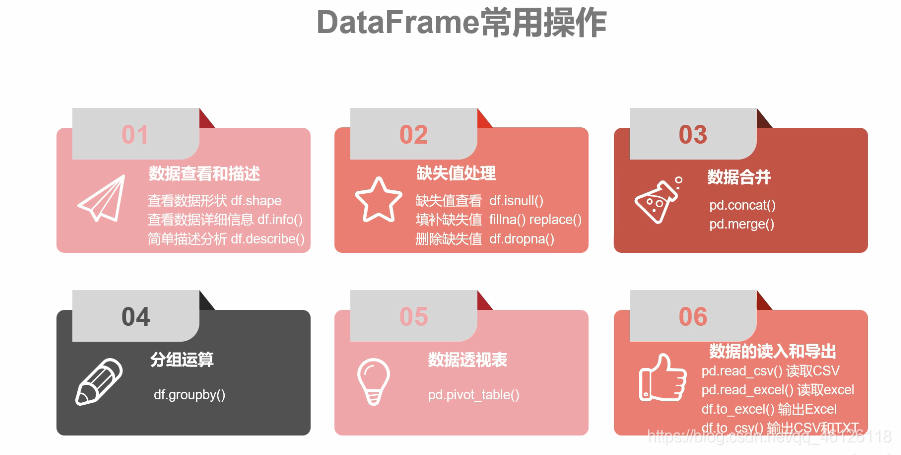
pandas-DataFrame常用操作
- 一、資料查看與描述
- 二、缺失值的處理
- 1、查看缺失值
- 2、填充缺失值
- 3、洗掉缺失值
- 三、資料的合并
- 1、pd.concat()函式
- 2、pd.merge()函式
- 四、分組運算
- 五、資料透視表
一、資料查看與描述
【首先講述一下如何進入jupyter notebook,需要下載anaconda,在anaconda里面下載numpy以及pandas,具體操作:軟體安裝,然后打開控制頁面,輸入jupyter notebook,即可,復制所給鏈接就可以進入啦
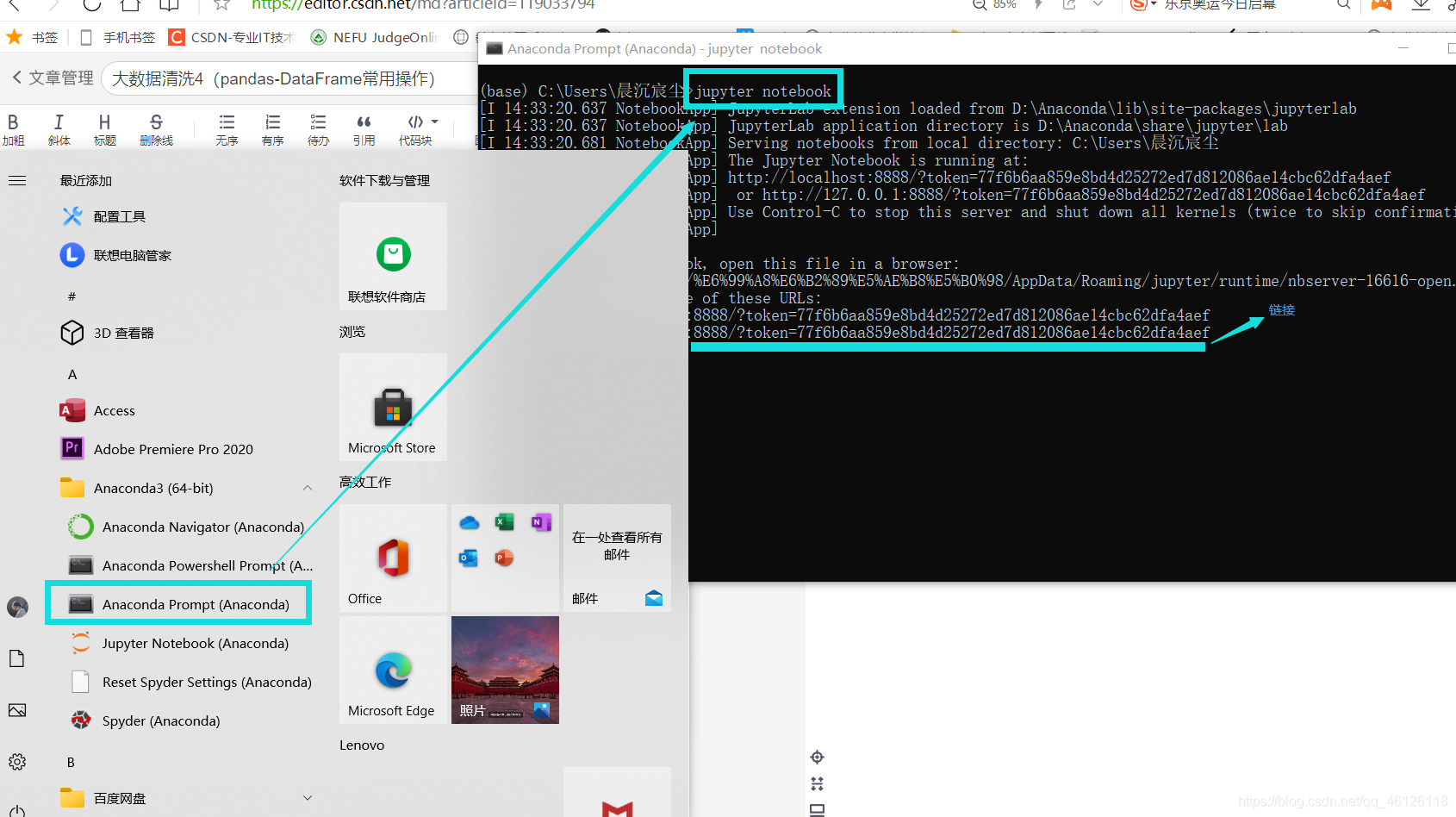
】進入正題
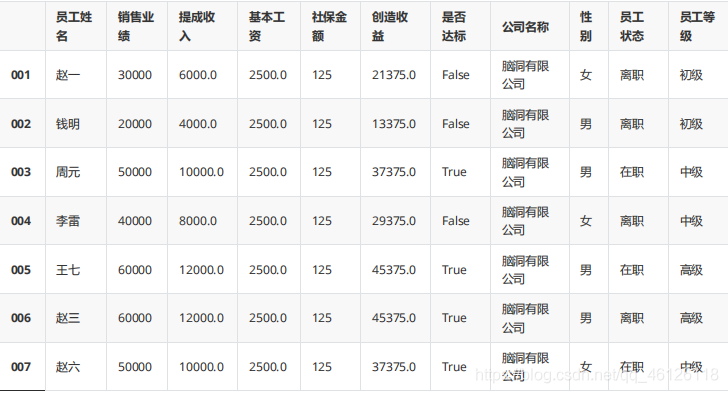
df = pd.read_csv("D:\data\sales.txt",sep='\t',index_col=0) df.index = ["001","002","003","004","005","006","007"] df
df.shape #查看資料框的形狀
df.head(2) #查看資料框的前幾行,默認前5行
df.tail(3) #查看資料框的結尾幾行,默認后5行
df.index #查看行索引
df.columns #查看列索引
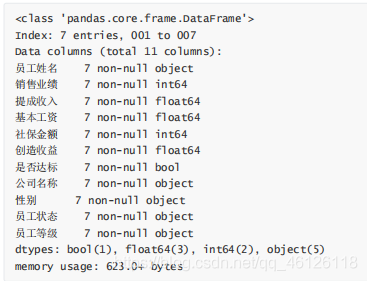
df.info()#查看資料框的詳細資訊
#進行簡單的描述統計
df.describe()
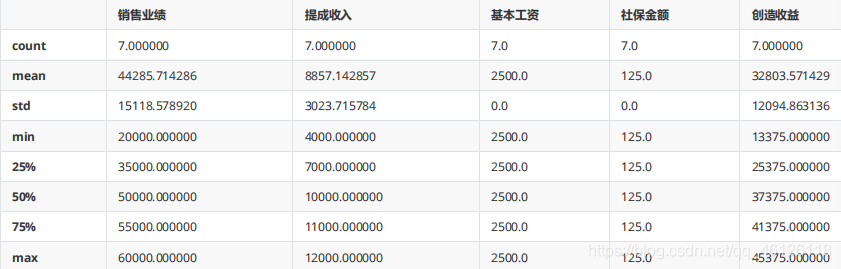
df.sort_index() #升序排序
df.sort_index(ascending=False) #降序排序
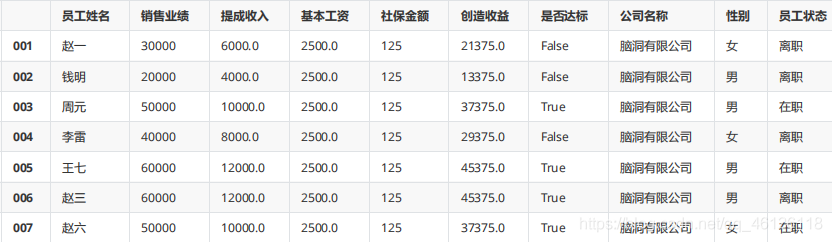
df.sort_values("銷售業績") #默認升序排序
df["工齡"] = [1,3,7,5,6,4,2]
df
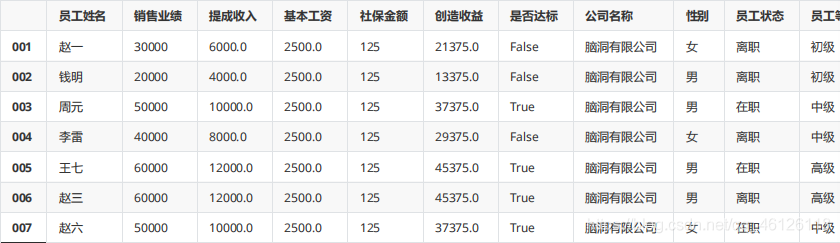
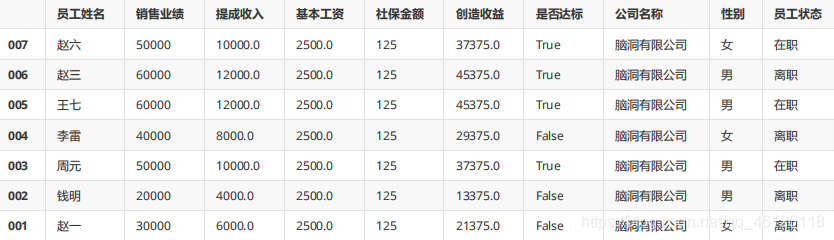
df.sort_values(["銷售業績","工齡"]) #默認升序排序
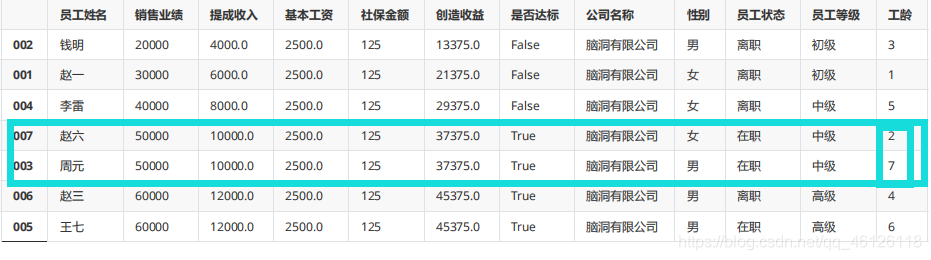
df.sort_values(["銷售業績","工齡"],ascending=False) #降序排序
df.sort_values(["銷售業績","工齡"],ascending=[False,True]) #降序排序
二、缺失值的處理
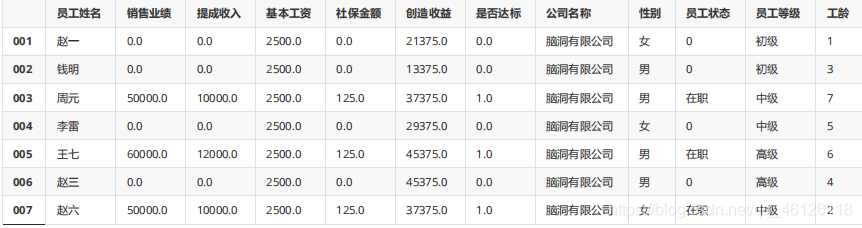
df.iloc[[0,1,3,5],[1,2,4,6,9]] = np.nan #認為制造缺失值 df
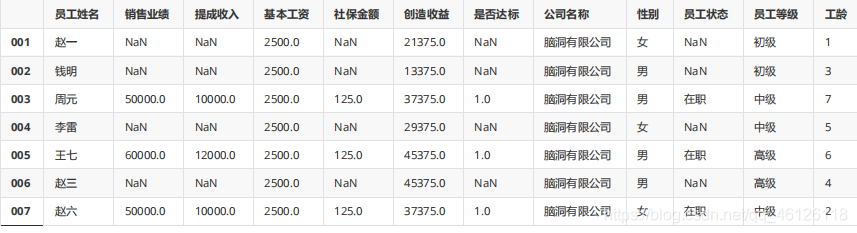
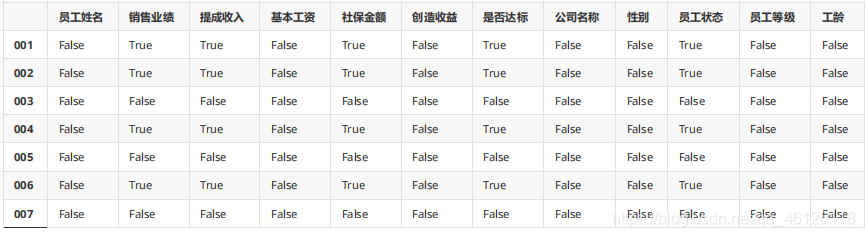
1、查看缺失值
df.isnull()
df.isnull().sum() #查看缺失值數量
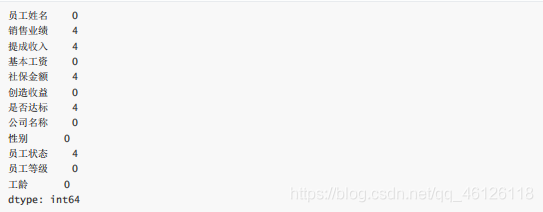
df.isnull().mean() #查看缺失值比例

df.shape
df.isnull().sum()/df.shape[0]

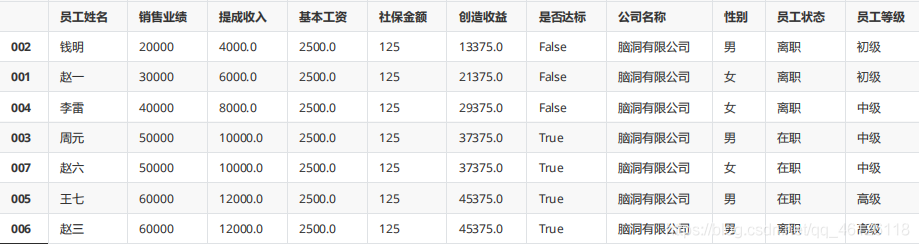
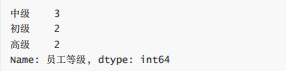
df.員工等級.value_counts()
2、填充缺失值
df.fillna(0)
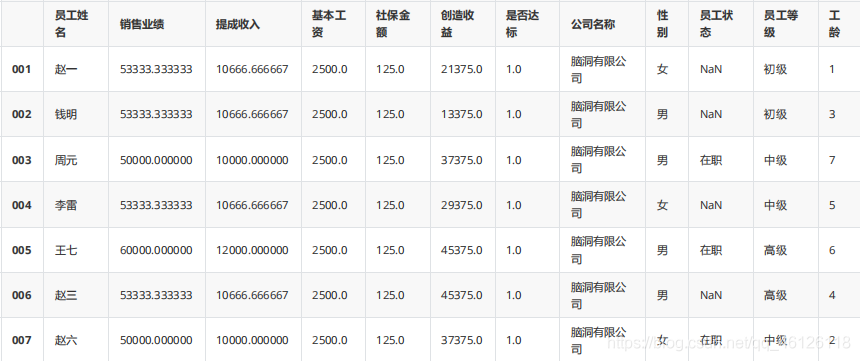
df.fillna(df.mean())
df.fillna(method="bfill",limit=1) #limit限制填充次數
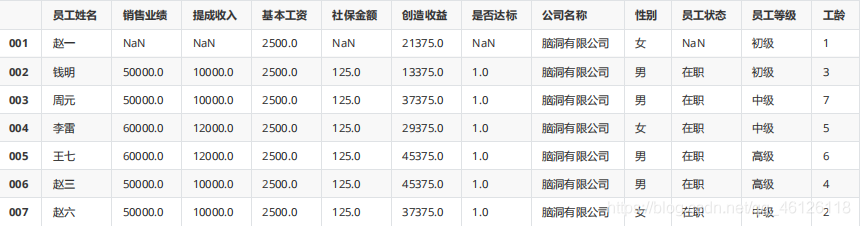
df.replace(np.nan,0)
df.replace(np.nan,df.median()) #用中位數進行填充
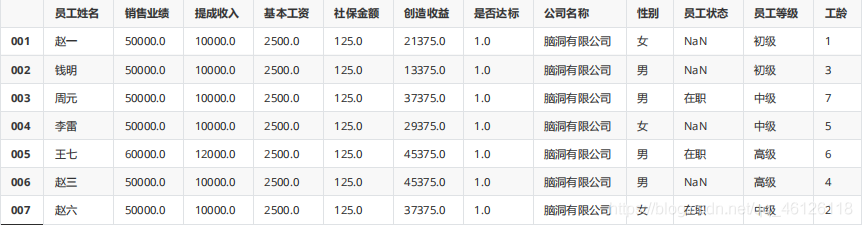
df.fillna(method="ffill")
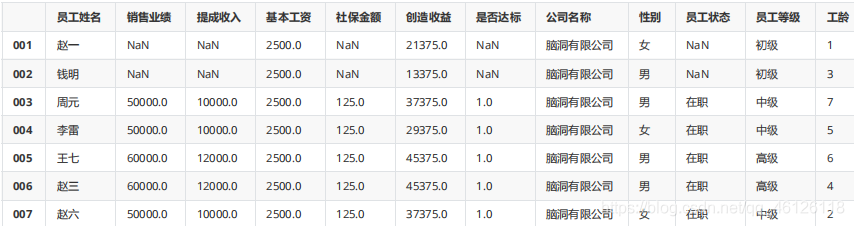
df.replace(method="ffill")
3、洗掉缺失值
df.dropna() #默認按照行進行洗掉
df.dropna(axis=1)#按照列進行洗掉
df.dropna(how='all')#按照列進行洗掉
三、資料的合并
1、pd.concat()函式
#來自兩個分公司的表
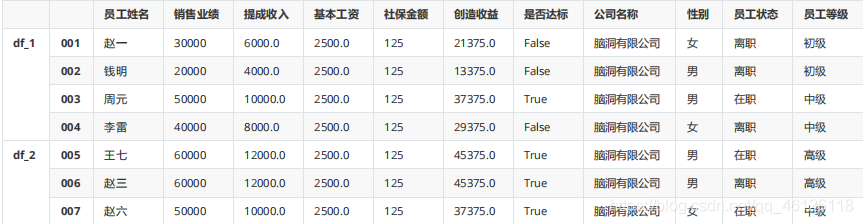
df_1 = df.iloc[:4]
df_2 = df.iloc[4:]
df_1 df_2
pd.concat([df_1,df_2])
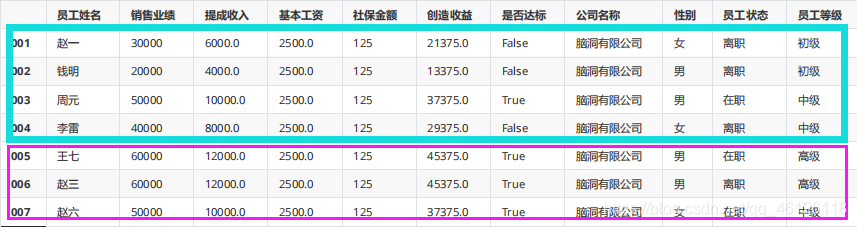
pd.concat([df_1,df_2],keys=["df_1","df_2"])
df_s = df.iloc[:,:7] #銷售部門統計表
df_h = df.iloc[:,[0,7,8,9,10]] #人力統計表
df_s
df_h
pd.concat([df_s,df_h],axis=1)
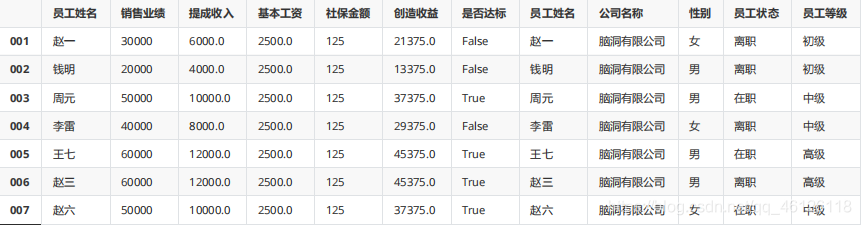
pd.concat([df_s,df_h],axis=1,keys=["df_s","df_h"],names=["來源表","索引"])
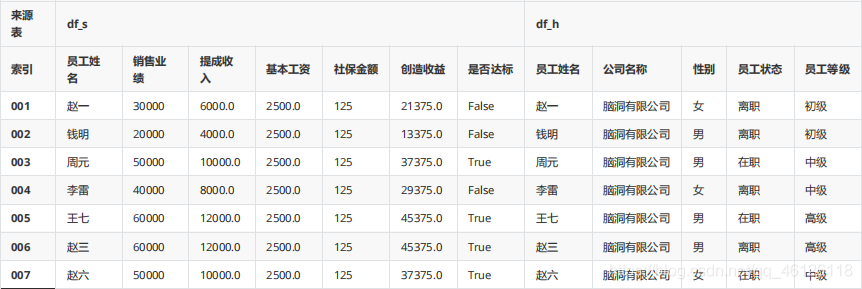
2、pd.merge()函式
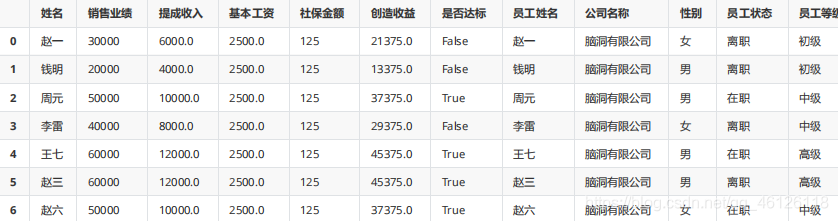
pd.merge(df_s,df_h,on="員工姓名")
df_ss = df_s.copy()
df_ss.columns=["姓名","銷售業績","提成收入","基本工資","社保金額","創造收益","是否達標"]
df_ss
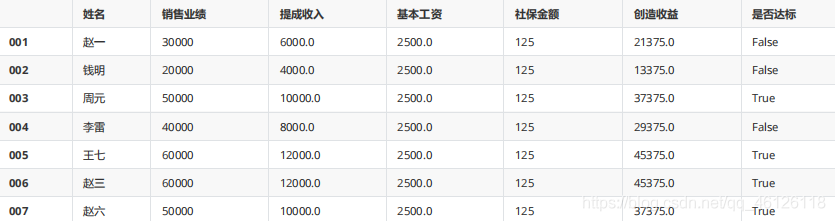
pd.merge(df_s,df_h)
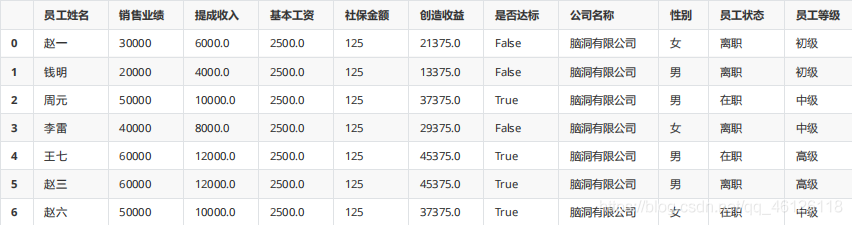
pd.merge(df_ss,df_h,left_on = "姓名",right_on="員工姓名")
四、分組運算
gp1 = df.groupby("性別")
len(gp1) #查看分組數 # 2
gp2 = df.groupby("員工等級")
len(gp2) #3
gp1.size()

gp1.mean()

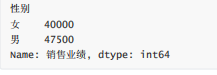
gp1["銷售業績"].mean()
gp3 = df.groupby(["性別","員工等級"])
len(gp3) #5
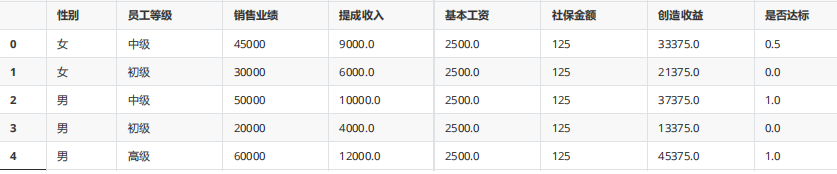
gp4 = df.groupby(["性別","員工等級"],as_index=False)
gp4.mean()
gpp = gp2["銷售業績"].agg([np.mean,np.std])
gpp
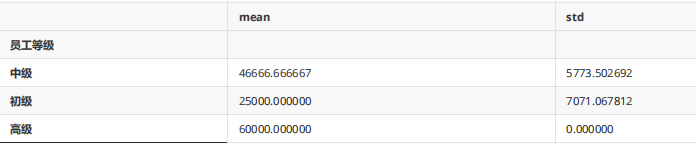
gpp.rename(columns={"mean":"平均銷售額","std":"標準差"})

gp2.agg({"銷售業績":np.mean,"提成收入":np.std})
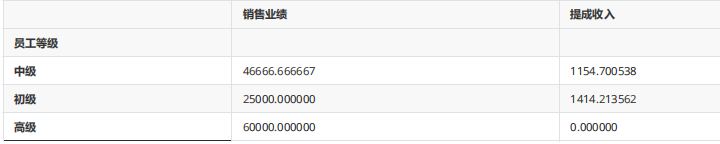
五、資料透視表
pd.pivot_table(df,values="創造收益",index="員工狀態")

pd.pivot_table(df,values="創造收益",index="員工狀態",columns="員工等級") #默認聚合方式為求均值
pd.pivot_table(df,values="創造收益",index="員工狀態",columns="員工等級",aggfunc=np.sum) #更改聚合方式為求和
pd.pivot_table(df,values=["創造收益","銷售業績"],index="員工狀態",columns="員工等級",aggfunc=np.sum) #更改聚合方式為求和
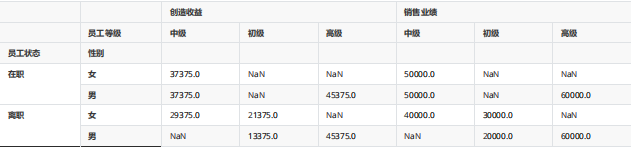
pd.pivot_table(df,values=["創造收益","銷售業績"],index=["員工狀態","性別"],columns="員工等級",aggfunc=np.sum) #更改聚合方式為求和
pd.pivot_table(df,values=["創造收益","銷售業績"],index=["員工狀態","性別"],columns="員工等級",aggfunc=[np.sum,np.mean]) #更改聚合方式為求和
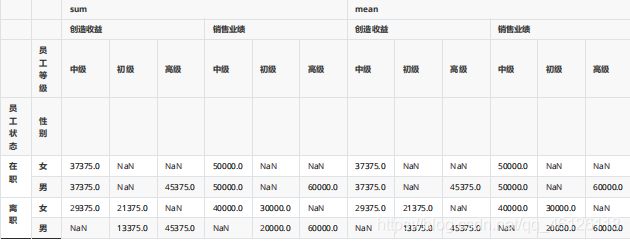
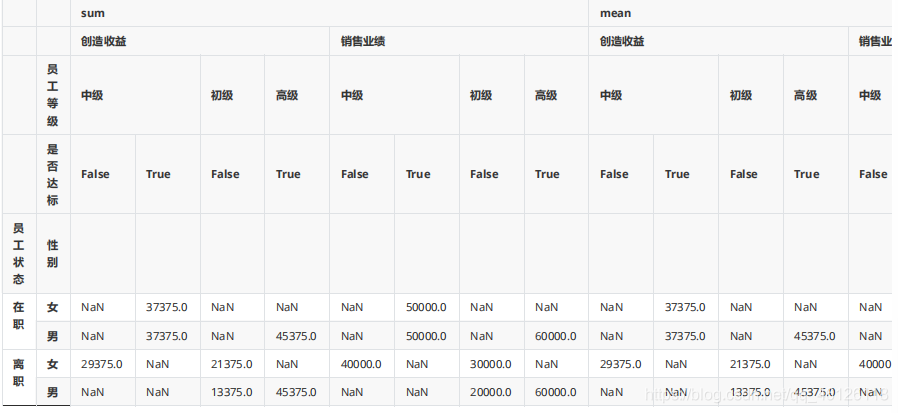
pd.pivot_table(df,values=["創造收益","銷售業績"],index=["員工狀態","性別"],columns=["員工等級","是否達標"],aggfunc=[np.sum,np.mean]) #更改聚合方式為求 和



轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290038.html
標籤:其他