目錄
- 一、attention定義
- 二、Deep learning于CV的考量
- 三、注意力機制中的各種"域"
- 1. “軟注意力”與“硬注意力”
- 2. 空間域(Spatial Domain)
- 3. 通道域(Channel Domain)
- 4. 混合域
- 5.時間域注意力
- 四、參考文獻
一、attention定義
注意力機制的基本原理很簡單:它認為,網路中每層不同的(可以是不同通道,也可以是不同位置,都可以)特征的重要性不同,后面的層應該更注重其中重要的資訊,抑制不重要的資訊,
attention機制可以它認為是一種資源分配的機制,可以理解為對于原本平均分配的資源根據attention物件的重要程度重新分配資源,重要的單位就多分一點,不重要或者不好的單位就少分一點,在深度神經網路的結構設計中,attention所要分配的資源基本上就是權重了,
比如,性別分類中,應該更注意人的頭發長短、胸部隆起情況這些和性別關系大的特征的抽取和判斷,而不是去注意人體和性別關系不大的,像腰部粗細、身高頭部比例,這些特征,
視覺注意力分為幾種,核心思想是基于原有的資料找到其之間的關聯性,然后突出其某些重要特征,有通道注意力,像素注意力,多階注意力等,也有把NLP中的自注意力引入,
二、Deep learning于CV的考量
在工程師和研究者設計新的網路的時候,為了提升網路的容量和性能,通常會從三個方面著手:
-
增加網路深度:例如,從開始的LeNet-5,到VGG-16,到ResNet-101,等等,網路的設計越來越深,性能也越來越好,網路深了,簡單地講,下一層的輸出是上一層的線性組合加激活,可以復合出更多更靈活的特征(其實就是更復雜的復合函式);
-
增加網路寬度:這里的網路寬度即特征圖的通道數,這里的典型例子可以從LeNet-5,到VGG-16,Wider ResNet,增加網路寬度,特征圖通道數多起來了,更多的卷積核可以得到更多更豐富的特征,網路的表達能力自然就強;
-
豐富網路感受野:這里可以參考Inception中的不同解析度的卷積核組成的小網路,還有FPN,SSD里面的各種變種,都有增加感受野的多樣性來提升性能的路子,感受野不同,對不同大小的目標的特征提取和表達能力就不同,一般是特征圖上感受野大的像素更能代表大的目標上面提取的資訊,感受野小的像素,只能看到大目標的一部分;反過來想,感受野大的像素,看到的視野太大,對于小目標就摻雜了太多的冗余資訊和噪音,所以,使用不同解析度的感受野,豐富網路的感受野來提升網路,讓大感受野處理大目標,小感受野處理小目標,各司其職,來提升網路性能也就成了很多網路設計的自然手段了,
三、注意力機制中的各種"域"
1. “軟注意力”與“硬注意力”
近幾年來,深度學習與視覺注意力機制結合的研究作業,大多數是集中于使用**掩碼(mask)**來形成注意力機制,掩碼的原理在于通過另一層新的權重,將圖片資料中關鍵的特征標識出來,通過學習訓練,讓深度神經網路學到每一張新圖片中需要關注的區域,也就形成了注意力,
這種思想,進而演化成兩種不同型別的注意力,一種是軟注意力(soft attention),另一種則是強注意力(hard attention),
軟注意力的關鍵點在于,這種注意力更關注區域或者通道,而且軟注意力是確定性的注意力,學習完成后直接可以通過網路生成,最關鍵的地方是軟注意力是可微的,這是一個非常重要的地方,可以微分的注意力就可以通過神經網路算出梯度并且前向傳播和后向反饋來學習得到注意力的權重,
強注意力與軟注意力不同點在于,首先強注意力是更加關注點,也就是影像中的每個點都有可能延伸出注意力,同時強注意力是一個隨機的預測程序,更強調動態變化,當然,最關鍵是強注意力是一個不可微的注意力,訓練程序往往是通過增強學習(reinforcement learning)來完成的,
為了更清楚地介紹計算機視覺中的注意力機制,這篇文章將從注意力域(attention domain)的角度來分析幾種注意力的實作方法,其中主要是三種注意力域,空間域(spatial domain),通道域(channel domain),混合域(mixed domain),
還有另一種比較特殊的強注意力實作的注意力域,時間域(time domain),但是因為強注意力是使用reinforcement learning來實作的,訓練起來有所不同,所以之后再詳細分析,
2. 空間域(Spatial Domain)
設計思路:
Spatial Transformer Networks(STN)模型是15年NIPS上的文章,這篇文章通過注意力機制,將原始圖片中的空間資訊變換到另一個空間中并保留了關鍵資訊,
這篇文章的思想非常巧妙,因為卷積神經網路中的池化層(pooling layer)直接用一些max pooling 或者average pooling 的方法,將圖片資訊壓縮,減少運算量提升準確率,
但是這篇文章認為之前pooling的方法太過于暴力,直接將資訊合并會導致關鍵資訊無法識別出來,所以提出了一個叫空間轉換器(spatial transformer)的模塊,將圖片中的的空間域資訊做對應的空間變換,從而能將關鍵的資訊提取出來,
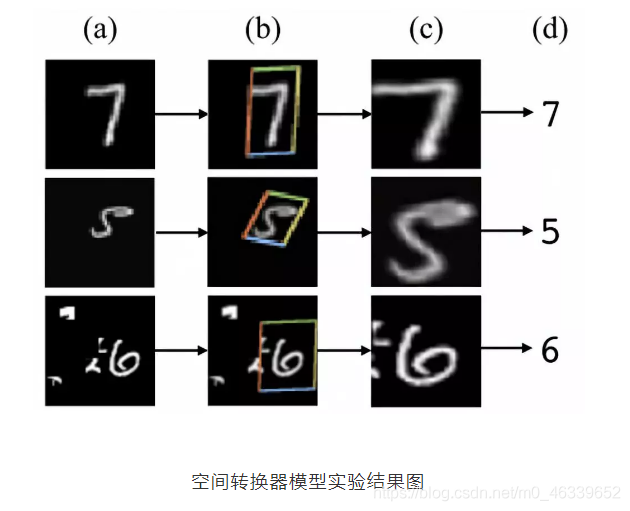
比如這個直觀的實驗圖:
(a)列是原始的圖片資訊,其中第一個手寫數字7沒有做任何變換,第二個手寫數字5,做了一定的旋轉變化,而第三個手寫數字6,加上了一些噪聲信號;
(b)列中的彩色邊框是學習到的spatial transformer的框盒(bounding box),每一個框盒其實就是對應圖片學習出來的一個spatial transformer;
?列中是通過spatial transformer轉換之后的特征圖,可以看出7的關鍵區域被選擇出來,5被旋轉成為了正向的圖片,6的噪聲資訊沒有被識別進入,
最終可以通過這些轉換后的特征圖來預測出(d)列中手寫數字的數值,
spatial transformer其實就是注意力機制的實作,因為訓練出的spatial transformer能夠找出圖片資訊中需要被關注的區域,同時這個transformer又能夠具有旋轉、縮放變換的功能,這樣圖片區域的重要資訊能夠通過變換而被框盒提取出來,
3. 通道域(Channel Domain)
設計思路:
通道域注意力機制原理很簡單,我們可以從基本的信號變換的角度去理解,信號系統分析里面,任何一個信號其實都可以寫成正弦波的線性組合,經過時頻變換之后,時域上連續的正弦波信號就可以用一個頻率信號數值代替了,
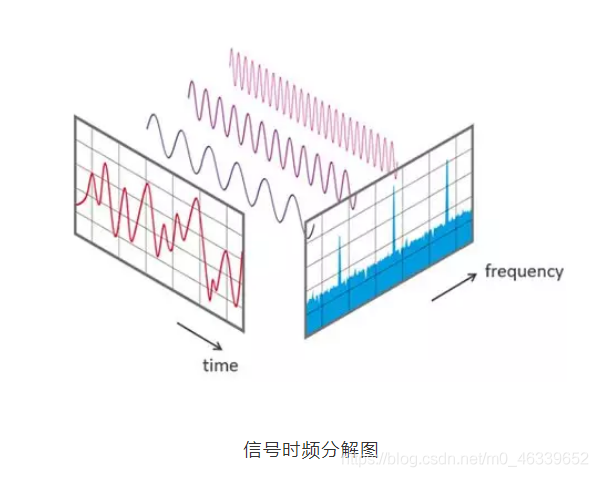
信號時頻分解圖
在卷積神經網路中,每一張圖片初始會由(R,G,B)三通道表示出來,之后經過不同的卷積核之后,每一個通道又會生成新的信號,比如圖片特征的每個通道使用64核卷積,就會產生64個新通道的矩陣(H,W,64),H,W分別表示圖片特征的高度和寬度,
每個通道的特征其實就表示該圖片在不同卷積核上的分量,類似于時頻變換,而這里面用卷積核的卷積類似于信號做了傅里葉變換,從而能夠將這個特征一個通道的資訊給分解成64個卷積核上的信號分量,

既然每個信號都可以被分解成核函式上的分量,產生的新的64個通道對于關鍵資訊的貢獻肯定有多有少,如果我們給每個通道上的信號都增加一個權重,來代表該通道與關鍵資訊的相關度的話,這個權重越大,則表示相關度越高,也就是我們越需要去注意的通道了,
4. 混合域
了解前兩種注意力域的設計思路后,簡單對比一下,首先,空間域的注意力是忽略了通道域中的資訊,將每個通道中的圖片特征同等處理,這種做法會將空間域變換方法局限在原始圖片特征提取階段,應用在神經網路層其他層的可解釋性不強,
而通道域的注意力是對一個通道內的資訊直接全域平均池化,而忽略每一個通道內的區域資訊,這種做法其實也是比較暴力的行為,所以結合兩種思路,就可以設計出混合域的注意力機制模型[8],
設計思路:
這篇文章中提出的注意力機制是與深度殘差網路(Deep Residual Network)相關的方法,基本思路是能夠將注意力機制應用到ResNet中,并且使網路能夠訓練的比較深,
文章中注意力的機制是軟注意力基本的加掩碼(mask)機制,但是不同的是,這種注意力機制的mask借鑒了殘差網路的想法,不只根據當前網路層的資訊加上mask,還把上一層的資訊傳遞下來,這樣就防止mask之后的資訊量過少引起的網路層數不能堆疊很深的問題,
正如之前說的,中提出的注意力mask,不僅僅只是對空間域或者通道域注意,這種mask可以看作是每一個特征元素(element)的權重,通過給每個特征元素都找到其對應的注意力權重,就可以同時形成了空間域和通道域的注意力機制,
很多人看到這里就會有疑問,這種做法應該是從空間域或者通道域非常自然的一個過渡,怎么做單一域注意力的人都沒有想到呢?原因有:
如果你給每一個特征元素都賦予一個mask權重的話,mask之后的資訊就會非常少,可能直接就破壞了網路深層的特征資訊;
另外,如果你可以加上注意力機制之后,殘差單元(Residual Unit)的恒等映射(identical mapping)特性會被破壞,從而很難訓練,
所以該文章的注意力機制的創新點在于提出了殘差注意力學習(residual attention learning),不僅只把mask之后的特征張量作為下一層的輸入,同時也將mask之前的特征張量作為下一層的輸入,這時候可以得到的特征更為豐富,從而能夠更好的注意關鍵特征,
5.時間域注意力
這個概念其實比較大,因為計算機視覺只是單一識別圖片的話,并沒有時間域這個概念,但是這篇文章中,提出了一種基于遞回神經網路(Recurrent Neural Network,RNN)的注意力機制識別模型,
RNN模型比較適合的場景是資料具有時序特征,比如使用RNN產生注意力機制做的比較好的是在自然語言處理的問題上,因為自然語言處理的是文本分析,而文本產生的背后其實是有一個時序上的關聯性,比如一個詞之后還會跟著另外一個詞,這就是一個時序上的依賴關聯性,
而圖片資料本身,并不具有天然的時序特征,一張圖片往往是一個時間點下的采樣,但是在視頻資料中,RNN就是一個比較好的資料模型,從而能夠使用RNN來產生識別注意力,
特意將RNN的模型稱之為時間域的注意力,是因為這種模型在前面介紹的空間域,通道域,以及混合域之上,又新增加了一個時間的維度,這個維度的產生,其實是基于采樣點的時序特征,
Recurrent Attention Model 中將注意力機制看成對一張圖片上的一個區域點的采樣,這個采樣點就是需要注意的點,而這個模型中的注意力因為不再是一個可以微分的注意力資訊,因此這也是一個強注意力(hard attention)模型,這個模型的訓練是需要使用增強學習(reinforcementlearning)來訓練的,訓練的時間更長,
這個模型更需要了解的并不是RNN注意力模型,因為這個模型其實在自然語言處理中介紹的更詳細,更需要了解的是這個模型的如何將圖片資訊轉換成時序上的采樣信號的:
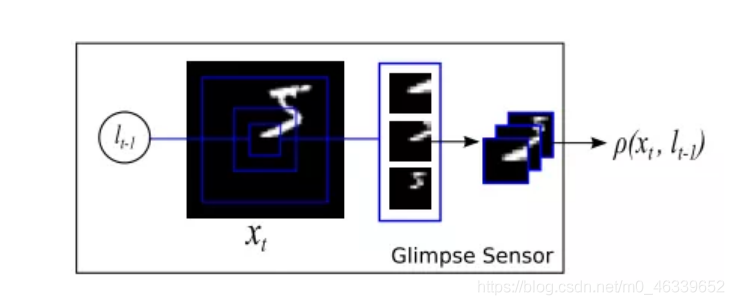
這個是模型中的關鍵點,叫Glimpse Sensor,有大佬翻譯為掃視器,這個sensor的關鍵點在于先確定好圖片中需要關注的點(像素),這時候這個sensor開始采集三種資訊,資訊量是相同的,一個是非常細節(最內層框)的資訊,一個是中等的區域資訊,一個是粗略的略縮圖資訊,
這三個采樣的資訊是在 l t ? 1 l_{t-1} lt?1?位置中產生的圖片資訊,而下一個時刻,隨著t的增加,采樣的位置又開始變化,至于l隨著t該怎么變化,這就是需要使用增強學習來訓練的東西了,
有關RNN做attention的,還是應該去了解自然語言處理,如機器翻譯中的做法,這里就不再繼續深入介紹,想深入了解的,推薦閱讀Attention模型方法綜述,
四、參考文獻
CV中的注意力機制https://zhuanlan.zhihu.com/p/83221558
計算機視覺中的注意力機制(Visual Attention)https://mp.weixin.qq.com/s/KKlmYOduXWqR74W03Kl-9A
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290762.html
標籤:其他