機器學習
交通工具(無人機,自動駕駛)
VR(虛擬現實)
位元幣,區塊鏈
定義:人工智能是研究開發用于模擬,延伸和擴展人的只能的理論、延伸和擴展人的智能的理論、方法、技術及應用系統的一門綜合性交叉學科,
- 弱人工智能:包含基礎的,特定場景下角色型的任務,如Siri和AlphaGo機器人
- 通用人工智能:包含人類水平的任務,涉及機器的持續學習,
- 強人工智能:比人類更聰明的機器,
機器學習是人工智能的一個領域
深度學習又是機器學習的一個分支
人工智能包括:
- 思考方面:機器學習,自動推理,人工意識,知識表示
- 聽覺方面:語音識別
- 視覺方面:視覺識別
- 運動方面:動作執行
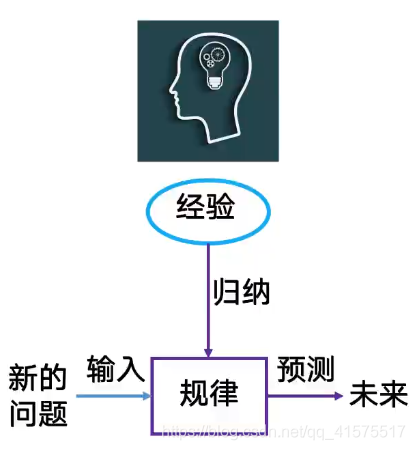
人類學習方式:
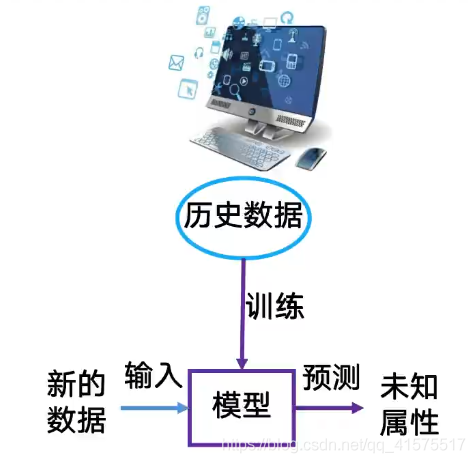
機器學習方式:
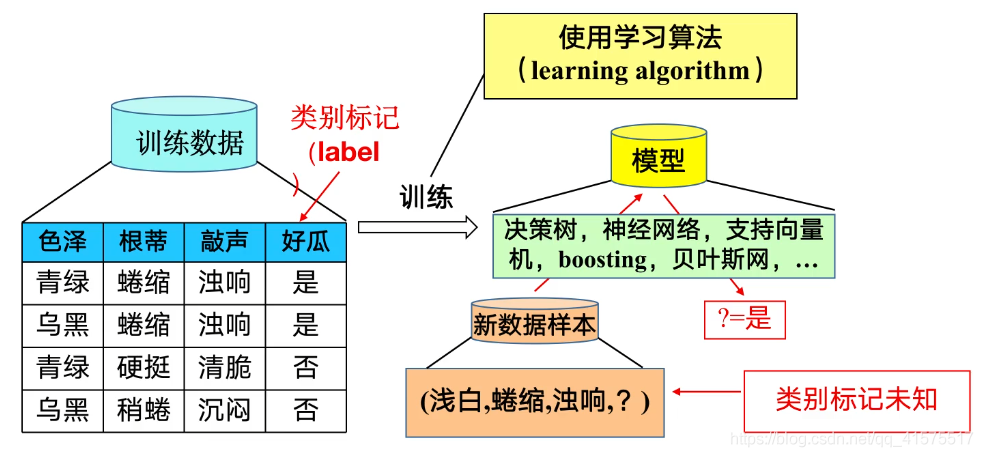
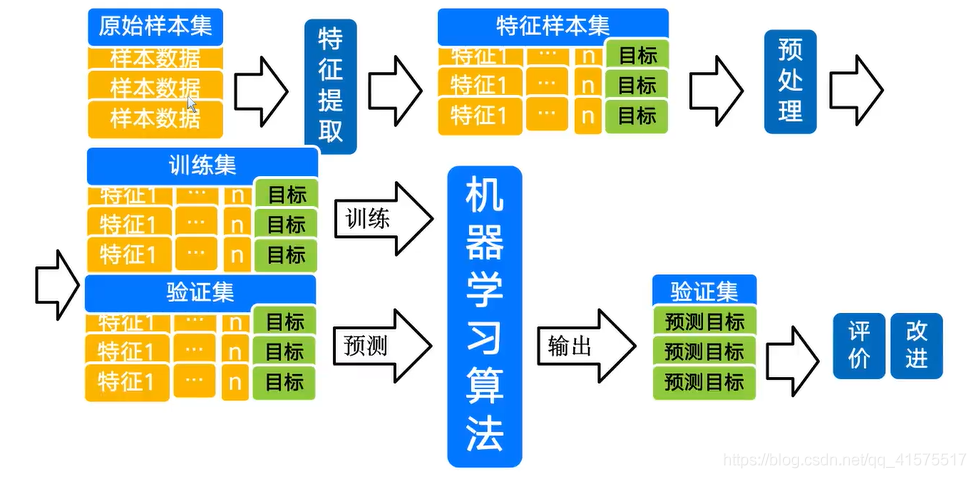
機器學習:
機器學習本質上就是用大量的輸入和輸出來訓練出一個模型,用這個模型輸入的資料所得出的輸出要盡可能貼合所解決的問題的解,模型其實就是一個函式,訓練模型實質上就是用大量的資料求出最合適的引數,
基本術語:
資料集,訓練,測驗,樣本(sample),屬性(attribute),特征(feature),屬性值,屬性空間,樣本空間,輸入空間,特征向量
機器學習的任務:
-
令W是這個給定世界的有限或無限所有物件的集合,由于觀察能力的限制,我們只能獲得這個世界的一個有限子集Q屬于W,稱為樣本集,
-
機器學習就是根據這個有限樣本集Q,推算這個世界的模型,使得其對這個世界的認知為真,
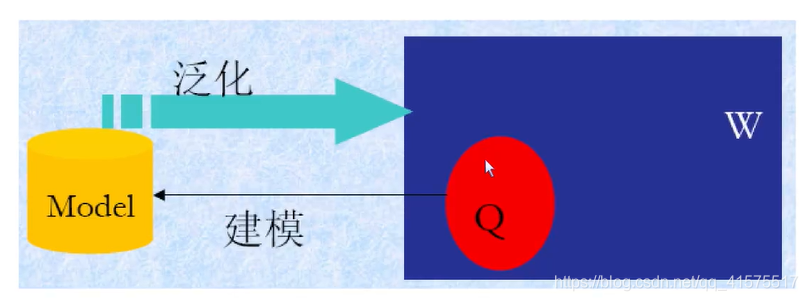
機器學習演算法:
- 監督學習:統計分類,回歸分析
- 無監督學習:聚類,關聯規則
KNN演算法:
分類的概念:把每個資料點分配到合適的類別中,即所謂的分類,其解決的問題就是如何建立一個有效的分類演算法模型將待分類的樣本進行正確的劃分
分類的核心思想是 相似
而判別相似性的一個重要條件就是距離
import matplotlib.pyplot as plt
fight = (3, 2, 1, 101, 99, 98, 18)
kiss = (104, 100, 81, 10, 5, 2, 90)
# 1:Romance型別,2:Action型別,3:Unkown型別
filmType = (1, 1, 1, 2, 2, 2, 3)
# 畫散點圖
plt.scatter(fight, kiss, c=filmType)
# 顯示散點圖
plt.show()
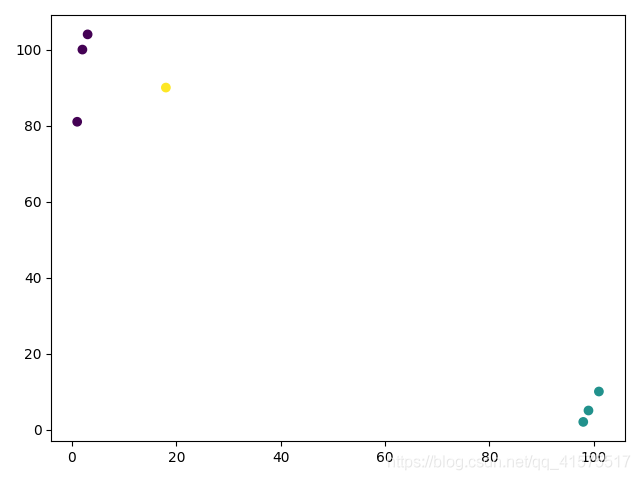 如果我們想要判斷黃球(unknown)是屬于兩者之間的哪一類,那么很顯然,由于黃球距離紫色球更近一點,所以,黃球有很大可能性是屬于紫色類,所以距離遠近可以作為分類的一個很好地切入點,
如果我們想要判斷黃球(unknown)是屬于兩者之間的哪一類,那么很顯然,由于黃球距離紫色球更近一點,所以,黃球有很大可能性是屬于紫色類,所以距離遠近可以作為分類的一個很好地切入點,
-
最近鄰演算法(NN):為判定未知樣本的類別,以全部訓練樣本作為代表點,計算未知樣本與所有訓練樣本的距離,并以最鄰近者的類別作為決策未知樣本的唯一依據,
但是,最近鄰演算法存在明顯缺陷
- 當周邊只有一個最近點但是存在多個其他樣本點時,所判定分類不太合理,所以最近鄰演算法對噪聲過于敏感
- 為了解決這個問題,我們可以把未知樣本周邊的多個最近樣本計算在內,擴大參與決策的樣本量,以避免個別資料直接決定決策結果,由此衍生出 K-近鄰演算法
-
K-近鄰演算法:KNN演算法的原理就是當預測一個新的值x的時候,根據它距離最近的K個點是什么類別來判斷x屬于哪個類別,其步驟為:
-
計算測驗物件與訓練集中的每個物件的距離,計算距離主要用到歐幾里得距離和曼哈頓距離
-
歐式距離公式為:
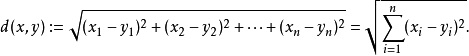
-
曼哈頓距離公式為:
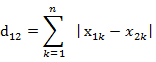
-
-
選取近鄰:將距離升序排序,選擇距離最近的K個樣本點
-
分類決策:根據這K個近鄰歸屬的類別,采用多數表決的方法,由這K個點來投票決定測驗物件歸為哪一類
- 準備資料,分析資料,對資料進行預處理,歸一化處理
- 劃分訓練集和測驗集
- 計算未知樣本和每個訓練集樣本的距離
- 設定引數,K值
- 將距離升序排序
- 選取距離最小的K個點
- 統計前K個最近鄰樣本點所在類別出現的次數
- 多數表決,選擇出現頻率最大的類別作為未知樣本的類別
- kNN演算法沒有進行資料的訓練,直接使用未知資料與已知資料進行比較,得到結果,因此,KNN演算法不具有顯式的學習程序
思考:如果采用多數表決的話,到最后那決定權似乎只是K樣本點中各個類別樣本點距離未知點的的個數了,而距離似乎只是用來判斷某一個點是不是樣本點,這樣分出來的類別似乎不太嚴謹,所以,能不能把樣本點個數作為一個比重或者是可調控引數,K樣本點距未知點的距離占剩下的比重,兩者以某一個模型來共同決定未知點的分類
import matplotlib.pyplot as plt import numpy as np fight = (3, 2, 1, 101, 99, 98) kiss = (104, 100, 81, 10, 5, 2) # 1:Romance型別,2:Action型別,3:Unkown型別 filmType = (1, 1, 1, 2, 2, 2) # 畫散點圖 plt.scatter(fight, kiss, c=filmType) # 顯示散點圖 plt.show() x = np.array([fight, kiss]) y = np.array(filmType) x = x.T print(x) print(y) xx = np.array([18, 90]) # 此處sum()中的引數可以為0或者是1,若為0,則按列求和,若為1,則按行求和 dist = (((x-xx)**2).sum(1))**0.5 print(dist) sortedDist = dist.argsort() print(sortedDist) # 在k=4的范圍內尋找哪一類樣本點距離未知型別點最多 k = 4 # 定義一個字典,其作用是為了判斷前k-1個樣本中每個種類出現了幾次 classCount = {} for i in range(k): voteLable = y[sortedDist[i]] # get()方法中第二個屬性的意思是若關鍵字不存在于字典中,則回傳0 classCount[voteLable] = classCount.get(voteLable, 0) + 1 print("key:value", classCount) # 在字典中尋找哪一類出現的次數最多 maxType = 0 maxCount = -1 # 這種遍歷方式是在字典中遍歷的方式,直接用key和value取字典中的鍵值對即可 for key, value in classCount.items(): if value> maxCount: maxType = key maxCount = value print('outPut:', maxType) 輸出: [[ 3 104] [ 2 100] [ 1 81] [101 10] [ 99 5] [ 98 2]] [1 1 1 2 2 2] [ 20.51828453 18.86796226 19.23538406 115.27792503 117.41379817 118.92854998] [1 2 0 3 4 5] key:value {1: 3, 2: 1} outPut: 1加一個知識點,函式的呼叫方式:
-
直接在本模塊中呼叫
import matplotlib.pyplot as plt import numpy as np # 個模塊是從Classify.py中抽離然后封裝來的 class KnnSort: def __init__(self, inX, dataSet, labels, k): self.inX = inX self.dataSet = dataSet self.labels = labels self.k = k # inX:未知型別資料; dataSet:訓練集;labels:訓練集標簽項(每個資料所屬型別); k:樣本所屬范圍 def knn(self): # 此處sum()中的引數可以為0或者是1,若為0,則按列求和,若為1,則按行求和 dist = (((self.inX - self.dataSet) ** 2).sum(1)) ** 0.5 sortedDist = dist.argsort() # 定義一個字典,其作用是為了判斷前k-1個樣本中每個種類出現了幾次 classCount = {} for i in range(self.k): voteLable = self.labels[sortedDist[i]] # get()方法中第二個屬性的意思是若關鍵字不存在于字典中,則回傳0 classCount[voteLable] = classCount.get(voteLable, 0) + 1 # 在字典中尋找哪一類出現的次數最多 maxType = 0 maxCount = -1 # 這種遍歷方式是在字典中遍歷的方式,直接用key和value取字典中的鍵值對即可 for key, value in classCount.items(): if value > maxCount: maxType = key maxCount = value return maxType if __name__ == '__main__': fight = (3, 2, 1, 101, 99, 98) kiss = (104, 100, 81, 10, 5, 2) # 1:Romance型別,2:Action型別,3:Unkown型別 filmType = (1, 1, 1, 2, 2, 2) x = np.array([fight, kiss]) y = np.array(filmType) x = x.T xx = np.array([18, 90]) # 直接呼叫類即可,在呼叫類的時候傳入引數,然后直接呼叫函式即可 result = KnnSort(xx, x, y, 4).knn() print(result) -
在其他檔案中呼叫
import Knn as k import matplotlib.pyplot as plt import numpy as np fight = (3, 2, 1, 101, 99, 98) kiss = (104, 100, 81, 10, 5, 2) # 1:Romance型別,2:Action型別,3:Unkown型別 filmType = (1, 1, 1, 2, 2, 2) x = np.array([fight, kiss]) y = np.array(filmType) x = x.T xx = np.array([18, 90]) # 上面 import Knn as k 中引入的k是Knn檔案名稱,KnnSort是類名 result = k.KnnSort(xx, x, y, 4).knn() print(result) -
大量存在于檔案中的資料進行資料集的構建
# -*- coding: utf-8 -*- # @Time : 2021/7/15 10:43 # @Author : wcc # @FileName: KnnLargeData.py # @Software: PyCharm # @Blog :https://blog.csdn.net/qq_41575517?spm=1000.2115.3001.5343 import numpy as np import matplotlib.pyplot as plt import pandas as pd class ProcessData: def __init__(self, file_name): self.filename = file_name # 構建訓練集 def file2matrix(self): # 打開檔案 fr = open(self.filename) # 計算檔案行數,readlines() 方法用于讀取所有行(直到結束符 EOF)并回傳串列,該串列可以由 Python 的 # for... in ... 結構進行處理,如果碰到結束符 EOF 則回傳空字串, numberOfLines = len(fr.readlines()) # 生成一個三列的全0矩陣 returnMat = np.zeros((numberOfLines, 3)) classLabelVector = [] # 此處再寫一次 fr = open(self.filename) 陳述句的原因是當使用 fr.readlines() 遍歷過一次之后其游標 # 移動到了最后,若再需要從頭遍歷資料,則此處需要重新設定游標位置,需要將其設定為(0,0),所以此處用 # seek()方法重新設定游標位置亦可 # fr = open(self.filename) fr.seek(0, 0) index = 0 for line in fr.readlines(): # str.strip()就是把字串(str)的頭和尾的空格,以及位于頭尾的\n \t之類給刪掉 line = line.strip() # 由于文本資料是以一個制表位來區分的,所以將遍歷到的文本的一行按制表位分割成一個1*3的矩陣 listFormLine = line.split('\t') # 將遍歷到的一行資料賦給returnMat的第index行的所有列位(因為上面定義的returnMat也只有3列,所以等號前面的列的范圍直接可以省略) returnMat[index, :] = listFormLine[0:3] # 這以上做的所有作業全是為了得到一個1000*3的矩陣 # 1:代表不喜歡;2:代表一點喜歡;3:代表非常喜歡 if listFormLine[-1] == 'didntLike': # 用append()方法可以得到一個list,而不是一個array classLabelVector.append(1) if listFormLine[-1] == 'smallDoses': classLabelVector.append(2) if listFormLine[-1] == 'largeDoses': classLabelVector.append(3) index += 1 x = returnMat[:, 0] y = returnMat[:, 1] z = returnMat[:, 2] classify = classLabelVector # 本例需要將三個變數兩兩進行比較 # plt.scatter(x, y, c=classify) plt.scatter(x, z, c=classify) # plt.scatter(y, z, c=classify) # # 顯示散點圖 plt.show() fr.close() return returnMat, classLabelVector if __name__ == '__main__': datingDataMat, datingLables = ProcessData('datingTestSet.txt').file2matrix() print(datingDataMat) print(datingLables)
-
-
資料歸一化:
當有多個屬性共同作用于結果且某一個屬性的數值遠大于其他屬性時,經計算所取得的結果必定是不精確的,所以就需要削弱這個屬性對結果所產生的影響,所以需要進行資料的歸一化
-
0—1標準化:將當前值映射到0—1區間之間
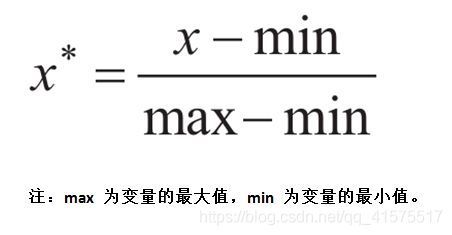
上式的意思是:(當前值 — 整個序列中的最小值) / (整個序列的最大值 — 整個序列的最小值)
-
Z—score標準化
-
sigmoid壓縮法
-
-
鳶尾花資料使用knn演算法分類
# -*- coding: utf-8 -*- # @Time : 2021/7/16 21:45 # @Author : wcc # @FileName: KnnIris.py # @Software: PyCharm # @Blog :https://blog.csdn.net/qq_41575517?spm=1000.2115.3001.5343 import numpy as np import matplotlib.pyplot as plt import pandas as pd class Iris: def __init__(self, file_name, data_set, labels_set, normal_data_set, sample_range, data_division): self.fileName = file_name self.dataMat = data_set self.labelsMat = labels_set self.normalDataSet = normal_data_set self.k = sample_range self.dataDivision = data_division # 資料預處理 def iris_processData(self): fr = open(self.fileName) numOfLines = len(fr.readlines()) # 此處一定是除標簽列以外的資料列數 dataMat = np.zeros((numOfLines, 4)) # 標簽單獨成一列 labelsMat = [] fr.seek(0, 0) index = 0 for line in fr.readlines(): line = line.strip() listLine = line.split(',') dataMat[index, :] = listLine[0:4] if listLine[-1] == 'Iris-setosa': labelsMat.append(1) if listLine[-1] == 'Iris-versicolor': labelsMat.append(2) if listLine[-1] == 'Iris-virginica': labelsMat.append(3) index += 1 labelsMat = np.array(labelsMat) self.dataMat = dataMat self.labelsMat = labelsMat # 資料歸一化(0-1歸一化) def iris_normal(self): colDataMax = self.dataMat.max(0) colDatamin = self.dataMat.min(0) normalDataSet = np.zeros(self.dataMat.shape) normalDataSet = (self.dataMat - colDatamin)/(colDataMax - colDatamin) self.normalDataSet = normalDataSet # knn演算法對測驗集進行測驗 def iris_knn(self): trainSize = int(self.normalDataSet.shape[0]*self.dataDivision) testSize = int(self.normalDataSet.shape[0]*(1-self.dataDivision)) result = [] errorCount = 0 errorRecords = {} correctRecords = {} index = 0 for i in range(testSize): count = {} dist = (((self.normalDataSet[trainSize+i, :]-self.normalDataSet[0:trainSize, :])**2).sum(1))**0.5 sortDisk = dist.argsort() for j in range(self.k): voteLable = self.labelsMat[sortDisk[j]] count[voteLable] = count.get(voteLable, 0) + 1 maxType = 0 maxCount = -1 for key, value in count.items(): if value>maxCount: maxType = key maxCount = value if self.labelsMat[trainSize+i] != maxType: errorRecords[trainSize+i] = maxType correctRecords[trainSize+i] = self.labelsMat[trainSize+i] errorCount +=1 print('錯誤個數:') print(errorCount) print('錯誤位置及錯誤值:') print(errorRecords) print('相應位置的正確值:') print(correctRecords) print('wrong proportion:', errorCount / testSize) if __name__ == '__main__': fileName = 'iris.txt' # 'datingTestSet.txt'# 檔案路徑 dataMat = [] # 資料集(自己讀取) labelsMat = [] # 標簽集(自己讀取) normalDataSet = [] #歸一化后的資料集 sampleRange = 5 # 范圍取值 dataDivision = 0.8 # 資料集中訓練集和測驗集的劃分比例 iris = Iris(file_name=fileName, data_set=dataMat, labels_set=labelsMat, normal_data_set=normalDataSet, sample_range=sampleRange, data_division=dataDivision) iris.iris_processData() iris.iris_normal() iris.iris_knn()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289433.html
標籤:AI
上一篇:Pytorch入門 - Day5