計算機視覺PyTorch實作(一)
PyTorch基礎模塊
計算機視覺可以被廣泛應用于多個現實領域中,如做影像基本處理、影像識別、影像分割、目標跟蹤、影像分類、姿態估計等,在深度學習中人們開發了很多的學習框架,如Caffe、MXNet、Pytorch和TensorFlow等,這些框架可以極大簡化了構建深度學習神經網路的程序,
在計算機視覺應用中通過pytorch模塊構建不同的神經網路在不同網路層提取不同的型別特征,來實作不同的應用功能,
這里先對pytorch基礎的幾個模塊展開學習,
這里先匯入對應用到的基礎包
import torch.nn as nn
import torch
1.線性層
線性層也叫全連接層,該層一般出現在網路的最后一層中
定義代碼如下:
nn.Linear(in_features,out_features,bias=True)
- in_features:代表輸入的特征維度
- out_features:代表輸出的特征維度
- bias:是否引入偏置引數
這層實際上執行了一個最簡單的線性回歸模型,相當于做了一個矩陣乘法和矩陣加法 y=x*W+b
2.卷積層
在深度學習模型中,最核心的部分就是卷積層,對于影像來說,卷積運算是一種影像線性變換,在卷積操作的運算涉及兩個張量,第一個張量為輸入張量,第二個張量是線性變換的權重張量也稱為卷積核,
定義代碼如下:
class _ConvNd(in_channels,out_channels,kernel_size,stride,padding,dilation,transposed,output_padding,groups,bias,padding_mode)
- in_channels:輸入通道數,舉例:一張彩色的影像,就是由R、G、B三種通道構成,
- out_channels :輸出通道,及卷積核的通道數
- kernel_size:;這個值代表卷積核的維度大小,對于二維卷積來說,這個值可以是一個元組,舉例(3,4),意味著卷積核的大小是3x4,
- stride:在卷積核中卷積運算的步長
- padding:填充輸入的張量空間大小
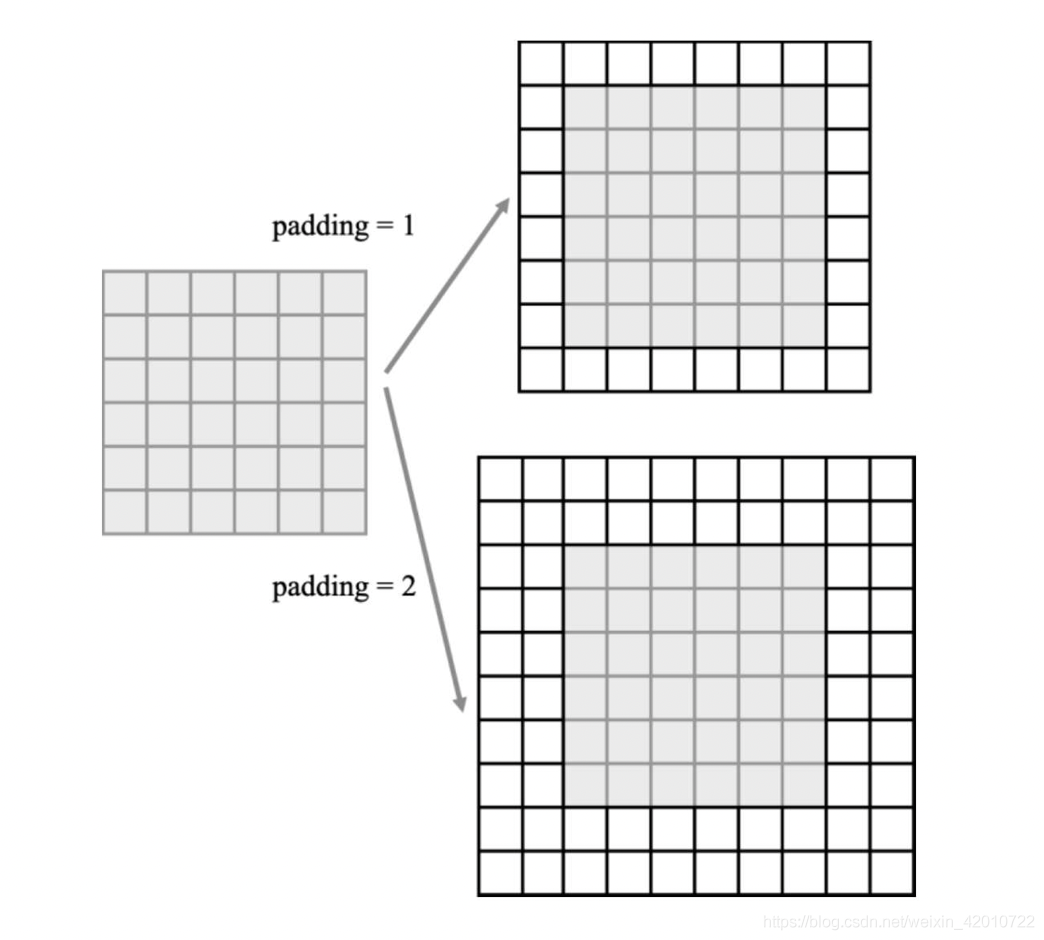
- dilation:另一種擴張卷積方法
- transposed:轉置卷積,如果為False進行普通卷積的計算,如果為True進行轉置卷積計算
3.歸一化層
歸一化層,有很多種,包括:
- 批次歸一化
nn.BatchNorm2d(num_features,eps=1e-05,momentum=0.1,affine=True,track_running_stats=True)
- 組歸一化
- 實體歸一化
- 層歸一化
- 區域回應歸一化
幾乎所有的歸一化都類似于如下表達方式,其中x是輸入的張量的值, γ \gamma γ 和 β \beta β是可以訓練的向量引數,其元素的數目和輸入張量的通道數目相等,它們區別在于歸一化的平均值 E ( x ) E(x) E(x)的計算方式和歸一化的方差 V a r ( x ) Var(x) Var(x)的計算方式不同,
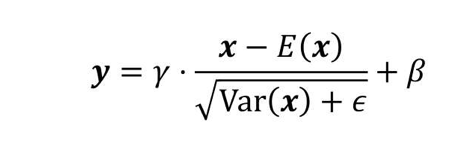
4.池化層
最大池化層:選定某一卷積核區域,取這個區域中輸入張量最大值,根據輸入張量形狀不同,最大池化層可以分為一維、二維和三維,
代碼如下:
nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1,return_indice=False,ceil_mode=False)
- kernel_siz:這里的卷積核不做計算處理,而是在輸入張量的卷積核內選擇最大的值,
- return_inices:決定是否回傳最大元素所在位置,
- ceil—mode:最大層池化層最后輸出是否向上取整,
5.dropout層
我們都知道,神經網路的復雜性和神經元的連接方式有關,神經元連接越多,模型越復雜,月容易發生過擬合,為了減少神經網路過擬合,通過減少神經元連接來進一步實作使模型泛化,
減少神經網路的連接實作相對比較復雜,一個等價最簡單的方式是把激活函式張量和權重張量的元素隨機置為零,
nn.Dropout2d(p=0.5,inplace=False)
6.模塊組合
下面通過使用nn.Sequential來構造順序模塊,
# 方法1.使用引數來構建順序模型
model=nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU())
# 方法2.使用順序字典來構建模型
model=nn.Sequential(OrdereDict([
('conv1',nn.Conv2d(1,20,5)),
('relu1',nn.ReLU()),
('conv2',nn.Conv2d(20,64,5)),
('relu2',nn.ReLU())]))
7.特征提取
在計算機視覺應用中,通過深度學習模型中間層計算產生一系列從簡單到復雜的特征,并最后提取得到復雜特征來進行預測的,也就是說深度學習神經網路模型分為二部分:第一部分,對原資料集進行特征提取,第二部分,對提取到的特征進行重新組合產生預測概率值,
在計算機視覺應用中,為了實作相應的應用,如影像分類,大佬們研究出許多的深度學習模型,即通過不同的卷積層,池化層等模塊組合,構造出不同的神經網路模型,如影像分類模型演算法,
這里通過構建一個AlexNet實體讓大家更快的了解pytorch構建神經網路模型的方法及其對應模版,
class AlexNet(nn.Module):
#定義分類種類 10
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
#特征提取
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
#特征組合分類
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289466.html
標籤:AI