Python實時語音識別轉字幕
實作原理
用speech_recognition庫獲得實時電腦音頻輸入,用requests和json庫將生成的語音檔案上傳至百度的云語音識別服務器進行識別,回傳結果用wx庫顯示為字幕,同時寫為txt檔案作為記錄,用threading庫呼叫兩個thread,一個識別和處理音頻,另一個從txt檔案讀取生成字幕,
該專案為個人參賽作品,原名TRAS(Toolkit for Recognition and Automatic Summarization),語音識別與自動總結工具,具體使用說明請看我的Github,該專案可用來為網課或語音生成字幕,也可幫助聾啞人“聽”到電腦音頻,代碼寫的不規范,請各位見諒!
代碼
以下代碼在我的Github上也有,這里為學習與分享的目的加了注釋,
import requests
import json
import base64
import os
import logging
import speech_recognition as sr
import wx
import threading
#呼叫庫
def get_token(): # 呼叫百度云語音識別API,具體看百度的技術檔案
logging.info('Retrieving token...') #和print差不多
baidu_server = "https://openapi.baidu.com/oauth/2.0/token?"
grant_type = "client_credentials"
client_id = "EUON57v2pcpk5CDQnet6AN6s" #你的ID
client_secret = "oHb0INPt5MGSC4LfoQ9hd7W2oSR6GLmV" #密鑰
url = f"{baidu_server}grant_type={grant_type}&client_id={client_id}&client_secret={client_secret}"
res = requests.post(url)
token = json.loads(res.text)["access_token"] #用json處理回傳資料
return token
def audio_baidu(filename): # 上傳音頻至百度云語音識別,回傳結果存盤為文本
if not os.path.exists('record'):
os.makedirs('record') #創建目錄
filename = 'record/' + filename
logging.info('Analysing audio file...')
with open(filename, "rb") as f:
speech = base64.b64encode(f.read()).decode('utf-8')
size = os.path.getsize(filename)
token = get_token()
headers = {'Content-Type': 'application/json'}
url = "https://vop.baidu.com/server_api"
data = {
"format": "wav",
"rate": "16000",
"dev_pid": 1737, #識別型別,1737=english, 17372=enhanced english, 15372=enhanced chinese, 具體參考百度技術檔案
"speech": speech,
"cuid": "3.141592653589793238462643383279502884197169399375105820", #獨特的符號串
"len": size,
"channel": 1,
"token": token,
}
req = requests.post(url, json.dumps(data), headers)
result = json.loads(req.text)
if result["err_msg"] == "success.":
message = ''.join(result['result'])
print('RETURNED: ' + message)
return result['result']
else:
print("RETURNED: Recognition failure")
return -1
def main(): # 執行緒2: 語音識別
logging.basicConfig(level=logging.INFO)
wav_num = 0
while True:
r = sr.Recognizer() #創建識別類
mic = sr.Microphone() #創建麥克風物件
logging.info('Recording...')
with mic as source:
r.adjust_for_ambient_noise(source) #減少環境噪音
audio = r.listen(source, timeout=1000) #錄音,1000ms超時
with open('record/' + f"00{wav_num}.wav", "wb") as f:
f.write(audio.get_wav_data(convert_rate=16000)) #寫檔案
message = ''.join(audio_baidu(f"00{wav_num}.wav"))
history = open('record/' + f"history.txt", "a")
history.write(message + '\n')
history.close()
wav_num += 1
def update_content(win, height=200, width=800): #用來更新字幕視窗內容
f = open('record/' + f"history.txt", "r") #讀取檔案
try:
last_line = f.readlines()[-1] #讀檔案最后一行
except IndexError:
last_line = ''
if last_line.strip('\n') in ['key point']: #有特殊詞匯的話字幕加粗顯示
logging.info('Emphasized')
ft = wx.Font(80, wx.MODERN, wx.NORMAL, wx.BOLD, False, '') #設定字體
else:
ft = wx.Font(50, wx.MODERN, wx.NORMAL, wx.NORMAL, False, '')
richText = wx.TextCtrl(win, value='', pos=(0, 0), size=(width, height))
richText.SetInsertionPoint(0) #從頭插入文字,把原來的內容頂掉
richText.SetFont(ft)
richText.SetValue(last_line)
f.close()
return last_line
def show_win(x=320, y=550, height=200, width=800): #創建字幕視窗
win = wx.Frame(None, title="TRAS v1.0.0", pos=(x, y), size=(width, height), style=wx.STAY_ON_TOP) #創建Frame物件
win.SetTransparent(1000) #透明度
win.Show()
return win
#主程式
if __name__ == "__main__":
history = open('record/' + f"history.txt", "w+")
history.close()
thread = threading.Thread(target=main) #創建另一個thread跑語音識別
thread.start()
global app #這里有報錯,要設定全域變數
app = wx.App() #創建物件
while True:
win = show_win() #創建字幕視窗
v = update_content(win) #更新視窗內容
wx.CallLater(2000, win.Destroy) #兩秒沒操作的話隱藏視窗
app.MainLoop()
運行結果
(整個專案的運行方法請看Github)
程式開始運行后,對著電腦麥克風說話,就能順利顯示實時字幕啦!
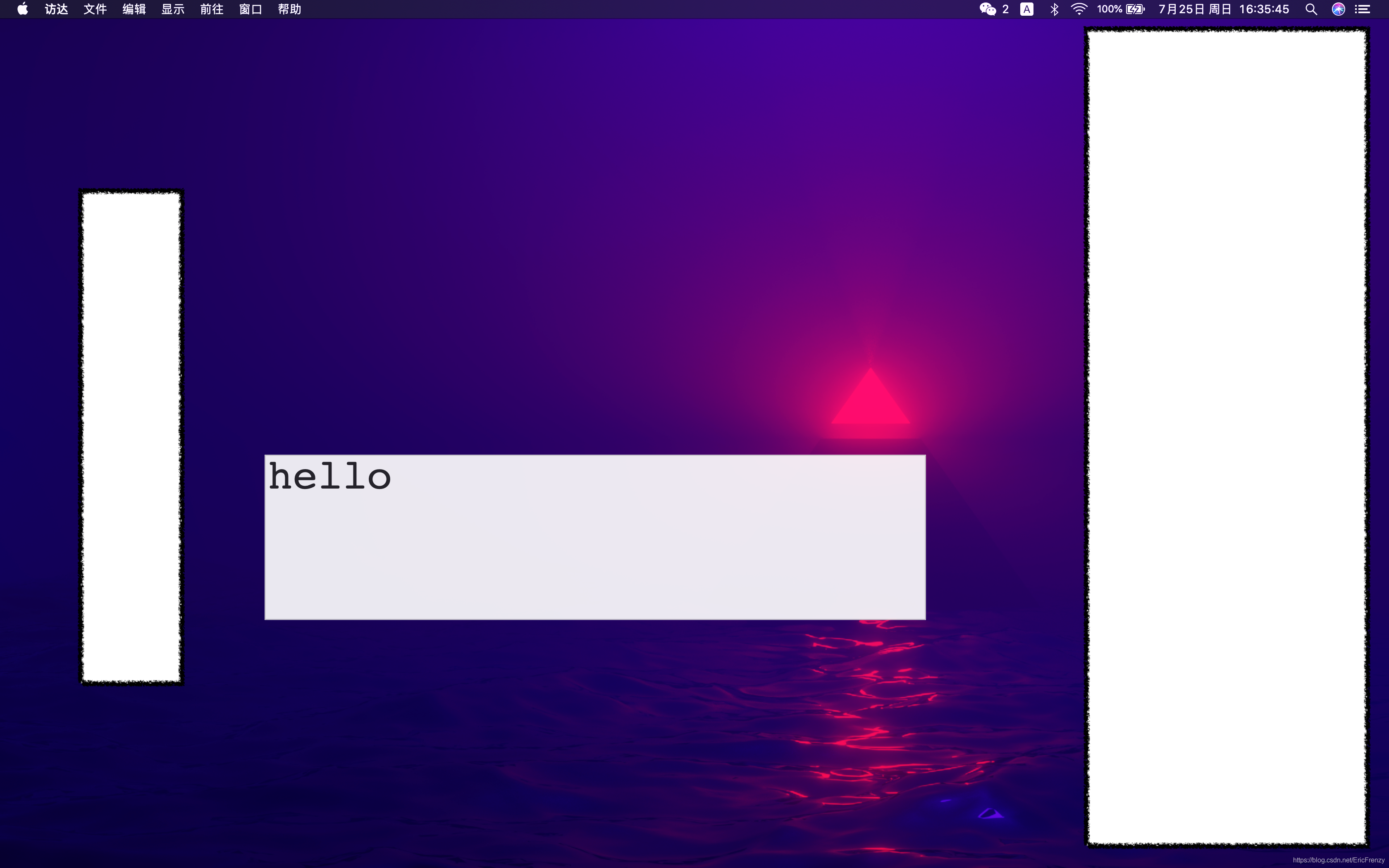
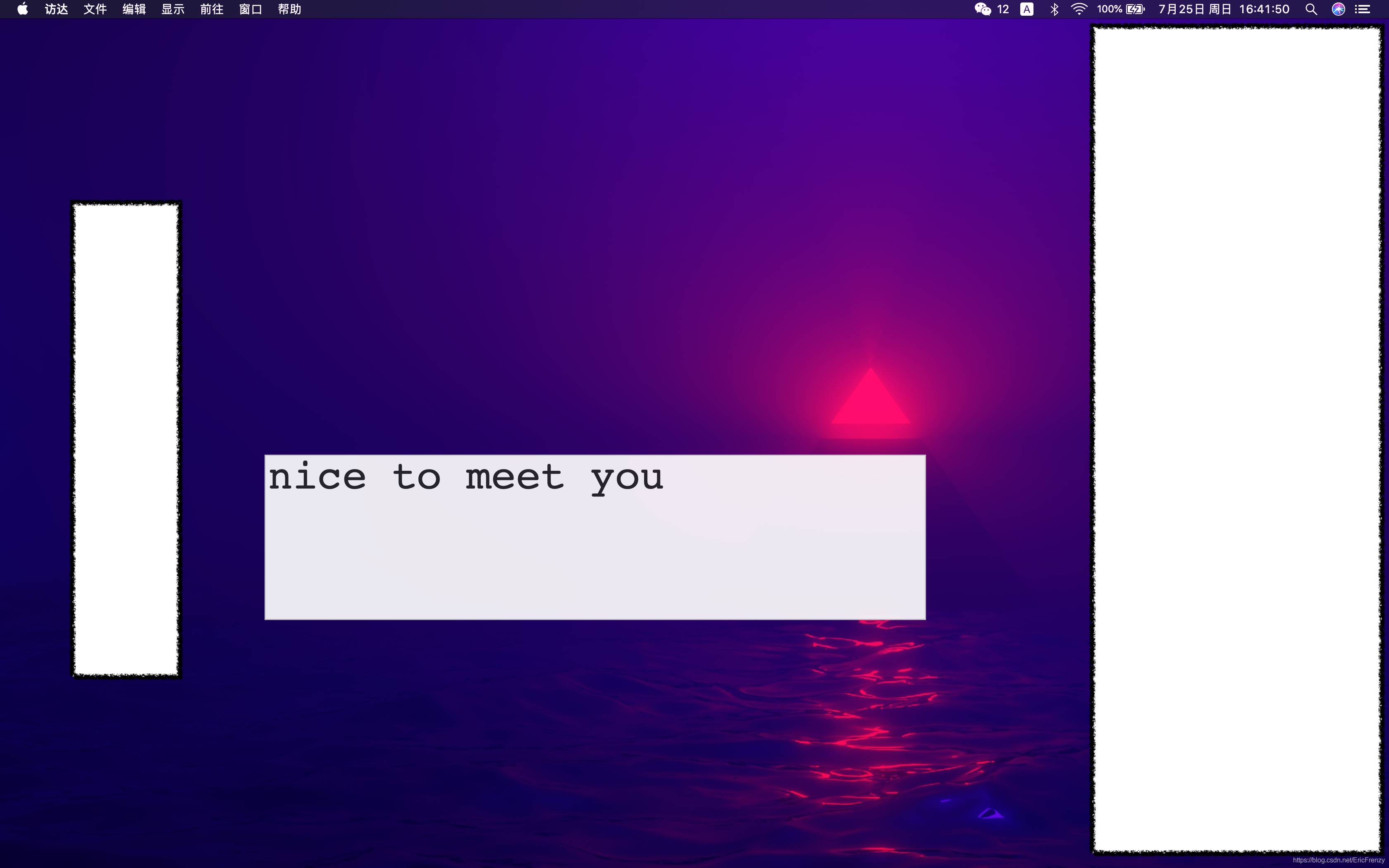
功能拓展
該程式目前支持MacOS,WinOS未測驗,選用ws庫也是因為它支持Mac更好,其它的輔助功能請見github,這里的版本是英文識別,目前的id與密鑰呼叫的是博主的免費額度,到達上限后可能會報錯,有興趣的同學可以了解百度云的其它功能,自行注冊賬號獲得呼叫額度,有任何問題歡迎私信討論或評論區留言!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290381.html
標籤:其他