來自 B 站劉二大人的《PyTorch深度學習實踐》P11 的學習筆記
GoogLeNet
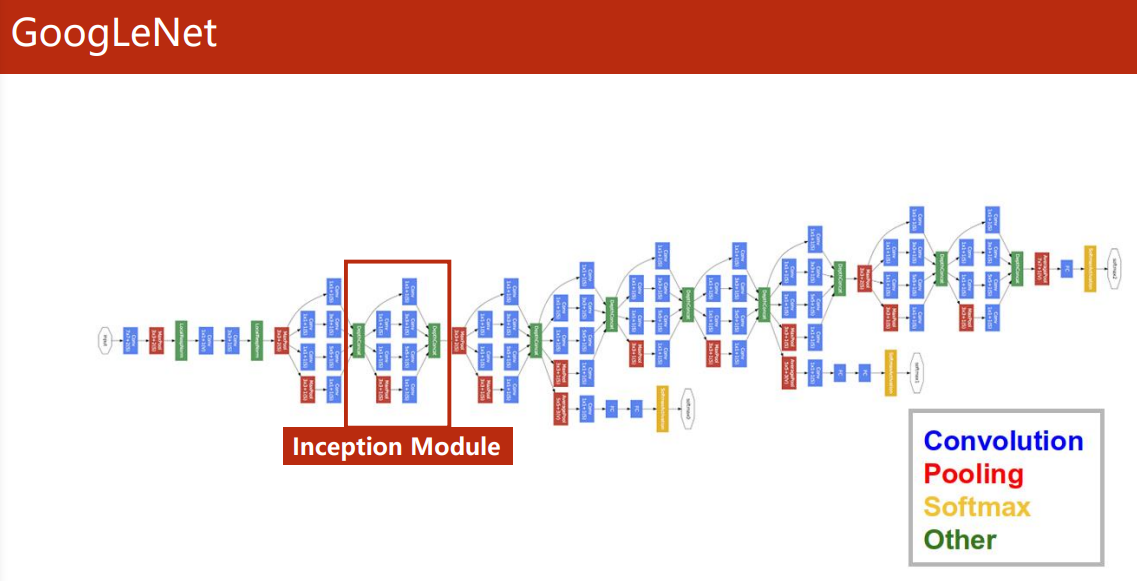
-
1×1 卷積
上一篇我們知道,卷積的個數取決于輸入影像的通道數,
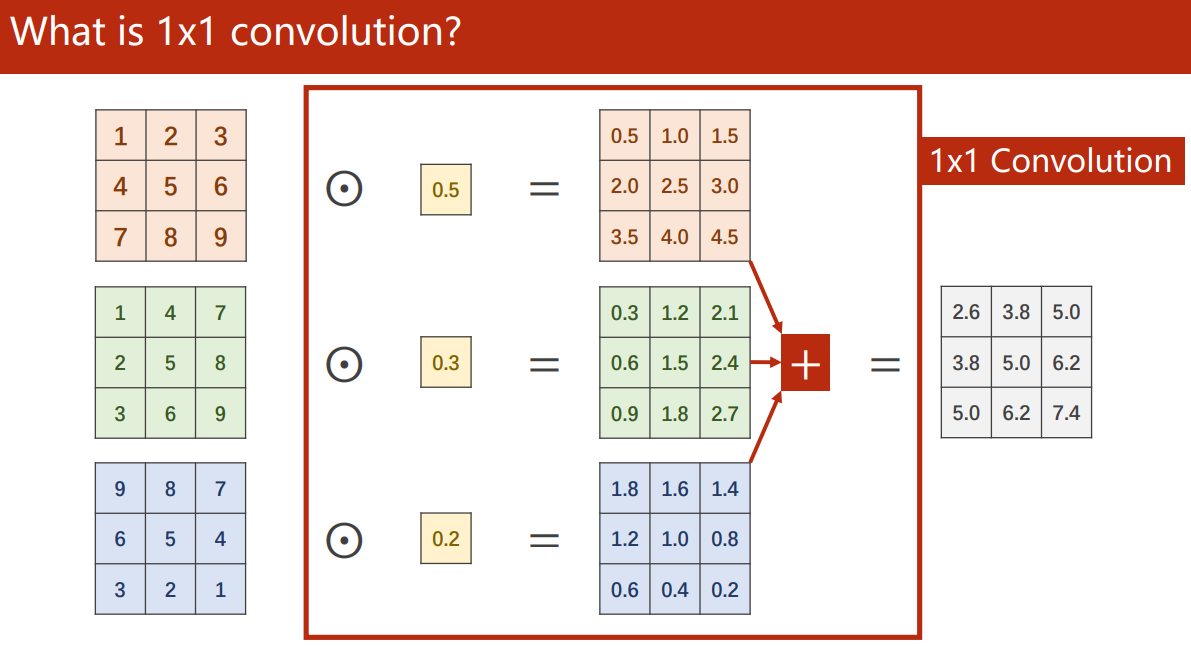
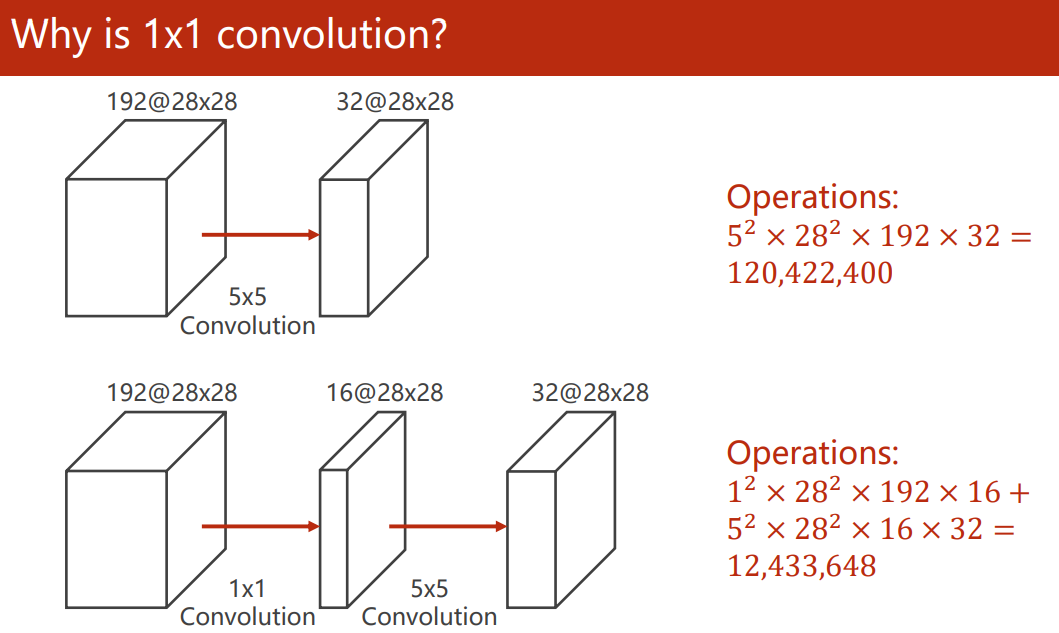
1×1 卷積能起到特征融合、改變通道數和減少計算量的效果,被稱為神經網路中的神經網路例如,我們先通過 1×1 卷積減少了通道的數量,讓大的卷積核計算更少的通道數,能大大減少計算量:
-
Inception Module
Inception(盜夢空間) Module 的目的在于給神經網路提供多個卷積層的配置,在將來通過訓練選擇最優線路,和其它輔助路線,
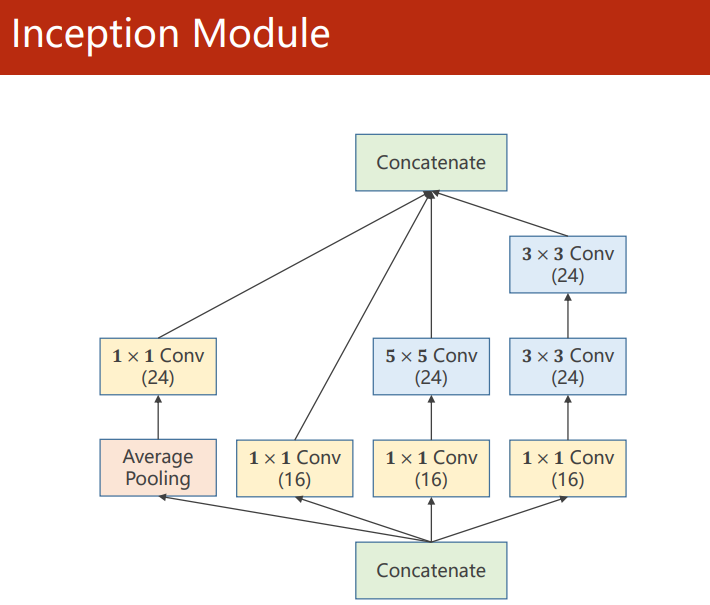
由于每條路線的最終結果需要堆疊起來,所以需要保證輸出的特征圖大小一致,對于 Average Pooling 池化層,需要通過 padding 和 stride 來保證最后的輸出大小,
實作
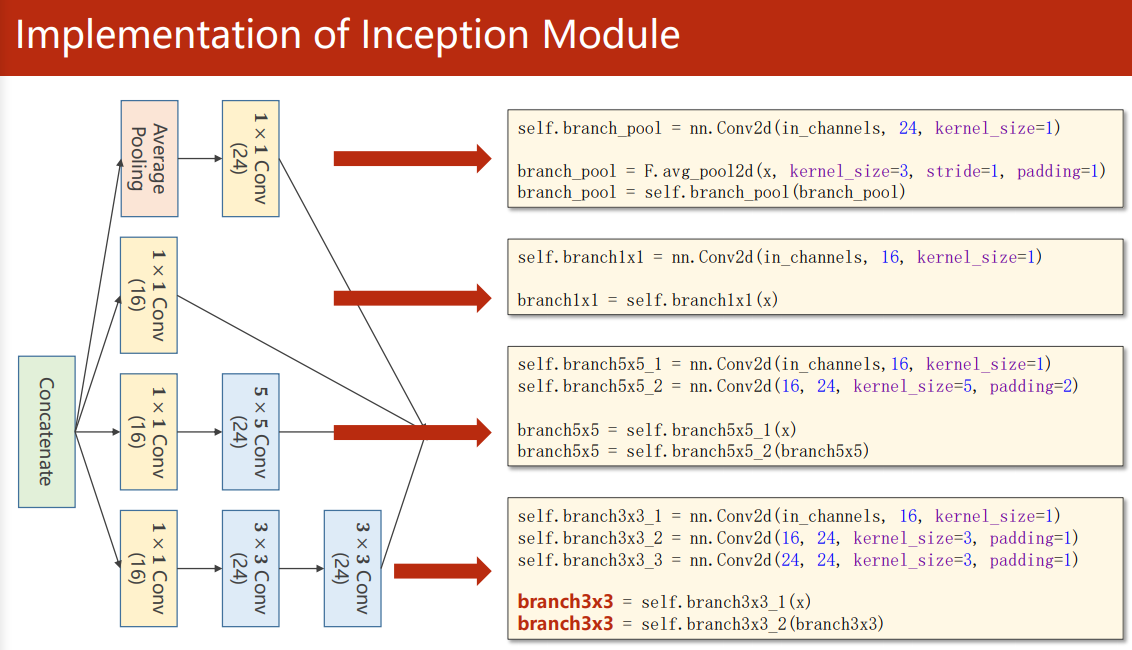
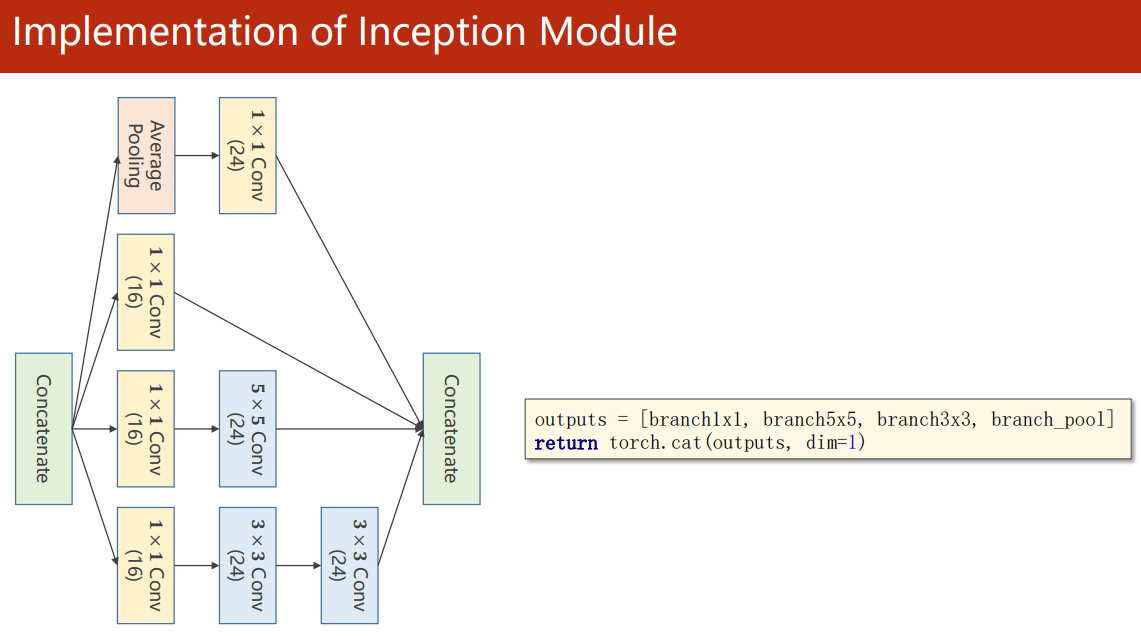
把輸出拼接到一起再輸入下一層
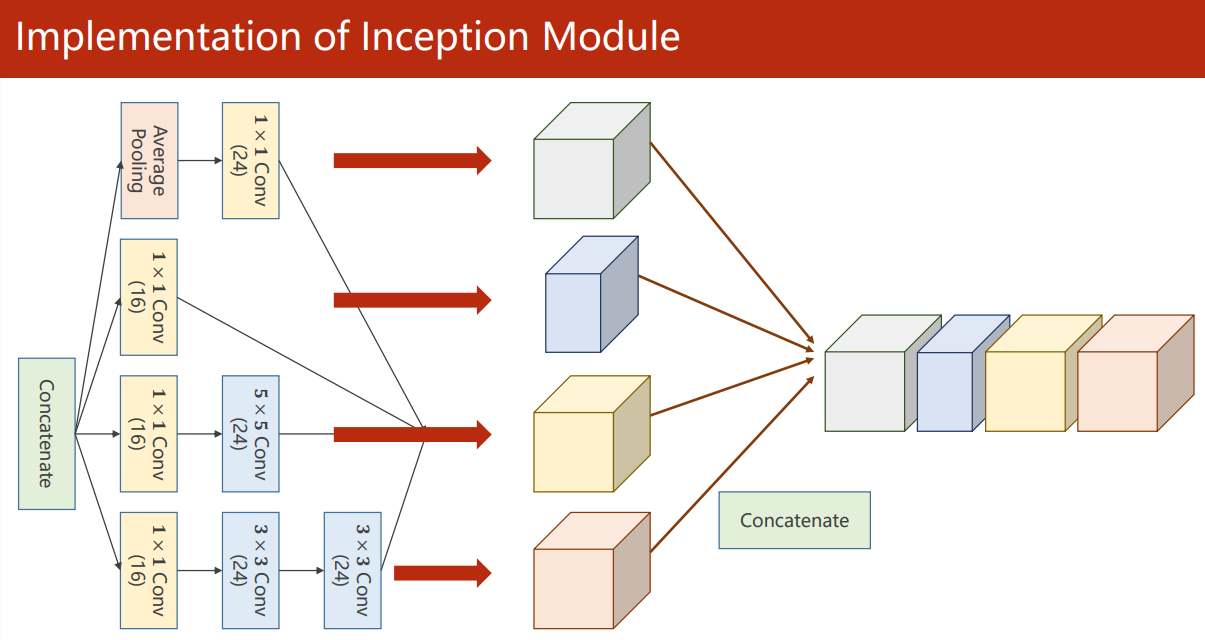
torch.cat(outputs, dim=1) 中,dim=1 指的是以通道維度拼接(N,C,W,H)
用了兩個 Inception Module:
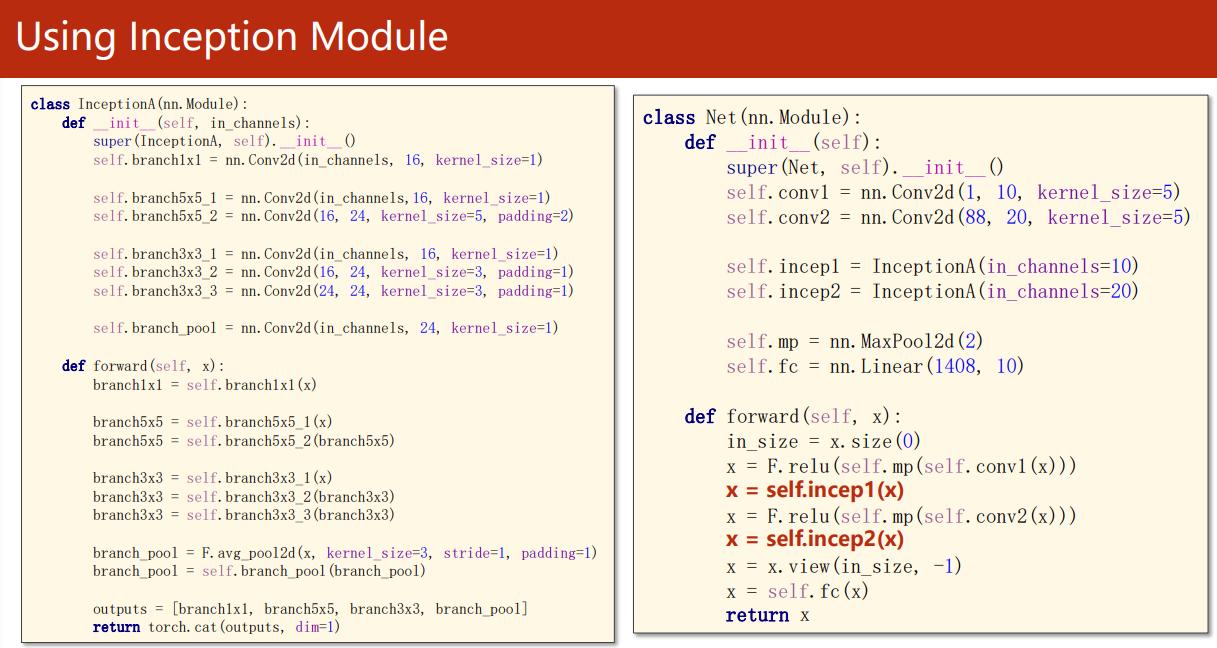
我們只需要把上一篇代碼中的神經網路部分換成 GoogleNet,即可使用它來識別 MNIST 資料集:
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
"""
由于特征圖要拼接,所以需要通過設定padding、stride來保證卷積過后特征圖大小不變;
由于在Inception塊之前還有卷積層,所以輸入的通道數不是一樣的,需要把輸入通道數作為一個引數,
:return:
輸出的通道數為 16+24×3=88,故回傳 N,88,*,* 的特征圖
"""
def __init__(self, in_channels):
super(Inception, self).__init__()
self.pool_conv1x1 = nn.Conv2d(in_channels, 24, kernel_size=1) # 池化+一個1×1卷積,輸出24通道
self.conv1x1 = nn.Conv2d(in_channels, 16, kernel_size=1) # 三個同樣的1×1卷積,輸出16通道
self.conv3x3_16 = nn.Conv2d(16, 24, kernel_size=3, padding=1) # 輸入為16通道的3×3卷積,輸出24通道
self.conv3x3_24 = nn.Conv2d(24, 24, kernel_size=3, padding=1) # 輸入為24通道的3×3卷積,輸出24通道
self.conv5x5 = nn.Conv2d(16, 24, kernel_size=5, padding=2) # 一個5×5卷積,輸出24通道
def forward(self, x):
out1 = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) # N,*,,
out1 = self.pool_conv1x1(out1) # N,24,,
out2 = self.conv1x1(x) # N,16,,
out3 = self.conv1x1(x) # N,16,,
out3 = self.conv5x5(out3) # N,24,,
out4 = self.conv1x1(x) # N,16,,
out4 = self.conv3x3_16(out4) # N,24,,
out4 = self.conv3x3_24(out4) # N,24,,
outputs = (out1, out2, out3, out4)
return torch.cat(outputs, dim=1) # N,88,,
class GoogleNet(nn.Module):
def __init__(self):
super(GoogleNet, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # return N,10,,
self.incep1 = Inception(in_channels=10) # return N,88,,
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep2 = Inception(in_channels=20) # return N,88,,
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) # N,10,12,12
x = self.incep1(x) # N,88,12,12
x = F.relu(self.mp(self.conv2(x))) # N,20,4,4
x = self.incep2(x) # N,88,4,4
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = GoogleNet()
Go Deeper
GoogleNet 想要借助 Inception Module 實作更深的網路來提高性能,但是,真的越深越爽嗎?

ResNet
-
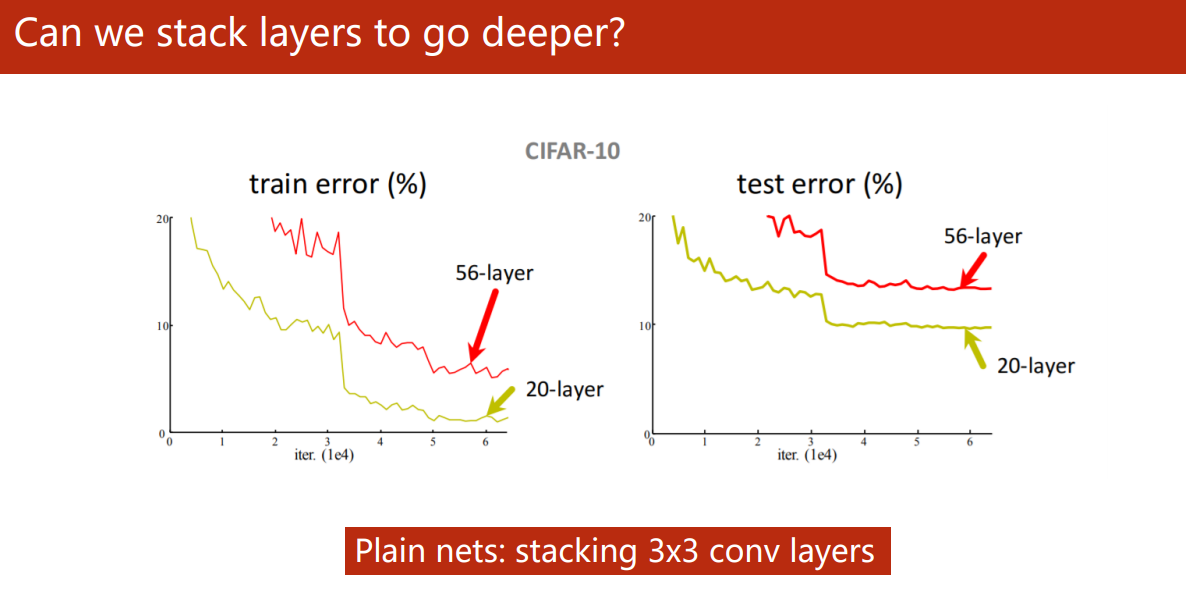
Can we stack layers to go deeper?
5 年前,何凱明大神的論文《Deep Residual Learning for Image Recognition》1 揭示了神經網路不是盲目地疊得越深就越好,
圖中所示 56 層深的網路的訓練以及測驗的錯誤率都比 20 層的要高,其中一個主要的原因是越深層的網路越容易發生梯度消失,造成一部分的網路層很難在訓練中更新,
-
Residual Block
縱使如此,我們依然沒有否定越深就越爽,仍然想要 Go Deeper,
于是,何凱明提出了殘差鏈接模塊,通過跳連(shortcut)的方式更容易保留上一層的梯度(圖中少了 BatchNorm 層),
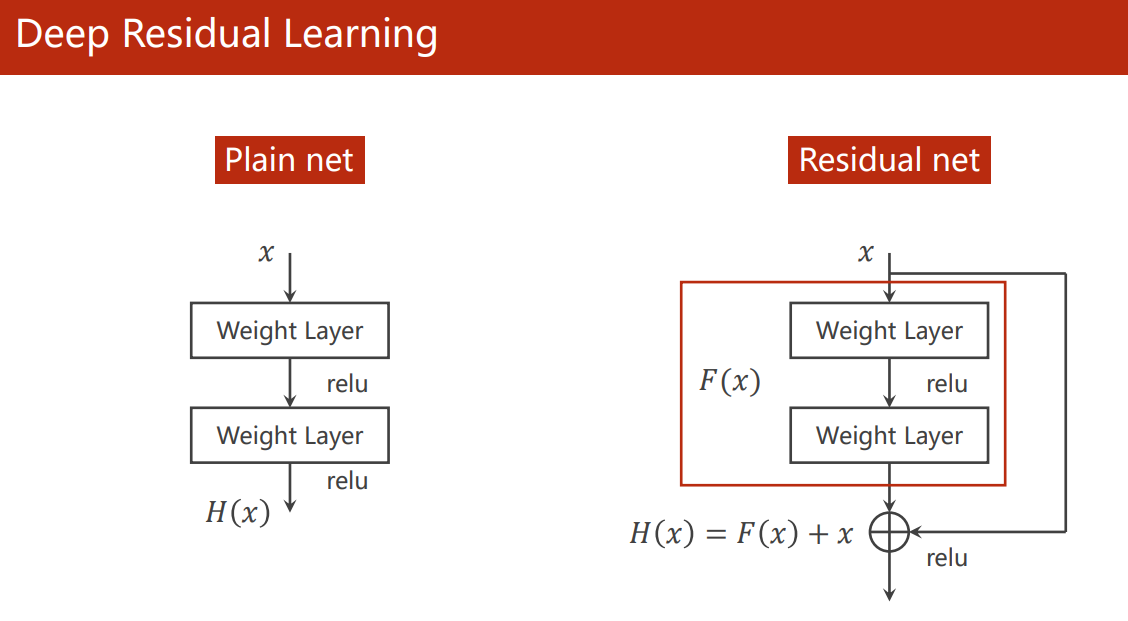
由于經過卷積后的特征圖要和前一層的輸出相加,所以整個 ResNet 的卷積層的輸出特征圖大小都要保證相同,或者每一個 Residual Block 中的卷積輸出要一致,

Residual Block 的實作:

論文2 有更加詳細的 Residual Block 流程圖: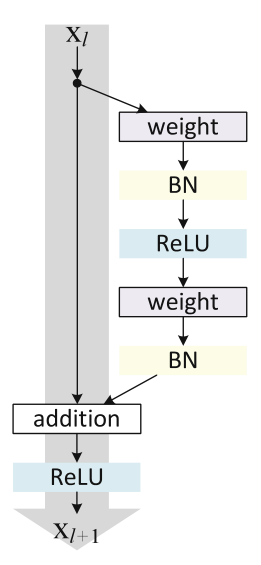
ResNet 的實作:

from torch import nn
from torch.nn import functional as F
from train_and_test import train, test, draw
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.bn = nn.BatchNorm2d(channels)
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) # 特征圖大小沒變
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.bn(self.conv1(x)))
y = self.bn(self.conv1(y))
return F.relu(x + y) # 不是拼接,所以回傳通道數還是 channel
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.rblock1 = ResidualBlock(channels=16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.rblock2 = ResidualBlock(channels=32)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(512, 10)
def forward(self, x):
batch_size = x.size(0)
x = self.mp(F.relu(self.conv1(x))) # N,16,12,12
x = self.rblock1(x) # N,16,12,12
x = self.mp(F.relu(self.conv2(x))) # N,32,4,4
x = self.rblock2(x) # N,32,4,4
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = ResNet()
讀論文,復現 ResNet v2
復現何凱明大神的 ResNet v2:《Identity Mappings in Deep Residual Networks》2
其實,這篇論文主要討論了 ResNet 的 Residual Block 可能的各種魔改方式:
- shortcut(灰色箭頭線、快捷鏈接)上加入其它操作或者像 Inception Module 一樣搞多個分支:
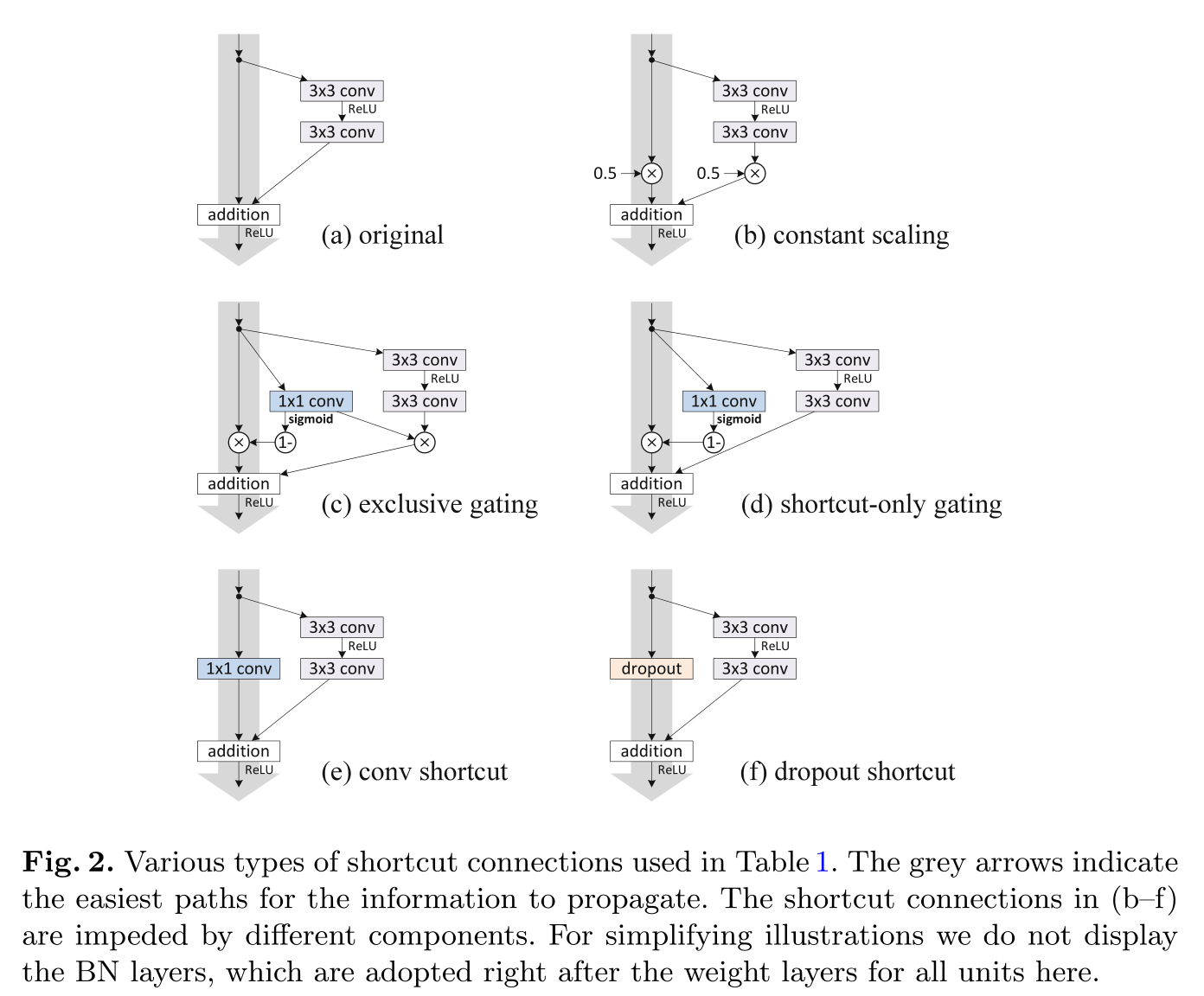
- 歸一化層(BatchNorm)和激活層(ReLU)的不同順序:
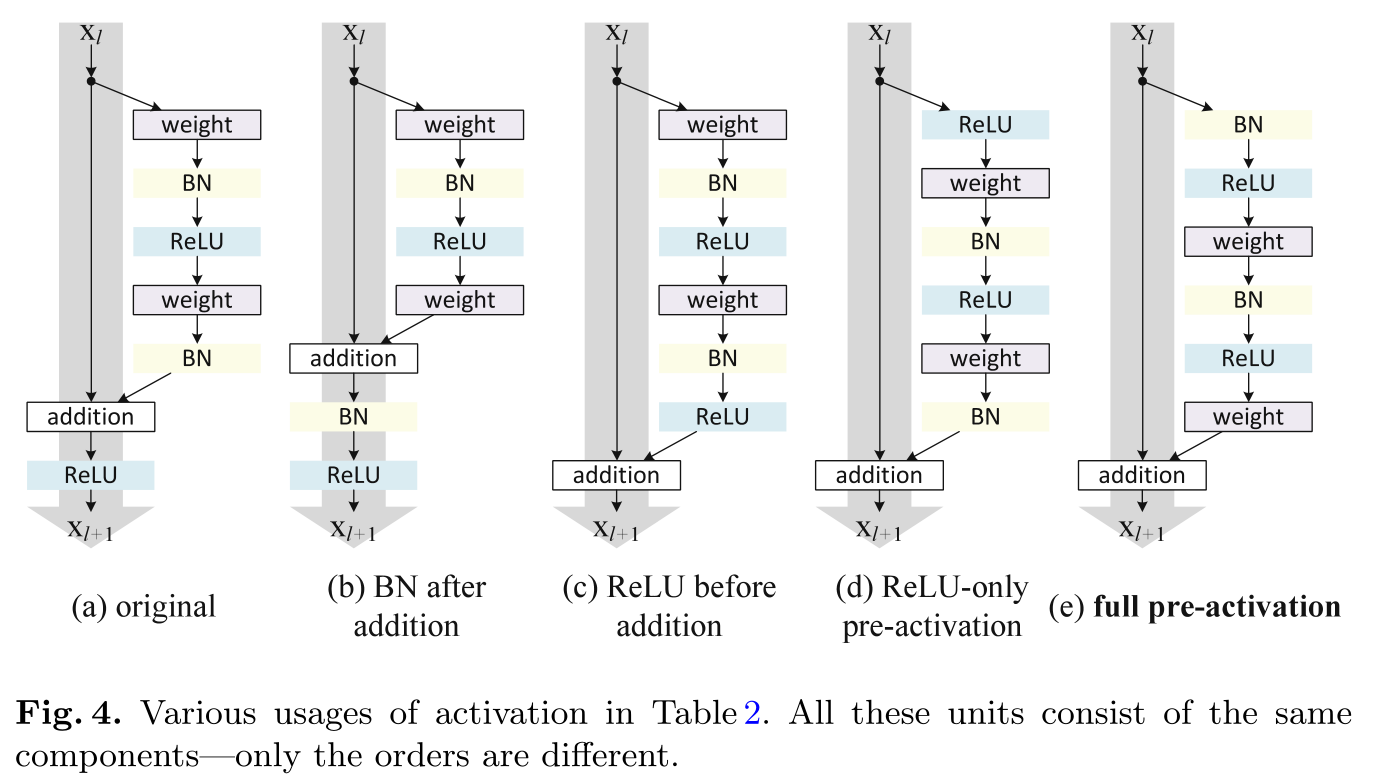
最終的結論是 shortcut(灰色箭頭線、快捷鏈接)最好不做其它操作,盡量保持干凈,以便資訊的傳播,消融實驗(控制變數法)也表明,original shortcut1 (Fig.2. (a) original)已經是最好的了,
對于歸一化層(BatchNorm)和激活層(ReLU)順序的魔改問題,最終的消融實驗(控制變數法)表明,BN+ReLU 層在卷積層前面先對輸入進行計算是更好的(Fig.4. (e) full pre-activation),比1 還好,
所以代碼只需要改一下 ResidualBlock 的 BN+ReLU 的順序:
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.bn = nn.BatchNorm2d(channels)
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) # 特征圖大小沒變
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = self.conv1(F.relu(self.bn(x)))
y = self.conv2(F.relu(self.bn(y)))
return x + y # 不需要再激活
讀論文,復現 DenseNet
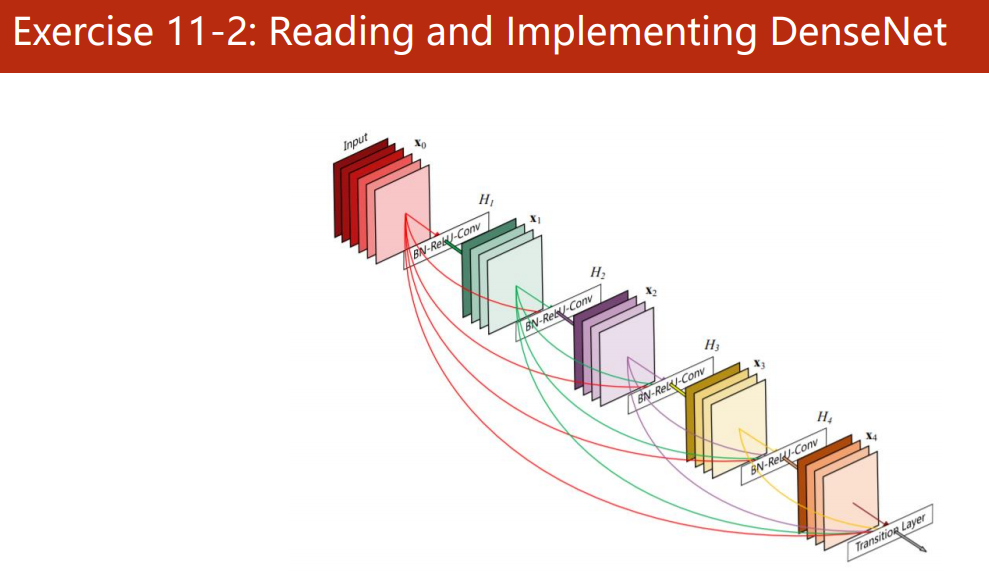
待續,,,
He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:770-778. ?? ?? ??
He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks[C]. ?? ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291415.html
標籤:AI