1 Discovery
Discovery模塊負責發現集群中的節點、選擇主節點,
ES支持多種不同Discovery型別選擇,內置的實作有兩種:Zen Discovery和Coordinator
7.x以上版本Coordinator提供了安全的亞秒級的master選舉時間,而Zen可能要花幾秒鐘來選擇一個新的master
涉及的核心配置如下,其它配置引數,參見: master-election-settings:
- discovery.seed_hosts: 提供群集中符合master-eligible的節點地址串列
- cluster.initial_master_nodes : 設定全新集群中符合主節點條件的初始節點集,默認情況下,此串列為空,這意味著該節點希望加入已經bootstrap的集群
ES集群中可能會有多個master-eligible node,在集群啟動時需要進行master選舉,保證只有一個當選master,如果有多個node當選為master,則集群會出現腦裂,腦裂會破壞資料的一致性,導致集群行為不可控,產生各種非預期的影響,
1.1 Coordinator
ES 7.x 重構了一個新的集群協調層Coordinator,采用 Raft 的實作,但并非嚴格按照 Raft 論文實作,而是根據ES做了一些調整
使用的演算法可以在配置中指定,詳見代碼如下:
org.elasticsearch.discovery.DiscoveryModule.DiscoveryModule的建構式
if (ZEN2_DISCOVERY_TYPE.equals(discoveryType) || SINGLE_NODE_DISCOVERY_TYPE.equals(discoveryType)) {
discovery = new Coordinator(NODE_NAME_SETTING.get(settings),
settings, clusterSettings,
transportService, namedWriteableRegistry, allocationService, masterService,
() -> gatewayMetaState.getPersistedState(settings, (ClusterApplierService) clusterApplier), seedHostsProvider,
clusterApplier, joinValidators, new Random(Randomness.get().nextLong()));
} else if (ZEN_DISCOVERY_TYPE.equals(discoveryType)) {
discovery = new ZenDiscovery(settings, threadPool, transportService, namedWriteableRegistry, masterService, clusterApplier,
clusterSettings, seedHostsProvider, allocationService, joinValidators, gatewayMetaState);
} else {
throw new IllegalArgumentException("Unknown discovery type [" + discoveryType + "]");
}
1.2 Zen Discovery
采用Bully演算法 Bully演算法是Leader選舉的基本演算法之一,優點是易于實作,該演算法和Solr Leader Shard選舉非常相似,
該演算法假定所有節點都有一個唯一的ID,使用該ID對節點進行排序,選擇最小的節點作為Master
任何時候當前Leader都是參與集群的最小ID節點,該演算法的優點是易于實作,
但是當擁有最小ID的節點處于不穩定狀態的場景下會有問題,例如Master負載過重而假死,集群擁有第二小ID的節點被選為新主,這時原來的Master恢復,再次被選為新主,然后又假死,
ES 通過推遲選舉,直到當前的 Master 失效來解決上述問題,只要當前主節點不掛掉,就不重新選主,但是容易產生腦裂(雙主),為此,再通過“法定得票人數過半”解決腦裂問題
1.3 演算法比較【raft & bully】
相同點
- 多數派原則:必須得到超過半數的選票才能成為master,
- 選出的leader一定擁有最新已提交資料:在raft中,資料更新的節點不會給資料舊的節點投選票,而當選需要多數派的選票,則當選人一定有最新已提交資料,在es中,clusterStateVersion大的節點排序優先級高,同樣用于保證這一點,
不同點
- 正確性論證:raft是一個被論證過正確性的演算法,而ES的演算法是一個沒有經過論證的演算法,只能在實踐中發現問題,做bug fix,這是我認為最大的不同,
- 是否有選舉周期term:raft引入了選舉周期的概念,每輪選舉term加1,保證了在同一個term下每個參與人只能投1票,ES在選舉時沒有term的概念,不能保證每輪每個節點只投一票,
- 選舉的傾向性:raft中只要一個節點擁有最新的已提交的資料,則有機會選舉成為master,在ES中,version相同時會按照NodeId排序,總是NodeId小的人優先級高,
2 Zen Discovery選舉
2.1 何時觸發
- 集群啟動,從無主狀態到產生新主時
- 集群在正常運行程序中,Master探測到節點離開時(NodesFaultDetection)
- 集群在正常運行程序中,非Master節點探測到Master離開時(MasterFaultDetection)
2.2 選舉誰
從原始碼分析,選舉集群狀態版本最高的作為master
先根據節點的clusterStateVersion比較,clusterStateVersion越大,優先級越高,clusterStateVersion相同時,進入compareNodes,其內部按照節點的Id比較(Id為節點第一次啟動時隨機生成),
選舉集群狀態版本最高的作為master的原因如下:
- 為了保證新Master擁有最新的clusterState(即集群的meta),避免已經commit的meta變更丟失,因為Master當選后,就會以這個版本的clusterState為基礎進行更新,
- 當clusterStateVersion相同時,節點的Id越小,優先級越高,即總是傾向于選擇Id小的Node,這個Id是節點第一次啟動時生成的一個隨機字串,之所以這么設計,應該是為了讓選舉結果盡可能穩定,不要出現都想當master而選不出來的情況,
參見ElectMasterService類中的這2個方法
/**
* Elects a new master out of the possible nodes, returning it. Returns {@code null}
* if no master has been elected.
*/
public MasterCandidate electMaster(Collection<MasterCandidate> candidates) {
assert hasEnoughCandidates(candidates);
List<MasterCandidate> sortedCandidates = new ArrayList<>(candidates);
sortedCandidates.sort(MasterCandidate::compare);
return sortedCandidates.get(0);
}
/**
* compares two candidates to indicate which the a better master.
* A higher cluster state version is better
*
* @return -1 if c1 is a batter candidate, 1 if c2.
*/
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// we explicitly swap c1 and c2 here. the code expects "better" is lower in a sorted
// list, so if c2 has a higher cluster state version, it needs to come first.
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}
2.3 選舉流程
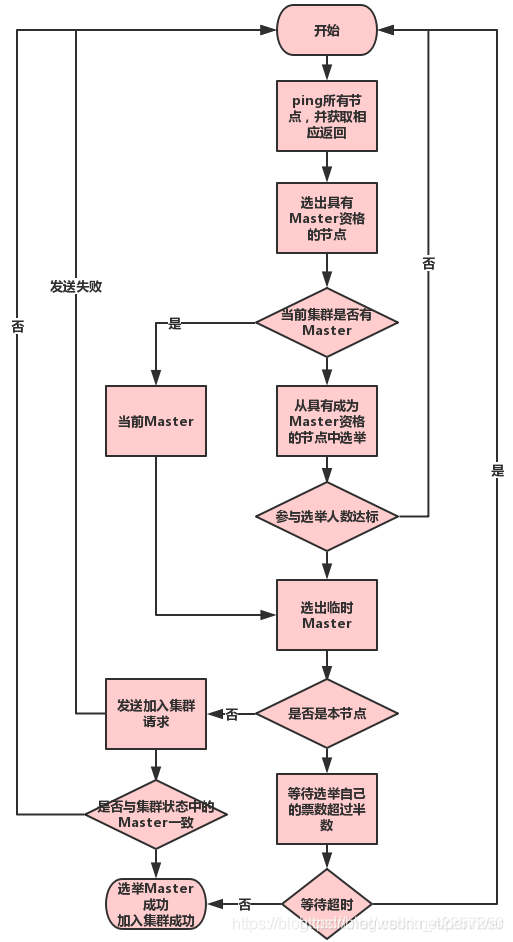
代碼詳見:ZenDiscovery的findMaster()方法
- ping所有節點,并獲取PingResponse回傳結果(findMaster)
- 過濾出具有Master資格的節點(filterPingResponses)并轉換為masterCandidates
- 選出臨時Master,根據PingResponse結果構建兩個串列:activeMasters和masterCandidates,
3.1. 如果activeMasters非空,則從activeMasters中選擇最合適的作為Master;
3.2. 如果activeMasters為空,則從masterCandidates中選舉,結果可能選舉成功,也可能選舉失敗, - 判斷臨時Master是否是本節點,
4.1. 如果臨時Master是本節點:則等待其他節點選我,默認30秒超時,成功的話就發布新的clusterState,(當選總統候選人,只等選票過半了)
4.2. 如果臨時Master是其他節點:則不再接受其他節點的join請求,并向Master節點發送加入請求
3 節點失效檢測
選主流程之后不可或缺的步驟,不執行失效檢測可能會產生腦裂現象,
定期(默認為1s)發送ping請求探測節點是否正常,當失敗達到一定次數(默認為3次),或者收到節點的離線通知時,開始處理節點離開事件,
3.1 NodesFaultDetection
NodesFaultDetection在Master節點啟動,定期探測加入集群的節點是否活躍,當有節點連不上時,會執行removeNode,然后需要審視此時的法定人數是否達標,不達標就主動放棄Master身份執行rejoin以避免腦裂,
3.2 MasterFaultDetection
MasterFaultDetection在非Master節點啟動,定期探測Master節點是否活躍,Master下線則觸發rejoin重新選舉,
參考
found-leader-election-in-general#the-zen-way
modules-discovery-settings.html#master-election-settings
Elasticsearch選主流程
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290031.html
標籤:其他