一、準備作業:
1.機器準備:
我們準備了6臺機器用來部署clickhouse,準備搭建一個3分片2副本集群,當然也可根據你自己實際情況選擇機器數量,
2.在每臺機器上安裝clickhouse:
依次執行以下命令(來源于官網檔案):
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
sudo yum install clickhouse-server clickhouse-client
3.啟動每臺機器的clickhouse:
sudo systemctl start clickhouse-server
啟動后可以查看狀態:
sudo systemctl status clickhouse-server
啟動成功后,可以使用命令連接clickhouse:
clickhouse-client
成功進入會顯示下:
4.部署zookeeper集群:
為什么使用zookeeper?不用也可以,但建議還是使用,附上我搭建zookeeper的教程連接:
zookeeper集群部署教程
(一定要看,本人親自搭建過,一步一步來,不會有問題)
二、clickhouse集群部署方式
ClickHouse提供了非常高級的基于zookeeper的表復制方式,同時也提供了基于Cluster的復制方式,分析一下這兩種方式:
首先附上clickhouse的組態檔目錄: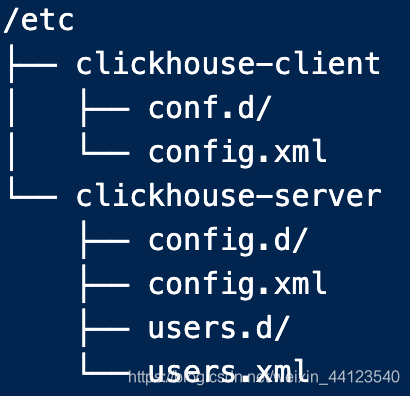
1.基于zookeeper的表復制方式:
打開這個組態檔:
/etc/clickhouse-server/config.xml
(1)配置 listen_host欄位:
<listen_host>::1</listen_host>
<listen_host>127.0.0.1</listen_host>
(2)配置zookeeper欄位:
host改成你自己的zookeeper 內網ip地址
<zookeeper>
<node index="1">
<host>172.31.36.230</host>
<port>2181</port>
</node>
<node index="2">
<host>172.31.36.231</host>
<port>2181</port>
</node>
<node index="3">
<host>172.31.36.232</host>
<port>2181</port>
</node>
</zookeeper>
3.配置 remote_server欄位:
找到組態檔中的 remote_server標簽,發現它里面有很多的內容,我們沒有都用到,它只是給我一個例子,把里面的內容都洗掉,粘貼上我們自己想要的:
<remote_servers>
<!--ck_cluster是集群名字,自己命名就可以,建庫建表需要用到-->
<ck_cluster>
<!-- 資料分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.32.28.141</host>
<port>9000</port>
</replica>
<replica>
<host>172.32.28.142</host>
<port>9000</port>
</replica>
</shard>
<!-- 資料分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.32.28.143</host>
<port>9000</port>
</replica>
<replica>
<host>172.32.28.144</host>
<port>9000</port>
</replica>
</shard>
<!-- 資料分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.32.28.145</host>
<port>9000</port>
</replica>
<replica>
<host>172.32.28.146</host>
<port>9000</port>
</replica>
</shard>
</ck_cluster>
</remote_servers>
由于我們準備部署的是3分片2副本的集群,現在來解釋一下配置引數的意思:
<shard></shard>
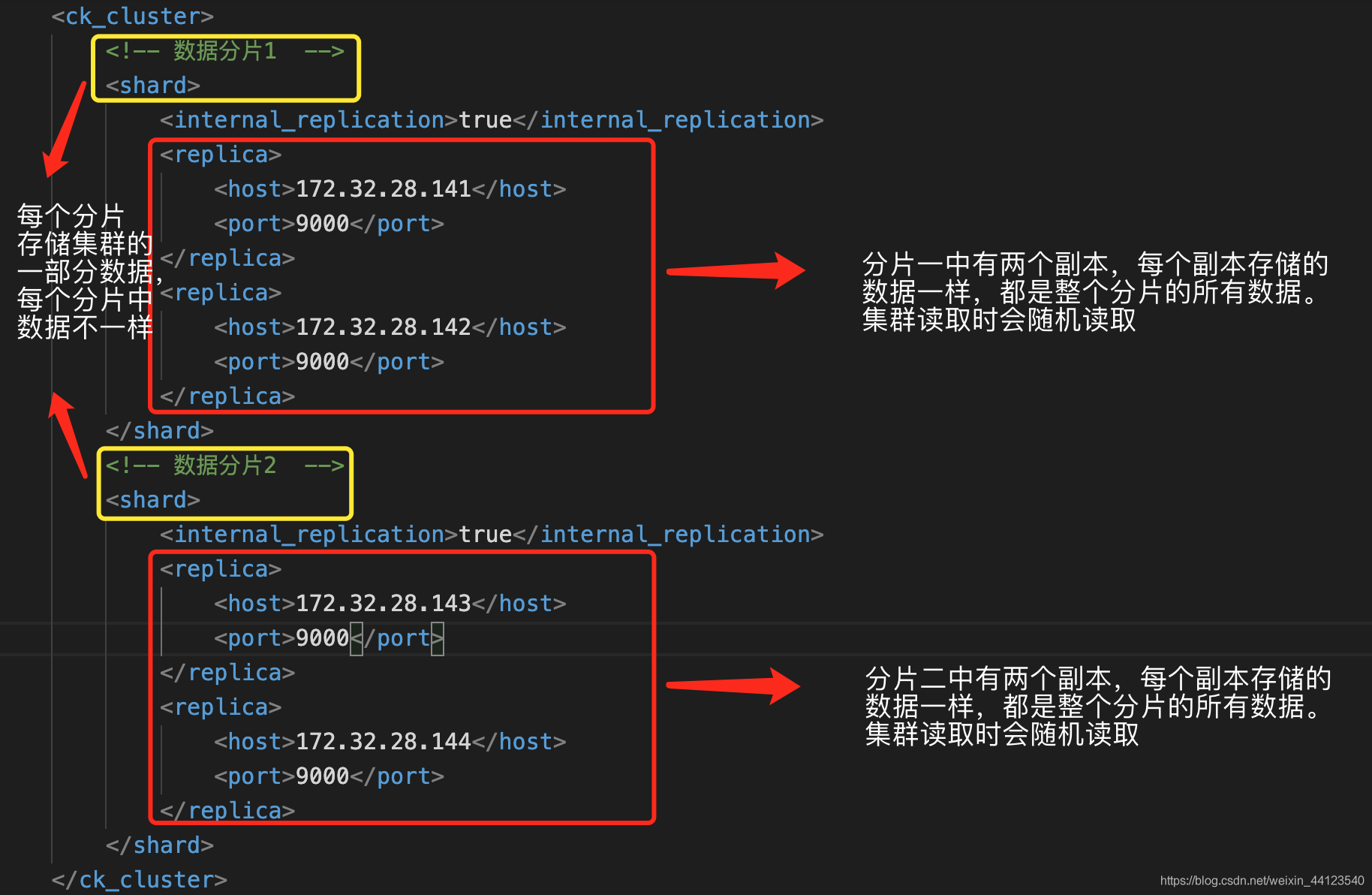
shard標簽代表分片的意思,如上圖我們有3個分片,clickhouse集群中每個分片會存盤整個集群一部分的資料,每個分片中有這個標簽:
<replica></replica>
代表副本的意思,什么是副本?比如我只有三臺機器做三個分片,那么每個分片中只有這一臺機器作為副本,這臺機器存盤這個分片的所有資料,若這臺機器掛掉了,那么資料就丟了,那如果我們有6臺機器或者更多,每個分片里就可以配置兩個副本機器,這兩個副本存盤的資料是一摸一樣的,集群讀取資料時會隨機從其中選擇一個讀取,這樣即使一臺機器掛掉了,也不會影響正常使用,而且對業務來說是無感的,資料一切正常,
還有最重要的這個標簽:
<internal_replication>true</internal_replication>
因為我們和zookeeper配合使用,internal_replication必須設定為true,原因等下解釋,
來張圖,看起來更直觀:
(4)配置macros欄位:
根據每臺機器的分片副本,配置,如:第3分片的第一副本這樣配置:
<macros>
<shard>03</shard>
<replica>01</replica>
</macros>
比如:我們所有機器具體資訊:
ck01: shard=01, replica=01
ck02: shard=01, replica=02
ck03: shard=02, replica=01
ck04: shard=02, replica=02
ck05: shard=03, replica=01
ck05: shard=03, replica=02
配置后可以再每臺機器上用命令查看是否成功:
select * from system.macros
第一分片第一副本的機器會顯示:
┌─macro───┬─substitution─┐
│ replica │ 01 │
│ shard │ 01 │
└─────────┴──────────────┘
組態檔是熱更新的,所以修改配置后無需要重啟服務,除非是首次啟動 ClickHouse ,
(5)實驗:
當我們配置完成以上之后,基于zookeeper的clickhouse集群就部署完成了,我們做幾個簡單的實驗來驗證:
查看集群狀態:
隨便選一臺機器,連接clickhouse后,輸入命令:
select * from system.clusters;
如果集群部署成功,你會看到所有機器的資訊,
創建 ReplicatedMergeTree 測驗表:
任選一臺機器,創建一個 ReplicatedMergeTree 引擎的測驗表,測驗 ZooKeeper 同步功能
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_ck', '{replica}') PARTITION BY toYYYYMM(EventDate) ORDER BY (Number, EventDate, intHash32(id)) SAMPLE BY intHash32(id);
在其他機器節點show tables查看表結構是否同步成功;
驗證同一分片不同副本資料備份是否生效:
-- ck01 登錄執行
insert into test_ck values ('2021-02-01 00:00:01', 2, 2);
-- ck02 登錄執行
select * from test
若資料存在,則表示資料同步配置成功!
創建 Distributed 引擎測驗表:
創建一個分布式測驗表測驗資料分片是否正常,因為已經配置了zookeeper,所以創建表的DDL陳述句也會同步到其他節點上,
CREATE TABLE dis_test ON CLUSTER ck_cluster AS test_ck
ENGINE = Distributed(ck_cluster, default, test_ck, rand())
//引數含義:ck_cluster集群名稱,default資料庫,test_ck表,rand()分布式表采用的分配演算法,除了這個還有sipHash64(欄位名)
(注意:分布式表是基于已經存在的本地表來實作的,分布式表相當于視圖,本身并不存盤資料,寫分布式表,分布式表會將資料發送到各個機器上,查分布式表,會聚合所有機器的資料顯示)
插入分布式表幾條資料:
insert into dis_test values ('2021-07-01 8:00:01', 1,10);
insert into dis_test values ('2021-07-01 8:00:02', 11,15);
insert into dis_test values ('2021-07-01 8:00:03', 10,15);
insert into dis_test values ('2021-07-01 8:00:04', 13,5);
insert into dis_test values ('2021-07-01 8:00:05', 1,5);
insert into dis_test values ('2021-07-01 8:00:06', 12,14);
直接查詢分布式表可以看到這些資料:
select * from dis_test
可以在每個分片的一個機器上查看本地表test_ck,看每個分片都有幾條資料:
select * from test_ck
至此,基于zookeeper的clickhouse集群部署方式完成!
2.基于Cluster的復制方式:
大致說一下這種方式,包括官方在內都不推薦這種方式,這種方式不需要配置zookeeper,
如果我們想使用這種方式,需要打開組態檔:
/etc/clickhouse-server/config.xml
找到<remote_servers>這個標簽,下面的所有資訊就是我們配置集群的配置資訊,和上邊基本一致,但這個標簽<internal_replication>false</internal_replication>不一樣,里面要寫false
詳細說一下:
(1)internal_replication=false時:
往分布式表(注意分布式表只是本地表的view,是不存放任何物體資料的)里面寫入資料時,表層面自動同步開啟,資料會寫入所有備份中(同屬一個shard內的表資料相同),但是這個時候是不校驗資料一致性的(比如說寫入server1的時候成功了,但是寫入server1的備份server2的時候有一些沒有寫入成功,那么這兩個互為備份的表就不一致了),也就是說,有可能出現兩個備份資料略微不一致的情況,雖然這種可能性很小,另外出現了不一致的時候表之間不會自動同步需要自己手動,這種被官方稱為poor man’s replication,如果喜歡簡單而且特別討厭配置zookeeper的話可以使用
(2)internal_replication=true,且沒有zookeeper的配合:
不使用zookeeper,那么往分布式表寫入資料時,是只寫入一組備份中的(也就是說同一個shard內部只有一個表寫入了資料,其他的表均不會寫入資料,除非有一個宕機另外的作為補充下入,但是這個時候表之間的資料就不同了,需要人工手動統一(備份合并就是shard總體),實際測驗中,當向分布式表寫入資料時,replica group 1 被寫入了資料,replica group 2 沒有被寫入資料,在此種條件下(internal_replication=true時且不使用zookeeper),存在海量風險,極其不建議使用: 實際測驗中,所有節點均正常作業的情況下,使用分布式表查詢,同樣的sql陳述句會出現前后結果不一致的情況 當有節點掛掉時候,那么掛掉之前的資料是寫入備份A,掛掉之后資料寫入了備份B(此時集群還是正常作業的),當你去使用分布表查詢資料時,是肯定會得到錯誤結果的,因為分布表的查詢方式是每個shard中選取一個表來查詢并合并結果,由于備份A和備份B之間沒同步,那么你查詢的只是一部分資料,這種方法切記不能使用!
(3)internal_replication=true時:
使用ReplicatedMergeTree表引擎+zookeeper,這種方案看起來配置很多但是也是最穩定的方案,
三、總結:
對比clickhouse集群部署提供的兩種方案,基于zookeeper的部署方案更穩重更安全,所以建議采用這種,
另外在搭建完成后,我們創建了分布式表和本地表,在上述實驗中,我們是直接寫分布式表,分布式表會將資料發送到其他機器的本地表上,有人建議不要直接這么做,我查閱了很多文章,總結一下原因:
1.資料量很大時:
當每天資料量很大時,比如每天上億級別或以上,
由于分布式表的邏輯簡單,僅僅是轉發請求,所以在轉發安全性上,會有風險,并且rand的方式,可能會造成不均衡,而且Distributed表在寫入時會在本地節點生成臨時資料,會產生寫放大,所以會對CPU及記憶體造成一些額外消耗,分布式表接收到資料后會將資料拆分成多個parts, 并轉發資料到其它服務器, 會引起服務器間網路流量增加、服務器merge的作業量增加, 導致寫入速度變慢, 并且增加了Too many parts的可能性.因此資料量大時建議通過輪詢的方式寫本地表,這樣最保險和均衡,這也是很多人建議使用的,
1.資料量并不大時:
直接寫分布式表和輪詢寫本地表都差不多,想用哪種方式都可以,
其實分布式表的本質就是一個視圖,設計的目的就是為了查詢的,雖然資料量不大時沒有什么影響,
2.綜上所述,我覺得集群部署使用的最佳建議:
(1)采用基于zookeeper的方式部署集群
(2)每個分片最少有兩個副本來保證資料一致性
(3)讀分布式表,分布式表只做查詢
(4)通過負載均衡的方式寫本地表
(5)盡量做1000條以上批量的寫入,避免逐行insert或小批量的insert,update,delete操作,因為ClickHouse底層會不斷的做異步的資料合并,會影響查詢性能,
大家如果有什么問題直接給我留言~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290037.html
標籤:其他