
撰文 | 袁進輝
上周寫了一篇《淺談GPU虛擬化與分布式深度學習框架的異同》,想不到引起很多關注和討論,和朋友們討論之后,覺得這個話題值得再發散一下:
首先,文章只討論了GPU“一分多”這種“狹義”的虛擬化,還存在另外的虛擬化,“多虛一”也是存在的,在此,我想特別強調的是:上一篇文章后半部分對深度學習框架“多合一”的討論恰恰是想說明“多虛一”是不可能靠僅僅一層包打天下的API就能實作,反而要靠”去虛擬化“的思路,
其次,“去虛擬化”這種理念在追求性能極致的場景不是新鮮事,在這篇文章里再舉幾個相關的例子,
在這篇小品文里再討論一下:虛擬化的本質和局限性,為什么在追求性能極致的場景要“去虛擬化”,
1
“虛擬化”溯源
“虛擬化”可能是計算機科學歷史上最偉大的思想之一,對此,計算機先驅David Wheeler有一句名言:
All problems in computer science can be solved by another level of indirection, except for the problem of too many layers of indirection.
這句話被尊稱為“軟體工程的基本定理”,并被C++之父Bjarne Stroustrup在專著《The C++ Programming Language》的序言處參考,不過,大部分人記住了前半句,卻忽略了后半句,而后半句正是本文想展開討論的,
"another level of indirection"刻畫了“虛擬化”的精髓:通過引入一層新的抽象,把與上層應用無關的細節隱藏掉,有選擇的給上層用戶暴露一些功能供其使用,也稱底層細節對用戶透明,既不損害上層應用的功能,又能享受“關注點分離”(separation of concerns)的好處,增加易用性,
可以說:虛擬化的案例無處不在,無往而不利,
作業系統是對硬體資源的虛擬化:計算核心被虛擬化成行程;硬體記憶體變成虛擬記憶體;存盤介質被虛擬化成檔案系統;網路傳輸通過多層協議堆疊被虛擬化成檔案描述符,使得資料傳輸就像讀寫普通的檔案一樣,
分布式存盤把通過網路互聯多個單機檔案系統虛擬化成的一個網路檔案系統,使得用戶不用再關心網路資料傳輸的細節,可以像訪問本地檔案一樣訪問其它節點上的資料,
當然,虛擬化造就了今天偉大的云計算技術和市場,云原生如火如荼,開發者只需要基于云服務的API編程,而不需要關于API 之下的物理細節,成本低,可靠性又高,
虛擬化的成功不可否認,但是,成也蕭何,敗也蕭何,虛擬化也有其代價,
2
“虛擬化”和極致性能的矛盾
一層層的抽象層次,一步步降低編程的復雜度,每一層都向上隱藏了一些東西,上層就相應地丟失一些操控能力,每經過一層抽象,就引入一些對上層而言的“不確定性”,最終的結果是,性能的天花板一步一步下降,
以Hadoop的分布式存盤為例,虛擬化的結果是掩蓋了資料真實的存盤位置,不管在哪個節點上,訪問介面都是一樣的,不過,當向這個集群調度一些MapReduce的資料處理任務時,如果Task被調度到資料所在的節點上,那么就不需要網路傳輸,如果調度到另外的節點,就需要把資料讀到記憶體并通過網路發送到計算所在的節點,也就是,被隱藏掉的資料位置資訊有可能被調度器用來提升系統效率,
隨著摩爾定律放緩,不止在深度學習領域,在任何追求極致性能的場景就出現了一種擊穿、擊碎中間抽象層次,一竿子插到底進行協同優化的強烈需求,
讓我們看六個例子,
1、作業系統把CPU資源抽象成被作業系統調度和管理的內核執行緒,避免了用戶調度計算資源的麻煩,但是,在高并發場景,用戶級執行緒(如coroutine)越來越多,計算資源更多的在用戶態(user mode)來調度,而不是完全依靠內核的調度,
2、作業系統通過頁表機制實作虛擬記憶體,神不知鬼不覺實作資料的換入換出,但在高性能場景,用戶程式會通過編程介面禁止這一行為,譬如在RDMA和GPU異步資料傳輸都依賴于鎖頁記憶體,確保作業系統不會幫倒忙,
3、傳統的網路傳輸協議堆疊TCP/IP都在作業系統內核,為了避免內核態和用戶態的資料拷貝和背景關系切換,人們先是使用用戶態協議堆疊(如Intel dpdk),仍無法滿足需求的話,就使用支持內核旁路(bypass)的RDMA技術,完全跳過了作業系統這一層,
4、快取(Cache)技術也可以視為一種虛擬化,命中就直接使用,沒命中就花時間從更慢的存盤取過來,在區域性較好的負載下作業得很好,但在特定領域,譬如深度學習領域,作業負載有特別的規律,如果用軟體來控制快取資料的彈出以及讀取甚至可以做到100%的命中率,這種辦法被稱為Scratchpad,現在幾乎所有的AI芯片都沒有用Cache,而是使用Scratchpad技術,
5、作業系統的檔案系統或者網路檔案系統,把底層硬體的細節隱藏了,編程時不需要考慮資料在哪臺機器的哪塊磁盤上,編程更簡單了,但訪問近處的資料速度快,訪問遠處的資料速度慢,為了提高效率,有人就提出了locality aware(區域性感知)的調度,把計算任務盡可能調度到存盤資料的節點上去,
6、工業級的大型軟體系統里,通常不會使用庫函式,恨不得把底層代碼庫重新打造一遍,譬如Chromium, OceanBase等大型C++專案,我想,這也可以算作反虛擬化的例子,
3
“虛擬化”的舒適區
虛擬化試圖向上層提供一劑一勞永逸的靈丹妙藥,既解決易用性,又不損害上層應用對性能的需求,但是,“虛擬化”到底好不好應該具體問題具體分析,那該如何判斷虛擬化到底合不合適呢?
這里嘗試拋出一個用來判斷是否有必要引入一層抽象(虛擬化)的量化指標,供參考,每引入一層虛擬化,就向上層隱藏了一些東西,向上提供的服務的延遲就因此引入了不確定性(以分布式存盤為例,有的資料近,有的資料遠;以分布式GPU資源池為例,有的近,有的遠),服務的回應延遲有一個波動范圍,也就是[min, max],延遲越小越好,
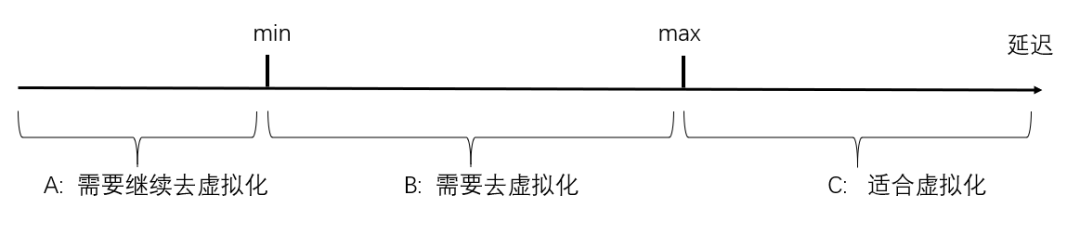
如果上層某一個應用需要保證的最低延遲仍大于max,那么這層虛擬化對這個應用就沒有損害,可以大膽的引入這個虛擬化技術(也就是上圖的C區域),
如果上層某一個應用需要保證的最低延遲介于min和max之間,那么引入這層虛擬化就對這個應用是有損害的,把這層虛擬化敲掉,就可以確保以min值滿足這個應用對延遲的需求(也就是上圖的B區域),
如果上層某一個應用需要保證的最低延遲小于min,那么即使敲掉當前層的虛擬化,仍不能滿足這個應用,就需要繼續向下敲,進行聯合優化,直到延遲得到滿足(也就是上圖的A區域),
4
魚與熊掌兼得?
如上所述,虛擬化的基本思路是通過“隱藏細節”給上層應用提供一種假象,降低上層應用使用底層資源的復雜度,不過,有時候,“隱藏”掉的資訊會阻礙上層應用挖掘極致的性能,有沒有兩全其美的辦法呢?
David Patterson在《計算機體系結構的黃金時代》一文中開出的藥方是從演算法到硬體直接打通,結合演算法和硬體的特點全部搞定制,定制表現在DSL和DSA,一方面是設計領域特定語言,方便編程,另一方面為面向領域應用設計領域特定架構,挖掘極致效率,
David Patterson的藥方既不是在已有方案中插入新的抽象層次,也不是完全不要中間抽象,而是把原有的抽象層次全部敲碎重建,這種重建是基于對演算法和硬體特點的充分挖掘,我理解這里有倆關鍵:軟硬體協同設計(分工),以及編譯器技術,
一方面,這里的思路和虛擬化不同之處是:不是向上層應用隱藏什么,而是強調要向上層暴露什么,或者說向上層讓渡什么職責,
另一方面,這里沒有期待只要提供一層API的抽象就包打天下,而是對從演算法到硬體的映射復雜性有充足的認識,這種映射既包含任務相關但硬體無關的問題,也包含硬體相關的問題,本質等同于人們熟知的編譯器技術,
說到這里,想到另一個“去虛擬化”的絕佳例子,就是軟體定義網路(Software defined network,SDN),對于同一套硬體基礎設施,承接不同的作業負載,交換機的最優轉發規則是不同的,SDN的思路是,令交換機的轉發規則是可編程的,對每一個不同的業務負載,都用靜態分析得到最優的轉發規則或策略(control plane),并按照這個規則對交換機編程,交換機在轉發資料時只需要按照已編程的規則執行即可(data plane),
在SDN的例子里,交換機讓渡了一部分職責給軟體,軟體根據不同的業務負載都生成不一樣的路由規則(策略),這是SDN平衡靈活性和極致性能的關鍵,
在OneFlow解決分布式深度學習的難題時,也是類似的思路,它不是靠額外引入的一個抽象層次實作,而是分成了控制平面和資料平面,在控制平面,編譯器根據特定深度學習模型的任務負載和底層硬體拓撲生成對這個配置最優的執行計劃(execution plan), 這個plan不是一勞永逸的,它需要上層模型的知識,也需要底層硬體的知識,模型或硬體拓撲一旦變化,plan就會變化,但是,編譯器生成plan的機制可以認為是不變的,也是整套系統的精髓,
5
結語
這篇文章補充解釋了我對“通過向上層演算法隱藏硬體資訊”的虛擬化思路,以及“通過向上層演算法暴露硬體資訊和讓渡職責”的去虛擬化的思路的理解,
簡單來說,虛擬化的思想強調的是隱藏(底層細節)和限制(上層的功能范圍),潛臺詞是:我認為對上層應用的需求足夠了解,告訴上層應用太多細節也沒有用,我把底層的東西一攬子處理好了,你只管呼叫我為你提供的API就可以了,
軟體定義的思想強調的是暴露(底層細節)和讓渡(硬體的策略可被軟體分析和配置),潛臺詞是:我對上層應用的需求了解不足,沒有辦法為上層應用提供一個足夠令人滿意的一攬子的策略,于是干脆把底層策略暴露給上層,上層應用對自己的需求和任務負載最清楚,上層自己來負責生成策略并來配置底層,
致力于提升深度學習系統性能的朋友對“去虛擬化”的思路應該是習以為常的,這應該是整個社區經過探索和碰壁逐漸收斂出來的主流思路,不是我個人的發明,我只是把觀察和理解寫下來而已,
順著這個思路,演算法-軟體-硬體協同優化領域正在發生一些令人興奮的進展,毫無疑問,廣義上的編譯器技術(無論是單設備代碼生成,還是分布式執行計劃生成)是里面最核心的部分,
注:題圖源自Pixabay
其他人都在看
淺談GPU虛擬化和分布式深度學習框架的異同
OneFlow v0.4.0 正式發布
動態調度的“詛咒”③
資料搬運的“詛咒”②
資源依賴的“詛咒”①
點擊“閱讀原文”,歡迎下載體驗OneFlow新一代開源深度學習框架


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289468.html
標籤:AI