文章目錄
- 一、前言
- 二、什么是生成對抗網路?
- 1. 設定GPU
- 2. 加載和準備資料集
- 三、創建模型
- 1. 生成器
- 2. 判別器
- 四、定義損失函式和優化器
- 1. 判別器損失
- 2. 生成器損失
- 五、保存檢查點
- 六、定義訓練回圈
- 七、訓練模型
- 1. 恢復模型引數
- 2. 訓練模型
- 3. 創建 GIF
- 八、同系列作品
- 九、資料+模型
一、前言
🚀 我的環境:
- 語言環境:Python3.6.5
- 編譯器:jupyter notebook
- 深度學習環境:TensorFlow2.4.1
🚀 深度學習新人必看:《小白入門深度學習》
- 小白入門深度學習 | 第一篇:配置深度學習環境
- 小白入門深度學習 | 第二篇:編譯器的使用-Jupyter Notebook
- 小白入門深度學習 | 第三篇:深度學習初體驗
🚀 往期精彩-卷積神經網路篇:
- 深度學習100例-卷積神經網路(CNN)實作mnist手寫數字識別 | 第1天
- 深度學習100例-卷積神經網路(CNN)彩色圖片分類 | 第2天
- 深度學習100例-卷積神經網路(CNN)服裝影像分類 | 第3天
- 深度學習100例-卷積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-卷積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-卷積神經網路(VGG-16)識別海賊王草帽一伙 | 第6天
- 深度學習100例-卷積神經網路(VGG-19)識別靈籠中的人物 | 第7天
- 深度學習100例-卷積神經網路(ResNet-50)鳥類識別 | 第8天
- 深度學習100例-卷積神經網路(AlexNet)手把手教學 | 第11天
- 深度學習100例-卷積神經網路(CNN)識別驗證碼 | 第12天
- 深度學習100例-卷積神經網路(Inception V3)識別手語 | 第13天
- 深度學習100例-卷積神經網路(Inception-ResNet-v2)識別交通標志 | 第14天
- 深度學習100例-卷積神經網路(CNN)實作車牌識別 | 第15天
- 深度學習100例-卷積神經網路(CNN)識別神奇寶貝小智一伙 | 第16天
- 深度學習100例-卷積神經網路(CNN)注意力檢測 | 第17天
🚀 往期精彩-回圈神經網路篇:
- 深度學習100例-回圈神經網路(RNN)實作股票預測 | 第9天
- 深度學習100例-回圈神經網路(LSTM)實作股票預測 | 第10天
🚀 往期精彩-生成對抗網路篇:
- 深度學習100例-生成對抗網路(GAN)手寫數字生成 | 第18天
- 深度學習100例-生成對抗網路(DCGAN)手寫數字生成 | 第19天
🚀 本文選自專欄:《深度學習100例》
🚀 推薦精選專欄:《夜深人靜寫演算法》
二、什么是生成對抗網路?
生成對抗網路(GAN)是當今計算機科學領域最有趣的想法之一,兩個模型通過對抗程序同時訓練,一個生成器模型(“藝術家”)學習創造看起來真實的影像,而判別器模型(“藝術評論家”)學習區分真偽影像,
GAN 的應用十分廣泛,它的應用包括影像合成、風格遷移、照片修復以及照片編輯,資料增強等等,這次我將講解如何用生成對抗網路生成小姐姐,
先看看我生成的小姐姐一睹為快

1. 設定GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #設定GPU顯存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 列印顯卡資訊,確認GPU可用
print(gpus)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
from tensorflow.keras import layers
from IPython import display
import numpy as np
import glob,imageio,os,PIL,time,pathlib
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
2. 加載和準備資料集
您將使用 MNIST 資料集來訓練生成器和判別器,生成器將生成類似于 MNIST 資料集的手寫數字,
data_dir = "D:/jupyter notebook/DL-100-days/datasets/020_cartoon_face"
data_dir = pathlib.Path(data_dir)
pictures_paths = list(data_dir.glob('*'))
pictures_paths = [str(path) for path in pictures_paths]
pictures_paths[:3]
['D:\\jupyter notebook\\DL-100-days\\datasets\\020_cartoon_face\\1.png',
'D:\\jupyter notebook\\DL-100-days\\datasets\\020_cartoon_face\\10.png',
'D:\\jupyter notebook\\DL-100-days\\datasets\\020_cartoon_face\\100.png']
image_count = len(list(pictures_paths))
print("圖片總數為:",image_count)
圖片總數為: 21551
plt.figure(figsize=(10,5))
plt.suptitle("資料示例",fontsize=15)
for i in range(40):
plt.subplot(5,8,i+1)
plt.xticks([])
plt.yticks([])
# 顯示圖片
images = plt.imread(pictures_paths[i])
plt.imshow(images)
# plt.show()

def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [64, 64])
return (image - 127.5) / 127.5
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
AUTOTUNE = tf.data.experimental.AUTOTUNE
path_ds = tf.data.Dataset.from_tensor_slices(pictures_paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# 批量化和打亂資料
train_dataset = image_ds.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
三、創建模型
1. 生成器
生成器使用 tf.keras.layers.Conv2DTranspose (上采樣)層來從種子(隨機噪聲)中產生圖片,以一個使用該種子作為輸入的 Dense 層開始,然后多次上采樣直到達到所期望的 28x28x1 的圖片尺寸,注意除了輸出層使用 tanh 之外,其他每層均使用 tf.keras.layers.LeakyReLU 作為激活函式,
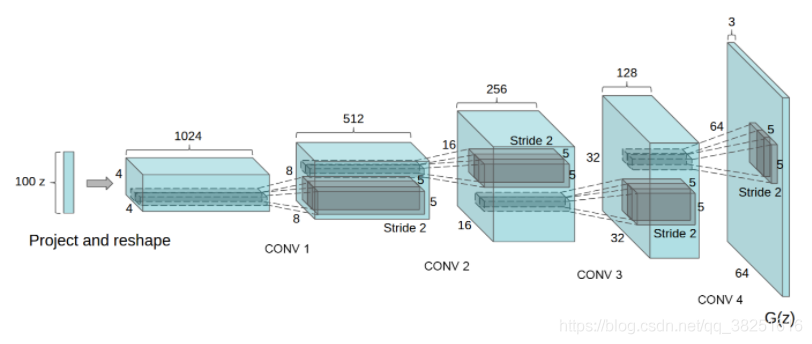
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(4*4*1024, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((4, 4, 1024)))
assert model.output_shape == (None, 4, 4, 1024)
# 第一層
model.add(layers.Conv2DTranspose(512, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 8, 8, 512)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 第二層
model.add(layers.Conv2DTranspose(256, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 16, 16, 256)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 第三層
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 32, 32, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 第四層
model.add(layers.Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 64, 64, 3)
return model
generator = make_generator_model()
generator.summary()
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 16384) 1638400
_________________________________________________________________
batch_normalization_8 (Batch (None, 16384) 65536
_________________________________________________________________
leaky_re_lu_16 (LeakyReLU) (None, 16384) 0
_________________________________________________________________
reshape_2 (Reshape) (None, 4, 4, 1024) 0
_________________________________________________________________
conv2d_transpose_8 (Conv2DTr (None, 8, 8, 512) 13107200
_________________________________________________________________
batch_normalization_9 (Batch (None, 8, 8, 512) 2048
_________________________________________________________________
leaky_re_lu_17 (LeakyReLU) (None, 8, 8, 512) 0
_________________________________________________________________
conv2d_transpose_9 (Conv2DTr (None, 16, 16, 256) 3276800
_________________________________________________________________
batch_normalization_10 (Batc (None, 16, 16, 256) 1024
_________________________________________________________________
leaky_re_lu_18 (LeakyReLU) (None, 16, 16, 256) 0
_________________________________________________________________
conv2d_transpose_10 (Conv2DT (None, 32, 32, 128) 819200
_________________________________________________________________
batch_normalization_11 (Batc (None, 32, 32, 128) 512
_________________________________________________________________
leaky_re_lu_19 (LeakyReLU) (None, 32, 32, 128) 0
_________________________________________________________________
conv2d_transpose_11 (Conv2DT (None, 64, 64, 3) 9600
=================================================================
Total params: 18,920,320
Trainable params: 18,885,760
Non-trainable params: 34,560
_________________________________________________________________
2. 判別器
判別器是一個基于 CNN 的圖片分類器,
def make_discriminator_model():
model = tf.keras.Sequential([
layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same', input_shape=[64, 64, 3]),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Conv2D(256, (5, 5), strides=(2, 2), padding='same'),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Conv2D(512, (5, 5), strides=(2, 2), padding='same'),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(1)
])
return model
discriminator = make_discriminator_model()
discriminator.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_8 (Conv2D) (None, 32, 32, 128) 9728
_________________________________________________________________
leaky_re_lu_20 (LeakyReLU) (None, 32, 32, 128) 0
_________________________________________________________________
dropout_8 (Dropout) (None, 32, 32, 128) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 128) 409728
_________________________________________________________________
leaky_re_lu_21 (LeakyReLU) (None, 16, 16, 128) 0
_________________________________________________________________
dropout_9 (Dropout) (None, 16, 16, 128) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 8, 8, 256) 819456
_________________________________________________________________
leaky_re_lu_22 (LeakyReLU) (None, 8, 8, 256) 0
_________________________________________________________________
dropout_10 (Dropout) (None, 8, 8, 256) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 4, 4, 512) 3277312
_________________________________________________________________
leaky_re_lu_23 (LeakyReLU) (None, 4, 4, 512) 0
_________________________________________________________________
dropout_11 (Dropout) (None, 4, 4, 512) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 8193
=================================================================
Total params: 4,524,417
Trainable params: 4,524,417
Non-trainable params: 0
_________________________________________________________________
四、定義損失函式和優化器
為兩個模型定義損失函式和優化器,
# 該方法回傳計算交叉熵損失的輔助函式
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
1. 判別器損失
該方法量化判斷真偽圖片的能力,它將判別器對真實圖片的預測值與值全為 1 的陣列進行對比,將判別器對偽造(生成的)圖片的預測值與值全為 0 的陣列進行對比,
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
2. 生成器損失
生成器損失量化其欺騙判別器的能力,直觀來講,如果生成器表現良好,判別器將會把偽造圖片判斷為真實圖片(或 1),這里我們將把判別器在生成圖片上的判斷結果與一個值全為 1 的陣列進行對比,
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
由于我們需要分別訓練兩個網路,判別器和生成器的優化器是不同的,
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
五、保存檢查點
tf.train.Checkpoint 只保存模型的引數,不保存模型的計算程序,因此一般用于在具有模型源代碼的時候恢復之前訓練好的模型引數,
# 定義模型保存路徑
checkpoint_dir = './model/model_20/training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
六、定義訓練回圈
EPOCHS = 600
noise_dim = 100
num_examples_to_generate = 16
# 我們將重復使用該種子(在 GIF 中更容易可視化進度)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
訓練回圈在生成器接收到一個隨機種子作為輸入時開始,該種子用于生產一張圖片,判別器隨后被用于區分真實圖片(選自訓練集)和偽造圖片(由生成器生成),針對這里的每一個模型都計算損失函式,并且計算梯度用于更新生成器與判別器,
# 注意 `tf.function` 的使用
# 該注解使函式被“編譯”
@tf.function
def train_step(images):
# 生成噪音
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
# 計算loss
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
#計算梯度
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
#更新模型
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# 實時更新生成的圖片
display.clear_output(wait=True)
generate_and_save_images(generator, epoch + 1, seed)
# 每 15 個 epoch 保存一次模型
if (epoch + 1) % 100 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# 最后一個 epoch 結束后生成圖片
display.clear_output(wait=True)
generate_and_save_images(generator, epochs, seed)
生成與保存圖片
def generate_and_save_images(model, epoch, test_input):
# 注意 training` 設定為 False
# 因此,所有層都在推理模式下運行(batchnorm),
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(5,5))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i] * 0.5 + 0.5) # 注意需要還原標準化的圖片
plt.axis('off')
plt.savefig('./images/images_20/image_at_epoch_{:04d}.png'.format(epoch+600))
plt.show()
七、訓練模型
呼叫上面定義的 train() 方法來同時訓練生成器和判別器,在訓練之初,生成的圖片看起來像是隨機噪聲,隨著訓練程序的進行,生成的數字將越來越真實,在大概 50 個 epoch 之后,這些圖片看起來像是 MNIST 數字,
1. 恢復模型引數
回傳目錄下最近一次checkpoint的檔案名,例如如果save目錄下有 model.ckpt-1.index 到 model.ckpt-10.index 的10個保存檔案, tf.train.latest_checkpoint('./save') 即回傳 ./save/model.ckpt-10 ,
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x20498267128>
2. 訓練模型
%%time:將會給出cell的代碼運行一次所花費的時間,
%%time
train(train_dataset, EPOCHS)

Time for epoch 201 is 17.364601135253906 sec
3. 創建 GIF
import imageio,pathlib
def compose_gif():
# 圖片地址
data_dir = "./images/images_20"
data_dir = pathlib.Path(data_dir)
paths = list(data_dir.glob('*'))
gif_images = []
for path in paths:
gif_images.append(imageio.imread(path))
imageio.mimsave("MINST_DCGAN_20.gif",gif_images,fps=8)
compose_gif()
print("GIF動圖生成完成!")
GIF動圖生成完成!

八、同系列作品
🚀 深度學習新人必看:《小白入門深度學習》
- 小白入門深度學習 | 第一篇:配置深度學習環境
- 小白入門深度學習 | 第二篇:編譯器的使用-Jupyter Notebook
- 小白入門深度學習 | 第三篇:深度學習初體驗
🚀 往期精彩-卷積神經網路篇:
- 深度學習100例-卷積神經網路(CNN)實作mnist手寫數字識別 | 第1天
- 深度學習100例-卷積神經網路(CNN)彩色圖片分類 | 第2天
- 深度學習100例-卷積神經網路(CNN)服裝影像分類 | 第3天
- 深度學習100例-卷積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-卷積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-卷積神經網路(VGG-16)識別海賊王草帽一伙 | 第6天
- 深度學習100例-卷積神經網路(VGG-19)識別靈籠中的人物 | 第7天
- 深度學習100例-卷積神經網路(ResNet-50)鳥類識別 | 第8天
- 深度學習100例-卷積神經網路(AlexNet)手把手教學 | 第11天
- 深度學習100例-卷積神經網路(CNN)識別驗證碼 | 第12天
- 深度學習100例-卷積神經網路(Inception V3)識別手語 | 第13天
- 深度學習100例-卷積神經網路(Inception-ResNet-v2)識別交通標志 | 第14天
- 深度學習100例-卷積神經網路(CNN)實作車牌識別 | 第15天
- 深度學習100例-卷積神經網路(CNN)識別神奇寶貝小智一伙 | 第16天
- 深度學習100例-卷積神經網路(CNN)注意力檢測 | 第17天
🚀 往期精彩-回圈神經網路篇:
- 深度學習100例-回圈神經網路(RNN)實作股票預測 | 第9天
- 深度學習100例-回圈神經網路(LSTM)實作股票預測 | 第10天
🚀 往期精彩-生成對抗網路篇:
- 深度學習100例-生成對抗網路(GAN)手寫數字生成 | 第18天
- 深度學習100例-生成對抗網路(DCGAN)手寫數字生成 | 第19天
🚀 本文選自專欄:《深度學習100例》
🚀 推薦精選專欄:《夜深人靜寫演算法》
九、資料+模型
鏈接:https://pan.baidu.com/s/1ZSOidGKbly5yDkiODsmn6A
提取碼:qt7h
小提示:記得將代碼中的路徑更換為自己本地的路徑!
未完~
持續更新 歡迎 點贊👍、收藏?、關注👀
- 點贊👍:點贊給我持續更新的動力
- 收藏??:收藏后你能夠隨時找到文章
- 關注👀:關注我第一時間接收最新文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290785.html
標籤:AI
下一篇:NLP經典模型復現之開宗明義