1、實戰問題
在使用 Elasticsearch 程序中,不免還會有 Mysql 等關系型資料庫的使用痕跡,以下兩個都是實戰開發問到的問題:
Elasticsearch 新增欄位,能在 Mapping 設定默認值嗎?
Elasticsearch 有什么好的方式維護檔案的 create_time (創建時間)和 update_time (更新時間)嗎?
本文就從 Elasticsearch 默認值的實作方案說開去,
2、Elasticsearch Mapping 層面默認值
認知前提:嚴格講 Elasticsearch 是不支持 Mapping 層面設定資料型別的時候,設定欄位的默認值的,
有人會說,null value 設定算不算?不算,
大家看一下:
PUT my-index-000001
{
"mappings": {
"properties": {
"status_code": {
"type": "keyword",
"null_value": "NULL"
}
}
}
}
null_value 的本質是將“NULL” 替換 null 值,以使得空值可被索引或者檢索,
我們期望設定 Mapping 的時候,可以對各種資料型別添加一個任意指定的預設值,但是 Elasticsearch Mapping 層面不支持,咋辦?
只能去尋找其他的方案,
3、曲線救國實作 Elasticsearch 設定默認值
直接給出答案,共三種設定默認值的,
3.1 方案 一:pipeline 設定默認值
# 創建 append 管道
PUT _ingest/pipeline/add_default_pipeline
{
"processors": [
{
"set": {
"field": "sale_count",
"value": 1
}
}
]
}
# 創建索引
PUT customer
{
"mappings":{
"properties":{
"sale_count":{
"type":"integer"
},
"major":{
"type":"keyword",
"null_value": "NULL"
}
}
},
"settings": {
"index":{
"default_pipeline":"add_default_pipeline"
}
}
}
插入資料,驗證一把:
POST customer/_doc/1
{
"major":null
}
回傳結果:
"max_score" : 1.0,
"hits" : [
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"major" : null,
"sale_count" : 1
}
}
]
}
以上的方式,實作了sale_count 的默認值為1 的設定,
是借助索引設計層面在 setting 中關聯 default_pipeline 實作的,
實作方式相對簡單,能保證用戶在設定索引的前提下,用戶只關注寫入資料,其他后臺預處理管道幫助實作細節,
引申一下,針對開篇提到的第二個問題:
create_time 借助 pipeline 管道預處理 set processor 實作即可,
PUT _ingest/pipeline/create_time_pipeline
{
"description": "Adds create_time timestamp to documents",
"processors": [
{
"set": {
"field": "_source.create_time",
"value": "{{_ingest.timestamp}}"
}
}
]
}
DELETE my_index_0003
PUT my_index_0003
{
"settings": {
"index.default_pipeline": "create_time_pipeline"
}
}
POST my_index_0003/_doc/1
{}
GET my_index_0003/_search
update_time 自己維護更新,業務更新的時刻通過代碼或者腳本加上時間戳就可以,
3.2 方案 二:update_by_query 通過更新添加默認值
POST customer/_doc/2
{
"major":null
}
# 批量更新腳本
POST customer/_update_by_query
{
"script": {
"lang": "painless",
"source": "if (ctx._source.major == null) {ctx._source.major = 'student'}"
}
}
POST customer/_search
結果是:
所有 major 為 null 的,都實作了更新,設定成了:“student",
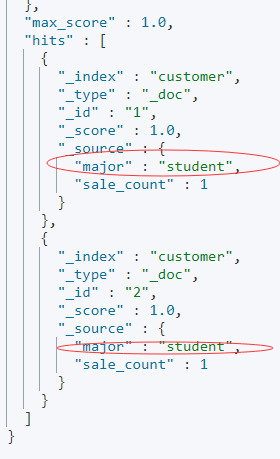
該方式屬于先寫入資料,然后實作資料層面的更新,算作設定默認值甚至都有點勉強,
3.3 方案 三:借助 pipeline script 更新
PUT _ingest/pipeline/update_pipeline
{
"processors": [
{
"script": {
"lang": "painless",
"source": """
if (ctx['major'] == null) {ctx['major'] = 'student'}
"""
}
}
]
}
POST customer/_doc/4
{
"major":null
}
POST customer/_update_by_query?pipeline=update_pipeline
{
"query": {
"match_all": {}
}
}
結果是:同方案二,也實作了更新,
該方案是第二種方案的內卷版本,本質實作基本一致,
強調細節不同點,ctx 取值的時候,細節語法不一樣:
腳本script 操作,訪問方式:ctx._source.major,
pipeline 預處理腳本操作:訪問方式:ctx['major'] ,
4、小結
本文講解了 Elasticsearch 實作類關系型資料庫默認值的三種方案,只有第一種屬于前置設定默認值,
后兩種都是先寫入后設定默認值的腳本更新實作方案,實戰方案選型,推薦方案一,
推薦
1、如何系統的學習 Elasticsearch ?
2、全網首發!《 Elasticsearch 最少必要知識教程 V1.0 》低調發布
3、從實戰中來,到實戰中去——Elasticsearch 技能更快提升方法論
4、刻意練習 Elasticsearch 10000 個小時,鬼知道經歷了什么?!
更短時間更快習得更多干貨!
中國50%+Elastic認證工程師出自于此!

比同事搶先一步學習進階干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290030.html
標籤:其他