任務目標:
- 完成灰分圖片的特征提取
- 將檔案夾所有灰分圖片進行批處理
- 輸出結果
關于灰分學習(灰分特征)
- 煤灰分,煤完全燃燒后余下的殘渣量,煤中灰分增加,增加了無效運輸,加劇了我國鐵路運輸的緊張,
- 從相關研究中了解到通過影像的特征分析可以提取出與煤灰分相關的特征有:均值、標準差、能量、熵、偏度、峰度等,
- 在本文選取從灰度直方圖中提取到均值、標準差、能量、熵、對比度來進行研究,
均值、標準差、熵、對比度與煤灰分的含量呈負相關
能量與煤灰分含量成正相關
灰度直方圖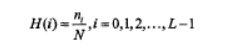
i 代表灰度級,L 代表灰度級的種類數,n代表影像中具有灰度級的像素點的數目,N 代表影像中的像素點總數,從公式中我們也可以看出,灰度直方圖H(i)代表的是影像中該灰度級的像素點的數目占影像全部像素點的比率,也就是影像中該灰度級i的像素點的頻率,其橫坐標表示影像的灰度級,縱坐標則表示此灰度級的頻率,
從灰度直方圖中我們提取出以下特征:
-
均值
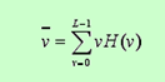
-
方差
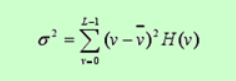
-
能量
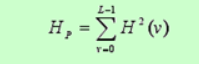
-
熵
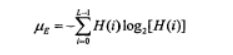
-
灰度對比度
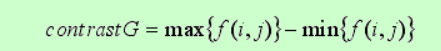
任務流程:
1.定義圖片處理函式
2.將圖片名稱
全部代碼展示:
import os
import cv2
import numpy as np
def gray_features(img):
hist = cv2.calcHist([img], [0], None, [256], [0, 255]) # 得到全域直方圖統計資料
h, w = img.shape
hist = hist / (h * w) # 將直方圖歸一化為0-1,概率的形式
grayFeature = []
# 灰度平均值
mean_gray = 0
for i in range(len(hist)):
mean_gray += i * hist[i]
grayFeature.append(mean_gray[0])
# 灰度方差
var_gray = 0
for i in range(len(hist)):
var_gray += hist[i] * ((i - mean_gray) ** 2)
grayFeature.append(var_gray[0])
# 能量sum(hist[i])**2
##歸一化
max_ = np.max(hist)
min_ = np.min(hist)
histOne = (hist - min_) / (max_ - min_)
##求解能量
energy = 0
for i in range(len(histOne)):
energy += histOne[i] ** 2
grayFeature.append(energy[0])
# 熵
he = 0
for i in range(len(hist)):
if hist[i] != 0: # 當等于0時,log無法進行計算,因此只需要計算非0部分的熵即可
he += hist[i] * (np.log(hist[i]) / (np.log(2)))
he = -he
grayFeature.append(he[0]) # 因為回傳的是含有一個元素的陣列,所以通過取值操作將其取出來再加入到串列中去
# 灰度對比度
con = np.max(img) - np.min(img)
grayFeature.append(con)
return grayFeature
# 打開檔案
path = "F:\coal_ash"
dirs = os.listdir(path)
# 輸出所有檔案和檔案夾
for file in dirs:
print(file)
# 單張待處理圖片路徑
f = open('F:\data.txt', 'a') # 設定檔案物件
f.write(("灰度均值,灰度方差,能量值,熵,灰度對比度 "))
f.write('\n')
for name in dirs:
image_path = os.path.join(path, name)
img = cv2.imread(image_path,0)
grayFeas = gray_features(img)
print('*' * 50)
print(grayFeas)
f = open('F:\data.txt', 'a')
f.write(str(grayFeas))
f.write('\n')
f.close()
print("done")
灰分檔案夾
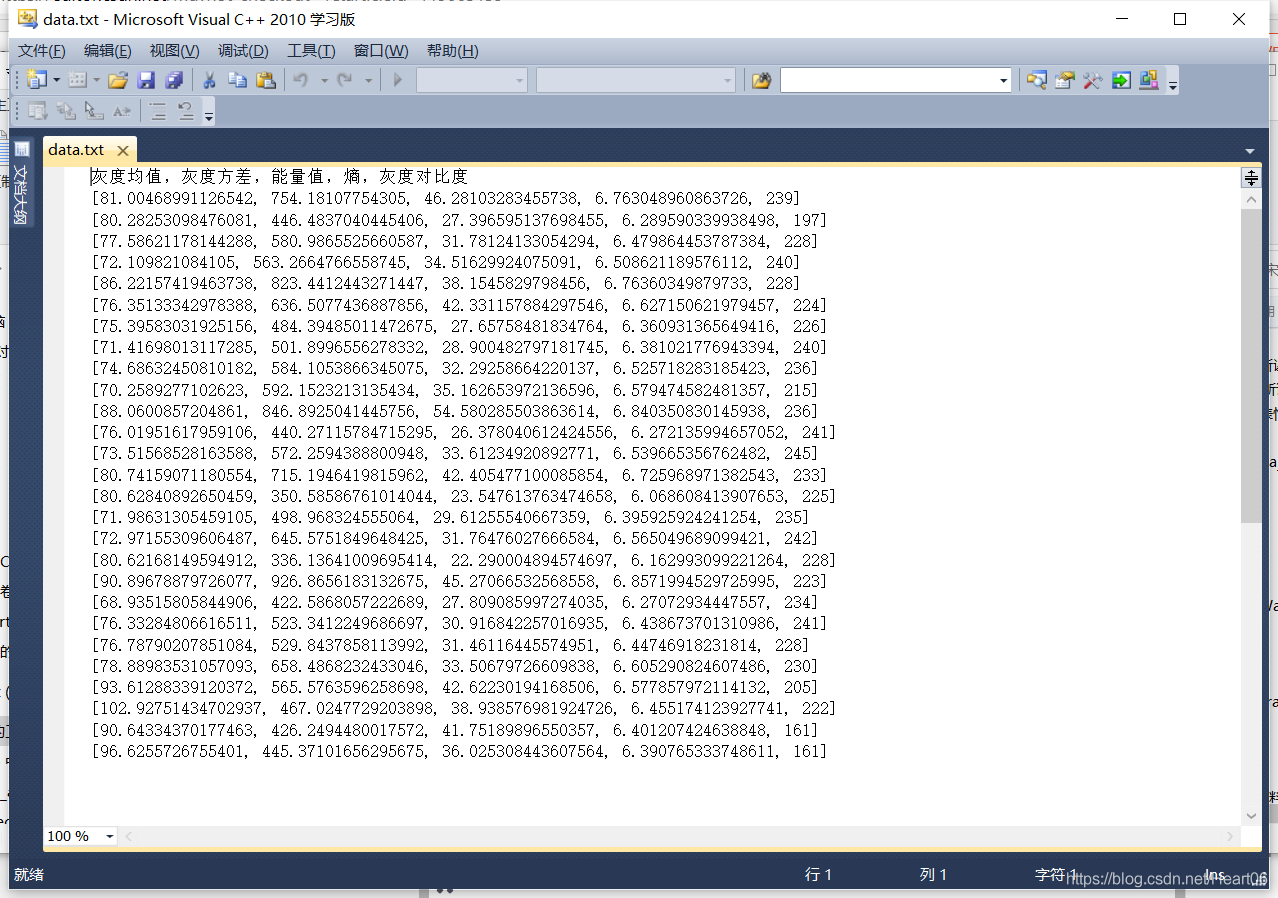
最終輸出效果圖
學習的一些python知識
1.關于cv2的imread函式
import cv2
image_path = “絕對路徑”
image = cv2.imread(image_path)
cv2.imshow(“cv2_image”, image)
cv2.waitKey()
2.關于路徑拼接函式os.path.join
這里是參考
os.path.join()函式:連接兩個或更多的路徑名組件
1.如果各組件名首字母不包含’/’,則函式會自動加上
2.如果有一個組件是一個絕對路徑,則在它之前的所有組件均會被舍棄
3.如果最后一個組件為空,則生成的路徑以一個’/’分隔符結尾
Demo1 import os
Path1 = ‘home’ Path2 = ‘develop’ Path3 = ‘code’
Path10 = Path1 + Path2 + Path3 Path20 =
os.path.join(Path1,Path2,Path3) print ('Path10 = ',Path10) print
('Path20 = ',Path20)輸出
Path10 = homedevelopcode Path20 = home\develop\code
Demo2
import os
Path1 = ‘/home’ Path2 = ‘develop’ Path3 = ‘code’
Path10 = Path1 + Path2 + Path3 Path20 =
os.path.join(Path1,Path2,Path3) print ('Path10 = ',Path10) print
('Path20 = ',Path20) 輸出Path10 = /homedevelopcode Path20 = /home\develop\code
Demo3 import os
Path1 = ‘home’ Path2 = ‘/develop’ Path3 = ‘code’
Path10 = Path1 + Path2 + Path3 Path20 =
os.path.join(Path1,Path2,Path3) print ('Path10 = ',Path10) print
('Path20 = ',Path20)輸出
Path10 = home/developcode Path20 = /develop\code
Demo4 import os
Path1 = ‘home’ Path2 = ‘develop’ Path3 = ‘/code’
Path10 = Path1 + Path2 + Path3 Path20 =
os.path.join(Path1,Path2,Path3) print ('Path10 = ',Path10) print
('Path20 = ',Path20 )輸出
Path10 = homedevelop/code Path20 = /code
轉https://www.cnblogs.com/an-ning0920/p/10037790.html
3.將輸出結果儲存到txt檔案
f = open(‘workfile’, ‘w’)
第一個引數filename是包含檔案地址的str
第二個引數mode用來指定檔案被使用的方式,The mode argument is optional;如果不指定則默認為mode= ‘r’ 即只讀模式
其中 mode=‘r’ 意味著 檔案只是用來讀入python ,
mode=‘w’ for only writing (如果寫入之后的檔案和之前的檔案同名,則之前的那個檔案會被擦除、覆寫an existing file with the same name will be erased)
mode=‘a’ opens the file for appending; any data written to the file is automatically added to the end任何append進file的資料都被自動加到檔案末尾位置
mode=‘r+’ opens the file for both reading and writing讀寫均可.
with open(’./data.txt’, ‘a’) as f: # 設定檔案物件
print(‘11111111111111’,file = f)
參考文獻:
[1]Qiu Zhaoyu,Dou Dongyang,Zhou Deyang,Yang Jianguo. On-line prediction of clean coal ash content based on image analysis[J]. Measurement,2021,173:
[2]王靖千. 基于影像處理的浮選尾礦灰分檢測方法研究[D].太原理工大學,2019.
[3]高博. 基于影像灰度特征的浮選尾礦灰分軟測量研究[D].中國礦業大學,2016.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290376.html
標籤:其他