物聯網應用中一種常見場景是:假設有一流量表(比如供氣站的接納量、風力發電站的風量流量計、居民用戶表等),每隔1秒鐘上報當前累積量,要求準實時統計該表具當日以及當月和當年的資料量,
分析:初看起來,這是小學生都會的數學減法問題:用當前值減去初始值,然而小學生的思維過于簡單和理想化,現實很復雜,因為在自然環境中存放的表具會斷電、表具會損壞、例外環境會讓表具讀數例外(如跳表)、表讀數達到最大值等,如果用當前值減去初始值,會因為忽略這期間的例外變化而導致資料丟失,進而得到不正確的結果,解決該問題可以借鑒銀行的存盤余額的做法,除了有一個匯總余額的結果,還必須有一個”消費明細“用于對賬和審計,在我們這個示例場景中,每秒鐘1次上報就是明細資料,有了明細資料后就可以計算一段時間范圍內的累計值,然后再把所有小范圍內的累計值再次匯總,即最終的結果,但是小范圍的時間范視窗取多大合適呢?如果時間視窗過小,可能會因為資料過小導致累計誤差放大,時間視窗過大,無法滿足業務需求,業務場景中一般會要求最近一分鐘、一小時或者一天,都有可能,這取決于應用需求,假如應用的最小統計周期為一小時,那么統計視窗為1小時,而實際中一個完整的業務日往往也是精確到小時級別,比如今日的8點鐘到明日的8點鐘視為今日,此時按照一小時匯總是比較合適的值,接下來我們看如何做?
按照表具數量分為3種情況來分析:One、Many、too Many,
One
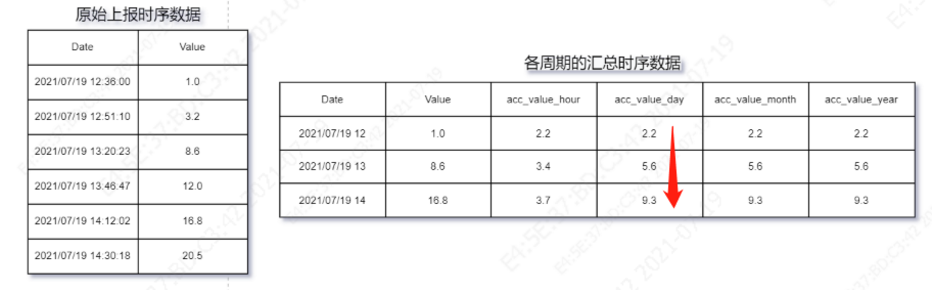
單表情況主要用于描述思路和演示,如下圖所示:低頻資料在高頻資料基礎上匯總,每個低頻資料記錄行格式為(統計周期、當前統計周期的初始值、當前周期內的累計值、日累計值、月累計值、年累計值),統計周期為唯一鍵,記錄的資料更新由最高頻資料到達觸發,比如當原始秒級的時序資料到達,觸發小時級及以上周期的行匯總資料同時”原地“更新:在同一資料行上更新累計值,其中當前小時統計周期內的累計值(acc_value_hour)為表具當前值與當前小時周期內的初始值的差值,其他周期內的累計值為當前小時統計周期內的累計值與上一小時統計周期內的累計值之和,比如圖中紅色箭頭的累加方向為榷訓總程序,
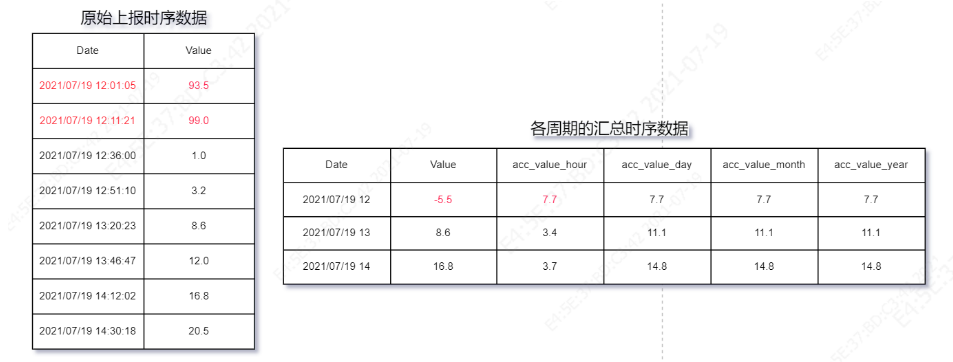
表具資料上報程序中,正常情況只增不減,但會存在例外值,例外值可能過大或者過小兩種情況,過小比如下圖中的示例:12點范圍的初始值正常為93.5,但是到第3條記錄出現時,該值遠小于前面的記錄,假設前面的記錄正常,而該記錄遠小于前面記錄的平均值,因此可以有理由認為表具出現變更重新計數,因此簡單的做法可以將前面正常的累計值取負作為新的初始值,
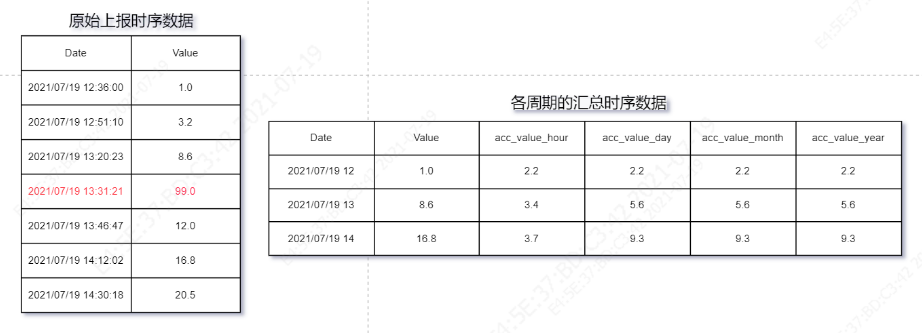
而過大的情況比如下圖中的示例:13點范圍內的某條記錄值遠大于之前記錄的平均值,此時有理由認為該值出現例外,對此做法可以根據情況自由而定,比如可以忽略該值,或者根據歷史平均值對其修正,
Many
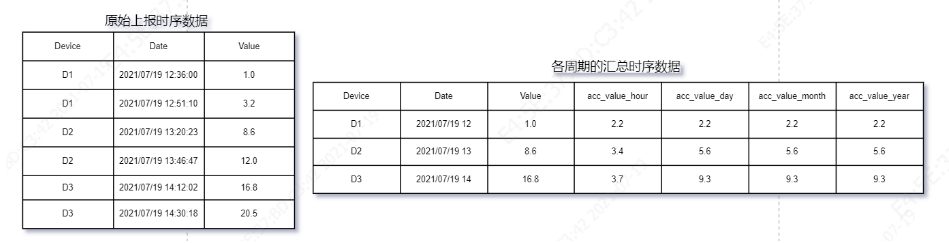
從單表的資料處理程序可知,小時周期資料匯總只跟當前記錄行資料有關系,其他周期匯總資料跟前一條資料有關系,而在資料例外處理程序中,最多跟當前小時周期的資料量有關,而例外情況發生頻率較低,因此通常情況下,每次更新記錄涉及至少2次讀寫,該統計操作的復雜度為O(1),對于有Many表的情況下,復雜度為O(n),n為設備數量,基于OLTP處理模式處理,上述資料存盤格式可增加設備標識:
此時常規的在線處理架構(如分布式服務和高并發讀寫系統)能勝任大部分以上場景的統計需求,然而其瓶頸是存盤系統的讀寫效率和存盤規模,比如假設場景有1000塊不同的表具,資料上報頻率為1次每秒,那么資料更新,讀寫操作頻率為至少每秒2000次,每天的原始時序資料記錄條數為1000*24*3600=8,6400,000,統計記錄條數為1000*24條,如果提高表的數量或者資料上報頻率,這個資料會更大,當然該場景還有很大優化空間,比如將原始時序表用其他系統存盤,比如訊息系統,資料統計結果更新也可以先合并后批量更新等,實際上這些優化方式已經進入OLAP模式了,或者說進入兩者的中間地帶,
too Many
分析上述OLTP模式,其瓶頸在于有速度無吞吐量,這也是批處理和”單個“處理的區別,那如何用批處理重做一遍呢?實際上根據日期維度,通過幾條group by即可,group by的匯總資料可以實作分組內的自定義邏輯如例外值剔除等資料清洗、求平均值等,接下來需要重點考慮的是如何優化巨量時序資料存盤的問題,常規方案很容易做到,比如這樣:
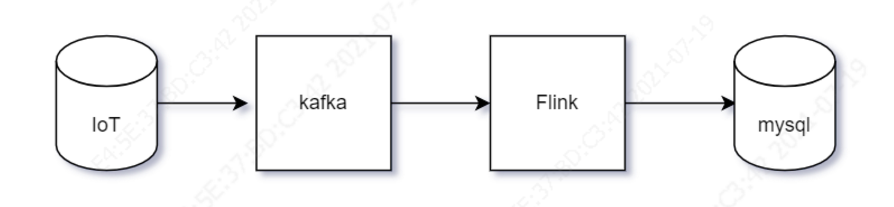
使用Flink的時間范圍為1小時的滾動視窗實作資料的聚合處理,然后將結果存盤到資料庫,既然說到這里,我們將問題描述得更為真實一些:比如某天然氣加氣站,有多個入口和多個出口,每個出入口都有多種型別的表具(計量表、溫度表、壓力表、閥門開關表等),如何實時計算并展示每個表具或站點的歷史資料變化曲線?
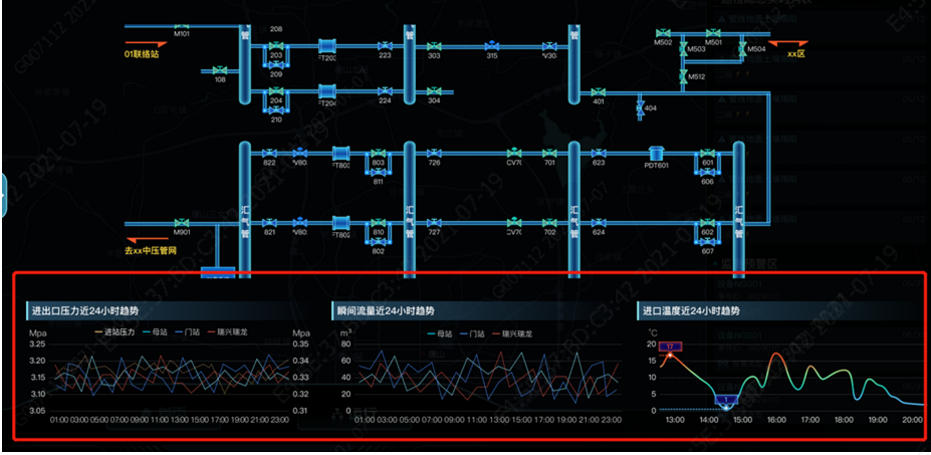
分析:先看看上述架構能否滿足,首先基于1小時的時間視窗計算,也能計算每小時內的累計流量以及最新瞬時流量、溫度和壓力值,然而如果在這個工藝圖中實時監控各閥門開閉狀態,如果不增加現有架構的復雜度情況下,能否實作呢?如果業務方要求縮小時間范圍,每隔5分鐘采集一個資料點,不增加現有架構的復雜度情況下,能否實作呢?留給讀者思考吧,歡迎后臺留言和討論,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289683.html
標籤:其他