽—練習集—L1-003 個位數統計【C++和python實作】
下一篇:機器學習之Knn演算法