文章目錄
- 1 序列到序列的模型
- 2 Seq2seq model 常見的應用場景
- 2.1 聊天機器人
- 2.2 問題回答 (QA)
- 2.3 文法剖析
- 2.4 多標簽分類
- 2.5 物件檢測
- 3 Seq2seq model的整體架構
- 4 編碼器的具體架構
1 序列到序列的模型
Transformer本質上就是一個Sequence-to-sequence的model,我們經常縮寫為Seq2seq,所有我們就先來討論一下什么是Seq2seq的model,
上一節在講自注意力機制的時候就提到過,input是一個sequence時,output有三種可能:
-
每一個向量都有一個對應的Label,就比如詞性標注的問題,
-
輸入多個向量,只需要輸出一個Label,就比如Sentiment Analysis的問題,分析一句話的情感是正面還是負面,
-
機器要自己決定應該輸出多少個Label,這就是Seq2seq的模型要處理的問題,
舉例來說,Seq2seq一個很好的應用就是語音辨識:
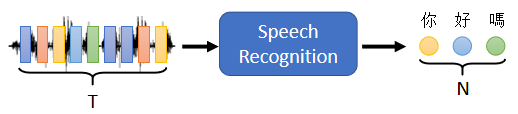
在做語音辨識的時候,輸入是聲音訊號,聲音訊號其實就是一串的vector,輸出是語音辨識的結果,也就是輸出的這段聲音訊號所對應的文字,輸出的長度由機器自己決定,由機器自己去聽這段聲音訊號的內容,并決定應該要輸出幾個文字,
還有很多其他的例子,比如說機器翻譯:

甚至可以做更復雜的問題,比如說做語音翻譯:

接下來就要介紹一下Seq2seq模型常見的一些應用,你可以發現這個模型的應用范圍是非常廣泛的,
2 Seq2seq model 常見的應用場景
2.1 聊天機器人
可以用Seq2seq model來訓練一個聊天機器人,聊天機器人就是你對它說一句話,它要給你一個回應,輸入輸出都是文字,而文字又可以看成是 vector sequence,因此可以考慮用 Seq2seq model 來處理,

為了訓練我們的模型,需要收集大量人的對話,像電視劇、電影的臺詞等等,可以很容易收集到很多人跟人之間的對話,假設在對話里面某一個人說“Hi”,另外一個人回答說“Hello, How are you today”,那我們就可以教機器看到輸入是Hi,那你的輸出就要跟“Hello, How are you today”越接近越好,這是一個基本的訓練思路,
2.2 問題回答 (QA)
事實上Seq2Seq model 在自然語言處理(NLP)的領域應用的也非常廣泛,特別是question answering任務上的應用,而其實很多自然語言處理的任務,都可以看成是question answering,QA的任務,
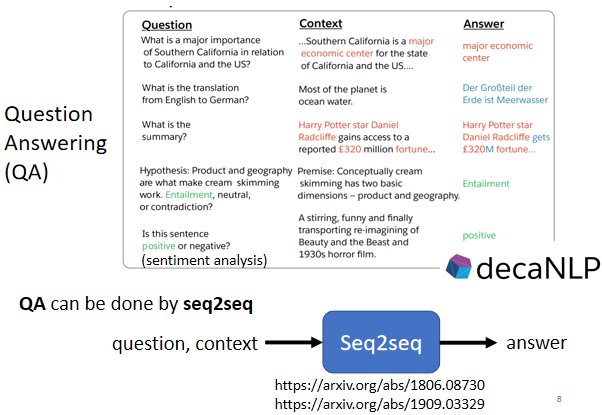
Question Answering 就是給機器讀一段文字,然后你問機器一個問題,希望他可以給你一個正確的答案,
-
假設你今天想做的是機器翻譯的任務,那機器讀的文章就是一個英文句子,問題就是這個句子的中文翻譯是什么,然后輸出的答案就是對應的中文,
-
或者你想要讓機器自動作自動摘要的任務,就是給機器讀一篇長的文章,讓機器把長文章中的重點摘錄出來,那你就是給機器一段文字,問題是這段文字的摘要是什么,然后輸出的答案就是這篇文章的摘要,
-
又或者是你想要讓機器做 Sentiment analysis的任務,就是機器要自動判斷一個句子是正面還是負面的,你就給機器要判斷正面還是負面的文章,問題就是這個句子是正面還是負面的,然后輸出的答案就是這個句子對應的情感,
所以各式各樣的NLP的問題,往往都可以看作是QA的問題,而QA的問題,就可以用Seq2Seq model來解,
2.3 文法剖析
還有一些你不覺得它是一個Seq2Seq model 的問題,但你仍然可以用 Seq2Seq model 硬解這個問題,就比如說文法剖析的問題:給機器一段文字,機器要做的事情是產生一個文法的剖析樹,告訴我們deep加learning合起來是一個名詞片語,very加powerful合起來是一個形容詞片語,形容詞片語加is以后會變成一個動詞片語,動詞片語加名詞片語合起來,是一個句子,
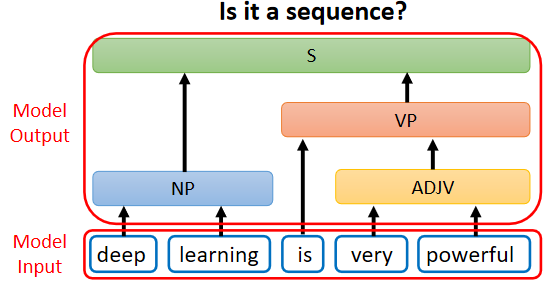
這個輸出看起來不像是一個 Sequence,輸出是一個樹狀的結構,但事實上一個樹狀的結構,也可以硬是把他看作是一個 Sequence:
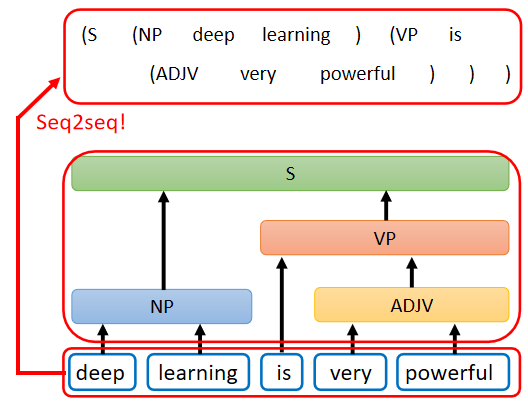
這一個 Sequence就代表了這一個 tree 的 structure,你先把 tree 的 structure 轉換成一個 Sequence 以后,你就可以用 Seq2Seq model 硬解這個問題,看起來挺離譜的哈?我反正覺得挺離譜的,但是實際上是真的可以做到的,就比如這篇paper Grammar as a Foreign Language (arxiv.org) 就是這樣做的,
2.4 多標簽分類
Seq2Seq model 也可以應用在多標簽分類的問題上,所謂的 multi-label classification ,意思是說同一個東西,它可以屬于多個class,舉例來說,你在做文章分類的時候,一篇文章可能既屬于類別1,又屬于類別2,
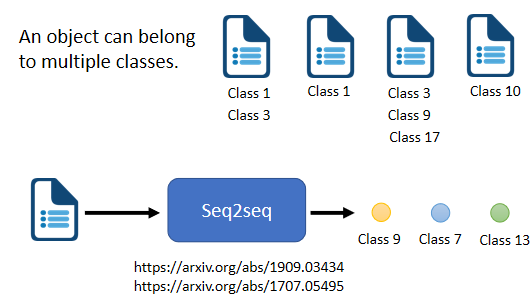
由于一篇文章屬于多少個類別是不確定的,所有我們用 Seq2Seq model 來解決這個問題,讓機器自己決定輸出幾個類別,
2.5 物件檢測
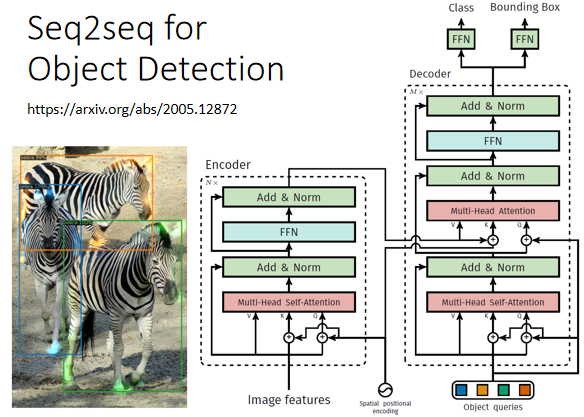
object detection,這個看起來跟 Seq2Seq model 八竿子打不著的問題,也可以用 Seq2Seq model 硬解,這里就放一下論文的鏈接: End-to-End Object Detection with Transformers (arxiv.org)
3 Seq2seq model的整體架構
現在我們要來看看這個似乎啥都能做的 seq2seq model 究竟是怎么實作的,一般的 seq2seq model 會分成兩個部分,一個部分是Encoder,另一個部分是Decoder:
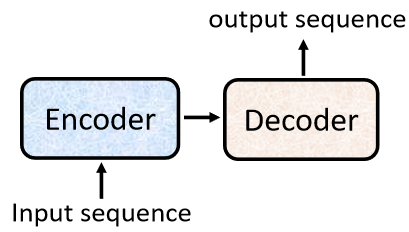
我們輸入一個sequence到Encoder,Encoder負責處理這個sequence,再把處理好的結果丟給Decoder,由Decoder決定要輸出什么樣的sequence,等一下還會具體介紹Encoder和Decoder內部的架構,
seq2seq model 的起源其實非常早,在2014年的9月,就有一篇把 seq2seq model用在翻譯上的論文: Sequence to Sequence Learning with Neural Networks (arxiv.org)

而在今天講到 seq2seq model 的時候,大家更多指的是我們今天的主角,也就是transformer,它有一個Encoder架構,有一個Decoder架構,還有很多花花綠綠的block,接下來就是要詳細介紹一下每一個花花綠綠的block分別在做的事情是什么,
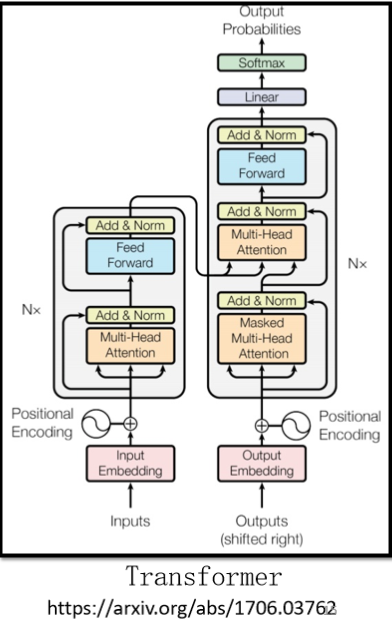
它有一個Encoder架構,有一個Decoder架構,它裡面有很多花花綠綠的block,等一下就會講一下,這裡面每一個花花綠綠的block,分別在做的事情是什麼
4 編碼器的具體架構
seq2seq model Encoder 要做的事情就是給一排向量,輸出另外一排向量,
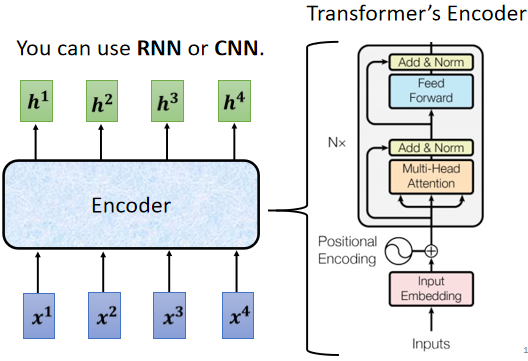
這件事情聽起來很簡單,很多模型都可以做到,可能第一個想到的就是上一節剛剛講完的 self-attention ,而事實上在transformer里面,它的Encoder用的就是self-attention,上面的這張圖來自于原始論文,看起來有點復雜,我們用下面這張簡化后的圖,來仔細地解釋一下Encoder的架構,
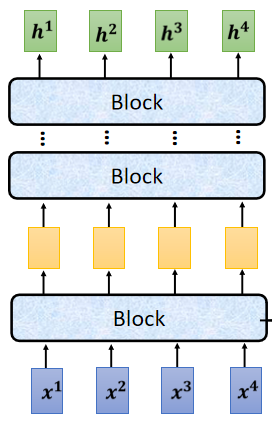
現在的Encoder里面,會分成很多的block,每一個block都是輸入一排向量,輸出一排向量,最后一個block會輸出最終的vector sequence,每一個block也并不是neural network的一層,而是做了好幾個layer在做的事情,在transformer的Encoder里面,每一個block做的事情大概是這樣的:
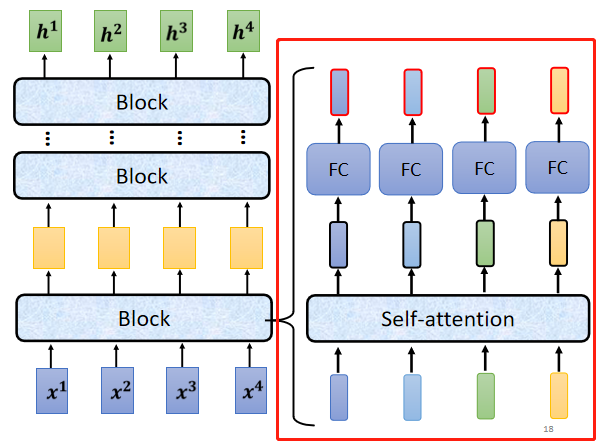
-
首先input一排vector以后,對它們做self-attention,考慮整個sequence的資訊,然后輸出另外一排vector,
-
接下來這一排vector,會分別丟到不同的fully connected network里面,再輸出另外一排vector,這一排vector就是這個block的輸出,
當然這是簡化版本的一個大致描述,事實上在原來的transformer里面做的事情要更復雜一些,
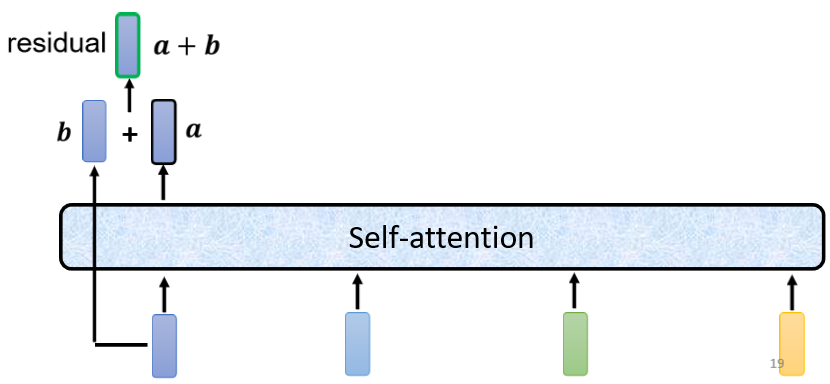
剛剛我們說self-attention層是輸入一排vector,考慮整個sequence的資訊,然后輸出另外一排vector,事實上在transformer里面,我們不只是輸出這個vector,我們還要把這個vector加上它的input,再得到新的output ,這個做法就叫做residual connection,主要是為了解決網路退化和梯度破碎問題,具體解釋可以參考這篇文章殘差網路解決了什么,為什么有效? - 知乎 (zhihu.com),這里就不再進一步說明,
得到residual的結果以后,還需要再做一件事情叫做normalization,這里使用的不是batch normalization,而是layer normalization,
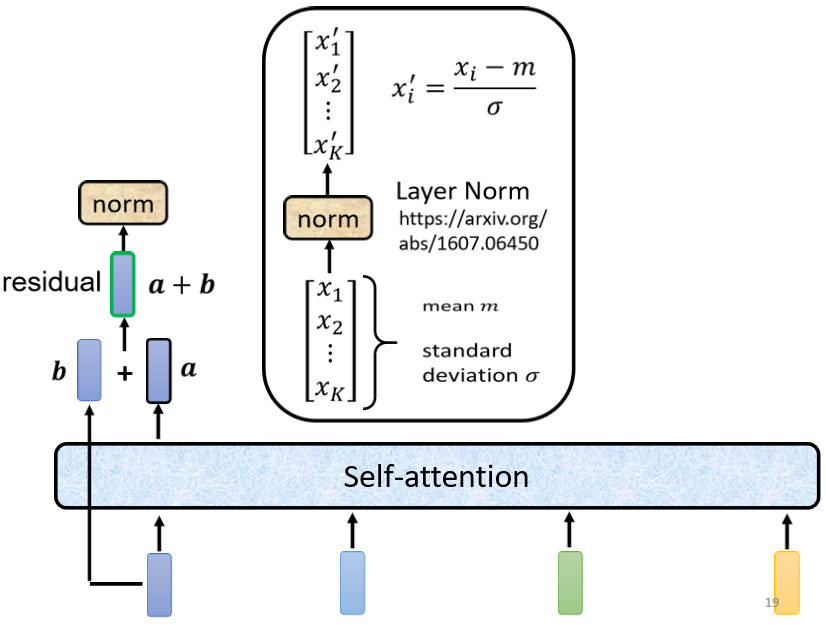
layer normalization做的事情比batch normalization更簡單一點,要注意的是,batch normalization是對不同example,不同feature的同一個dimension,去計算均值和標準差;而layer normalization是對同一個example,同一個feature里面不同的dimension,去計算均值和標準差,
計算出均值和標準差以后,就可以做一個normalize,把輸入vector里面的每一個dimension減掉均值
m
m
m,再除以s標準差
σ
\sigma
σ以后就得到layer normalization的輸出:
x
i
′
=
x
i
?
m
σ
x'_i=\frac{x_i-m}{\sigma}
xi′?=σxi??m?
這個輸出才是self-attention層真正的輸出,它會作為下一個全連接層的輸入,
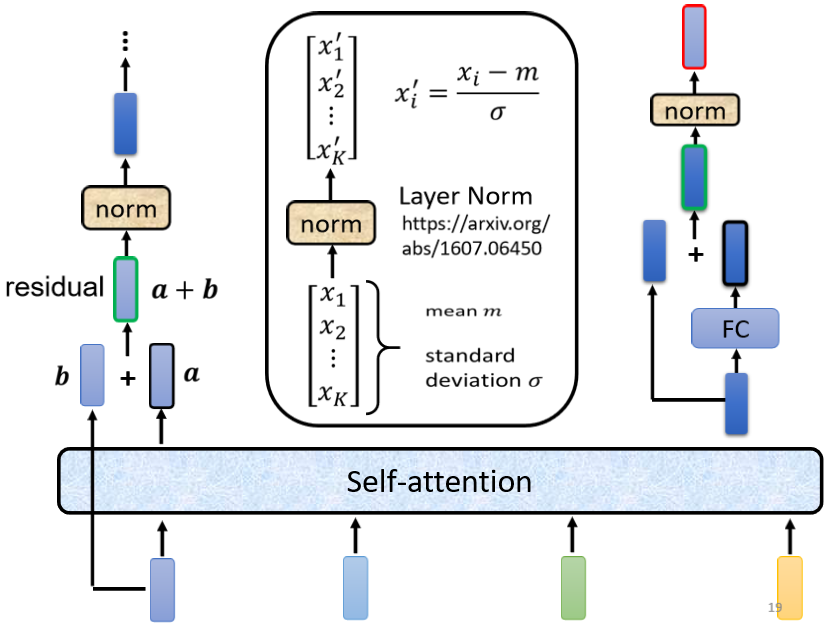
而fully connected network 這邊也設計了residual的架構,也就是說我們會把全連接層的input跟它的output加起來,才得到新的輸出,并且得到residual的結果以后,也需要再做一次layer normalization,才得到全連接層真正的輸出,
現在回到原論文里Encoder的圖片,其實就是我們剛剛講到的程序:
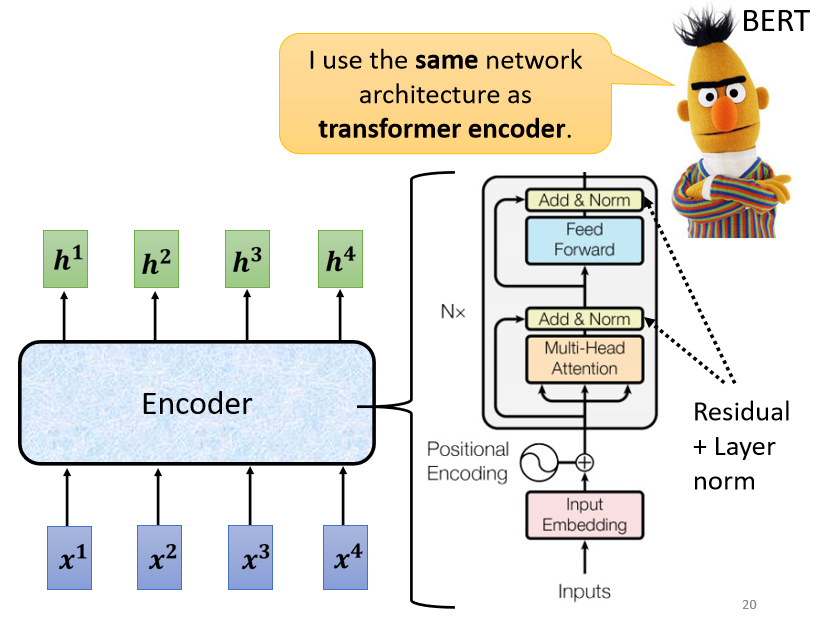
- 首先我們的輸入通過input embedding層得到嵌入表達,這里還需要加上positional encoding,來讓我們之后的self-attention能夠考慮到輸入位置的資訊,
- 接下來進入Multi-Head Attention層,這個就是self-attention的block,這邊特別強調了它是Multi-Head的self-attention
- Add&norm,就是residual加layer normalization,Multi-Head Attention層的輸出要做residual加layer normalization之后,才會輸入下一個模塊,也就是全連接層,
- 全連接的 feed forward network 的輸出也需要再做一次 Add&norm,才是整個block的輸出,
- 然后這個block會重復n次,這個復雜的block其實在之后會講到的一個非常重要的模型BERT里面會再用到, BERT其實就是transformer的encoder,
這就是transformer的Encoder的具體架構介紹啦,至于Decoder的架構又是怎樣的,且聽下回分解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289465.html
標籤:AI