文章目錄
- 一、簡要介紹
- 二、主要貢獻
- 三、相關背景
- (1)編碼器-解碼器架構
- (2)多分支結構
- (3)Fast-SCNN
- 四、網路架構
- (1)學習下采樣模塊
- (2)全域特征提取器
- (3)特征融合模塊
- (4)標準分類器
- 五、實驗結果
- (1)實驗環境與引數設定
- (2)在 Cityscapes 上的實驗效果
- (3)在弱標簽上測驗性能
- (4)大規模預訓練測驗結果
一、簡要介紹
本文發布于BMVC2019,是由英國東芝研究院Rudra、Stephan和劍橋大學Roberto共同完成的,本文的亮點是提出了一種快速的語意分割網路 Fast-SCNN,對于高解析度(1024×2048)影像,在 NVIDIA Titan XP GPU 上測驗表明,在Cityscapes資料集上的mIOU達到68.0%,速度達到123.5幀/秒,

二、主要貢獻
本文主要的貢獻,有以下幾個方面:
- 調整了捷徑連接,提出了一個淺層的learning to downsample模塊,可以快速而高效地通過multi-branch來提取低層次特征,
- 驗證了大規模的預訓練不是必須的,也可以通過加大訓練的輪數來達到接近的效果,
- 融合了經典編解-碼器框架和多分支框架的思想,提出了一個新的實時語意分割架構Fast-SCNN,
三、相關背景
語意分割通常由具有編碼器-解碼器框架的深度卷積神經網路(DCNN)來處理,而許多運行時高效的實作采用雙分支或多分支體系結構,
通常情況下,對于設計語意分割網路架構來說,需要注意以下幾個方面:
- 較大的感受野對于了解物件類之間的復雜關聯(即全域背景關系)非常重要
- 影像中的空間細節是保持物件邊界所必需的
- 需要特定的設計來平衡速度和準確性
(1)編碼器-解碼器架構
編碼器利用卷積和池化操作提取深度卷積網路特征,解碼器從低解析度特征上恢復空間資訊,然后通過像素分類層(softmax)來預測物體標簽,其中,編碼器通常采用VGG、ResNet來構建,解碼器則上采樣模塊來構建,
下面是經典的編碼器-解碼器架構,最開始的語意分割網路就是采用這種結構,比如FCN、SegNet、UNet等語意分割網路,
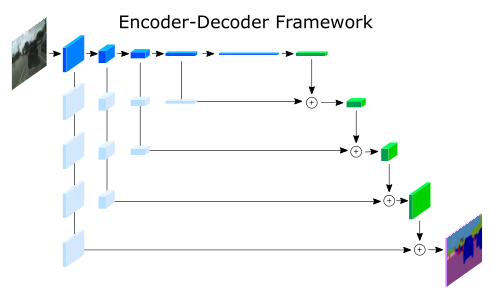
(2)多分支結構
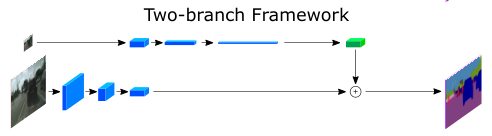
在雙分支網路中: 在低解析度輸入分支下,使用較深的CNN來捕捉全域背景關系;在全解析度輸入分支下,采用較淺的分支來學習空間細節;然后,通過合并兩者來提供最終的語意分割結果,通過這種設計方式,降低了網路的計算成本,使其能在一般GPU上實時運行,
下面是經典的多分支結構,采用這種的架構的語意分割網路實時性能一般都比較高,比如ICNet、ContextNet、BiSeNet 和 GUN 等一些語意分割網路,
(3)Fast-SCNN
本文提出的Fast-SCNN是一種融合了經典編解-碼器框架和多分支框架的實時語意分割演算法,

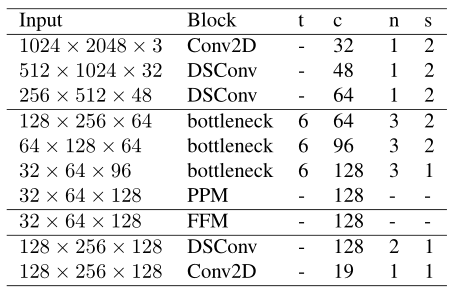
(1)學習下采樣模塊
在學習下采樣模塊中,采用了三層的結構,只使用了三層來確保低級特征共享的有效性和高效實施,第一層是標準卷積層(Conv2D),其余兩層是沿深度可分離的卷積層(DSConv),這里我們要強調的是,雖然DSConv的計算效率更高,但是在第一層仍然采用Conv2D,因為輸入影像只有三個通道,這使得DSConv的計算優勢在這個階段微不足道,
學習下采樣模塊中的所有三層都使用了步長為2、卷積核大小為3×3的卷積層,卷積層之后是批歸一化和RELU激活函式,
(2)全域特征提取器
全域特征提取器模塊旨在捕獲用于影像分割的全域背景關系,與對輸入影像的低解析度版本進行操作的普通兩分支方法相比,我們的模塊直接將學習的輸出帶到下采樣模塊(它是原始輸入的1/8解析度),
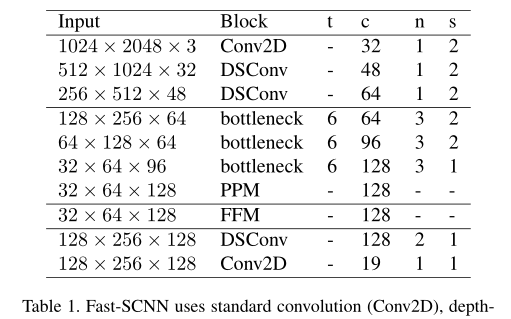
模塊的詳細結構如表1所示,我們使用了從 MobileNet-V2 引入的 bottleneck residual block(表2),特別是,當輸入和輸出大小相同時,我們對bottleneck residual block殘差連接,我們的bottleneck residual block使用了高效的深度可分離卷積,從而減少了引數和浮點運算的數量,此外,在末尾添加了一個金字塔池模塊(PPM) ,以聚合基于不同區域的背景關系資訊,

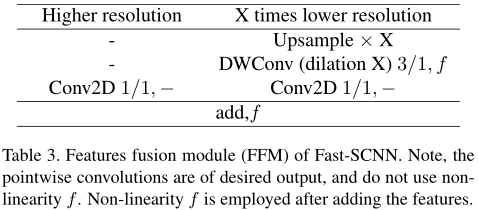
(3)特征融合模塊
與 ICNet 和 ContextNet 類似,通過簡單地融合不同branch的特征以確保有效性,或者,可以以運行時性能為代價使用更復雜的特征融合模塊(例如Bisenet),以達到更高的精度,特征融合模塊的詳細資訊如表3所示:
(4)標準分類器
在分類器中,我們采用了兩個深度可分離卷積(DSConv)和逐點卷積(Conv2D),我們發現,在特征融合模塊之后增加幾層可以提高準確率,分類器模塊的詳細資訊如表1所示,
在訓練期間使用Softmax,因為使用了梯度下降,在推理程序中,我們可以用argmax替換昂貴的softmax計算,因為這兩個函式都是單調遞增的,我們將此選項表示為Fast-SCNN cls(分類),另一方面,如果需要基于標準DCNN的概率模型,則使用SoftMax,表示為Fast-SCNN Prob(概率),
五、實驗結果
(1)實驗環境與引數設定
使用Python在TensorFlow機器學習平臺上進行了實驗,我們的實驗是在NVIDIA Titan X(Maxwell)或NVIDIA Titan XP(Pascal)GPU、CUDA 9.0和CuDNN v7的作業站上進行的,運行時評估在單個CPU執行緒和一個GPU中執行,以測量正向推理時間,
使用動量為0.045,批量為12的隨機梯度下降(SGD),受[4,37,10]的啟發,我們使用Poly學習率,基數為0.045,冪為0.9,類似于MobileNet-V2,我們發現深度卷積不需要L2正則化,對于其他層L2正則化引數是0.00004,
由于用于語意分割的訓練資料有限,實驗中應用了各種資料增強技術:0.5到2之間的隨機大小調整、平移/裁剪、水平翻轉、顏色通道噪聲和亮度,我們的模型是在交叉熵損失的情況下訓練的,我們發現,學習結束時的輔助損失對下采樣和具有0.4權重的全域特征提取模塊是有利的,
在每個非線性函式之前使用批量歸一化,Dropout僅用于最后一層,恰好在Softmax層之前,與MobileNet和ContextNet相反,我們發現Fast-SCNN使用RELU訓練速度更快,精度略高于ReLU6,即使使用我們在整個模型中使用的深度可分離卷積也是如此,
(2)在 Cityscapes 上的實驗效果
Cityscapes 是城市道路上最大的公開可用的資料集,該資料集包含從歐洲50個不同城市拍攝的各種高解析度影像(1024×2048px),它有5000張高標簽質量的影像:2975張的訓練集、500張的驗證集和1525張的測驗集,
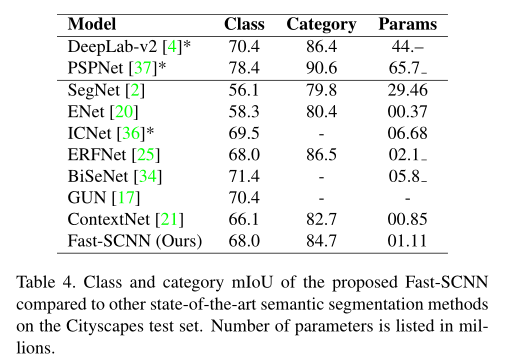
在 Cityscapes 測驗集上評估整體性能,與其他實時語意分割方法(ContextNet、BiSeNet、GUN、ENET 和 ICNet)和離線語意分割方法(PSPNet 、DeepLab-V2)的比較,平均精確度mIOU如下圖所示:
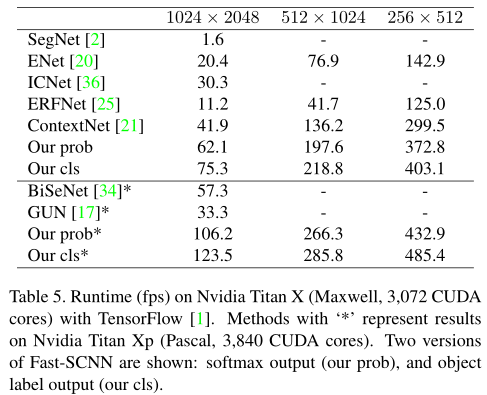
分別在英偉達 Titan X 和 Titan Xp(帶*號)上進行測驗,測得其與不同分割網路的檢測速度對比:
(3)在弱標簽上測驗性能
采用弱標簽Coarse、預訓練模型ImageNet的形式,進行了幾組不同的實驗,實驗結果對比如下表所示:

從實驗結果可以看出,在低容量DCNN上附加弱標記資料進行訓練,沒有對性顯著的改善,
(4)大規模預訓練測驗結果
下圖是采用弱標簽Coarse、預訓練模型ImageNet訓練程序中的測驗資料:
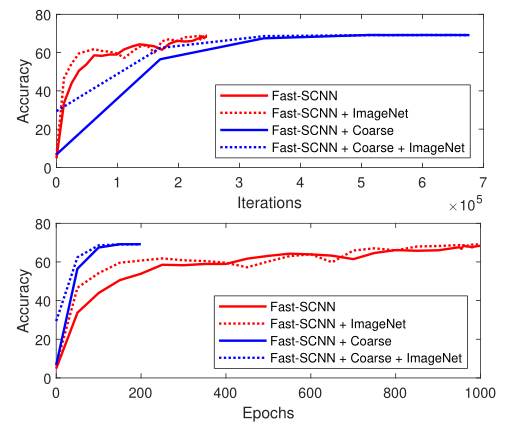
從圖中可以看出,不管是采用弱標簽Coarse,還是預訓練模型ImageNet的方式,最終的準確度都趨于一樣,所以,通過本實驗可以反映出:弱標簽Coarse,預訓練模型ImageNet對于低容量的Fast SCNN作用不大,甚至,只要訓練的時間足夠久,不經過Coarse或ImageNet進行訓練的模型可以達到相同的效果,
最好的關系是互相成就,各位的「三連」就是【AI 菌】創作的最大動力,我們下期見!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289579.html
標籤:其他
上一篇:資料結構(11)---二叉樹
下一篇:【C++】友元+記憶體管理